模型自动化压缩工具(ACT)¶
模型压缩技术,一般是指在基础模型结构的基础上,通过精简模型结构、减少模型参数量或者降低模型存储量化位数,从而减小计算量,降低所需存储资源,提升模型推理速度。
一、模型压缩简介¶
1.1 模型压缩背景¶
端侧设备相关场景要求响应速度快、内存占用少和能耗低,模型压缩可以有效提升模型推理速度、减少模型所需存储空间和降低模型能耗。在超大模型落地应用场景中,模型压缩可以降本增效和低碳环保,从而提升产品竞争力。
传统的压缩方式有低比特量化、知识蒸馏、稀疏化和模型结构搜索等。传统的模型压缩技术门槛比较高,其难度主要来源于三点:模型压缩算法依赖训练过程、调参难度大和依赖部署环境。
相比于传统手工压缩,飞桨提供了模型自动化压缩工具(Auto Compression Toolkit,ACT),具备以下特征:
『解耦训练代码』 :开发者无需了解或修改模型源码,直接使用导出的预测模型进行压缩。
『全流程自动优化』 :开发者简单配置即可启动压缩,ACT 工具会自动优化得到最好预测模型。
『支持丰富压缩算法』 :ACT 提供了量化训练、蒸馏、结构化剪枝、非结构化剪枝、多种离线量化方法及超参搜索等等,可任意搭配使用。
说明:PaddleSlim是一个专注于深度学习模型压缩的工具库,提供低比特量化、知识蒸馏、稀疏化和模型结构搜索等模型压缩策略,帮助开发者快速实现模型的小型化。支持飞桨、PyTorch 等模型的压缩。
1.2 核心技术方案¶
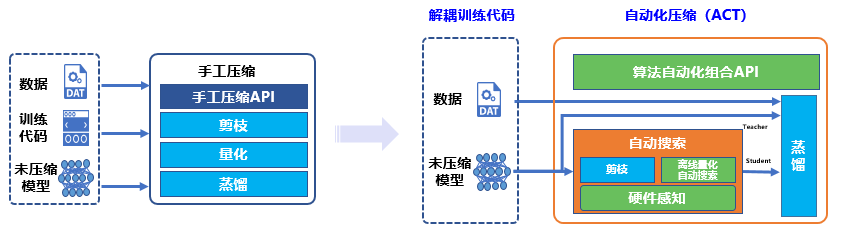
总结来说,相比传统手工压缩,ACT 的“自动”主要体现在 4 个方面:
解耦训练代码
用户只用提供推理模型和无标注数据,就可以执行量化训练、稀疏训练等依赖训练过程的压缩方法。
离线量化超参搜索
实践中发现,不同的业务模型适用不同的离线量化算法。面对多种离线量化算法及其参数的组合,靠人工实验,难以跟上模型迭代的速度。ACT 借助随机森林超参搜索方法改进了离线量化过程,将原来一周的工作量缩短至 1~2 天。
策略自动组合
为了更极致的压缩以取得更好的加速,通常可以将稀疏化方法和量化方法叠加使用。两种方法的叠加效果不仅取决于部署环境,还取决于模型结构。自动压缩功能会分析模型结构,并根据模型结构特点和用户指定的部署环境,自动选择合适的组合算法。
硬件感知 (硬件延时预估)
在选定组合压缩算法后,如何针对每个压缩算法自动调参,则是另一个难点。压缩算法的参数设定与部署环境密切相关,需要考虑芯片特性、推理库的优化程度等各种因素。在模型结构多样化和部署环境多样化的背景下,靠人工经验或简单的公式,无法准确评估压缩参数与推理速度的关系。该功能利用数据表结合深度学习模型的方式,对影响推理速度的因素进行建模,为组合算法的参数设置提供指导信息。
1.3 模型压缩效果展示¶
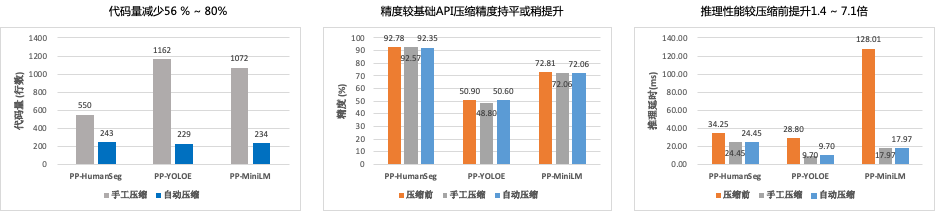
ACT 相比传统的模型压缩方法,具备以下优势:
代码量减少 50% 以上。
压缩精度与手工压缩基本持平。在 PP-YOLOE 模型上,效果优于手动压缩。
自动化压缩后的推理性能收益与手工压缩持平,相比压缩前,推理速度可以提升 1.4~7.1 倍。
模型压缩效果 Benchmark
| 模型类型 | model name | 压缩前 精度(Top1 Acc %) | 压缩后 精度(Top1 Acc %) | 压缩前 推理时延(ms) | 压缩后 推理时延(ms) | 推理 加速比 | 芯片 |
|---|---|---|---|---|---|---|---|
| 图像分类 | MobileNetV1 | 70.90 | 70.57 | 33.15 | 13.64 | 2.43 | SDM865(骁龙 865) |
| 图像分类 | ShuffleNetV2_x1_0 | 68.65 | 68.32 | 10.43 | 5.51 | 1.89 | SDM865(骁龙 865) |
| 图像分类 | SqueezeNet1_0_infer | 59.60 | 59.45 | 35.98 | 16.96 | 2.12 | SDM865(骁龙 865) |
| 图像分类 | PPLCNetV2_base | 76.86 | 76.43 | 36.50 | 15.79 | 2.31 | SDM865(骁龙 865) |
| 图像分类 | ResNet50_vd | 79.12 | 78.74 | 3.19 | 0.92 | 3.47 | NVIDIA Tesla T4 |
| 语义分割 | PPHGNet_tiny | 79.59 | 79.20 | 2.82 | 0.98 | 2.88 | NVIDIA Tesla T4 |
| 语义分割 | PP-HumanSeg-Lite | 92.87 | 92.35 | 56.36 | 37.71 | 1.49 | SDM710 |
