原理和实践案例¶
数据并行是深度学习领域最常用的并行方法。在此策略下数据集被平均分为多份,每个卡上保存完整的模型参数并独立处理一份子数据集,以加速模型训练过程。
一、原理介绍¶
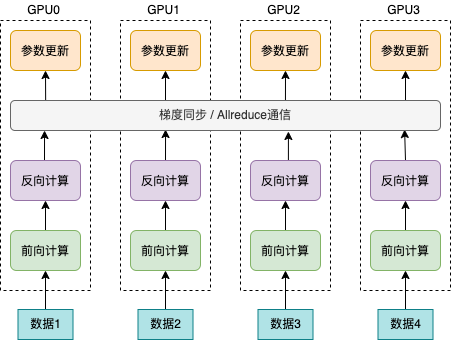
深度学习模型训练过程计算通常分为前向计算、反向计算和梯度更新。由于各个计算设备的初始随机状态不同,各个计算设备上的初始模型参数也因此存在差异。数据并行方式下,为了保持各个计算设备上参数的一致性,在初始阶段需要通过广播的方式将第一张计算设备上的模型参数广播到其它所有计算设备。这样,各个计算设备上的模型参数在广播完成后是一致的。前向计算阶段,各个计算设备使用自己的数据计算模型损失值。由于各个计算设备读取的数据不同,因此各个计算设备上得到的模型损失值也往往是不同的。反向计算阶段,各个计算设备根据其前向计算得到的损失值计算梯度,使用 AllReduce 操作逐个累加每个参数在所有计算设备上的梯度值,并计算累积梯度的平均值,从而确保各个计算设备上用于更新参数的梯度值是相同的。参数更新阶段,使用梯度平均值更新参数。整个计算过程如下图所示。
由于在训练起始阶段,通过广播操作确保了各个计算设备上的参数一致性;反向阶段,各个计算设备上使用相同的梯度均值更新参数;因此,可以保证训练过程中各个计算设备上的参数值始终是一致的。
数据并行训练主要包括以下两种方式。
各个卡的批处理大小(batch size)和单卡训练保持一致。假设单卡的批处理大小为
B,数据并行训练使用的卡数为K。那么,数据并行方式下,单次迭代处理的数据量为KB。在理想情形下,数据并行训练的吞吐量是单卡训练的K倍。但实际情形下,分布式训练引入了额外的通信和计算开销,如累积各个卡上梯度值并计算平均值。这种额外的通信开销和计算开销通常较小。因此,数据并行训练相比于单卡训练的吞吐量更高,加速比通常略小于K。各个卡的批处理大小总和与单卡训练的批处理大小一致。那么,分布式训练方式下,各个卡的批处理大小为
B/K。因此,分布式训练方式下,每次迭代的时间均明显小于单卡训练,从而在整体上提高训练吞吐量。
二、动态图使用方法¶
与单机单卡的普通模型训练相比,数据并行训练代码只需要补充以下四个部分:
导入依赖包。
初始化分布式环境。
设置模型、优化器。
设置批采样器。
下面将逐一进行讲解。
2.1 导入依赖包¶
导入必要的依赖,例如分布式训练专用的 Fleet API(paddle.distributed.fleet)。
from paddle.distributed import fleet
from paddle.io import DistributedBatchSampler
2.2 初始化分布式环境¶
包括定义缺省的分布式策略,然后通过将参数 is_collective 设置为 True,使训练架构设定为 Collective 架构。
strategy = fleet.DistributedStrategy()
fleet.init(is_collective=True, strategy=strategy)
2.3 设置模型、优化器¶
使用 Fleet API 设置分布式训练需要的模型和优化器。
model = fleet.distributed_model(model)
optimizer = fleet.distributed_optimizer(optimizer)
2.4 设置批采样器¶
使用 DistributedBatchSampler 设置数据并行训练需要的分布式批采样器,并传递给 DataLoader ,使得每个进程加载原始数据的一个子集。
dataset = RandomDataset(batch_num * batch_size)
sampler = DistributedBatchSampler(dataset,
rank=get_rank(),
batch_size=batch_size,
shuffle=False,
drop_last=True,)
train_loader = DataLoader(dataset,
batch_sampler=sampler,
num_workers=1)
三、动态图运行示例¶
本节给出一个分布式任务的完整训练代码和部分训练日志。它使用了动态图数据并行策略,并通过 paddle.distributed.launch 组件启动。
3.1 完整训练代码¶
动态图完整训练代码如下所示(train.py),只需添加高亮部分代码,即可将单卡训练扩展为分布式训练:
# -*- coding: UTF-8 -*-
import numpy as np
import paddle
# 导入必要分布式训练的依赖包
from paddle.distributed import fleet, get_rank
# 导入模型文件
from paddle.vision.models import ResNet
from paddle.vision.models.resnet import BottleneckBlock
from paddle.io import Dataset, DistributedBatchSampler, DataLoader
base_lr = 0.1 # 学习率
momentum_rate = 0.9 # 冲量
l2_decay = 1e-4 # 权重衰减
epoch = 10 #训练迭代次数
batch_num = 100 #每次迭代的 batch 数
batch_size = 32 #训练批次大小
class_dim = 102
# 设置数据读取器
class RandomDataset(Dataset):
def __init__(self, num_samples):
self.num_samples = num_samples
def __getitem__(self, idx):
image = np.random.random([3, 224, 224]).astype('float32')
label = np.random.randint(0, class_dim - 1, (1, )).astype('int64')
return image, label
def __len__(self):
return self.num_samples
