转换原理¶
在飞桨框架内部,动转静模块在转换上主要包括对输入数据的 InputSpec 的处理,对函数调用的递归转写,对 IfElse、For、While 控制语句的转写,以及 Layer 的 Parameters 和 Buffers 变量的转换。下面将介绍动转静模块的转换过程。
一、 概述¶
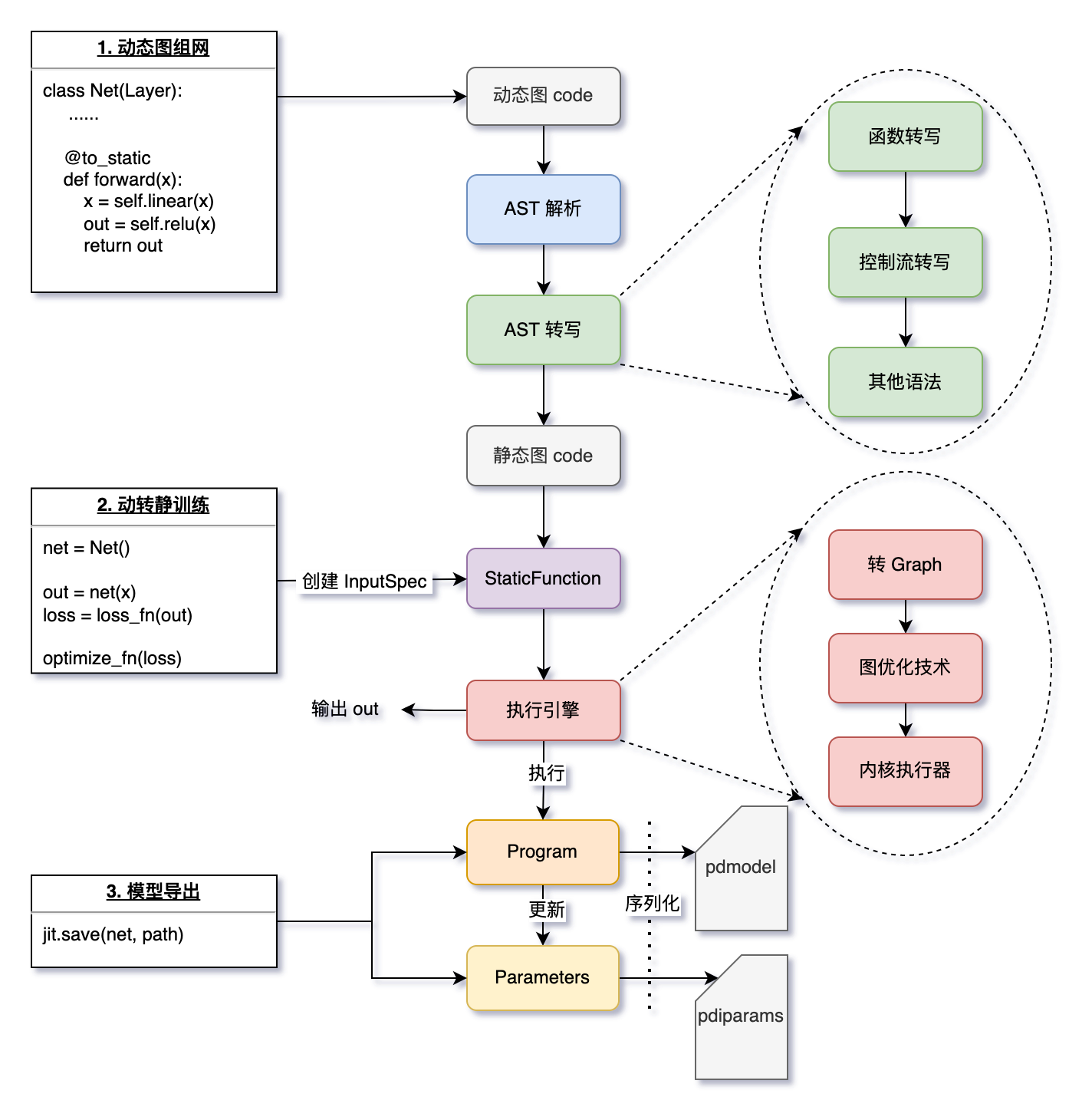
上图是动转静转换和训练执行的基本流程:
AST 解析动态图代码
当某个函数被
@to_static装饰、或用paddle.jit.to_static()包裹时,飞桨会隐式地解析动态图的 Python 代码(即解析:抽象语法树,简称 AST)。
AST 转写,得到静态图代码
函数转写:递归地对所有函数进行转写,实现用户仅需在最外层函数添加 @to_static 的体验效果。
控制流转写:用户的代码中可能包含依赖 Tensor 的控制流代码,飞桨框架会自动且有选择性地将 if、for、while 转换为静态图对应的控制流。
其他语法处理:包括 break、continue、assert、提前 return 等语法的处理。
生成静态图的 Program 和 Parameters
得到静态图代码后,根据用户指定的
InputSpec信息(或训练时根据实际输入 Tensor 隐式创建的 InputSpec)作为输入,执行静态图代码生成 Program。每个被装饰的函数,都会被替换为一个 StaticFunction 对象,其持有此函数对应的计算图 Program,在执行paddle.jit.save时会被用到。对于
trainable=True的 Buffers 变量,动转静会自动识别并将其和 Parameters 一起保存到.pdiparams文件中。
执行动转静训练
使用执行引擎执行函数对应的 Program,返回输出 out。
执行时会根据用户指定的 build_strategy 策略应用图优化技术,提升执行效率。
使用
paddle.jit.save保存静态图模型使用
paddle.jit.save时会遍历模型 net 中所有的函数,将每个的 StaticFunction 中的计算图 Program 和涉及到的 Parameters 序列化为磁盘文件。
二、设置输入数据的 InputSpec 信息¶
InputSpec 用于表示模型输入数据的 shape、dtype、name 信息,是辅助动静转换的必要描述信息。
在静态图模式下,飞桨框架会将神经网络描述为 Program 的数据结构,并对 Program 进行编译优化,再调用执行器获得计算结果。可以看到静态图模式下运行,在调用执行器前并不执行实际操作(这个阶段一般称为“组网阶段”或者“编译阶段”),因此也并不读入实际数据,所以在静态图中还需要一种特殊的变量来表示输入数据,一般称为“占位符”,动转静提供了 InputSpec 接口配置该“占位符”,用于表示输入数据的描述信息。
如下静态图的示例代码中,模型的 “占位符” 信息是通过 paddle.static.data 来指定的,并以此作为编译期的 InferShape 推导起点,即用于推导输出 Tensor 的 shape。
import paddle
# 开启静态图模式
paddle.enable_static()
# placeholder 信息
x = paddle.static.data(shape=[None, 10], dtype='float32', name='x')
y = paddle.static.data(shape=[None, 3], dtype='float32', name='y')
