使用线性回归预测波士顿房价¶
作者: PaddlePaddle
日期: 2022.5
摘要: 本示例教程将会演示如何使用线性回归完成波士顿房价预测。
一、简要介绍¶
经典的线性回归模型主要用来预测一些存在着线性关系的数据集。回归模型可以理解为:存在一个点集,用一条曲线去拟合它分布的过程。如果拟合曲线是一条直线,则称为线性回归。如果是一条二次曲线,则被称为二次回归。线性回归是回归模型中最简单的一种。 本示例简要介绍如何用飞桨开源框架,实现波士顿房价预测。其思路是,假设uci-housing数据集中的房子属性和房价之间的关系可以被属性间的线性组合描述。在模型训练阶段,让假设的预测结果和真实值之间的误差越来越小。在模型预测阶段,预测器会读取训练好的模型,对从未遇见过的房子属性进行房价预测。
二、环境配置¶
本教程基于 PaddlePaddle 2.3.0 编写,如果你的环境不是本版本,请先参考官网安装 PaddlePaddle 2.3.0。
import paddle
import numpy as np
import os
import matplotlib
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
print(paddle.__version__)
2.3.0
三、数据集介绍¶
本示例采用uci-housing数据集,这是经典线性回归的数据集。数据集共7084条数据,可以拆分成506行,每行14列。前13列用来描述房屋的各种信息,最后一列为该类房屋价格中位数。
前13列用来描述房屋的各种信息
3.1 数据处理¶
#下载数据
!wget https://archive.ics.uci.edu/ml/machine-learning-databases/housing/housing.data -O housing.data
# 从文件导入数据
datafile = './housing.data'
housing_data = np.fromfile(datafile, sep=' ')
feature_names = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE','DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV']
feature_num = len(feature_names)
# 将原始数据进行Reshape,变成[N, 14]这样的形状
housing_data = housing_data.reshape([housing_data.shape[0] // feature_num, feature_num])
# 画图看特征间的关系,主要是变量两两之间的关系(线性或非线性,有无明显较为相关关系)
features_np = np.array([x[:13] for x in housing_data], np.float32)
labels_np = np.array([x[-1] for x in housing_data], np.float32)
# data_np = np.c_[features_np, labels_np]
df = pd.DataFrame(housing_data, columns=feature_names)
matplotlib.use('TkAgg')
%matplotlib inline
sns.pairplot(df.dropna(), y_vars=feature_names[-1], x_vars=feature_names[::-1], diag_kind='kde')
plt.show()

# 相关性分析
fig, ax = plt.subplots(figsize=(15, 1))
corr_data = df.corr().iloc[-1]
corr_data = np.asarray(corr_data).reshape(1, 14)
ax = sns.heatmap(corr_data, cbar=True, annot=True)
plt.show()

3.2 数据归一化处理¶
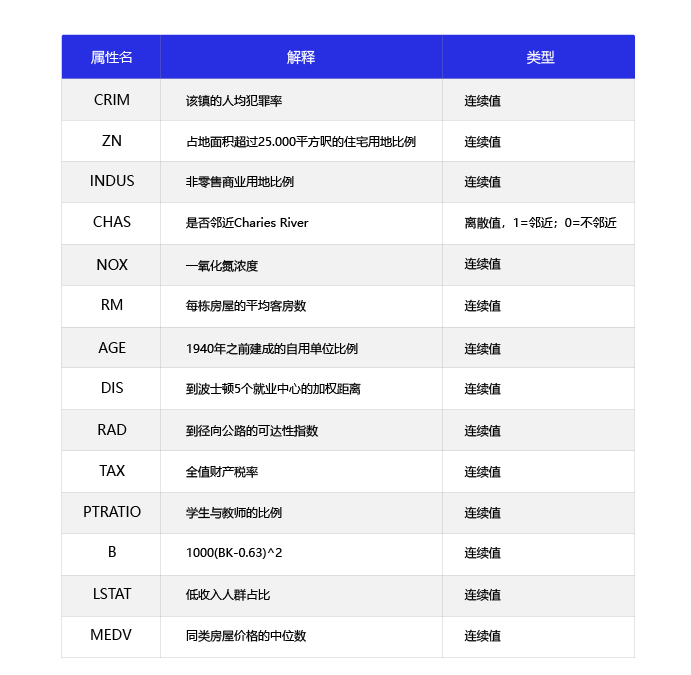
下图展示各属性的取值范围分布:
sns.boxplot(data=df.iloc[:, 0:13])
<matplotlib.axes._subplots.AxesSubplot at 0x7fc3bcbc5310>
从上图看出,各属性的数值范围差异太大,甚至不能够在一个画布上充分的展示各属性具体的最大、最小值以及异常值等。下面进行归一化。
做归一化(或 Feature scaling)至少有以下2个理由:
过大或过小的数值范围会导致计算时的浮点上溢或下溢。
不同的数值范围会导致不同属性对模型的重要性不同(至少在训练的初始阶段如此),而这个隐含的假设常常是不合理的。这会对优化的过程造成困难,使训练时间大大的加长.
