模型量化¶
首先我们介绍一下 Paddle 支持的模型量化方法,让大家有一个整体的认识。
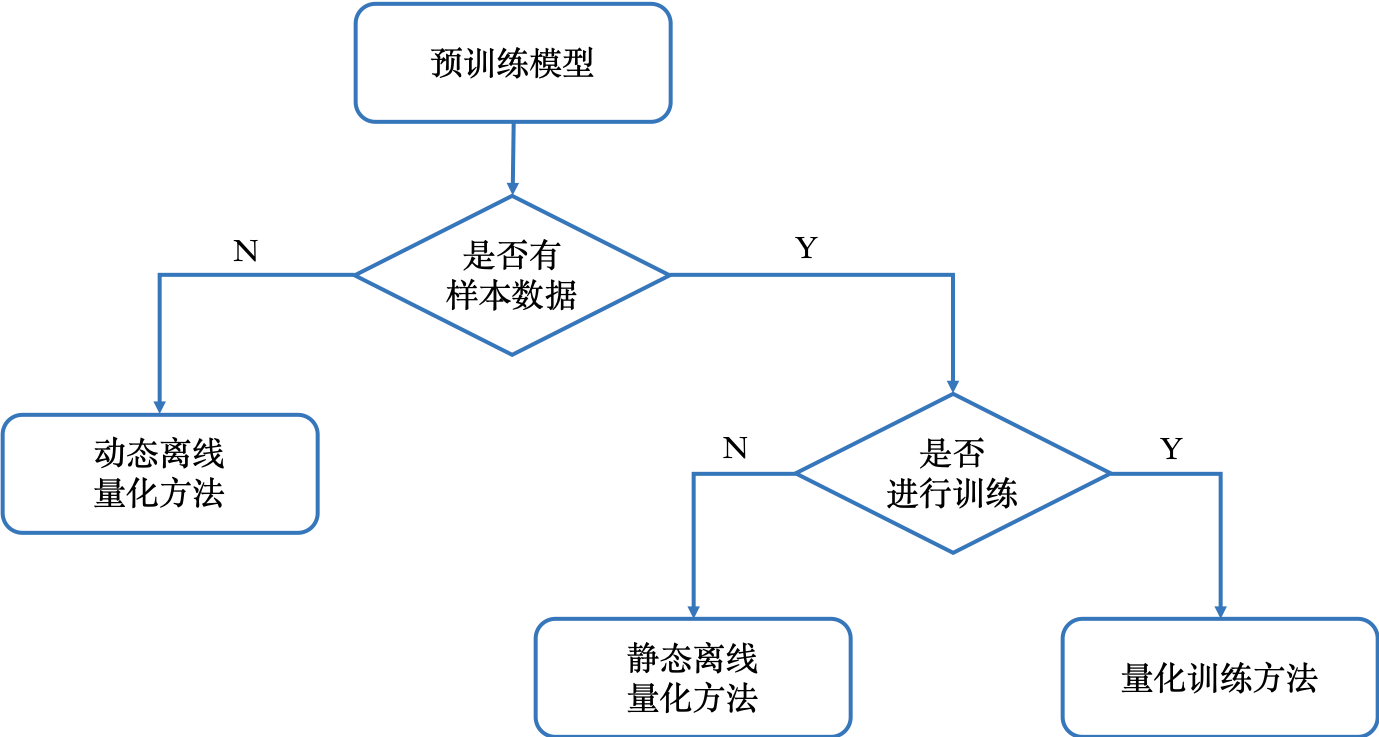
Paddle 模型量化包含三种量化方法,分别是动态离线量化方法、静态离线量化方法和量化训练方法。
下图展示了如何选择模型量化方法。
下图综合对比了模型量化方法的使用条件、易用性、精度损失和预期收益。

大家可以根据不同情况选用不同的量化方法,有几点着重注意:
动态离线量化方法主要用于减小模型体积
静态离线量化方法和量化训练方法既可以减小模型体积,也可以加快性能,性能加速基本相同
静态离线量化方法比量化训练方法更加简单,一般建议首先使用静态离线量化方法,如果量化模型精度损失较大,再尝试使用量化训练方法。
本章节主要介绍使用 PaddleSlim 量化训练方法产出的量化模型,使用 Paddle Lite 加载量化模型进行推理部署,
量化训练¶
1 简介¶
量化训练是使用较多训练数据,对训练好的预测模型进行量化。该方法使用模拟量化的思想,在训练阶段更新权重,实现减小量化误差。
使用条件:
有预训练模型
有较多训练数据(通常大于5000)
使用步骤:
产出量化模型:使用 PaddlePaddle 调用量化训练接口,产出量化模型
量化模型预测:使用 Paddle Lite 加载量化模型进行预测推理
优点:
减小计算量、降低计算内存、减小模型大小
模型精度受量化影响小
缺点:
使用条件较苛刻,使用门槛稍高
建议首先使用“静态离线量化”方法对模型进行量化,然后使用使用量化模型进行预测。如果该量化模型的精度达不到要求,再使用“量化训练”方法。
2 产出量化模型¶
目前,PaddleSlim 的量化训练主要针对卷积层和全连接层,对应算子是 conv2d、depthwise_conv2d、conv2d_tranpose 和 mul。Paddle Lite 支持运行 PaddleSlim 量化训练产出的模型,可以进一步加快模型在移动端的执行速度。
温馨提示:如果您是初次接触 PaddlePaddle 框架,建议首先学习使用文档。
使用 PaddleSlim 模型压缩工具训练量化模型,请参考文档:
3 使用 Paddle Lite 运行量化模型推理¶
首先,使用 Paddle Lite 提供的模型转换工具(model_optimize_tool)将量化模型转换成移动端预测的模型,然后加载转换后的模型进行预测部署。
3.1 模型转换¶
参考模型转换准备模型转换工具,建议从 Release 页面下载。
参考模型转换使用模型转换工具,参数按照实际情况设置。比如在安卓手机ARM端进行预测,模型转换的命令为:
./OPT --model_dir=./mobilenet_v1_quant \
--optimize_out_type=naive_buffer \
--optimize_out=mobilenet_v1_quant_opt \
--valid_targets=arm
3.2 量化模型预测¶
和 FP32 模型一样,转换后的量化模型可以在 Android/iOS APP 中加载预测,建议参考C++ Demo、Java Demo、Android/iOS Demo。
FAQ¶
问题:Compiled with WITH_GPU, but no GPU found in runtime
解答:检查本机是否支持 GPU 训练,如果不支持请使用 CPU 训练。如果在 docker 进行 GPU 训练,请使用 nvidia_docker 启动容器。
问题:Inufficient GPU memory to allocation. at [/paddle/paddle/fluid/platform/gpu_info.cc:262]
解答:正确设置 run.sh 脚本中CUDA_VISIBLE_DEVICES,确保显卡剩余内存大于需要内存。
使用示例:提供了动态离线量化完整示例,用于参考。