新增硬件¶
背景¶
深度学习技术在安防、交通、医疗、工业制造等行业获得了较广泛的应用,为了满足实际需求,越来越多算力更高、功耗更低的专用硬件被研发出来投向市场,涌现了诸如华为昇腾/麒麟 SoC 的达芬奇架构 NPU 、瑞芯微 RK/RV 系列 SoC 的 NPU 、寒武纪 MLU 、谷歌 TPU 和昆仑芯 XPU 等不同形态的硬件,以明显优于传统 CPU 、 GPU 的性能和功耗的特点,逐步获得市场的认可,被广泛用于服务器端、边缘端和移动端。
意义¶
良好的软件生态是硬件获得成功的关键,硬件驱动的兼容性、成熟的编译工具链、完善的 SDK 、 API 和文档、更多第三方深度学习框架的支持,都是影响硬件能否积攒用户、建立完善的软件生态的重要因素。特别的,在实际的项目部署过程中,推理引擎对硬件的支持尤为关键,它能屏蔽底层硬件细节,提供统一的接口,实现同一个模型在多种硬件间无缝迁移和异构计算,帮助应用提供方降低迁移成本并获得更高的性能;
Paddle Lite 是一款支持服务器端、边缘端和移动端场景的推理引擎,在设计之初就考虑了如何友好的支持不同形态的硬件(例如 CPU 、 GPU 、 DSP 、 FPGA 和 ASIC 等),主要表现在推理框架与硬件解耦合,提出了统一的图优化 Pass 层、算子层和 Kernel 层接口,在实现灵活配置多硬件间异构执行的同时,最大限度地减少适配过程中对框架的修改,真正做到硬件细节对用户透明;
Paddle Lite 支持的硬件目前已多达十余种,这其中不乏像华为 NPU 、芯原 NPU、联发科 APU 、颖脉( Imagination ) NNA、昆仑芯 XPU 和寒武纪 MLU 等一线芯片(或 IP )厂商研发的 ASIC 芯片,我们也希望更多的硬件(或 IP )厂商与我们合作,共建 Paddle Lite 和 PaddlePaddle 的硬件生态。
在阐述硬件接入的具体步骤前,我们将简单介绍下 Paddle Lite 的工作原理,即从读入模型文件到硬件执行过程中都经历了哪些步骤?
Paddle Lite 是如何工作的?¶
如下图所示, Paddle Lite 整个推理的过程,可以简单分成分析( Analysis phase )和执行( Execution phase )两个阶段,分析阶段包括 Paddle 模型文件的加载和解析、计算图的转化、图分析和优化、运行时程序的生成和执行等步骤。具体地,
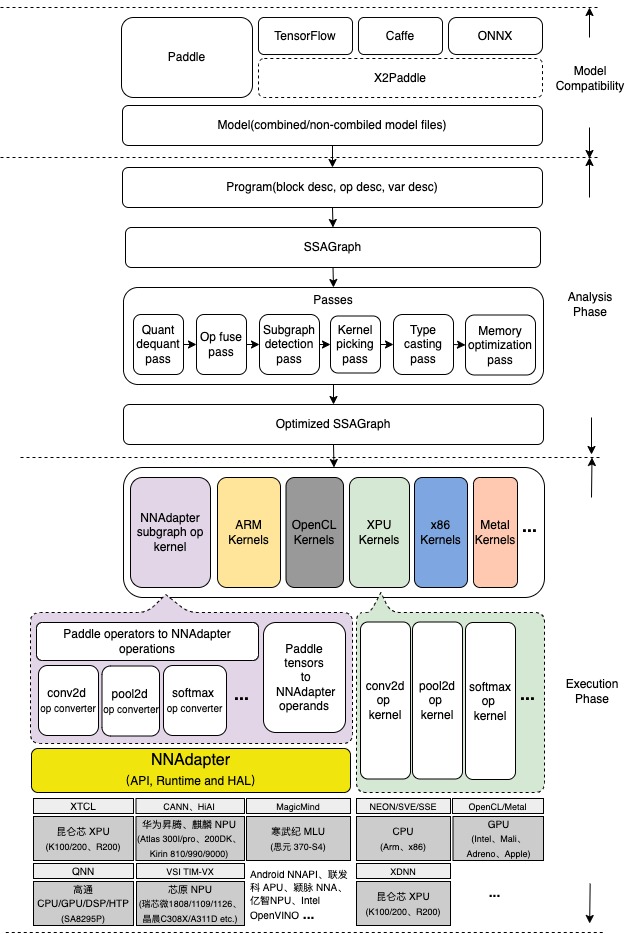
模型文件的加载和解析 Paddle 模型由程序( Program )、块( Block )、算子( Operator )和变量( Variable )组成(如下图所示,程序由若干块组成,块由若干算子和变量组成,变量包括中间变量和持久化变量,如卷积的权值),经序列化保存后形成 Combined 和 Non-combined 两种形式的模型文件, Non-combined 形式的模型由一个网络拓扑结构文件 model 和一系列以变量名命名的参数文件组成, Combined 形式的模型由一个网络拓扑结构文件 model 和一个合并后的参数文件 params 组成,其中网络拓扑结构文件是基于 Protocol Buffers 格式以 Paddle proto 文件规则序列化后的文件。现在以 Non-combined 格式的 Paddle 模型为例,将网络拓扑结构文件(要求文件名必须是 model )拖入到 Netron 工具即可图形化显示整个网络拓扑结构。

了解更多细节,可以访问具体的代码实现
计算图的转化 将每个块按照如下规则生成对应的计算图的过程:每个算子或变量都对应计算图的一个节点,节点间的有向边由算子的输入、输出决定(依赖关系确定边的方向),算子节点与变量节点相邻。为了方便调试,分析阶段的各个步骤都会将计算图的拓扑结构以 DOT 格式的文本随 log 打印,可以将 DOT 文本复制、粘贴到 webgraphviz 进行可视化,如下图所示,黄色矩形节点为算子,椭圆形节点为变量。

