PaddleLite使用英特尔FPGA预测部署¶
PaddleLite已支持英特尔FPGA平台的预测部署,PaddleLite通过调用底层驱动实现对FPGA硬件的调度。
PaddleLite实现英特尔FPGA简介¶
PaddleLite支持英特尔FPGA作为后端硬件进行模型推理,其主要特性如下:
PaddleLite中英特尔FPGA的kernel,weights和bias仍为FP32、NCHW的格式,在提升计算速度的同时能做到用户对数据格式无感知
对于英特尔FPGA暂不支持的kernel,均会切回arm端运行,实现arm+FPGA混合布署运行
目前英特尔FPGA成本功耗都较低,可作为边缘设备首选硬件
支持现状¶
已支持的芯片¶
英特尔FPGA Cyclone V系列芯片
已支持的设备¶
海运捷讯C5MB(英特尔FPGA Cyclone V)开发板
海运捷讯C5CB(英特尔FPGA Cyclone V)开发板
海运捷讯C5TB(英特尔FPGA Cyclone V)开发板
已支持的Paddle模型¶
已支持(或部分支持)的Paddle算子¶
conv2d
depthwise_conv2d
准备工作¶
开发板C5MB可以通过串口线进行连接,也可以通过ssh进行连接,初次使用请参考文档 可以通过串口完成C5MB开发板的IP修改:
$ vi /etc/network/interfaces # 设备网络配置文件,将对应的address,netmask,和gateway设置为指定的地址即可。
参考示例演示¶
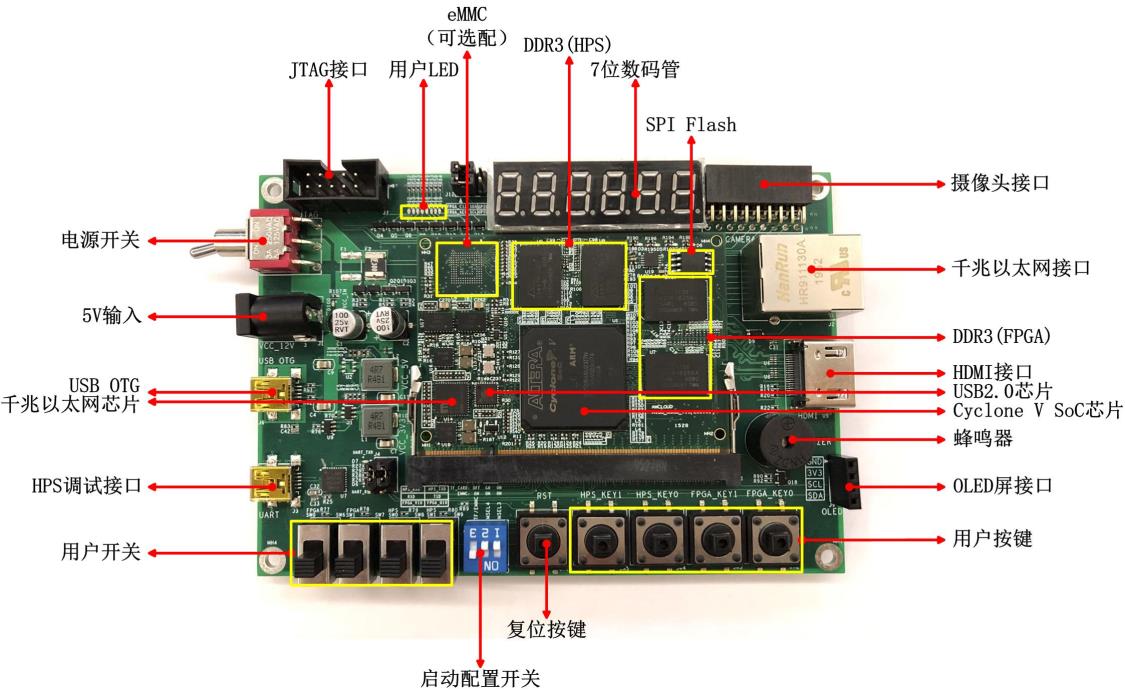

准备设备环境¶
提前准备带有intelfpgadrv.ko的英特尔FPGA开发板(如C5MB);
确定能够通过SSH方式远程登录C5MB开发板;
由于C5MB的ARM能力较弱,示例程序和PaddleLite库的编译均采用交叉编译方式。
准备交叉编译环境¶
为了保证编译环境一致,建议参考编译环境准备中的Docker开发环境进行配置;
由于需要通过scp和ssh命令将交叉编译生成的PaddleLite库和示例程序传输到设备上执行,因此,在进入Docker容器后还需要安装如下软件:
# apt-get install openssh-client sshpass
运行图像检测示例程序¶
下载示例程序PaddleLite-linux-demo.tar.gz,解压后清单如下:
- PaddleLite-linux-demo - ssd_detection - assets - images - dog.jpg # 测试图片 - dog.raw # 已处理成raw数据的测试图片 - labels - pascalvoc_label_list # 检测label文件 - models - ssd_mobilenet_v1_fp32_300_fluid # Paddle fluid non-combined格式的SSD-MobileNetV1 float32模型 - ssd_mobilenet_v1_fp32_300_for_intel_fpga - model.nb # 已通过opt转好的、适合英特尔FPGA的SSD-MobileNetV1 float32模型 - shell - CMakeLists.txt # 示例程序CMake脚本 - build - ssd_detection # 已编译好的示例程序 - ssd_detection.cc # 示例程序源码 - convert_to_raw_image.py # 将测试图片保存为raw数据的python脚本 - build.sh # 示例程序编译脚本 - run.sh # 示例程序运行脚本 - intelfpgadrv.ko # 英特尔FPGA内核驱动程序 - libs - PaddleLite - armhf - include # PaddleLite头文件 - lib - libvnna.so # 英特尔FPGA推理运行时库 - libpaddle_light_api_shared.so # 用于最终移动端部署的预编译PaddleLite库(tiny publish模式下编译生成的库) - libpaddle_full_api_shared.so # 用于直接加载Paddle模型进行测试和Debug的预编译PaddleLite库(full publish模式下编译生成的库)按照以下命令运行转换后的ARM+FPGA模型
注意: 1)run.sh必须在Host机器上运行,且执行前需要配置目标设备的IP地址、SSH账号和密码; 2)build.sh建议在docker环境中执行,目前英特尔FPGA在PaddleLite上只支持armhf。 