强化学习——Advantage Actor-Critic(A2C)¶
作者::EastSmith
日期: 2022.1
AI Studio项目:点击体验
一、介绍¶
先回顾一下以前的知识, 你可能知道,目前有两种主要的RL方法类型:¶
基于值:试图找到或近似最佳值函数,这是一个动作和一个值之间的映射。 值越高,动作越好。 最著名的算法是Q学习及其所有增强的方法, 例如Deep Q Networks,Double Dueling Q Networks等
基于策略的:基于策略的算法(例如“ 策略梯度” 和REINFORCE)尝试直接找到最佳策略,而无需Q值作为中间步骤。
当这两个算法流行以后,下一个显而易见的步骤是……尝试合并它们。 这就是演员——评论家的诞生方式。 演员评论家旨在利用基于价值和基于策略的优点,同时消除其弊端。 以及他们如何做到这一点?
主要思想是将模型分为两部分:一个用于基于状态计算动作,另一个用于估计动作的Q值。¶
演员将状态作为输入并输出最佳动作。 它实质上是通过控制代理的行为来学习最佳策略 (基于策略) 。 另一方面,评论家通过计算值函数评估动作 (基于值)来 。 这两个模型参加了一场比赛,随着时间的流逝,他们各自的角色都变得更好。 结果是,与单独使用两种方法相比,整个体系结构将学会更有效地玩游戏。
让两个模型相互交互(或竞争)的想法在机器学习领域越来越流行。 例如, 生成对抗网络(Generative Adversarial Networks) 或 变体自动编码器(Variational Autoencoders)
演员——评论家:¶
(可以参照的教程:强化学习——Actor Critic Method-使用文档-PaddlePaddle深度学习平台)
演员——评论家的一个很好的比喻是一个小男孩和他的母亲。 这个孩子(演员)不断尝试新事物并探索他周围的环境。 他吃自己的玩具,触摸热烤箱,用头撞在墙上(谁知道他为什么这样做)。 他的母亲(评论家)看着他,并批评或称赞他。 这个孩子听母亲讲给他的话,并调整自己的行为。 随着孩子的成长,他学会了什么动作是坏事还是好事,并且他实质上学会了玩称为生活的游戏。 这与演员评论家的工作方式完全相同。
参与者演员可以是类似于神经网络的函数逼近器,其任务是针对给定状态产生最佳动作。 当然,它可以是全连接的神经网络,也可以是卷积或其他任何东西。 评论家是另一个函数逼近器,它接收参与者输入的环境和动作作为输入,将它们连接起来并输出评分值(Q值)。 让我提醒您几秒钟,Q值本质上是将来的最大奖励。
这两个网络的训练是分别进行的,评论家使用梯度上升(找到全局最大值而不是最小值)来更新它们的权重。 随着时间的流逝,演员正在学会做出更好的动作(他开始学习策略),而评论家在评估这些动作方面也越来越好。 重要的是要注意,权重的更新发生在每个步骤(TD学习),而不是发生在事件的结尾,这与策略梯度相反。
事实证明,演员评论家能够学习大型复杂的环境,并且已在很多著名的2d和3d游戏中使用,例如Doom,Super Mario等。
优势-演员-评论家 Advantage-Actor-Critic(A2C)¶
什么是优势? Q值实际上可以分解为两部分:状态值函数V(s)和优势值A(s,a):
Q(s,a)= V(s)+ A(s,a)
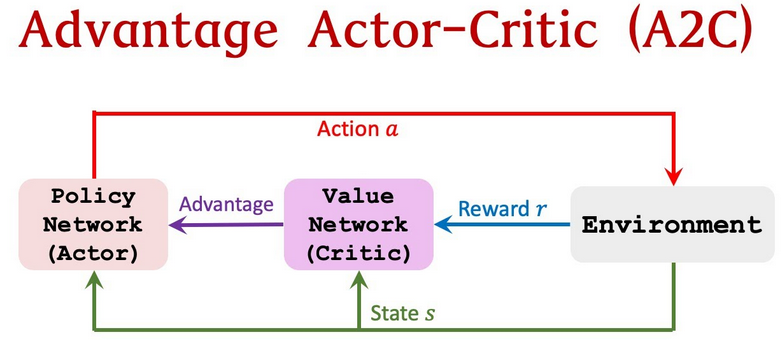
优势函数能够评估在给定状态下与其他行为相比更好的行为,而众所周知,价值函数是评估在此状态下行为的良好程度。
你猜这是怎么回事,对不对? 与其让评论家学习Q值,不如让评论家学习Advantage值 。 这样,对行为的评估不仅基于行为的良好程度,而且还取决于行为可以改善的程度。 优势函数的优势是它减少了策略网络的数值差异并稳定了模型。
二、环境配置¶
本教程基于Paddle 2.2 编写,如果你的环境不是本版本,请先参考官网安装 Paddle 2.2。
import math
import random
import os
import gym
import numpy as np
import paddle
import paddle.nn as nn
import paddle.optimizer as optim