了解更多细节,可以访问具体代码实现
图分析和优化 将一系列 pass (优化器,用于描述一个计算图优化生成另一个计算图的算法过程)按照一定的顺序依次应用到每个块对应的计算图的过程,包括量化信息处理、算子融合、 Kernel 选择、类型转化、上下文创建、内存复用优化和子图检测等,实现不同设备的适配、高效的计算和更少的内存占用。其中,算子融合作为一种行之有效的优化策略,普遍存在于各种推理框架中,它通过相邻算子间的融合,减少访存和计算量,有效提高模型的整体性能,例如前一步骤的计算图中, conv_bn_fuse_pass 、 conv_activation_fuse_pass 分别以 conv2d + batch_norm 和 conv2d + relu 为 pattern ,先后搜索整个计算图并完成融合,如下图所示, conv2d + batch_norm + relu 结构,经过前面的 pass 处理后只保留了 1 个 conv2d 算子。

了解更多细节,可以访问具体代码实现
Pass 的注册方法、管理机制可以参考文档新增 Pass , Pass 列表是指按照规定的顺序处理的 Pass 的集合,它使用 std::vector<<std::string>> 存储,每个元素代表已注册到框架的 Pass 的名称,如果需要在 Pass 列表中新增一个 Pass ,只需在合适的位置增加一个字符串即可,例如,为了可视化 conv_bn_fuse_pass 优化后的计算图,可以在它后面增加一个名为 graph_visualize_pass 的特殊 Pass ,用于在 log 中生成以 DOT 文本的表示计算图结构。
diff --git a/lite/core/optimizer/optimizer.cc b/lite/core/optimizer/optimizer.cc --- a/lite/core/optimizer/optimizer.cc +++ b/lite/core/optimizer/optimizer.cc class Optimizer { "weight_quantization_preprocess_pass", // "lite_conv_elementwise_fuse_pass", // conv-elemwise-bn "lite_conv_bn_fuse_pass", // + "graph_visualize_pass", "lite_conv_elementwise_fuse_pass", // conv-bn-elemwise "lite_conv_conv_fuse_pass", // // TODO(Superjomn) Refine the fusion related design to select fusion
运行时程序的生成和执行 按照拓扑顺序遍历优化后的计算图,生成算子和 Kernel 列表的过程,它基于 generate_program_pass 实现。具体地,只遍历计算图中的算子节点,提取所携带的算子和 Kernel (经过 static_kernel_pick_pass 选取的、适合目标硬件的、最优的 Kernel )对象,以 Instruction 封装后按顺序依次存放到 RuntimeProgram 对象。运行时程序的执行也非常简单,即依次遍历 RuntimeProgram 对象存储的每个 Instruction ,调用其算子对象的 CheckShape 和 InfereShape 方法,最后执行 Kernel 对象的 Launch 方法。
硬件接入方式¶
按照层次硬件提供给开发者的接口一般可以分为两类:
