架构设计¶
Paddle Lite 架构侧重多硬件、高性能的支持,其主要设计思想如下
引入 Type system,强化多硬件、量化方法、data layout 的混合调度能力
硬件细节隔离,通过不同编译开关,对支持的任何硬件可以自由插拔
引入 MIR(Machine IR) 的概念,强化带执行环境下的优化支持
图优化模块和执行引擎实现了良好的解耦拆分,保证预测执行阶段的轻量和高效率
架构图如下
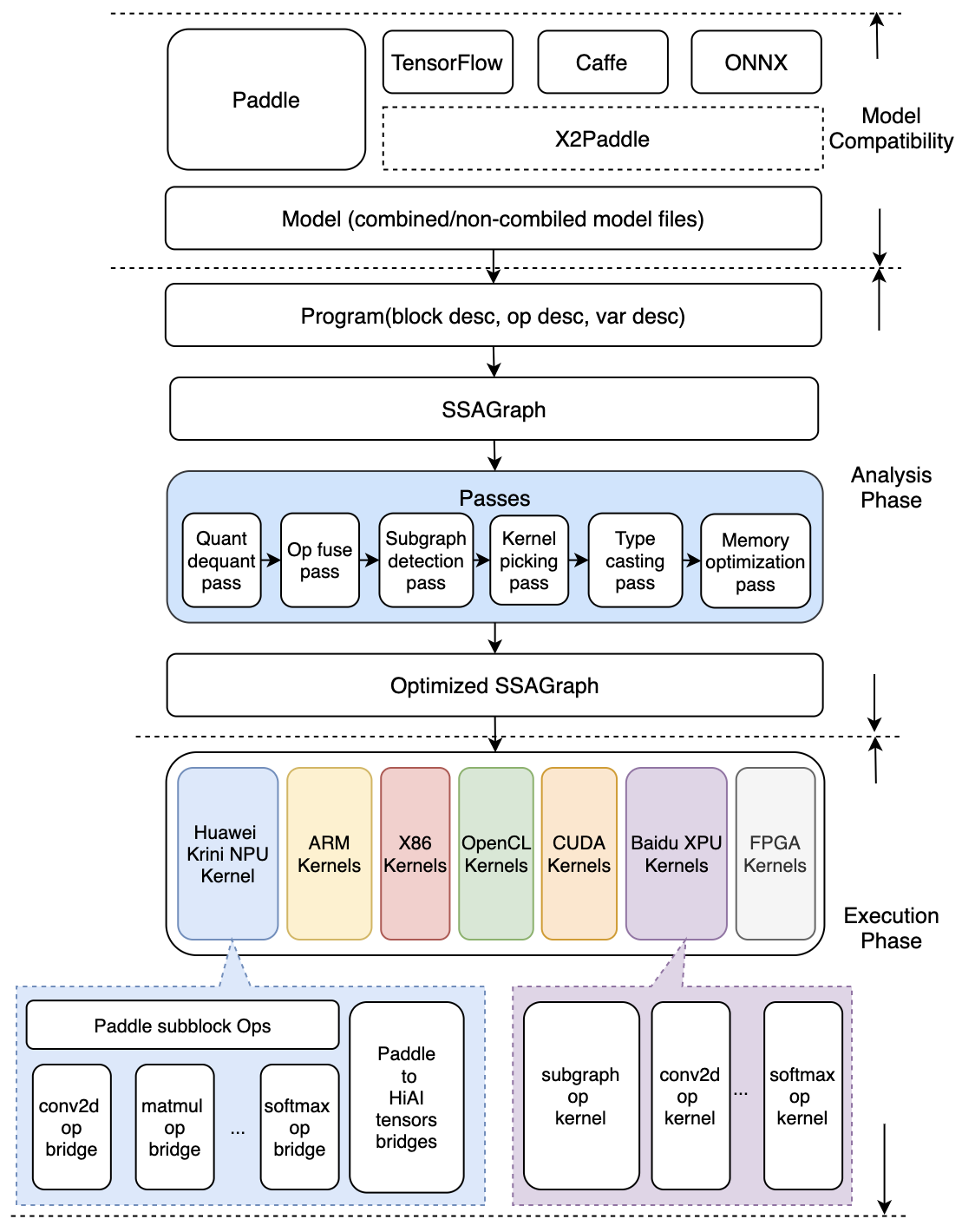
模型优化阶段和预测执行阶段的隔离设计¶
Analysis Phase为模型优化阶段,输入为Paddle的推理模型,通过Lite的模型加速和优化策略对计算图进行相关的优化分析,包含算子融合,计算裁剪,存储优化,量化精度转换、存储优化、Kernel优选等多类图优化手段。优化后的模型更轻量级,在相应的硬件上运行时耗费资源更少,并且执行速度也更快。
Execution Phase为预测执行阶段,输入为优化后的Lite模型,仅做模型加载和预测执行两步操作,支持极致的轻量级部署,无任何第三方依赖。
Lite设计了两套 API 及对应的预测库,满足不同场景需求:
CxxPredictor同时包含Analysis Phase和Execution Phase,支持一站式的预测任务,同时支持模型进行分析优化与预测执行任务,适用于对预测库大小不敏感的硬件场景。MobilePredictor只包含Execution Phase,保持预测部署和执行的轻量级和高性能,支持从内存或者文件中加载优化后的模型,并进行预测执行。
Execution Phase轻量级设计和实现¶
在预测执行阶段,每个 batch 实际执行只包含两个步骤执行
OpLite.InferShape基于输入推断得到输出的维度Kernel.Run,Kernel 相关参数均使用指针提前确定,后续无查找或传参消耗设计目标,执行时,只有 kernel 计算本身消耗
轻量级
Op及Kernel设计,避免框架额外消耗Op只有CreateKernels和InferShape两个重要职能Kernel只有Run职能
多硬件后端支持¶
硬件通用行为,使用
TargetWrapper模块做适配器适配,对上层框架提供一致界面框架上层策略保持硬件无关,如存储优化 (Memory optimize),计算剪枝 (Computation prune) 等,任何硬件接入均可直接复用
框架支持了硬件通用行为,特定硬件细节不做过多约束,各硬件可以自行实现并接入框架