out = paddle.static.nn.fc(x, 3)
out = paddle.add(out, y)
动转静代码示例,通过 InputSpec 设置 “占位符” 信息:
import paddle
from paddle.jit import to_static
from paddle.static import InputSpec
class SimpleNet(paddle.nn.Layer):
def __init__(self):
super(SimpleNet, self).__init__()
self.linear = paddle.nn.Linear(10, 3)
def forward(self, x, y):
out = self.linear(x)
out = out + y
return out
net = SimpleNet()
# 通过 InputSpec 设置 Placeholder 信息
x_spec = InputSpec(shape=[None, 10], name='x')
y_spec = InputSpec(shape=[3], name='y')
net = paddle.jit.to_static(net, input_spec=[x_spec, y_spec]) # 动静转换
在导出模型时,需要显式地指定输入 Tensor 的签名信息,优势是:
可以指定某些维度为
None, 如batch_size,seq_len维度可以指定 Placeholder 的
name,方便预测时根据name输入数据
注:
InputSpec接口的详细用法,请参见 InputSpec 的用法介绍。
三、动转静代码转写(AST 转写)¶
3.1 函数转写¶
在 NLP、CV 领域中,一个模型常包含层层复杂的子函数调用,动转静中是如何实现只需装饰最外层的 forward 函数,就能递归处理所有的函数。
如下是一个模型样例:
import paddle
from paddle.jit import to_static
class SimpleNet(paddle.nn.Layer):
def __init__(self):
super(SimpleNet, self).__init__()
self.linear = paddle.nn.Linear(10, 3)
@to_static
def forward(self, x, y):
out = self.my_fc(x) # <---- self.other_func
out = add_two(out, y) # <---- other plain func
return out
def my_fc(self, x):
out = self.linear(x)
return out
# 此函数可以在任意文件
def add_two(x, y):
out = x + y
return out
net = SimpleNet()
# 查看转写的代码内容
paddle.jit.set_code_level(100)
x = paddle.zeros([2,10], 'float32')
y = paddle.zeros([3], 'float32')
out = net(x, y)
可以通过 paddle.jit.set_code_level(100) 在执行时打印代码转写的结果到终端,转写代码如下:
def forward(self, x, y):
out = paddle.jit.dy2static.convert_call(self.my_fc)(x)
