模型保存与加载¶
模型训练后,训练好的模型参数保存在内存中,通常需要使用模型保存(save)功能将其持久化保存到磁盘文件中,并在后续需要训练调优或推理部署时,再加载(load)到内存中运行。本章详细介绍不同场景下模型保存与加载的方法。
一、概述¶
在模型训练过程中,通常会在如下场景中用到模型的保存与加载功能:
训练调优场景:
模型训练过程中定期保存模型,以便后续对不同时期的模型恢复训练或进行研究;
模型训练完毕,需要保存模型方便进行评估测试;
载入预训练模型,并对模型进行微调(fine-tune)。
推理部署场景:
模型训练完毕,在云、边、端不同的硬件环境中部署使用,飞桨提供了服务器端部署的 Paddle Inference、移动端/IoT端部署的 Paddle Lite、服务化部署的 Paddle Serving 等,以实现模型的快速部署上线。
针对以上场景,飞桨框架推荐使用的模型保存与加载基础 API 主要包括:
模型保存与加载高层 API 主要包括:
注:在深度学习模型构建上,飞桨框架同时支持动态图编程和静态图编程,由于动态图编程采用 Python 的编程风格,解析式地执行每一行网络代码,并同时返回计算结果,编程体验更佳、更易调试,因此飞桨框架推荐采用动态图进行模型开发,本章之前均介绍的是动态图的模型开发、训练方法。下文中先介绍推荐使用的动态图模型的保存和加载方法。
二、用于训练调优场景¶
2.1 保存和加载机制介绍¶
如下图所示,动态图模式下,模型结构指的是 Python 前端组网代码;模型参数主要指网络层 Layer.state_dict() 和优化器 Optimizer.state_dict()中存放的参数字典。state_dict()中存放了模型参数信息,包括所有可学习的和不可学习的参数(parameters 和 buffers),从网络层(Layer)和优化器(Optimizer)中获取,以字典形式存储,key 为参数名,value 为对应参数数据(Tensor)。
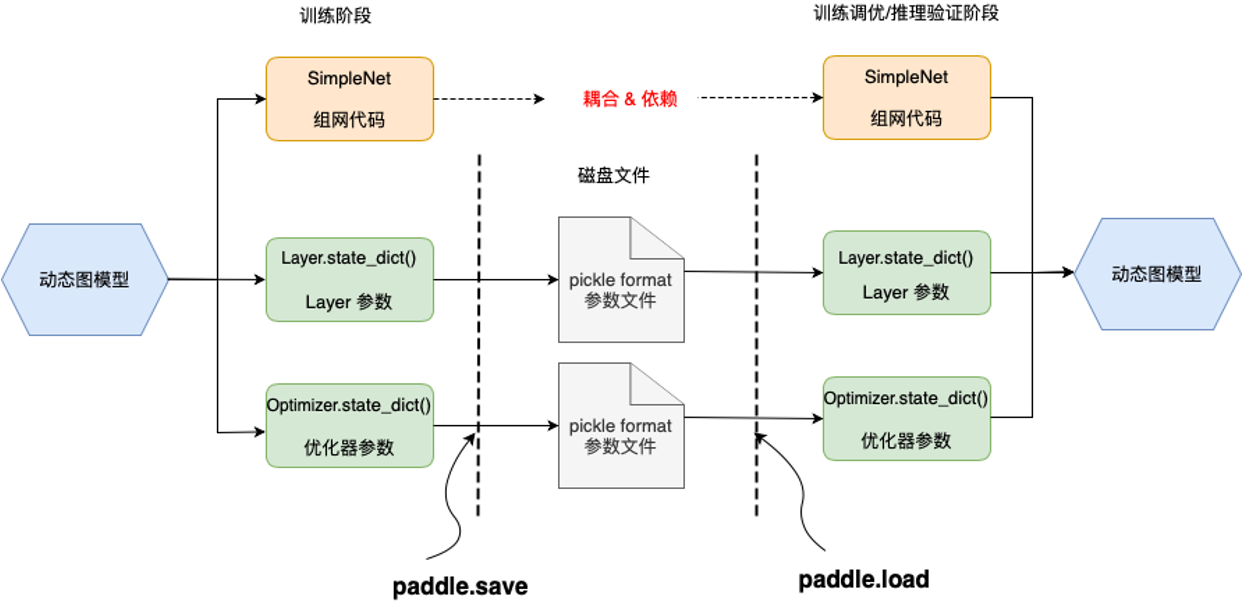
paddle.save:使用
paddle.save保存模型,实际是通过 Python pickle 模块来实现的,传入要保存的数据对象后,会在指定路径下生成一个 pickle 格式的磁盘文件。paddle.load:加载时还需要之前的模型组网代码,并使用
paddle.load传入保存的文件路径,即可重新将之前保存的数据从磁盘文件中载入。
另外,paddle.save还支持直接保存 Tensor 数据,或者含 Tensor 的 list/dict 嵌套结构。所以动态图模式下,可支持保存和加载的内容包括:
网络层参数:
Layer.state_dict()优化器参数:
Optimizer.state_dict()Tensor 数据 :(如创建的 Tensor 数据、网络层的 weight 数据等)
含 Tensor 的 list/dict 嵌套结构对象 (如保存 state_dict() 的嵌套结构对象:
obj = {'model': layer.state_dict(), 'opt': adam.state_dict(), 'epoch': 100})
如果使用高层 API,需预先将模型定义为 paddle.Model 实例,后续的训练、模型保存/加载、预测等功能都需要该实例来调用各 API。模型的保存和加载使用 paddle.Model.save 和 paddle.Model.load 这一对,它们的底层实现与基础 API 类似。
2.2 使用基础 API¶
结合以下简单示例,介绍参数保存和载入的方法,以下示例完成了一个简单网络的训练过程:
注:如果要在训练过程中保存模型参数,通常叫保存检查点(checkpoint),需在训练过程中自行设置保存检查点的代码,如设置定时每几个 epoch 保存一个检查点,设置保存精度最高的检查点等,如下示例代码中设置了在最后一个 epoch 保存检查点的代码。
import numpy as np
import paddle
import paddle.nn as nn
import paddle.optimizer as opt
BATCH_SIZE = 16
BATCH_NUM = 4
EPOCH_NUM = 4
IMAGE_SIZE = 784
CLASS_NUM = 10
final_checkpoint = dict()
# 定义一个随机数据集
class RandomDataset(paddle.io.Dataset):
def __init__(self, num_samples):
self.num_samples = num_samples