features_max = housing_data.max(axis=0)
features_min = housing_data.min(axis=0)
features_avg = housing_data.sum(axis=0) / housing_data.shape[0]
BATCH_SIZE = 20
def feature_norm(input):
f_size = input.shape
output_features = np.zeros(f_size, np.float32)
for batch_id in range(f_size[0]):
for index in range(13):
output_features[batch_id][index] = (input[batch_id][index] - features_avg[index]) / (features_max[index] - features_min[index])
return output_features
# 只对属性进行归一化
housing_features = feature_norm(housing_data[:, :13])
# print(feature_trian.shape)
housing_data = np.c_[housing_features, housing_data[:, -1]].astype(np.float32)
# print(training_data[0])
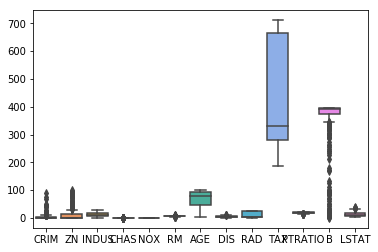
# 归一化后的train_data, 看下各属性的情况
features_np = np.array([x[:13] for x in housing_data],np.float32)
labels_np = np.array([x[-1] for x in housing_data],np.float32)
data_np = np.c_[features_np, labels_np]
df = pd.DataFrame(data_np, columns=feature_names)
sns.boxplot(data=df.iloc[:, 0:13])
<matplotlib.axes._subplots.AxesSubplot at 0x7fc3bca4cc10>
# 将训练数据集和测试数据集按照8:2的比例分开
ratio = 0.8
offset = int(housing_data.shape[0] * ratio)
train_data = housing_data[:offset]
test_data = housing_data[offset:]
四、模型组网¶
线性回归就是一个从输入到输出的简单的全连接层。
对于波士顿房价数据集,假设属性和房价之间的关系可以被属性间的线性组合描述。
class Regressor(paddle.nn.Layer):
def __init__(self):
super().__init__()
self.fc = paddle.nn.Linear(13, 1,)
def forward(self, inputs):
pred = self.fc(inputs)
return pred
定义绘制训练过程的损失值变化趋势的方法 draw_train_process .
train_nums = []
train_costs = []
def draw_train_process(iters, train_costs):
plt.title("training cost", fontsize=24)
plt.xlabel("iter", fontsize=14)
plt.ylabel("cost", fontsize=14)
plt.plot(iters, train_costs, color='red', label='training cost')
plt.show()
五、方式1:使用基础API完成模型训练&预测¶
5.1 模型训练¶
下面展示模型训练的代码。
这里用到的是线性回归模型最常用的损失函数–均方误差(MSE),用来衡量模型预测的房价和真实房价的差异。
对损失函数进行优化所采用的方法是梯度下降法.
import paddle.nn.functional as F
y_preds = []
labels_list = []
def train(model):
print('start training ... ')
# 开启模型训练模式
model.train()
EPOCH_NUM = 500
train_num = 0
optimizer = paddle.optimizer.SGD(learning_rate=0.001, parameters=model.parameters())
for epoch_id in range(EPOCH_NUM):
# 在每轮迭代开始之前,将训练数据的顺序随机的打乱
np.random.shuffle(train_data)
# 将训练数据进行拆分,每个batch包含20条数据
mini_batches = [train_data[k: k+BATCH_SIZE] for k in range(0, len(train_data), BATCH_SIZE)]
for batch_id, data in enumerate(mini_batches):
features_np = np.array(data[:, :13], np.float32)
labels_np = np.array(data[:, -1:], np.float32)
features = paddle.to_tensor(features_np)
labels = paddle.to_tensor(labels_np)
# 前向计算
y_pred = model(features)
cost = F.mse_loss(y_pred, label=labels)
train_cost = cost.numpy()[0]
# 反向传播
cost.backward()
# 最小化loss,更新参数
optimizer.step()
# 清除梯度
optimizer.clear_grad()
if batch_id%30 == 0 and epoch_id%50 == 0:
print("Pass:%d,Cost:%0.5f"%(epoch_id, train_cost))
train_num = train_num + BATCH_SIZE
train_nums.append(train_num)
train_costs.append(train_cost)
model = Regressor()
train(model)
W0509 14:51:50.219018 1188 gpu_context.cc:278] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 10.1
W0509 14:51:50.223405 1188 gpu_context.cc:306] device: 0, cuDNN Version: 7.6.
start training ...