import paddle.nn.functional as F
from paddle.distribution import Categorical
import matplotlib.pyplot as plt
from visualdl import LogWriter
三、实施“优势-演员-评论家 Advantage-Actor-Critic(A2C)”算法¶
构建多个进程玩CartPole-v0¶
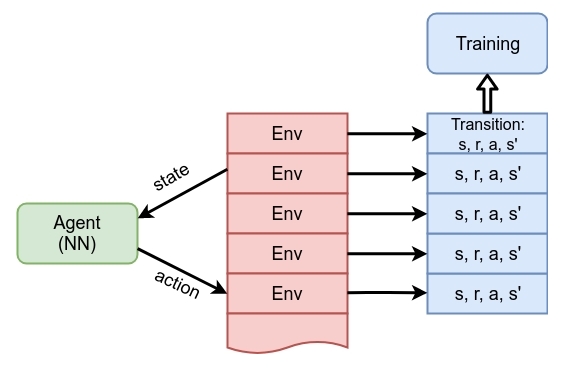
A2C会构建多个进程,包括多个并行的 worker,与独立的环境进行交互,收集独立的经验。详细代码在multiprocessing_env.py里。简单介绍一下创建多环境的过程:env = gym.make(env_name)只能创建一个线程,智能体只能和一个环境进行交互,而使用 SubprocVecEnv(envs)可以创建多个并行的环境,用num_envs定义并行环境的数量。需要注意的是如果创建的是多个并行的环境envs的话,那么envs.step()需要输入的是成组的动作,每个环境对应一组动作,相应的envs返回的next_state, reward等也是成组的。
#This code is from openai baseline
#https://github.com/openai/baselines/tree/master/baselines/common/vec_env
import numpy as np
from multiprocessing import Process, Pipe
def worker(remote, parent_remote, env_fn_wrapper):
parent_remote.close()
env = env_fn_wrapper.x()
while True:
cmd, data = remote.recv()
if cmd == 'step':
ob, reward, done, info = env.step(data)
# ob, reward, done, info = env.step(1)
if done:
ob = env.reset()
remote.send((ob, reward, done, info))
elif cmd == 'reset':
ob = env.reset()
remote.send(ob)
elif cmd == 'reset_task':
ob = env.reset_task()
remote.send(ob)
elif cmd == 'close':
remote.close()
break
elif cmd == 'get_spaces':
remote.send((env.observation_space, env.action_space))
else:
raise NotImplementedError
class VecEnv(object):
"""
An abstract asynchronous, vectorized environment.
"""
def __init__(self, num_envs, observation_space, action_space):
self.num_envs = num_envs
self.observation_space = observation_space
self.action_space = action_space
def reset(self):
"""
Reset all the environments and return an array of
observations, or a tuple of observation arrays.
If step_async is still doing work, that work will
be cancelled and step_wait() should not be called
until step_async() is invoked again.