def __getitem__(self, idx):
image = np.random.random([IMAGE_SIZE]).astype('float32')
label = np.random.randint(0, CLASS_NUM - 1, (1, )).astype('int64')
return image, label
def __len__(self):
return self.num_samples
class LinearNet(nn.Layer):
def __init__(self):
super(LinearNet, self).__init__()
self._linear = nn.Linear(IMAGE_SIZE, CLASS_NUM)
def forward(self, x):
return self._linear(x)
def train(layer, loader, loss_fn, opt):
for epoch_id in range(EPOCH_NUM):
for batch_id, (image, label) in enumerate(loader()):
out = layer(image)
loss = loss_fn(out, label)
loss.backward()
opt.step()
opt.clear_grad()
print("Epoch {} batch {}: loss = {}".format(
epoch_id, batch_id, np.mean(loss.numpy())))
# 最后一个epoch保存检查点checkpoint
if epoch_id == EPOCH_NUM - 1:
final_checkpoint["epoch"] = epoch_id
final_checkpoint["loss"] = loss
# 创建网络、loss和优化器
layer = LinearNet()
loss_fn = nn.CrossEntropyLoss()
adam = opt.Adam(learning_rate=0.001, parameters=layer.parameters())
# 创建用于载入数据的DataLoader
dataset = RandomDataset(BATCH_NUM * BATCH_SIZE)
loader = paddle.io.DataLoader(dataset,
batch_size=BATCH_SIZE,
shuffle=True,
drop_last=True,
num_workers=2)
# 开始训练
train(layer, loader, loss_fn, adam)
2.2.1 保存动态图模型¶
参数保存时,先获取目标对象(Layer 或者 Optimzier)的 state_dict,然后将 state_dict 保存至磁盘,同时也可以保存模型训练 checkpoint 的信息,保存的 checkpoint 的对象已在上文示例代码中进行了设置,保存代码如下(接上文示例代码):
# 保存Layer参数
paddle.save(layer.state_dict(), "linear_net.pdparams")
# 保存优化器参数
paddle.save(adam.state_dict(), "adam.pdopt")
# 保存检查点checkpoint信息
paddle.save(final_checkpoint, "final_checkpoint.pkl")
注:
paddle.save的文件名称是自定义的,以输入参数path(如 "linear_net.pdparams")直接作为存储结果的文件名。为了便于辩识,我们推荐使用统一的标椎文件后缀:
对于
Layer.state_dict()(模型参数),推荐使用后缀.pdparams;对于
Optimizer.state_dict()(优化器参数),推荐使用后缀.pdopt。
2.2.2 加载动态图模型¶
参数载入时,先从磁盘载入保存的 state_dict,然后通过 set_state_dict()方法将 state_dict 配置到目标对象中。另外载入之前保存的 checkpoint 信息并打印出来,示例如下(接上文示例代码):
# 载入模型参数、优化器参数和最后一个epoch保存的检查点
layer_state_dict = paddle.load("linear_net.pdparams")
opt_state_dict = paddle.load("adam.pdopt")
final_checkpoint_dict = paddle.load("final_checkpoint.pkl")