通用编程接口( Low Level )
通用的编程语言:例如 NVIDIA 的 CUDA 、 Knorons 的 OpenCL 和寒武纪的 BANG-C 语言等;
高性能库函数:例如 NVIDIA 的 cuDNN 、 Intel 的 MKL 和 MKL-DNN 等。
优点是灵活,但缺点也显而易见,性能的好坏取决于负责接入框架的研发同学的能力和经验,更依赖对硬件的熟悉程度;
中间表示层( Intermediate Representation , IR )接口( High Level )
组网 IR 和运行时 API :例如 NVIDIA 的 TensorRT 、 Intel 的 nGraph 、华为 HiAI IR 和昆仑芯的 XTCL 接口。
优点是屏蔽硬件细节,模型的优化、生成和执行由运行时库完成,对负责接入框架的研发同学要求较低,性能取决于硬件厂商(或 IP 提供商)的研发能力,相对可控;
提供这两类接口的硬件可分别按照如下两种接入方式接入到框架:
算子 Kernel 接入方式¶
主要涉及 Paddle Lite 架构图中算子、Kernel层的硬件适配工作,具体是在 lite/kernels 下增加待新增硬件的目录,为每个算子实现待新增硬件的 Kernel ,具体可参考新增 OP 中”添加 Argmax Kernel 并绑定”步骤;
为了将硬件细节与 Kernel 的实现剥离,减少冗余代码,建议在 lite/backends 目录下增加待新增硬件的目录,利用硬件提供的编程接口实现诸如 gemm 等通用数学运算,向 Kernel 提供统一的数学运算接口;
其它诸如添加新增硬件的 Target 、 Place 、 Context 等方面的内容可参考即将详细介绍的”子图接入方式”中的相关章节。
子图接入方式¶
硬件要求提供以下接口:
Graph 组网接口,必须保证不同硬件型号、不同软件版本间的兼容性;
Graph 生成 Model 的接口;
设置 Model 的输入、输出张量和 Model 执行的运行时接口;
输入、输出张量的内存管理接口。
具体可参考华为 HiAI DDK v330 、瑞芯微 rknpu_ddk 和 MTK Neuron Adapter(类似 Android NNAPI )进行接口设计。
什么是子图? 将计算图依据某种规则分割为多个部分,每个部分都被称为一个子图,它包含一个或多个算子和变量,规则一般依据硬件支持能力而定。
框架如何实现子图检测和融合? 在” Paddle Lite 是如何工作的?”章节中的”图分析和优化”步骤曾提到了子图检测 Pass ,它依据硬件对 Paddle 算子的支持情况,将每个块对应的计算图分别进行分割,生成一个或多个子图,如下图所示,具体包括以下三个步骤:

算子标记 按照拓扑顺序依次遍历计算图中每个算子,依据已注册的 Paddle 算子->硬件IR的转换表,标记能够转为硬件 IR 的算子。例如,在上图第一幅图的计算图中,包含 10 个算子 Op1~Op10 ,假设 Op1 、 Op3 和 Op10 不能够转为硬件 IR ,如第二幅图所示,这三个算子会被标记为默认颜色(黄色),代表使用 CPU Kernel 进行计算,而 Op2 、 Op4 、 Op5 、 Op6 、 Op7 、 Op8 和 Op9 则标记为红色,代表这些算子可以被转换成硬件的 IR 。
子图检测 对标记的算子作进一步分析,采用反向 DFS 算法将相邻的算子标记为同一个子图。例如上图第三幅图所示, Op2 被单独分到子图 1 ,而 Op4 、 Op5 、 Op6 、 Op7 、 Op8 和 Op9 则划到子图 2 。
