自动混合精度训练¶
一般情况下,训练深度学习模型时使用的数据类型为单精度(FP32)。2018年,百度与NVIDIA联合发表论文:MIXED PRECISION TRAINING,提出了混合精度训练的方法。混合精度训练是指在训练过程中,同时使用单精度(FP32)和半精度(FP16),其目的是相较于使用单精度(FP32)训练模型,在保持精度持平的条件下,能够加速训练。本文将介绍如何使用飞桨框架,实现自动混合精度训练。
一、半精度浮点类型 FP16¶
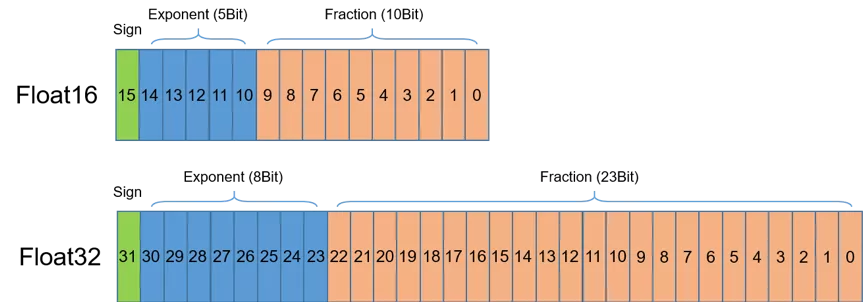
首先介绍半精度(FP16)。如图1所示,半精度(FP16)是一种相对较新的浮点类型,在计算机中使用2字节(16位)存储。在IEEE 754-2008标准中,它亦被称作binary16。与计算中常用的单精度(FP32)和双精度(FP64)类型相比,FP16更适于在精度要求不高的场景中使用。
二、NVIDIA GPU的FP16算力¶
在使用相同的超参数下,混合精度训练使用半精度浮点(FP16)和单精度(FP32)浮点即可达到与使用纯单精度训练相同的准确率,并可加速模型的训练速度。这主要得益于英伟达推出的Volta及Turing架构GPU在使用FP16计算时具有如下特点:
FP16可降低一半的内存带宽和存储需求,这使得在相同的硬件条件下研究人员可使用更大更复杂的模型以及更大的batch size大小。
FP16可以充分利用英伟达Volta及Turing架构GPU提供的Tensor Cores技术。在相同的GPU硬件上,Tensor Cores的FP16计算吞吐量是FP32的8倍。
三、使用飞桨框架实现自动混合精度¶
使用飞桨框架提供的API,paddle.amp.auto_cast 和 paddle.amp.decorate 和 paddle.amp.GradScaler 能够实现自动混合精度训练(Automatic Mixed Precision,AMP),即在相关OP的计算中,根据一定的规则,自动选择FP16或FP32计算。飞桨的AMP为用户提供了两种模式:
level=’O1‘:采用黑名名单策略的混合精度训练,使用FP16与FP32进行计算的OP列表可见该文档。
level=’O2‘:纯FP16训练,除用户自定义黑名单中指定的OP和不支持FP16计算的OP之外,全部使用FP16计算。
下面来看一个具体的例子,来了解如果使用飞桨框架实现混合精度训练。
3.1 辅助函数¶
首先定义辅助函数,用来计算训练时间。
import time
# 开始时间
start_time = None
def start_timer():
# 获取开始时间
global start_time
start_time = time.time()
def end_timer_and_print(msg):
# 打印信息并输出训练时间
end_time = time.time()
print("\n" + msg)
print("共计耗时 = {:.3f} sec".format(end_time - start_time))
3.2 构建一个简单的网络¶
构建一个简单的网络,用于对比使用普通方法进行训练与使用混合精度训练的训练速度。该网络由三层 Linear 组成,其中前两层 Linear 后接 ReLU 激活函数。
import paddle
import paddle.nn as nn
class SimpleNet(nn.Layer):
def __init__(self, input_size, output_size):
super(SimpleNet, self).__init__()
self.linear1 = nn.Linear(input_size, output_size)
self.relu1 = nn.ReLU()
self.linear2 = nn.Linear(input_size, output_size)
self.relu2 = nn.ReLU()
self.linear3 = nn.Linear(input_size, output_size)
def forward(self, x):
x = self.linear1(x)
x = self.relu1(x)
x = self.linear2(x)
x = self.relu2(x)
x = self.linear3(x)
return x
设置训练的相关参数,这里为了能有效的看出混合精度训练对于训练速度的提升,将 input_size 与 output_size 的值设为较大的值,为了使用GPU 提供的Tensor Core 性能,还需将 batch_size 设置为 8 的倍数。
epochs = 5
input_size = 4096 # 设为较大的值
output_size = 4096 # 设为较大的值
batch_size = 512 # batch_size 为8的倍数
nums_batch = 50
train_data = [paddle.randn((batch_size, input_size)) for _ in range(nums_batch)]