Pass:0,Cost:829.83044
Pass:50,Cost:61.24179
Pass:100,Cost:39.79546
Pass:150,Cost:30.91046
Pass:200,Cost:72.18225
Pass:250,Cost:15.98895
Pass:300,Cost:24.57131
Pass:350,Cost:11.01749
Pass:400,Cost:12.64952
Pass:450,Cost:38.58059
matplotlib.use('TkAgg')
%matplotlib inline
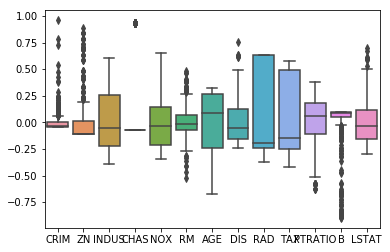
draw_train_process(train_nums, train_costs)
可以从上图看出,随着训练轮次的增加,损失在呈降低趋势。但由于每次仅基于少量样本更新参数和计算损失,所以损失下降曲线会出现震荡。
5.2 模型预测¶
# 获取预测数据
INFER_BATCH_SIZE = 100
infer_features_np = np.array([data[:13] for data in test_data]).astype("float32")
infer_labels_np = np.array([data[-1] for data in test_data]).astype("float32")
infer_features = paddle.to_tensor(infer_features_np)
infer_labels = paddle.to_tensor(infer_labels_np)
fetch_list = model(infer_features)
sum_cost = 0
for i in range(INFER_BATCH_SIZE):
infer_result = fetch_list[i][0]
ground_truth = infer_labels[i]
if i % 10 == 0:
print("No.%d: infer result is %.2f,ground truth is %.2f" % (i, infer_result, ground_truth))
cost = paddle.pow(infer_result - ground_truth, 2)
sum_cost += cost
mean_loss = sum_cost / INFER_BATCH_SIZE
print("Mean loss is:", mean_loss.numpy())
No.0: infer result is 11.82,ground truth is 8.50
No.10: infer result is 5.35,ground truth is 7.00
No.20: infer result is 14.91,ground truth is 11.70
No.30: infer result is 16.59,ground truth is 11.70
No.40: infer result is 13.60,ground truth is 10.80
No.50: infer result is 16.11,ground truth is 14.90
No.60: infer result is 18.67,ground truth is 21.40
No.70: infer result is 15.46,ground truth is 13.80
No.80: infer result is 18.04,ground truth is 20.60
No.90: infer result is 21.31,ground truth is 24.50
Mean loss is: [12.7556715]
def plot_pred_ground(pred, ground):
plt.figure()
plt.title("Predication v.s. Ground truth", fontsize=24)
plt.xlabel("ground truth price(unit:$1000)", fontsize=14)
plt.ylabel("predict price", fontsize=14)
plt.scatter(ground, pred, alpha=0.5) # scatter:散点图,alpha:"透明度"
plt.plot(ground, ground, c='red')
plt.show()
plot_pred_ground(fetch_list, infer_labels_np)
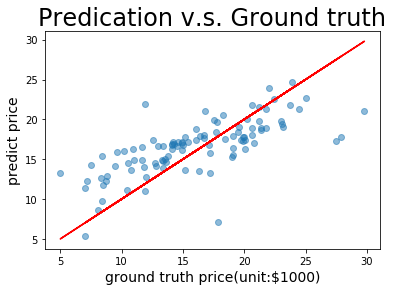
上图可以看出,训练出来的模型的预测结果与真实结果是较为接近的。
六、方式2:使用高层API完成模型训练&预测¶
也可以用飞桨的高层API来做线性回归训练,高层API相较于底层API更加的简洁方便。
import paddle
paddle.set_default_dtype("float64")
# step1:用高层API定义数据集,无需进行数据处理等,高层API为你一条龙搞定
train_dataset = paddle.text.datasets.UCIHousing(mode='train')
eval_dataset = paddle.text.datasets.UCIHousing(mode='test')
# step2:定义模型
class UCIHousing(paddle.nn.Layer):
def __init__(self):
super().__init__()
self.fc = paddle.nn.Linear(13, 1, None)
def forward(self, input):
pred = self.fc(input)
return pred
# step3:训练模型
model = paddle.Model(UCIHousing())
model.prepare(paddle.optimizer.Adam(parameters=model.parameters()),
paddle.nn.MSELoss())
model.fit(train_dataset, eval_dataset, epochs=5, batch_size=8, verbose=1)