"""
pass
def step_async(self, actions):
"""
Tell all the environments to start taking a step
with the given actions.
Call step_wait() to get the results of the step.
You should not call this if a step_async run is
already pending.
"""
pass
def step_wait(self):
"""
Wait for the step taken with step_async().
Returns (obs, rews, dones, infos):
- obs: an array of observations, or a tuple of
arrays of observations.
- rews: an array of rewards
- dones: an array of "episode done" booleans
- infos: a sequence of info objects
"""
pass
def close(self):
"""
Clean up the environments' resources.
"""
pass
def step(self, actions):
self.step_async(actions)
return self.step_wait()
class CloudpickleWrapper(object):
"""
Uses cloudpickle to serialize contents (otherwise multiprocessing tries to use pickle)
"""
def __init__(self, x):
self.x = x
def __getstate__(self):
import cloudpickle
return cloudpickle.dumps(self.x)
def __setstate__(self, ob):
import pickle
self.x = pickle.loads(ob)
class SubprocVecEnv(VecEnv):
def __init__(self, env_fns, spaces=None):
"""
envs: list of gym environments to run in subprocesses
"""
self.waiting = False
self.closed = False
nenvs = len(env_fns)
self.nenvs = nenvs
self.remotes, self.work_remotes = zip(*[Pipe() for _ in range(nenvs)])
self.ps = [Process(target=worker, args=(work_remote, remote, CloudpickleWrapper(env_fn)))
for (work_remote, remote, env_fn) in zip(self.work_remotes, self.remotes, env_fns)]
for p in self.ps:
p.daemon = True # if the main process crashes, we should not cause things to hang
p.start()
for remote in self.work_remotes:
remote.close()
self.remotes[0].send(('get_spaces', None))
observation_space, action_space = self.remotes[0].recv()
VecEnv.__init__(self, len(env_fns), observation_space, action_space)
def step_async(self, actions):
for remote, action in zip(self.remotes, actions):
remote.send(('step', action))
self.waiting = True
def step_wait(self):
results = [remote.recv() for remote in self.remotes]
self.waiting = False
obs, rews, dones, infos = zip(*results)
return np.stack(obs), np.stack(rews), np.stack(dones), infos
def reset(self):
for remote in self.remotes:
remote.send(('reset', None))
return np.stack([remote.recv() for remote in self.remotes])
def reset_task(self):
for remote in self.remotes:
remote.send(('reset_task', None))
return np.stack([remote.recv() for remote in self.remotes])
def close(self):
if self.closed:
return
if self.waiting:
for remote in self.remotes:
remote.recv()
for remote in self.remotes:
remote.send(('close', None))
for p in self.ps:
p.join()
self.closed = True
def __len__(self):
return self.nenvs
writer = LogWriter(logdir="./log")
#from multiprocessing_env import SubprocVecEnv
num_envs = 8
env_name = "CartPole-v0"
def make_env():
def _thunk():
env = gym.make(env_name)
return env
return _thunk
plt.ion()
envs = [make_env() for i in range(num_envs)]
envs = SubprocVecEnv(envs) # 8 env
env = gym.make(env_name) # a single env
定义网络结构并开始训练¶
self.critic部分定义的是“评论家”,self.actor部分定义的是“演员”。“评论家”网络观察输入并“打分”,“演员”网络接收输入并给出行动的类别分布,这里用到了API——paddle.distribution.Categorical,后续调用sample(shape)生成指定维度的样本、调用entropy()返回类别分布的信息熵、调用log_prob(value)返回所选择类别的对数概率,其他用法可以查看飞桨API文档。
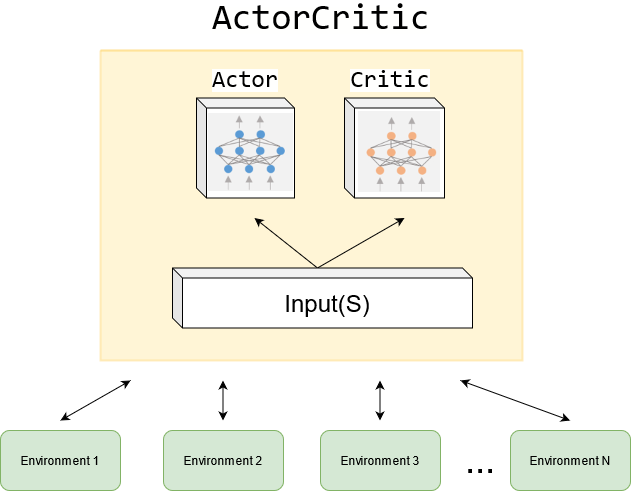
class ActorCritic(nn.Layer):
def __init__(self, num_inputs, num_outputs, hidden_size, std=0.0):
super(ActorCritic, self).__init__()
nn.initializer.set_global_initializer(nn.initializer.XavierNormal(), nn.initializer.Constant(value=0.))