子图融合 为了减少硬件与 Host 端过多的数据拷贝而带来的额外开销,如果某个子图的算子过少,则删除该子图,即它所包含的所有算子都不会放在目标硬件上执行,然后对保留下来的子图进行算子融合,具体是利用一个子图算子代替该子图包含的所有算子,但所有算子信息将以新的块( Block desc )的形式保存在程序( Program desc )中,块索引则以属性的形式保存子图算子中。
由于子图检测代码较为通用,在硬件接入的过程中无需做过多的修改,只需参照着增加对应硬件的 subgraph pass 即可,具体可参考 NNAdapterSubgraphPass 的实现。
框架如何执行子图? 当计算图被分割成若干普通算子和多个子图算子后(如上图的第四幅图所示,包含 4 个普通算子 Op1 、 Op2 、 Op3 和 Op10 , 1 个子图算子 Op1 ),通过”运行时程序的生成和执行”步骤将普通算子( Kernel )和子图算子( Kernel ,参考 NNAdapter subgraph op kernel 保存在运行时程序中,当运行时程序执行时,如果遇到子图算子,则执行如下步骤:
读取并加载子图中的原始算子 通过保存在子图算子中的 sub_block 属性,在程序描述对象( Program desc )中找到相应的块描述对象( Block desc ),然后依次读取算子描述对象( Op desc ),根据算子类型创建算子对象。
加载原始算子的 Kernel ,创建原始运行时程序 通过算子描述对象中保存的 kKernelTypeAttr 属性找到对应的 Kernel ,与上个步骤获得的算子对象,一起封装在 Instruction 对象中,所有算子的 Instruction 对象便组成了子图原始运行时程序。
原始算子转为硬件 IR 、组网生成 Graph 遍历子图中的所有原始算子(已按照拓扑顺序排序),依次将每个原始算子转为硬件 IR ,具体地,通过算子类型查询是否注册对应的转换器( Op converter ),如果已注册,则执行转换器器实现算子到硬件IR的转换,并调用硬件组网 API 生成 Graph 。转换器是子图接入方式最重要的模块,也是工作量最大的部分,为了尽可能将算子放到硬件上执行,应当为每个算子增加相应的转换器,具体实现可参考 NNAdapter unary activation op converter 。
Graph 生成 Model ,设置输入、输出张量:当子图中所有原始算子都转换完成后,调用硬件提供的接口将 Graph 生成 Model 并设置输入、输出张量。
执行 Model ,读取输出张量的数据:将原始输入张量的数据拷贝至(或将指针传递至,以防止重复拷贝实现 ZeroCopy )硬件 Model 的输入张量,然后调用硬件提供 Model 执行接口,待执行结束后将硬件输出张量的数据拷贝至原始输出张量。
了解上述三个步骤的更多细节,可以访问具体代码实现
前四个步骤一般在子图算子 Kernel 第一次运行的时候执行,只有在输入尺寸发生变更且需要重新生成 Model 时,才会回到步骤三重新执行。
为什么需要创建原始运行时程序?在硬件 IR 转换失败、 Graph 或 Model 生成失败的时候,例如不同硬件型号、不同软件版本导致的不兼容,或者运行在不支持该硬件的设备上时,就需要回退到原始运行时程序进行执行,完成推理任务。
硬件接入时需要做哪些代码改动?
参考最近接入的 Imagination NNA 的 Pull Request(PR) 的代码修改https://github.com/PaddlePaddle/Paddle-Lite/pull/4335
代码提交、 Review 、合入机制、 CI 机制¶
参考 Docker 统一编译环境搭建 中的 Docker 开发环境(由于代码提交时会使用 git pre-commit hooks ,对 clang-format 版本约束)
注册 github 账户,将 Paddle Lite 代码仓库 Fork 到自己的账户.