# 将load后的参数与模型关联起来
layer.set_state_dict(layer_state_dict)
adam.set_state_dict(opt_state_dict)
# 打印出来之前保存的 checkpoint 信息
print("Loaded Final Checkpoint. Epoch : {}, Loss : {}".format(final_checkpoint_dict["epoch"], final_checkpoint_dict["loss"].numpy()))
加载以后就可以继续对动态图模型进行训练调优(fine-tune),或者验证预测效果(predict)。
2.3 使用高层 API¶
下面结合简单示例,介绍高层 API 模型保存和载入的方法。
2.3.1 保存动态图模型¶
以下示例完成了一个简单网络的训练和保存动态图模型的过程,示例后介绍保存动态图模型的两种方式:
import paddle
import paddle.nn as nn
import paddle.vision.transforms as T
from paddle.vision.models import LeNet
model = paddle.Model(LeNet())
optim = paddle.optimizer.SGD(learning_rate=1e-3,
parameters=model.parameters())
model.prepare(optim, paddle.nn.CrossEntropyLoss())
transform = T.Compose([
T.Transpose(),
T.Normalize([127.5], [127.5])
])
data = paddle.vision.datasets.MNIST(mode='train', transform=transform)
#方式一:设置训练过程中保存模型
model.fit(data, epochs=1, batch_size=32, save_freq=1)
#方式二:设置训练后保存模型
model.save('checkpoint/test') # save for training
方式一:开启训练时调用的
paddle.Model.fit函数可自动保存模型,通过它的参数save_freq可以设置保存动态图模型的频率,即多少个 epoch 保存一次模型,默认值是 1。方式二:调用
paddle.Model.saveAPI。只需要传入保存的模型文件的前缀,格式如dirname/file_prefix或者file_prefix,即可保存训练后的模型参数和优化器参数,保存后的文件后缀名固定为.pdparams和.pdopt。
2.3.2 加载动态图模型¶
高层 API 加载动态图模型所需要调用的 API 是 paddle.Model.load,从指定的文件中载入模型参数和优化器参数(可选)以继续训练。paddle.Model.load需要传入的核心的参数是待加载的模型参数或者优化器参数文件(可选)的前缀(需要保证后缀符合 .pdparams 和.pdopt)。
假设上面的示例代码已经完成了参数保存过程,下面的例子会加载上面保存的参数以继续训练:
import paddle
import paddle.nn as nn
import paddle.vision.transforms as T
from paddle.vision.models import LeNet
model = paddle.Model(LeNet())
optim = paddle.optimizer.SGD(learning_rate=1e-3,
parameters=model.parameters())
model.prepare(optim, paddle.nn.CrossEntropyLoss())
transform = T.Compose([
T.Transpose(),
T.Normalize([127.5], [127.5])
])
data = paddle.vision.datasets.MNIST(mode='train', transform=transform)
# 加载模型参数和优化器参数
model.load('checkpoint/test')
model.fit(data, epochs=1, batch_size=32, save_freq=1)
model.save('checkpoint/test_1') # save for training
三、用于推理部署场景¶
