纯 GPU 参数服务器¶
1 原理简介¶
在开始使用纯 GPU 参数服务器之前,需要先了解参数服务器的基本知识,详细内容参见参数服务器概述。
1.1 参数服务器解决的问题¶
搜索推荐场景下的模型训练存在以下两大难题:
稀疏参数量大:模型特征稀疏,存在大量称为稀疏参数,通常参数量在百亿级别及以上。
训练数据量大:训练数据量级巨大,单机训练速度过慢。
为解决这些难题,早在 2018 年,飞桨的纯 CPU 参数服务器模式就可以支持万亿规模稀疏参数模型的高效训练,但随着模型中网络结构越来越复杂,纯 CPU 参数服务器的局限性逐步显现。
1.2 传统参数服务器的局限¶
传统参数服务器采用纯 CPU 机器进行训练。在实际工业应用中,存在着以下问题:
CPU 机器算力有瓶颈:利用多台 CPU 机器多核的优势,在简单模型上极大的提升数据吞吐,整体训练达到较好的性能。但是,随着深度学习模型的日渐复杂,在一些计算能力要求高的模型中,计算能力严重不足,模型计算耗时极高。
分布式 CPU 机器成本大:CPU 机器的算力瓶颈可以通过增加 CPU 机器数量来解决,甚至可以增加上百台,但是这种方法不仅成本大幅提高,而且集群的稳定性和扩展性也存在较大的问题。
因此飞桨引入了纯 GPU 参数服务器来提升计算性能,之前 100 台 CPU 机器才能训练的模型,仅需 1 台多卡 GPU 机器即可完成训练。
1.3 纯 GPU 参数服务器的特点¶
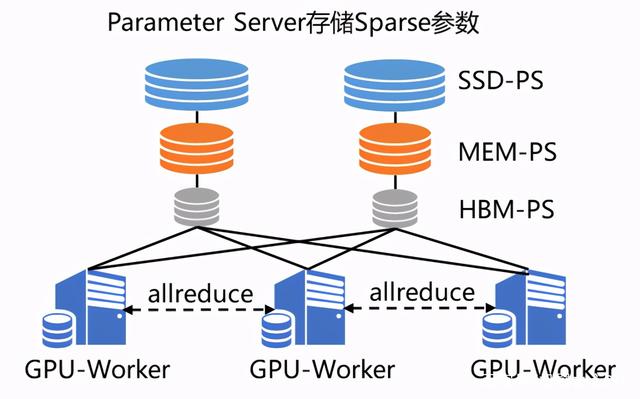
GPU 强大的算力毋庸置疑可以提升集群的计算性能,但随之而来的是,不仅模型规模会受到机器显存和内存的制约,而且通信带宽也会由于集群网卡数量降低而成为瓶颈。
飞桨的纯 GPU 参数服务器引入两大亮点技术解决存储及通信问题:
SSD-MEM-HBM 三级存储:允许全量参数使用 SSD 硬盘存储,高频参数存储于内存,当前 Pass 训练所用参数使用显存,并且同时支持 SSD 的参数在硬盘、内存、显存之间快速拷贝。
RPC&NCCL 混合通信:将部分稀疏参数采用 RPC 协议跨节点通信,其余参数采用卡间 NCCL 方式完成通信,充分利用带宽资源。
2 使用方法¶
本节将采用推荐领域非常经典的 wide&deep 模型为例,介绍纯 GPU 参数服务器训练的使用方法,详细示例代码可参考:GPUPS 示例代码。
在编写分布式训练程序之前,用户需要确保已经安装 PaddlePaddle develop GPU 版本的飞桨开源框架。
纯 GPU 参数服务器训练的基本代码主要包括如下几个部分:
导入分布式训练需要的依赖包并初始化 GPUPS 训练环境。
加载模型。
构建 dataset 加载数据
定义参数更新策略及优化器。
开始训练。
下面将逐一进行讲解。
2.1 依赖导入及环境初始化¶
导入必要的依赖,例如分布式训练专用的 Fleet API(paddle.distributed.fleet)。
import paddle
import paddle.distributed.fleet as fleet
初始化训练环境,包括初始化分布式环境以及构造 GPUPS 对象:
# 当前 GPUPS 模式只支持静态图模式, 因此训练前必须指定 ``paddle.enable_static()``
paddle.enable_static()
# 初始化 fleet 环境
fleet.init()
# 构造 GPUPS 对象
psgpu = paddle.fluid.core.PSGPU()
2.2 加载模型¶
GPUPS 的加载模型部分与 CPUPS 相比无区别。
# 模型定义参考 examples/wide_and_deep_gpups 中 model.py
from model import WideDeepModel
model = WideDeepModel()
model.net(is_train=True)
2.3 构建 dataset 加载数据¶
GPUPS 的数据处理脚本 reader.py 与 CPUPS 相比无区别。
目前 GPUPS 仅支持 InmemoryDataset,并且在 dataset 初始化之前,需要设置 use_ps_gpu=True,框架会根据这个属性,优化 GPUPS 训练过程中加载数据的性能。
# GPUPS 目前仅支持 InMemoryDataset
dataset = paddle.distributed.InMemoryDataset()
# 设置 use_ps_gpu 属性为 True,此操作需要在 dataset.init()之前
dataset._set_use_ps_gpu(True)