# 设置优化器
def optimizer_setting(parameter_list=None):
optimizer = paddle.optimizer.Momentum(
learning_rate=base_lr,
momentum=momentum_rate,
weight_decay=paddle.regularizer.L2Decay(l2_decay),
parameters=parameter_list)
return optimizer
# 设置训练函数
def train_model():
# 初始化 Fleet 环境
fleet.init(is_collective=True)
model = ResNet(BottleneckBlock, 50, num_classes=class_dim)
optimizer = optimizer_setting(parameter_list=model.parameters())
# 通过 Fleet API 获取分布式 model,用于支持分布式训练
model = fleet.distributed_model(model)
optimizer = fleet.distributed_optimizer(optimizer)
dataset = RandomDataset(batch_num * batch_size)
# 设置分布式批采样器,用于数据并行训练
sampler = DistributedBatchSampler(dataset, rank=get_rank(),
batch_size=batch_size,shuffle=False, drop_last=True)
train_loader = DataLoader(dataset,
batch_sampler=sampler,
num_workers=1)
for eop in range(epoch):
model.train()
for batch_id, data in enumerate(train_loader()):
img, label = data
label.stop_gradient = True
out = model(img)
loss = paddle.nn.functional.cross_entropy(input=out, label=label)
avg_loss = paddle.mean(x=loss)
acc_top1 = paddle.metric.accuracy(input=out, label=label, k=1)
acc_top5 = paddle.metric.accuracy(input=out, label=label, k=5)
avg_loss.backward()
optimizer.step()
model.clear_gradients()
if batch_id % 5 == 0:
print("[Epoch %d, batch %d] loss: %.5f, acc1: %.5f, acc5: %.5f" % (eop, batch_id, avg_loss, acc_top1, acc_top5))
# 启动训练
if __name__ == '__main__':
train_model()
3.2 运行方式¶
飞桨分布式任务可以通过 paddle.distributed.launch 组件启动。假设要运行 2 卡任务,只需在命令行中执行:
python -m paddle.distributed.launch --gpus=0,1 --log_dir logs train.py
您将在 logs 路径下看到 2 份日志文件,即 workerlog.0 和 workerlog.1,分别记录着 gpu0 和 gpu1 的运行信息。
四、数据并行使用技巧¶
本节给出一些常见的数据并行技巧。在实际使用中,用户需要根据实际业务需要,灵活处理。
4.1 学习率设置¶
首先,阐述数据并行模式下学习率的设置技巧,其基本原则是学习率正比于 global batch size。
与单卡训练相比,数据并行训练通常有两种配置: 1. 一种是保持保持所有计算设备的 batch size 的总和(我们称为 global batch size)与单卡训练的 batch size 保持一致。这中情形下,由于数据并行训练和单卡训练的 global batch size 是一致的,通常保持数据并行模式下各个计算设备上的学习率与单卡训练一致。 2. 另一种情形是,保持数据并行模式下每个计算设备的 batch size 和单卡训练的 batch size 一致。这种情形下,数据并行模式的 global batch size 是单卡训练的 N 倍。这里, N 指的是数据并行计算的设备数。因此,通常需要将数据并行模式下每个计算设备的学习率相应的设置为单卡训练的 N 倍。这样,数据并行模式下的初始学习率通常较大,不利于模型的收敛。因此,通常需要使用 warm-up 机制。即,在初始训练时使用较小的学习率,并逐步缓慢增加学习率,经过一定迭代次数后,学习率增长到期望的学习率。
4.2 数据集切分¶
接着,介绍数据集切分问题。数据并行中,我们通常将数据集切分为 N 份,每个训练卡负责训练其中的一份数据。这里, N 是数据并行的并行度。如我们前面介绍的,每一个迭代中,各个训练卡均需要做一次梯度同步。因此,我们需要确保对于每个 epoch ,各个训练卡经历相同的迭代数,否则,运行迭代数多的训练卡会一直等待通信完成。实践中,我们通常通过数据补齐或者丢弃的方式保证各个训练卡经历相同的迭代数。数据补齐的方式指的是,为某些迭代数少训练数据补充部分数据,从而保证切分后的各份数据集的迭代次数相同;丢弃的方式则是丢弃部分迭代次数较多的数据,从而保证各份数据集的迭代次数相同。
通常,在每个 epoch 需要对数据做 shuffle 处理。因此,根据 shuffle 时机的不同,有两种数据切分的方法。一种是在数据切分前做 shuffle;即,首先对完整的数据做 shuffle 处理,做相应的数据补充或丢弃,然后做数据的切分。另一种是在数据切分后做 shuffle;即,首先做数据的补充或丢弃和数据切分,然后对切分后的每一份数据分别做 shuffle 处理。