由于动态图模型采用 Python 实时执行的方式,开销较大,在性能方面与 C++ 有一定差距;静态图模型将前端 Python 编写的神经网络预定义为 Program 描述,转到 C++ 端重新解析执行,脱离了 Python 依赖,往往执行性能更佳,并且预先拥有完整网络结构也更利于全局优化,在推理部署场景有天然的优势。
因此在飞桨框架中,动态图模型训练完成后,为了在部署场景中获得更好的推理性能,提供了自动将动态图模型保存为静态图模型的功能,主要使用的保存和加载 API 是 paddle.jit.save 和 paddle.jit.load。
3.2 使用高层 API¶
高层 API paddle.Model.save可支持保存推理使用的模型,此时高层 API 在动态图下实际上是对paddle.jit.save的封装,在静态图下是对 paddle.static.save_inference_model的封装,会自动将训练好的动态图模型保存为静态图模型。
paddle.Model.save的第一个参数需要设置为待保存的模型和参数等文件的前缀名,第二个参数 training 表示是否保存动态图模型以继续训练,默认是 True,这里需要设为 False,即保存推理部署所需的参数与文件。接前文高层 API 训练的示例代码,保存推理模型代码示例如下:
model.save('inference_model', False) # save for inference
执行上述代码样例后,会在当前目录下生成三个文件,即代表成功导出可用于推理部署的静态图模型:
inference_model.pdiparams // 存放模型中所有的权重数据
inference_model.pdmodel // 存放模型的网络结构
inference_model.pdiparams.info // 存放和参数状态有关的额外信息
四、其他场景¶
4.1 旧版本格式兼容载入¶
如果你是从飞桨框架 1.x 切换到 2.1及以上 版本,曾经使用飞桨框架 1.x 的 fluid 相关接口保存模型或者参数,飞桨框架 2.1 及以上 版本也对这种情况进行了兼容性支持,请参考 兼容载入旧格式模型。
4.2 静态图模型的保存与加载¶
在静态图模型中,对应模型结构的部分为可持久化的 Program,可以保存为磁盘文件(这点不同于动态图),模型参数与动态图类似,也是用 state_dict 获取,是个状态字典,key 为参数名,value 为参数真实的值。
若仅需要保存/载入模型的参数用于训练调优场景,可以使用
paddle.save/paddle.load结合静态图模型 Program 的 state_dict 达成目的。也支持保存整个模型,可以使用paddle.save将 Program 和state_dict 都保存下来。高层 API 兼容了动态图和静态图,因此Paddle.Model.save和Paddle.Model.load也兼容了动、静态图的保存和加载。若需保存推理模型用于模型部署场景,则可以通过
paddle.static.save_inference_model、paddle.static.load_inference_model实现。
4.2.1 训练调优场景¶
结合以下简单示例,介绍参数保存和载入的方法:
import paddle
import paddle.static as static
# 开启静态图模式
paddle.enable_static()
# 创建输入数据和网络
x = paddle.static.data(name="x", shape=[None, 224], dtype='float32')
z = paddle.static.nn.fc(x, 10)
# 设置执行器开始训练
place = paddle.CPUPlace()
exe = paddle.static.Executor(place)
exe.run(paddle.static.default_startup_program())
prog = paddle.static.default_main_program()
如果只想保存模型的参数,先获取 Program 的 state_dict,然后将 state_dict 保存至磁盘,示例如下(接上文示例):
# 保存模型参数
paddle.save(prog.state_dict(), "temp/model.pdparams")
如果想要保存整个静态图模型(含模型结构和参数),除了 state_dict 还需要保存 Program(接上文示例):
# 保存模型结构(program)
paddle.save(prog, "temp/model.pdmodel")