| 语义分割 | PP-LiteSeg | 77.04 | 76.93 | 1.43 | 1.16 | 1.23 | NVIDIA Tesla T4 |
| 语义分割 | HRNet | 78.97 | 78.90 | 8.19 | 5.81 | 1.41 | NVIDIA Tesla T4 |
| 语义分割 | UNet | 65.00 | 64.93 | 15.29 | 10.23 | 1.49 | NVIDIA Tesla T4 |
| NLP | PP-MiniLM | 72.81 | 72.44 | 128.01 | 17.97 | 7.12 | NVIDIA Tesla T4 |
| NLP | ERNIE 3.0-Medium | 73.09 | 72.40 | 29.25(fp16) | 19.61 | 1.49 | NVIDIA Tesla T4 |
| 目标检测 | YOLOv5s (PyTorch) | 37.40 | 36.9 | 5.95 | 1.87 | 3.18 | NVIDIA Tesla T4 |
| 目标检测 | YOLOv6s (PyTorch) | 42.4 | 41.3 | 9.06 | 1.83 | 4.95 | NVIDIA Tesla T4 |
| 目标检测 | YOLOv7 (PyTorch) | 51.1 | 50.8 | 26.84 | 4.55 | 5.89 | NVIDIA Tesla T4 |
| 目标检测 | PP-YOLOE-s | 43.1 | 42.6 | 6.51 | 2.12 | 3.07 | NVIDIA Tesla T4 |
| 图像分类 | MobileNetV1 (TensorFlow) | 71.0 | 70.22 | 30.45 | 15.86 | 1.92 | SDMM865(骁龙 865) |
二、模型压缩操作指导¶
本节以 ImageNet 数据集、图像分类任务作为示例,详细描述使用 ACT 进行模型自动压缩的步骤。
2.1 准备工作¶
安装飞桨最新版本:(可以参考飞桨官网安装文档下载安装)
# CPU
pip install paddlepaddle --upgrade
# GPU 以 CUDA11.2 为例
python -m pip install paddlepaddle-gpu.post112 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html
安装 PaddleSlim 最新版本
pip install paddleslim
2.2 操作步骤¶
2.2.1 下载数据集¶
本案例默认以 ImageNet1k 数据进行自动压缩实验,如数据集为非 ImageNet1k 格式数据, 请参考PaddleClas 数据准备文档。将下载好的数据集放在当前目录下./ILSVRC2012。
# 下载 ImageNet 小型数据集
wget https://sys-p0.bj.bcebos.com/slim_ci/ILSVRC2012_data_demo.tar.gz
tar -xf ILSVRC2012_data_demo.tar.gz
2.2.2 准备预测模型¶
预测模型的格式为:model.pdmodel 和 model.pdiparams两个,带pdmodel的是模型文件,带pdiparams后缀的是权重文件。
可在PaddleClas 预训练模型库中直接获取 Inference 模型,具体可参考下方获取 MobileNetV1 模型。也可根据PaddleClas 文档导出 Inference 模型。
**提示:**其他像
__model__和__params__分别对应model.pdmodel和model.pdiparams文件。
# 下载 MobileNet 预测模型
wget https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/inference/MobileNetV1_infer.tar
tar -xf MobileNetV1_infer.tar
2.2.3 导入依赖包及数据处理¶
以下代码首先定义了读取数据的 DataLoader。
DataLoader 传入的数据集是待压缩模型所用的数据集,DataLoader 继承自paddle.io.DataLoader。可以直接使用模型套件中的 DataLoader,或者根据paddle.io.DataLoader自定义所需要的 DataLoader。
# 导入依赖包
import paddle
from PIL import Image
from paddle.vision.datasets import DatasetFolder