self.critic = nn.Sequential(
nn.Linear(num_inputs, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, 1)
)
self.actor = nn.Sequential(
nn.Linear(num_inputs, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, num_outputs),
nn.Softmax(axis=1),
)
def forward(self, x):
value = self.critic(x)
probs = self.actor(x)
dist = Categorical(probs)
return dist, value
def test_env(vis=False):
state = env.reset()
if vis: env.render()
done = False
total_reward = 0
while not done:
state = paddle.to_tensor(state,dtype="float32").unsqueeze(0)
dist, _ = model(state)
next_state, reward, done, _ = env.step(dist.sample([1]).cpu().numpy()[0][0])
state = next_state
if vis: env.render()
total_reward += reward
return total_reward
def compute_returns(next_value, rewards, masks, gamma=0.99):
R = next_value
returns = []
for step in reversed(range(len(rewards))):
R = rewards[step] + gamma * R * masks[step]
returns.insert(0, R)
return returns
def plot(frame_idx, rewards):
plt.plot(rewards,'b-')
plt.title('frame %s. reward: %s' % (frame_idx, rewards[-1]))
plt.pause(0.0001)
实例化模型和定义优化器¶
hidden_size是网络的隐藏层的“神经元”数目,lr是优化器的学习率,咱使用经典的Adam优化器。num_steps是收集轨迹的步数,值设置的越大,更新网络前收集的轨迹越长。
num_inputs = envs.observation_space.shape[0]
num_outputs = envs.action_space.n
# Hyper params:
hidden_size = 256
lr = 1e-3
num_steps = 8
model = ActorCritic(num_inputs, num_outputs, hidden_size)
optimizer = optim.Adam(parameters=model.parameters(),learning_rate=lr)
save_model_path = "models/A2C_model.pdparams"
if os.path.exists(save_model_path):
model_state_dict = paddle.load(save_model_path)
model.set_state_dict(model_state_dict )
print(' Model loaded')