# use_var 指定网络中的输入数据,pipe_command 指定数据处理脚本
# 要求 use_var 中输入数据的顺序与数据处理脚本输出的特征顺序一一对应
dataset.init(use_var=model.inputs,
pipe_command="python reader.py",
batch_size=batch_size,
thread_num=thread_num)
train_files_list = [os.path.join(train_data_path, x)
for x in os.listdir(train_data_path)]
# set_filelist 指定 dataset 读取的训练文件的列表
dataset.set_filelist(train_files_list)
# 加载数据到内存
dataset.load_into_memory()
# 执行训练过程
# 训练结束后释放内存
dataset.release_memory()
2.4 定义同步训练 Strategy 及 Optimizer¶
在 Fleet API 中,用户可以使用 fleet.DistributedStrategy() 接口定义自己想要使用的分布式策略。
在 GPUPS 模式下,需要配置 a_sync 选项为 False,同时设置 a_sync_configs 中的 use_ps_gpu 为 True
strategy = fleet.DistributedStrategy()
# 设置 a_sync 为 False
strategy.a_sync = False
# 设置 use_ps_gpu 为 True
strategy.a_sync_configs = {"use_ps_gpu": True}
optimizer = paddle.optimizer.SGD(learning_rate=0.0001)
optimizer = fleet.distributed_optimizer(optimizer, strategy)
optimizer.minimize(model.loss)
2.5 开始训练¶
完成模型及训练策略以后,我们就可以开始训练模型了,GPUPS 同样具有服务器节点和训练节点两种不同的角色。
对于服务器节点,首先用 init_server() 接口对其进行初始化,然后启动服务并开始监听由训练节点传来的梯度。
同样对于训练节点,用 init_worker() 接口进行初始化后, 开始执行训练任务。运行 exe.train_from_dataset() 接口开始训练。
需要注意的是,由于 GPUPS 对稀疏参数的三级存储机制,在训练过程前后需要加入对稀疏参数的拷贝操作:
数据通过 InMemoryDataset 的 load_into_memory()加载到内存后,在 Pass 开始训练之前需要调用
begin_pass()接口,将数据中涉及到的稀疏参数拷贝到显存。Pass 训练结束后,需要调用
end_pass()接口,将显存中更新好的稀疏参数拷贝回内存。
整个训练过程结束后,在调用 stop_worker() 接口停止训练节点前,需要调用 finalize() 接口销毁 GPUPS 环境。
if fleet.is_server():
fleet.init_server()
fleet.run_server()
else:
exe = paddle.static.Executor(paddle.CPUPlace())
exe.run(paddle.static.default_startup_program())
fleet.init_worker()
psgpu = paddle.fluid.core.PSGPU()
# 创建 dataset 并将数据加载到内存
dataset.load_into_memory()
# Pass 开始前调用 begin_pass()将稀疏参数拷贝到显存
psgpu.begin_pass()
for epoch_id in range(1):
exe.train_from_dataset(paddle.static.default_main_program(),
dataset,
paddle.static.global_scope(),
debug=False,
fetch_list=[model.loss],
fetch_info=["loss"],
print_period=1)
# Pass 结束后调用 end_pass()将显存中更新好的稀疏参数拷贝回内存
psgpu.end_pass()
# 释放 dataset 数据
dataset.release_memory()
# 训练结束销毁 psgpu
psgpu.finalize()
fleet.stop_worker()