out = paddle.jit.dy2static.convert_call(add_two)(out, y)
return out
def my_fc(self, x):
out = paddle.jit.dy2static.convert_call(self.linear)(x)
return out
def add_two(x, y):
out = x + y
return out
如上所示,所有的函数调用都会被转写如下形式:
out = paddle.jit.dy2static.convert_call( self.my_fc )( x )
^ ^ ^ ^
| | | |
返回列表 convert_call 原始函数 参数列表
即使函数定义分布在不同的文件中, convert_call 函数也会递归地处理和转写所有嵌套的子函数。
3.2 控制流转写¶
控制流 if/for/while 的转写和处理是动转静中比较重要的模块,也是动态图模型和静态图模型实现上差别最大的一部分。如下图所示,对于控制流的转写分为两个阶段:转写期和执行期。在转写期,动转静模块将控制流语句转写为统一的形式;在执行期,根据控制流是否依赖 Tensor 来决定是否将控制流转写为相应的 cond_op/while_op 。
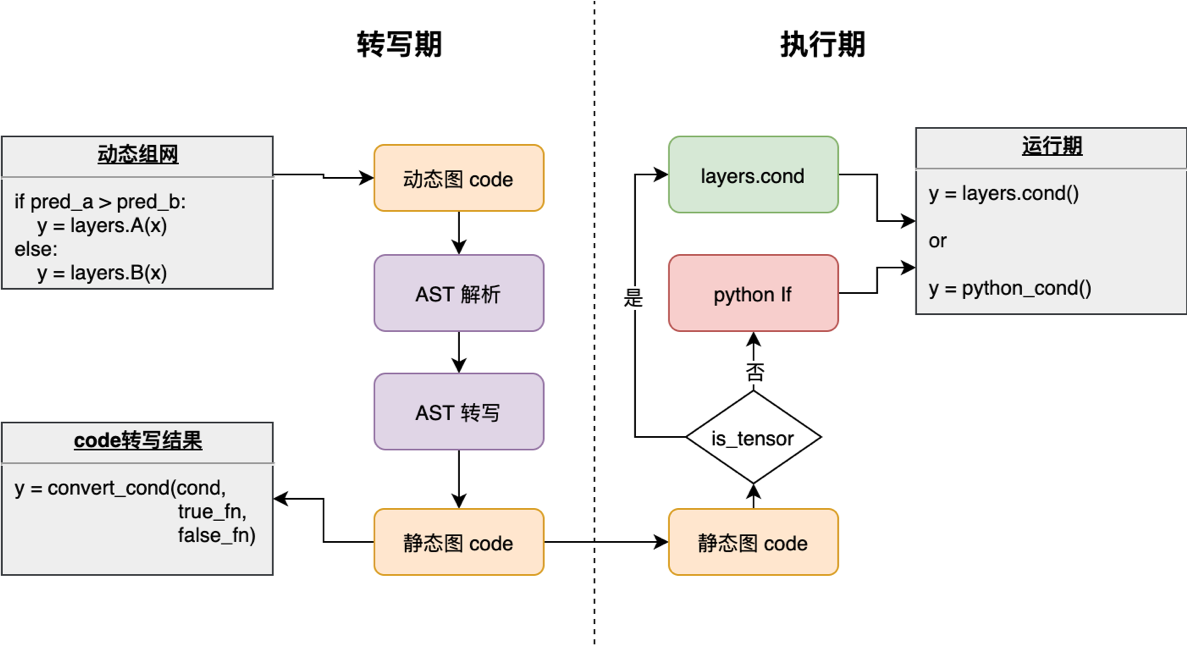
转写上有两个基本原则:
并非所有动态图中的
if/for/while都会转写为cond_op/while_op只有控制流的判断条件 依赖了
Tensor(如shape或value),才会转写为对应 Op
这是因为模型代码中不依赖 Tensor 的 if/for/while 会正常按照 Python 原生的语法逻辑去执行;而依赖 Tensor 的 if/for/while 才会调用 paddle.static.cond 和 paddle.static.while_loop 两个飞桨的控制流 API。
3.2.1 IfElse¶
无论是否会转写为 cond_op ,动转静都会首先对代码进行处理,转写为 cond 接口可以接受的写法。
示例一:不依赖 Tensor 的控制流
如下代码样例中的 if label is not None, 此判断只依赖于 label 是否为 None(存在性),并不依赖 label 的 Tensor 值(数值性),因此属于不依赖 Tensor 的控制流。
from paddle.jit import to_static
def not_depend_tensor_if(x, label=None):
out = x + 1
if label is not None: # <----- python bool 类型
out = paddle.nn.functional.cross_entropy(out, label)
return out
print(to_static(not_depend_tensor_if).code)
# 转写后的代码:
"""
def not_depend_tensor_if(x, label=None):
out = x + 1
def true_fn_0(label, out): # true 分支
out = paddle.nn.functional.cross_entropy(out, label)
return out
def false_fn_0(out): # false 分支
return out