模型载入阶段,如果只保存了 state_dict,可以跳过下面此段代码,直接载入 state_dict。如果模型文件中包含 Program 和 state_dict,请先载入 Program,示例如下(接上文示例):
# 载入模型结构(program)
prog = paddle.load("temp/model.pdmodel")
参数载入时,先从磁盘载入保存的 state_dict,然后通过 set_state_dict()方法配置到 Program 中,示例如下(接上文示例):
# 载入模型参数
state_dict = paddle.load("temp/model.pdparams")
# 将load后的参数与模型program关联起来
prog.set_state_dict(state_dict)
4.2.2 推理部署场景¶
保存/载入静态图推理模型,可以通过 paddle.static.save_inference_model、paddle.static.load_inference_model实现。结合以下简单示例,介绍参数保存和载入的方法,示例如下:
import paddle
import numpy as np
# 开启静态图模式
paddle.enable_static()
# 创建输入数据和网络
startup_prog = paddle.static.default_startup_program()
main_prog = paddle.static.default_main_program()
with paddle.static.program_guard(main_prog, startup_prog):
image = paddle.static.data(name="img", shape=[64, 784])
w = paddle.create_parameter(shape=[784, 200], dtype='float32')
b = paddle.create_parameter(shape=[200], dtype='float32')
hidden_w = paddle.matmul(x=image, y=w)
hidden_b = paddle.add(hidden_w, b)
# 设置执行器开始训练
exe = paddle.static.Executor(paddle.CPUPlace())
exe.run(startup_prog)
静态图导出推理模型需要指定导出路径、输入、输出变量以及执行器。paddle.static.save_inference_model 会裁剪 Program 的冗余部分,并导出两个文件: path_prefix.pdmodel、path_prefix.pdiparams 。示例如下(接上文示例):
# 保存静态图推理模型
path_prefix = "./infer_model"
paddle.static.save_inference_model(path_prefix, [image], [hidden_b], exe)
载入静态图推理模型时,输入给 paddle.static.load_inference_model 的路径必须与 save_inference_model 的一致。示例如下(接上文示例):
# 载入静态图推理模型
[inference_program, feed_target_names, fetch_targets] = (
paddle.static.load_inference_model(path_prefix, exe))
tensor_img = np.array(np.random.random((64, 784)), dtype=np.float32)
results = exe.run(inference_program,
feed={feed_target_names[0]: tensor_img},
fetch_list=fetch_targets)
五、总结¶
飞桨框架同时支持动态图和静态图,优先推荐使用动态图训练,兼容支持静态图。
如果用于训练调优场景,动态图和静态图均使用
paddle.save和paddle.load保存和加载模型参数,或者在高层 API 训练场景下使用paddle.Model.save和paddle.Model.load。如果用于推理部署场景,动态图模型需先转为静态图模型再保存,使用
paddle.jit.save和paddle.jit.load保存和加载模型结构和参数;静态图模型直接使用paddle.static.save_inference_model和paddle.static.load_inference_model保存和加载模型结构和参数。