运行适用于英特尔FPGA的ssd_mobilenet_v1量化模型 $ cd PaddleLite-linux-demo/ssd_detection/assets/models $ cp ssd_mobilenet_v1_fp32_300_for_intel_fpga/model.nb ssd_mobilenet_v1_fp32_300_fluid.nb $ cd ../../shell $ vim ./run.sh MODEL_NAME设置为ssd_mobilenet_v1_fp32_300_fluid $ ./run.sh iter 0 cost: 3079.443115 ms iter 1 cost: 3072.508057 ms iter 2 cost: 3063.342041 ms warmup: 1 repeat: 3, average: 3071.764404 ms, max: 3079.443115 ms, min: 3063.342041 ms results: 3 [0] bicycle - 0.997817 0.163673,0.217786,0.721802,0.786120 [1] car - 0.943994 0.597238,0.131665,0.905698,0.297017 [2] dog - 0.959329 0.157911,0.334807,0.431497,0.920035 Preprocess time: 114.061000 ms Prediction time: 3071.764404 ms Postprocess time: 13.166000 ms
如果需要更改测试图片,可通过convert_to_raw_image.py工具生成;
如果需要重新编译示例程序,直接运行./build.sh即可,注意:build.sh的执行建议在docker环境中,否则可能编译出错。
更新模型¶
通过Paddle Fluid训练,或X2Paddle转换得到SSD-MobileNetV1 float32模型ssd_mobilenet_v1_fp32_300_fluid;
参考模型转化方法,利用opt工具转换生成英特尔FPGA模型,仅需要将valid_targets设置为intel_fpga,arm即可。
$ ./opt --model_dir=ssd_mobilenet_v1_fp32_300_fluid \ --optimize_out_type=naive_buffer \ --optimize_out=opt_model \ --valid_targets=intel_fpga,arm 替换自带的英特尔FPGA模型 $ cp opt_model.nb ssd_mobilenet_v1_fp32_300_for_intel_fpga/model.nb
注意:opt生成的模型只是标记了英特尔FPGA支持的Paddle算子,并没有真正生成英特尔FPGA模型,只有在执行时才会将标记的Paddle算子转成英特尔FPGA的APIs,最终生成并执行模型。
更新支持英特尔FPGA的PaddleLite库¶
下载PaddleLite源码和英特尔FPGA的SDK
$ git clone https://github.com/PaddlePaddle/Paddle-Lite.git $ cd Paddle-Lite $ git checkout <release-version-tag> $ curl -L https://paddlelite-demo.bj.bcebos.com/devices/intel/intel_fpga_sdk_1.0.0.tar.gz -o - | tar -zx
编译并生成PaddleLite+IntelFPGA的部署库
For C5MB
tiny_publish编译方式
$ ./lite/tools/build_linux.sh --arch=armv7hf --with_extra=ON --with_log=ON --with_intel_fpga=ON --intel_fpga_sdk_root=./intel_fpga_sdk 将tiny_publish模式下编译生成的build.lite.armlinux.armv7hf.gcc/inference_lite_lib.armlinux.armv7hf.intel_fpga/cxx/lib/libpaddle_light_api_shared.so替换PaddleLite-linux-demo/libs/PaddleLite/armhf/lib/libpaddle_light_api_shared.so文件;
full_publish编译方式
$ ./lite/tools/build_linux.sh --arch=armv7hf --with_extra=ON --with_log=ON --with_intel_fpga=ON --intel_fpga_sdk_root=./intel_fpga_sdk full_publish 将full_publish模式下编译生成的build.lite.armlinux.armv7hf.gcc/inference_lite_lib.armlinux.armv7hf.intel_fpga/cxx/lib/libpaddle_full_api_shared.so替换PaddleLite-linux-demo/libs/PaddleLite/armhf/lib/libpaddle_full_api_shared.so文件。
将编译生成的build.lite.armlinux.armv7hf.gcc/inference_lite_lib.armlinux.armv7hf.intel_fpga/cxx/include替换PaddleLite-linux-demo/libs/PaddleLite/armhf/include目录;