out = paddle.jit.dy2static.convert_ifelse(label is not None, true_fn_0,
false_fn_0, (label, out), (out,), (out,))
return out
"""
示例二:依赖 Tensor 的控制流
如下代码样例中的 if paddle.mean(x) > 5, 此判断直接依赖 paddle.mean(x) 返回的 Tensor 值(数值性),因此属于依赖 Tensor 的控制流。
from paddle.jit import to_static
def depend_tensor_if(x):
if paddle.mean(x) > 5.: # <---- Bool Tensor 类型
out = x - 1
else:
out = x + 1
return out
print(to_static(depend_tensor_if).code)
# 转写后的代码:
"""
def depend_tensor_if(x):
out = paddle.jit.dy2static.data_layer_not_check(name='out_0', shape=[-1],
dtype='float32')
def true_fn_0(x): # true 分支
out = x - 1
return out
def false_fn_0(x): # false 分支
out = x + 1
return out
out = paddle.jit.dy2static.convert_ifelse(paddle.mean(x) > 5.0,
true_fn_0, false_fn_0, (x,), (x,), (out,))
return out
"""
规范化代码之后,所有的 IfElse 均转为了如下形式:
out = convert_ifelse(paddle.mean(x) > 5.0, true_fn_0, false_fn_0, (x,), (x,), (out,))
^ ^ ^ ^ ^ ^ ^ ^
| | | | | | | |
输出 convert_ifelse 判断条件 true 分支 false 分支 分支输入 分支输入 输出
convert_ifelse 是框架底层的函数,在逐行执行用户代码生成 Program 时,执行到此处时,会根据判断条件的类型( bool 还是 Bool Tensor ),自适应决定是否转为 cond_op 。
def convert_ifelse(pred, true_fn, false_fn, true_args, false_args, return_vars):
if isinstance(pred, Variable): # 触发 cond_op 的转换
return _run_paddle_cond(pred, true_fn, false_fn, true_args, false_args,
return_vars)
else: # 正常的 python if
return _run_py_ifelse(pred, true_fn, false_fn, true_args, false_args)
3.2.2 For/While¶
For/While 也会先进行代码层面的规范化,在逐行执行用户代码时,才会决定是否转为 while_op。
示例一:不依赖 Tensor 的控制流
如下代码样例中的 while a < 10, 此循环条件中的 a 是一个 int 类型,并不是 Tensor 类型,因此属于不依赖 Tensor 的控制流。