from paddle.vision.transforms import transforms
from paddleslim.auto_compression import AutoCompression
paddle.enable_static()
# 定义 DataSet
class ImageNetDataset(DatasetFolder):
def __init__(self, path, image_size=224):
super().__init__(path)
normalize = transforms.Normalize(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.120, 57.375])
self.transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(image_size), transforms.Transpose(),
normalize
])
def __getitem__(self, idx):
img_path, _ = self.samples[idx]
return self.transform(Image.open(img_path).convert('RGB'))
def __len__(self):
return len(self.samples)
# 定义 DataLoader
train_dataset = ImageNetDataset("./ILSVRC2012_data_demo/ILSVRC2012/train/")
image = paddle.static.data(
name='inputs', shape=[None] + [3, 224, 224], dtype='float32')
train_loader = paddle.io.DataLoader(train_dataset, feed_list=[image], batch_size=32, return_list=False)
2.2.4 自动压缩并产出模型¶
调用自动化压缩接口AutoCompression 对模型进行量化训练和蒸馏,配置完成后便可开始自动压缩。
# 开始自动压缩
ac = AutoCompression(
model_dir="./MobileNetV1_infer",
model_filename="inference.pdmodel",
params_filename="inference.pdiparams",
save_dir="MobileNetV1_quant",
config={'Quantization': {}, "HyperParameterOptimization": {'ptq_algo': ['avg'], 'max_quant_count': 3}},
train_dataloader=train_loader,
eval_dataloader=train_loader)
ac.compress()
AutoCompression 接口参数说明:
model_dir:需要压缩的推理模型所在的目录。
model_filename:需要压缩的推理模型文件名称。
params_filename:需要压缩的推理模型参数文件名称。
save_dir:压缩后模型的所保存的目录。
config:自动压缩训练配置。可定义量化、蒸馏、剪枝等压缩算法并合并执行。压缩策略有:量化+蒸馏,剪枝+蒸馏等。本示例选择的配置为离线量化超参搜索。详细解释请点击ACT 参数设置获取。
train_dataloader/eval_dataloader:训练数据迭代器。
eval_dataloader:如果传入测试数据迭代器,则会计算压缩前后模型输出特征的相似性。目前仅离线量化超参搜索支持使用这种方式评估压缩前后模型的精度损失。
压缩训练结束后,会在 output 文件夹中生成:
model.pdiparams:飞桨预测模型权重model.pdmodel:飞桨预测模型文件calibration_table.txt:量化后校准表quant_model.onnx:量化后转出的 ONNX 模型
2.3 测试压缩后的模型¶
2.3.1 测试模型精度¶
测试压缩前模型的精度:
CUDA_VISIBLE_DEVICES=0 python ./image_classification/eval.py
### Eval Top1: 0.7171724759615384
测试压缩后模型的精度:
CUDA_VISIBLE_DEVICES=0 python ./image_classification/eval.py --model_dir='MobileNetV1_quant'### Eval Top1: 0.7166466346153846
