参数调整常见问题¶
问题:如何将本地数据传入paddle.nn.embedding的参数矩阵中?¶
答复:需将本地词典向量读取为NumPy数据格式,然后使用
paddle.nn.initializer.Assign这个API初始化paddle.nn.embedding里的param_attr参数,即可实现加载用户自定义(或预训练)的Embedding向量。
问题:如何实现网络层中多个feature间共享该层的向量权重?¶
答复:你可以使用
paddle.ParamAttr并设定一个name参数,然后再将这个类的对象传入网络层的param_attr参数中,即将所有网络层中param_attr参数里的name设置为同一个,即可实现共享向量权重。如使用embedding层时,可以设置param_attr=paddle.ParamAttr(name="word_embedding"),然后把param_attr传入embedding层中。
问题:使用optimizer或ParamAttr设置的正则化和学习率,二者什么差异?¶
答复:ParamAttr中定义的
regularizer优先级更高。若ParamAttr中定义了regularizer,则忽略Optimizer中的regularizer;否则,则使用Optimizer中的regularizer。ParamAttr中的学习率默认为1.0,在对参数优化时,最终的学习率等于optimizer的学习率乘以ParamAttr的学习率。
问题:如何导出指定层的权重,如导出最后一层的weights和bias?¶
答复:
问题:训练过程中如何固定网络和Batch Normalization(BN)?¶
答复:
对于固定BN:设置
use_global_stats=True,使用已加载的全局均值和方差:global mean/variance,具体内容可查看官网API文档batch_norm。对于固定网络层:如: stage1→ stage2 → stage3 ,设置stage2的输出,假设为y,设置
y.stop_gradient=True,那么, stage1→ stage2整体都固定了,不再更新。
问题:训练的step在参数优化器中是如何变化的?¶
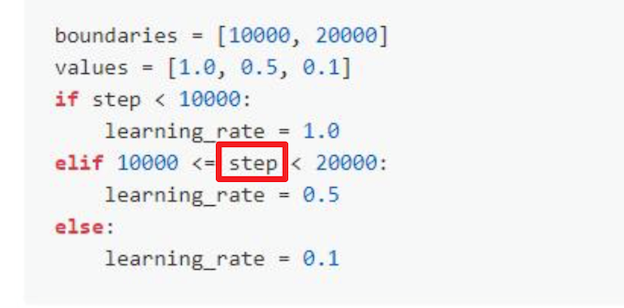
答复:
step表示的是经历了多少组mini_batch,其统计方法为exe.run(对应Program)运行的当前次数,即每运行一次exe.run,step加1。举例代码如下:
# 执行下方代码后相当于step增加了N x Epoch总数
for epoch in range(epochs):
# 执行下方代码后step相当于自增了N
for data in [mini_batch_1,2,3...N]:
# 执行下方代码后step += 1
exe.run(data)
问题:如何修改全连接层参数,比如weight,bias?¶
答复:可以通过
param_attr设置参数的属性,paddle.ParamAttr(initializer=paddle.nn.initializer.Normal(0.0, 0.02), learning_rate=2.0),如果learning_rate设置为0,该层就不参与训练。也可以构造一个numpy数据,使用paddle.nn.initializer.Assign来给权重设置想要的值。
问题:如何进行梯度裁剪?¶
答复:Paddle的梯度裁剪方式需要在Optimizer中进行设置,目前提供三种梯度裁剪方式,分别是paddle.nn.ClipGradByValue
(设定范围值裁剪)、paddle.nn.ClipGradByNorm(设定L2范数裁剪)、paddle.nn.ClipGradByGlobalNorm(通过全局L2范数裁剪),需要先创建一个该类的实例对象,然后将其传入到优化器中,优化器会在更新参数前,对梯度进行裁剪。
注:该类接口在动态图、静态图下均会生效,是动静统一的。目前不支持其他方式的梯度裁剪。
linear = paddle.nn.Linear(10, 10)
clip = paddle.nn.ClipGradByNorm(clip_norm=1.0) # 可以选择三种裁剪方式
sdg = paddle.optimizer.SGD(learning_rate=0.1, parameters=linear.parameters(), grad_clip=clip)
sdg.step() # 更新参数前,会先对参数的梯度进行裁剪
问题:如何在同一个优化器中定义不同参数的优化策略,比如bias的参数weight_decay的值为0.0,非bias的参数weight_decay的值为0.01?¶
问题:paddle fluid如何自定义优化器,自定义更新模型参数的规则?¶
答复:
要定义全新优化器,自定义优化器中参数的更新规则,可以通过继承fluid.Optimizer,重写_append_optimize_op方法实现。不同优化器实现原理各不相同,一般流程是先获取learning_rate,gradients参数,可训练参数,以及该优化器自身特别需要的参数,然后实现更新参数的代码,最后返回更新后的参数。
在实现更新参数代码时,可以选择直接调用paddle的API或者使用自定义原生算子。在使用自定义原生算子时,要注意动态图与静态图调用方式有所区别:
需要首先使用framework.in_dygraph_mode()判断是否为动态图模式,如果是动态图模式,则需要调用paddle._C_ops中相应的优化器算子;如果不是动态图模式,则需要调用block.append_op来添加优化器算子。
代码样例可参考paddle源码中AdamOptimizer等优化器的实现。使用现有的常用优化器,可以在创建
Param的时候,可以通过设置ParamAttr的属性来控制参数的属性,可以通过设置regularizer,learning_rate等参数简单设置参数的更新规则。