计算模式上目前支持两种主流模型,一种是类似 X86, ARM CPU 等非异构设备;一种是 GPU,或 FPGA 等异构设备(支持 stream, event异步执行模式以及跨设备拷贝)
多硬件及算法混合调度支持¶
TensorTy 用来表示 Tensor 类型
struct TensorTy {
TargetType target;
PrecisionType precision;
DataLayout layout;
int deviceid;
};
enum class TargetType { kARM, kX86, kCUDA, kOpenCL };
enum class PrecisionType { kFP32, kFP16, kInt8, kInt16 };
enum class DataLayout { kNCHW, kNHWC };
注册 Kernel,确定特定 Kernel 的输入输出特征
REGISTER_LITE_KERNEL(
mul, kARM, kFloat, kNCHW, arm::MulCompute, def)
.BindInput("X", {LiteType::GetTensorTy(kARM, kFloat, kNCHW)})
.BindInput("Y", {LiteType::GetTensorTy(kARM, kFloat, kNCHW))})
.BindOutput("Out", {LiteType::GetTensorTy(kARM, kFloat, kNCHW)})
.Finalize();
同一个 Op 的不同 Kernel 类似函数重载
用于支持任意的混合调度:
标记模型中所有 tensor 的 Type
标记 Kernel 的 硬件、执行精度、data layout 等信息
全局做类型推断,当发现 tensor 传递中有类型冲突,采用 type cast 操作,通过插入特定功能 Op 来实现正确的传导

MIR 用于图分析优化¶
基于 Type System 的 SSA,通过 IR Pass 对计算图进行分析和优化:
支持对整个 graph 进行类型推断,发现类型冲突并加入 type cast op,来支持通用混合调度
计算剪枝 (Compute prune),比如去掉 scale(1), assign op 等
存储优化 (Memory optimize)
操作熔合 (Operator fuse)(已经支持 fc, conv_bn, ele_add+act 等6种 fuse 策略)
支持量化处理(已支持 Int8预测)