from paddle.jit import to_static
def not_depend_tensor_while(x):
a = 1
while a < 10: # <---- a is python scalar
x = x + 1
a += 1
return x
print(to_static(not_depend_tensor_while).code)
"""
def not_depend_tensor_while(x):
a = 1
def while_condition_0(a, x):
return a < 10
def while_body_0(a, x):
x = x + 1
a += 1
return a, x
[a, x] = paddle.jit.dy2static.convert_while_loop(while_condition_0,
while_body_0, [a, x])
return x
"""
示例二:依赖 Tensor 的控制流
如下代码样例中的 for i in range(bs), 此循环条件中的 bs 是一个 paddle.shape 返回的 Tensor 类型,且将其 Tensor 值作为了循环的终止条件,因此属于依赖 Tensor 的控制流。
from paddle.jit import to_static
def depend_tensor_while(x):
bs = paddle.shape(x)[0]
for i in range(bs): # <---- bs is a Tensor
x = x + 1
return x
print(to_static(depend_tensor_while).code)
"""
def depend_tensor_while(x):
bs = paddle.shape(x)[0]
i = 0
def for_loop_condition_0(x, i, bs):
return i < bs
def for_loop_body_0(x, i, bs):
x = x + 1
i += 1
return x, i, bs
[x, i, bs] = paddle.jit.dy2static.convert_while_loop(for_loop_condition_0,
for_loop_body_0, [x, i, bs])
return x
"""
convert_while_loop 的底层的逻辑同样会根据 判断条件是否为Tensor 来决定是否转为 while_op。
四、 生成静态图的 Program 和 Parameters¶
静态图模式下,神经网络会被描述为 Program 的数据结构,并对 Program 进行编译优化,再调用执行器获得计算结果。另外静态图的变量是 Variable 类型(动态图是 Tensor 类型),因此要运行静态图模型,需要生成静态图的 Program 和 Parameters。
4.1 动态图 layer 生成 Program¶
文档开始的样例中 forward 函数包含两行组网代码: Linear 和 add 操作。以 Linear 为例,在飞桨框架底层,每个组网 API 的实现包括两个分支:动态图分支和静态图分支。
class Linear(...):
def __init__(self, ...):
# ...(略)
def forward(self, input):
if in_dygraph_mode(): # 动态图分支
core.ops.matmul(input, self.weight, pre_bias, ...)