四、开始循环训练过程:¶
收集经验—>计算损失—>反向传播
# 首先定义最大的训练帧数,并行的环境envs每执行一步step()算一帧。如果按照前面定义的
# 是8组环境并行,那么envs就需要输入8组动作,同时会输出8组回报(reward)、下一
# 观测状态(next_state)。
max_frames = 20000
frame_idx = 0
test_rewards = []
state = envs.reset()
while frame_idx < max_frames:
log_probs = []
values = []
rewards = []
masks = []
entropy = 0
# rollout trajectory
# 现在模型展开num_steps步的轨迹:模型会根据观测状态返回动作的分布、状态价值,然后
# 根据动作分布采样动作,接着环境step一步进入到下一个状态,并返回reward。
for _ in range(num_steps):
state = paddle.to_tensor(state,dtype="float32")
dist, value = model(state)
action = dist.sample([1]).squeeze(0)
next_state, reward, done, _ = envs.step(action.cpu().numpy())
log_prob = dist.log_prob(action)
entropy += dist.entropy().mean()
log_probs.append(log_prob)
values.append(value)
rewards.append(paddle.to_tensor(reward,dtype="float32").unsqueeze(1))
masks.append(paddle.to_tensor(1 - done).unsqueeze(1))
state = next_state
frame_idx += 1
Plot = False
# 程序每隔100帧会进行一次评估,评估的方式是运行2次test_env()并计算返回的
# total_reward的均值,这里用VisualDL记录它,文章的最后会展示模型运行效果。
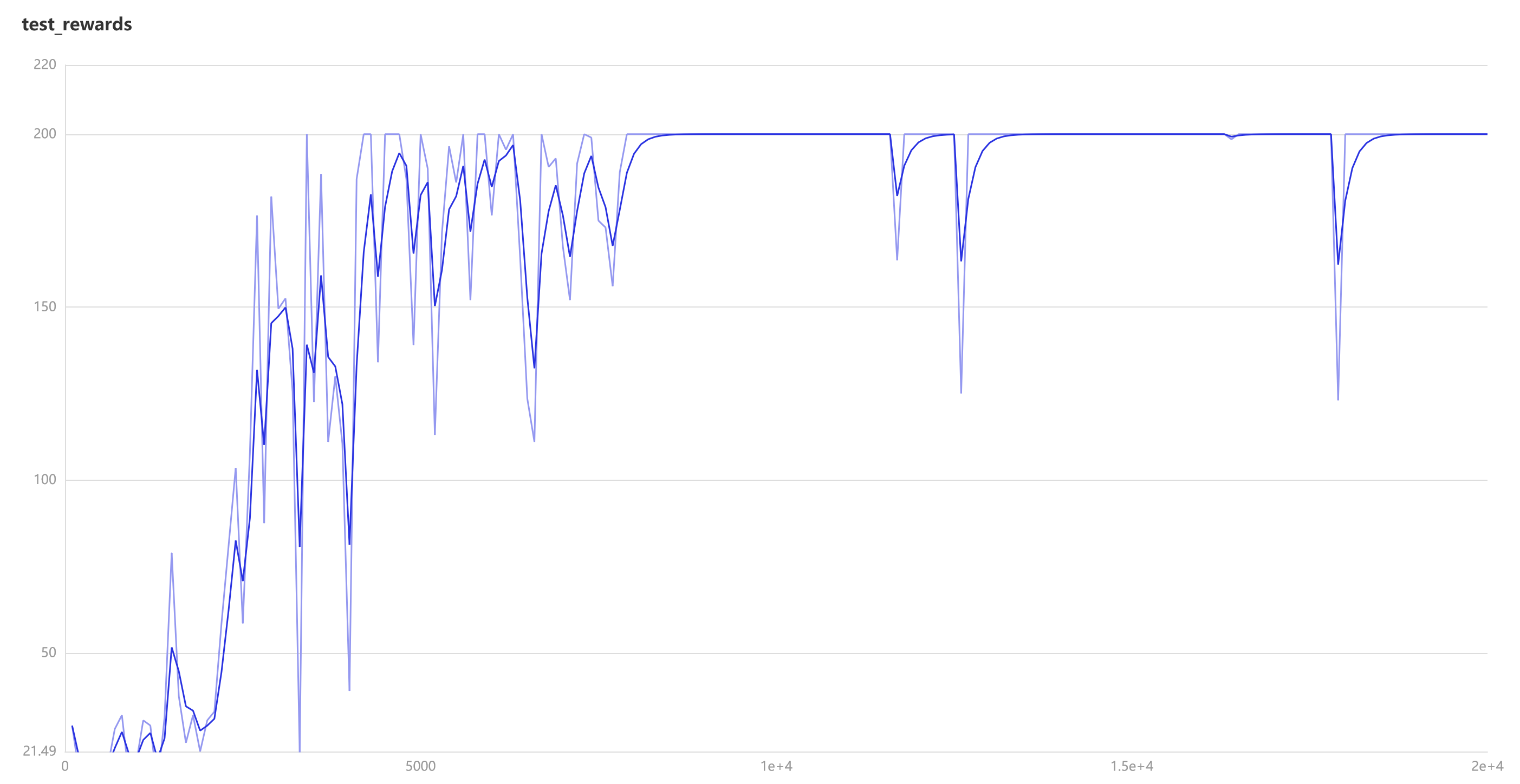
if frame_idx % 100 == 0:
test_rewards.append(np.mean([test_env() for _ in range(2)]))
writer.add_scalar("test_rewards", value=test_rewards[-1], step=frame_idx)
if Plot:
plot(frame_idx, test_rewards)
else:
print('frame {}. reward: {}'.format(frame_idx, test_rewards[-1]))
# 程序会记录展开轨迹的动作对数似然概率log_probs、模型估计价值values、回报rewards等,
# 并计算优势值advantage 。由于是多环境并行,可以用paddle.concat将这些值分别拼接起来,
# 随后计算出演员网络的损失actor_loss、评论家网络的损失critic_loss,在最终loss中有一项
# 是动作分布熵的均值,希望能增大网络的探索能力。
next_state = paddle.to_tensor(next_state,dtype="float32")
_, next_value = model(next_state)