对比模型压缩前后 Eval Top1 精度指标发现,模型几乎精度无损。由于是使用的超参搜索的方法来选择的量化参数,所以每次运行得到的量化模型精度会有些许波动。
2.3.2 测试模型速度¶
压缩后模型速度的测试依赖推理库的支持,所以确保安装的是带有 TensorRT 的飞桨框架。以下示例和展示的测试结果是基于 Tesla V100、CUDA 10.2、python3.7 得到的。
使用以下指令查看本地 cuda 版本,并且在下载链接中下载对应 cuda 版本和对应 Python 版本的飞桨框架安装包。
cat /usr/local/cuda/version.txt ### CUDA Version 10.2.89
### 10.2.89 为 cuda 版本号,可以根据这个版本号选择需要安装的带有 TensorRT 的 PaddlePaddle 安装包。
安装下载的 whl 包
注意:
这里通过 wget 下载到的是 python3.7、cuda10.2 的飞桨框架安装包。若您的环境和示例环境不同,请依赖您自己机器的环境下载对应的安装包,否则运行示例代码会报错。
wget https://paddle-inference-lib.bj.bcebos.com/2.3.0/python/Linux/GPU/x86-64_gcc8.2_avx_mkl_cuda10.2_cudnn8.1.1_trt7.2.3.4/paddlepaddle_gpu-2.3.0-cp37-cp37m-linux_x86_64.whl
pip install paddlepaddle_gpu-2.3.0-cp37-cp37m-linux_x86_64.whl --force-reinstall
测试模型速度
准备好 inference 模型后,使用以下命令进行预测:
测试压缩前模型的速度
python infer.py --config_path="configs/infer.yaml"
配置文件:configs/infer.yaml中有以下字段用于配置预测参数:
inference_model_dir:inference 模型文件所在目录,该目录下需要有文件 .pdmodel 和 .pdiparams 两个文件model_filename:inference_model_dir 文件夹下的模型文件名称params_filename:inference_model_dir 文件夹下的参数文件名称batch_size:预测一个 batch 的大小image_size:输入图像的大小use_tensorrt:是否使用 TesorRT 预测引擎use_gpu:是否使用 GPU 预测enable_mkldnn:是否启用MKL-DNN加速库,注意enable_mkldnn与use_gpu同时为True时,将忽略enable_mkldnn,而使用GPU预测use_fp16:是否启用FP16use_int8:是否启用INT8
注意:
请注意模型的输入数据尺寸,如 InceptionV3 输入尺寸为 299,部分模型需要修改参数:
image_size。如果希望提升评测模型速度,使用
GPU评测时,建议开启TensorRT加速预测,使用CPU评测时,建议开启MKL-DNN加速预测。
python ./image_classification/infer.py
### using tensorrt FP32 batch size: 1 time(ms): 0.6140608787536621
测试 FP16 模型的速度
python ./image_classification/infer.py --use_fp16=True
### using tensorrt FP16 batch size: 1 time(ms): 0.5795984268188477
测试 INT8 模型的速度
python ./image_classification/infer.py --model_dir=./MobileNetV1_quant/ --use_int8=True
### using tensorrt INT8 batch size: 1 time(ms): 0.5213963985443115
**提示:**如果要压缩的模型参数是存储在各自分离的文件中,需要先通过convert.py脚本将其保存成一个单独的二进制文件。
2.4 后续处理¶
ACT 可以自动处理常见的预测模型,如果有更特殊的改造需求,可以参考ACT 超参配置教程来进行单独配置压缩策略。
更多场景示例请参考:https://github.com/PaddlePaddle/PaddleSlim/tree/develop/example/auto_compression