return out
else: # 静态图分支
self._helper.append_op(type="matmul", inputs=inputs, ...) # <----- 生成一个 Op
if self.bias is not None:
self._helper.append_op(type='elementwise_add', ...) # <----- 生成一个 Op
return out
动态图 layer 生成 Program ,其实是开启 paddle.enable_static() 时,在静态图下逐行执行用户定义的组网代码,依次添加(对应 append_op 接口) 到默认的主 Program(即 main_program ) 中。
4.2 动态图 Tensor 转为静态图 Variable¶
上面提到,所有的组网代码都会在静态图模式下执行,以生成完整的 Program 。但静态图 append_op 有一个前置条件必须满足:
前置条件:
append_op()时,所有的 inputs,outputs 必须都是静态图的 Variable 类型,不能是动态图的 Tensor 类型。
原因:静态图下,操作的都是描述类单元:计算相关的 OpDesc ,数据相关的 VarDesc 。可以分别简单地理解为 Program 中的 Op 和 Variable 。
因此,在动转静时,我们在需要在某个统一的入口处,将动态图 Layers 中 Tensor 类型(包含具体数据)的 Weight 、Bias 等变量转换为同名的静态图 Variable。
ParamBase → Parameters
VarBase → Variable
技术实现上,我们选取了框架层面两个地方作为类型转换的入口:
Paddle.nn.Layer基类的__call__函数def __call__(self, *inputs, **kwargs): # param_guard 会对将 Tensor 类型的 Param 和 buffer 转为静态图 Variable with param_guard(self._parameters), param_guard(self._buffers): # ... forward_pre_hook 逻辑 outputs = self.forward(*inputs, **kwargs) # 此处为 forward 函数 # ... forward_post_hook 逻辑 return outputs
Block.append_op函数中,生成Op之前def append_op(self, *args, **kwargs): if in_dygraph_mode(): # ... (动态图分支) else: inputs=kwargs.get("inputs", None) outputs=kwargs.get("outputs", None) # param_guard 会确保将 Tensor 类型的 inputs 和 outputs 转为静态图 Variable with param_guard(inputs), param_guard(outputs): op = Operator( block=self, desc=op_desc, type=kwargs.get("type", None), inputs=inputs, outputs=outputs, attrs=kwargs.get("attrs", None))
以上,是动态图转为静态图的两个核心逻辑,总结如下:
动态图
layer调用在动转静时会走底层append_op的分支,以生成Program动态图
Tensor转为静态图Variable,并确保编译期的InferShape正确执行
4.3 Buffers 变量¶
什么是 Buffers 变量?
Parameters:
persistable为True,且每个 batch 都被 Optimizer 更新的变量Buffers:
persistable为True,is_trainable = False,不参与更新,但与预测相关;如BatchNorm层中的均值和方差
在动态图模型代码中,若一个 paddle.to_tensor 接口生成的 Tensor 参与了最终预测结果的的计算,则此 Tensor 需要在转换为静态图预测模型时,也需要作为一个 persistable 的变量保存到 .pdiparam 文件中。
举一个例子(错误写法):
import paddle
from paddle.jit import to_static
class SimpleNet(paddle.nn.Layer):
def __init__(self, mask):
super(SimpleNet, self).__init__()
self.linear = paddle.nn.Linear(10, 3)
# mask value,此处不会保存到预测模型文件中
self.mask = mask # 假设为 [0, 1, 1]
def forward(self, x, y):
out = self.linear(x)
out = out + y
mask = paddle.to_tensor(self.mask) # <----- 每次执行都转为一个 Tensor
out = out * mask
return out
推荐的写法是:
class SimpleNet(paddle.nn.Layer):
def __init__(self, mask):
super(SimpleNet, self).__init__()
self.linear = paddle.nn.Linear(10, 3)
# 此处的 mask 会当做一个 buffer Tensor,保存到 .pdiparam 文件
self.mask = paddle.to_tensor(mask) # 假设为 [0, 1, 1]
def forward(self, x, y):
out = self.linear(x)
out = out + y
out = out * self.mask # <---- 直接使用 self.mask
return out
总结一下 Buffers 的用法:
若某个非
Tensor数据需要当做Persistable的变量序列化到磁盘,则最好在__init__中调用self.XX= paddle.to_tensor(xx)接口转为buffer变量