returns = compute_returns(next_value, rewards, masks)
log_probs = paddle.concat(log_probs)
returns = paddle.concat(returns).detach()
values = paddle.concat(values)
advantage = returns - values
actor_loss = -(log_probs * advantage.detach()).mean()
critic_loss = advantage.pow(2).mean()
loss = actor_loss + 0.5 * critic_loss - 0.01 * entropy
# 用VisualDL记录训练的actor_loss、critic_loss以及合并后的loss。然后再反向传播,优化神
# 经网络的参数,开始下一轮的训练循环。
writer.add_scalar("actor_loss", value=actor_loss, step=frame_idx)
writer.add_scalar("critic_loss", value=critic_loss, step=frame_idx)
writer.add_scalar("loss", value=loss, step=frame_idx)
##动态学习率,每隔2000帧缩放一次
if frame_idx % 2000 ==0:
lr = 0.92*lr
optimizer.set_lr(lr)
optimizer.clear_grad()
loss.backward()
optimizer.step()
if not os.path.exists(os.path.dirname(save_model_path)):
os.makedirs(os.path.dirname(save_model_path))
# paddle.save(model.state_dict(), save_model_path)
五、VisualDL里展示模型运行的效果¶
在gym的CartPole环境(env)里面,小车需要左右移动来保持杆子竖直。左移或者右移小车之后,env会返回一个“+1”的reward,如果杠子倾角过大或者小车超范围游戏就结束了。其中,在CartPole-v0环境里reward达到200也会结束游戏。
六、总结和建议¶
深度强化学习中,很多基础算法都是单线程的,也就是一个 agent 去跟环境交互产生经验。基础版 Actor-Critic ,由于环境是固定不变的,agent 的动作又是连续的,这样收集到的经验就有很强的时序关联,而且在有限的时间内也只能探索到部分状态和动作空间。
为了打破经验之间的耦合,可以采用Experiencre Replay的方法,让 agent 能够在后续的训练中访问到以前的历史经验,这就是 DQN 和 DDPG 这类基于值的(DDPG虽然也属于 Actor-Critic 架构,但本质上是 DQN 在连续空间中的扩展)算法所采用的方式。而对于基于策略类的算法,agent 收集的经验都是以 episode为单位的,跑完一个episode 后经验就要丢掉,更好的方式是采用多线程的并行架构,这样既能解决前面的问题,又能高效利用计算资源,提升训练效率。
Advantage Actor-Critic(A2C) 算法引入了并行架构,各个 worker 都会独立的跟自己的环境去交互,得到独立的采样经验,而这些经验之间也是相互独立的,这样就打破了经验之间的耦合,起到跟 Experiencre Replay 相当的效果。因此通常 A2C和A3C 是不需要使用 Replay Buffer 的,这种结构本身就可以替代了。