labels = [paddle.randn((batch_size, output_size)) for _ in range(nums_batch)]
mse = paddle.nn.MSELoss()
W1110 18:42:02.362493 104 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1
W1110 18:42:02.367755 104 device_context.cc:465] device: 0, cuDNN Version: 7.6.
3.3 使用默认的训练方式进行训练¶
model = SimpleNet(input_size, output_size) # 定义模型
optimizer = paddle.optimizer.SGD(learning_rate=0.0001, parameters=model.parameters()) # 定义优化器
start_timer() # 获取训练开始时间
for epoch in range(epochs):
datas = zip(train_data, labels)
for i, (data, label) in enumerate(datas):
output = model(data)
loss = mse(output, label)
# 反向传播
loss.backward()
# 训练模型
optimizer.step()
optimizer.clear_grad()
print(loss)
end_timer_and_print("默认耗时:") # 获取结束时间并打印相关信息
Tensor(shape=[1], dtype=float32, place=CUDAPlace(0), stop_gradient=False,
[1.24519622])
默认耗时:
共计耗时 = 2.926 sec
3.4 使用AMP训练模型¶
在飞桨框架中,使用自动混合精度训练,需要进行四个步骤:
Step1: 定义
GradScaler,用于缩放loss比例,避免浮点数下溢Step2: 使用
decorate在level=’O1‘模式下不做任何处理,无需调用该api,在level=’O2‘模式下,将网络参数从FP32转换为FP16Step3: 使用
auto_cast用于创建AMP上下文环境,该上下文中自动会确定每个OP的输入数据类型(FP16或FP32)Step4: 使用 Step1中定义的
GradScaler完成loss的缩放,用缩放后的loss进行反向传播,完成训练
采用level=’O1‘模式训练:
model = SimpleNet(input_size, output_size) # 定义模型
optimizer = paddle.optimizer.SGD(learning_rate=0.0001, parameters=model.parameters()) # 定义优化器
# Step1:定义 GradScaler,用于缩放loss比例,避免浮点数溢出
scaler = paddle.amp.GradScaler(init_loss_scaling=1024)
start_timer() # 获取训练开始时间
for epoch in range(epochs):
datas = zip(train_data, labels)
for i, (data, label) in enumerate(datas):
# Step2:创建AMP上下文环境,开启自动混合精度训练
with paddle.amp.auto_cast():
output = model(data)
loss = mse(output, label)
# Step3:使用 Step1中定义的 GradScaler 完成 loss 的缩放,用缩放后的 loss 进行反向传播
scaled = scaler.scale(loss)
scaled.backward()
# 训练模型
scaler.minimize(optimizer, scaled)
optimizer.clear_grad()
print(loss)
end_timer_and_print("使用AMP-O1模式耗时:")
Tensor(shape=[1], dtype=float32, place=CUDAPlace(0), stop_gradient=False,
[1.24815702])
使用AMP-O1模式耗时:
共计耗时 = 1.294 sec
采用level=’O2‘模式训练:
model = SimpleNet(input_size, output_size) # 定义模型
optimizer = paddle.optimizer.SGD(learning_rate=0.0001, parameters=model.parameters()) # 定义优化器
# Step1:定义 GradScaler,用于缩放loss比例,避免浮点数溢出
scaler = paddle.amp.GradScaler(init_loss_scaling=1024)
# Step2:在level=’O2‘模式下,将网络参数从FP32转换为FP16
model, optimizer = paddle.amp.decorate(models=model, optimizers=optimizer, level='O2', master_weight=None, save_dtype=None)
start_timer() # 获取训练开始时间
for epoch in range(epochs):
datas = zip(train_data, labels)
for i, (data, label) in enumerate(datas):
# Step3:创建AMP上下文环境,开启自动混合精度训练
with paddle.amp.auto_cast(enable=True, custom_white_list=None, custom_black_list=None, level='O2'):
output = model(data)
loss = mse(output, label)
# Step4:使用 Step1中定义的 GradScaler 完成 loss 的缩放,用缩放后的 loss 进行反向传播
scaled = scaler.scale(loss)
scaled.backward()
# 训练模型
scaler.minimize(optimizer, scaled)
optimizer.clear_grad()
print(loss)
end_timer_and_print("使用AMP-O2模式耗时:")
in ParamBase copy_to func
in ParamBase copy_to func
in ParamBase copy_to func
in ParamBase copy_to func
in ParamBase copy_to func
in ParamBase copy_to func
Tensor(shape=[1], dtype=float32, place=CUDAPlace(0), stop_gradient=False,
[1.25423336])
使用AMP-O2模式耗时:
共计耗时 = 0.890 sec
四、进阶用法¶
4.1 使用梯度累加¶
梯度累加是指在模型训练过程中,训练一个batch的数据得到梯度后,不立即用该梯度更新模型参数,而是继续下一个batch数据的训练,得到梯度后继续循环,多次循环后梯度不断累加,直至达到一定次数后,用累加的梯度更新参数,这样可以起到变相扩大 batch_size 的作用。
在自动混合精度训练中,也支持梯度累加,使用方式如下:
model = SimpleNet(input_size, output_size) # 定义模型
optimizer = paddle.optimizer.SGD(learning_rate=0.0001, parameters=model.parameters()) # 定义优化器
accumulate_batchs_num = 10 # 梯度累加中 batch 的数量
# 定义 GradScaler
scaler = paddle.amp.GradScaler(init_loss_scaling=1024)
start_timer() # 获取训练开始时间
for epoch in range(epochs):
datas = zip(train_data, labels)
for i, (data, label) in enumerate(datas):
# 创建AMP上下文环境,开启自动混合精度训练
with paddle.amp.auto_cast():
output = model(data)
loss = mse(output, label)
# 使用 GradScaler 完成 loss 的缩放,用缩放后的 loss 进行反向传播
scaled = scaler.scale(loss)
scaled.backward()
# 当累计的 batch 为 accumulate_batchs_num 时,更新模型参数
if (i + 1) % accumulate_batchs_num == 0:
# 训练模型
scaler.minimize(optimizer, scaled)
optimizer.clear_grad()
print(loss)
end_timer_and_print("使用AMP模式耗时:")
Tensor(shape=[1], dtype=float32, place=CUDAPlace(0), stop_gradient=False,
[1.25602019])
使用AMP模式耗时:
共计耗时 = 1.026 sec
五、总结¶
从上面的示例中可以看出,使用自动混合精度训练,O1模式共计耗时约 1.294s,O2模式共计耗时约 0.890s,而普通的训练方式则耗时 2.926s,O1模式训练速度提升约为 2.1倍,O2模式训练速度提升约为 3.0倍。如需更多使用混合精度训练的示例,请参考飞桨模型库: paddlepaddle/models。