将自己 github 账户的 Paddle Lite 仓库克隆到本地。
# git clone https://github.com/UserName/Paddle-Lite
# cd Paddle-Lite
创建本地分支:从 develop 分支创建一个新的本地分支,命名规则为 UserName/FeatureName ,例如 hongming/print_ssa_graph
$ git checkout -b UserName/FeatureName
启用 pre-commit 钩子: pre-commit 作为 git 预提交钩子,帮助我们在 git commit 时进行自动代码( C++,Python )格式化和其它检查(如每个文件只有一个 EOL ,Git 中不要添加大文件等),可通过以下命令进行安装(注意:pre-commit 测试是 Travis-CI 中单元测试的一部分,不满足钩子的 PR 不能被提交到 Paddle Lite ):
$ pip install pre-commit
$ pre-commit install
修改代码:提交代码前通过 git status 和 git diff 命令查看代码改动是否符合预期,避免提交不必要或错误的修改。
$ git status
On branch hongming/print_ssa_graph
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
(commit or discard the untracked or modified content in submodules)
modified: lite/core/optimizer/optimizer.h
$ git diff
diff --git a/lite/core/optimizer/optimizer.h b/lite/core/optimizer/optimizer.h
index 00e9e07..1b273af 100644
--- a/lite/core/optimizer/optimizer.h
+++ b/lite/core/optimizer/optimizer.h
@@ -55,7 +55,8 @@ class Optimizer {
if (passes.empty()) {
std::vector<std::string> passes_local{
- {"lite_quant_dequant_fuse_pass", //
+ {"graph_visualze",
+ "lite_quant_dequant_fuse_pass", //
"lite_conv_elementwise_fuse_pass", // conv-elemwise-bn
提交代码:git add 命令添加需要修改的文件,放弃提交可用 git reset 命令,放弃修改可使用 git checkout – [file_name] 命令,每次代码提交时都需要填写说明,以便让他人知道这次提交做了哪些修改,可通过 git commit 命令完成,修改提交说明可通过 git commit –amend 命令;为了触发 CI ,提交说明最后结束前必须回车换行,然后添加 test=develop ,如果本次提交的 Pull request 仅修改 doc 目录下的文档,则额外加上 test=document_fix 加快 CI 流水线。
$ git add lite/core/optimizer/optimizer.h
$ git status
On branch hongming/print_ssa_graph
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: lite/core/optimizer/optimizer.h
$ git commit -m "Add graph_visualze pass to output ssa graph
> test=develop"
CRLF end-lines remover...................................................Passed
Check for added large files..............................................Passed
Check for merge conflicts................................................Passed
Check for broken symlinks................................................Passed
Detect Private Key.......................................................Passed
Fix End of Files.........................................................Passed
clang-format.............................................................Passed
cpplint..................................................................Passed
copyright_checker........................................................Passed
[hongming/print_ssa_graph 75ecdce] Add graph_visualze pass to output ssa graph test=develop
1 file changed, 2 insertions(+), 1 deletion(-)
同步本地仓库代码:在准备发起 Pull Request 前,需要将原仓库 https://github.com/PaddlePaddle/Paddle-Lite 的 develop 分支的最新代码同步到本地仓库的新建分支。首先通过 git remote -v 命令查看当前远程仓库的名字,然后通过 git remote add 命令添加原 Paddle Lite 仓库地址,最后使用 git fetch 和 git pull 命令将本地分支更新到最新代码。
$ git remote -v
origin https://github.com/UserName/Paddle-Lite.git (fetch)
origin https://github.com/UserName/Paddle-Lite.git (push)
$ git remote add upstream https://github.com/PaddlePaddle/Paddle-Lite
$ git remote
origin
upstream
$ git fetch upstream
remote: Enumerating objects: 105, done.
remote: Counting objects: 100% (105/105), done.
remote: Compressing objects: 100% (6/6), done.
remote: Total 142 (delta 99), reused 100 (delta 99), pack-reused 37
Receiving objects: 100% (142/142), 52.47 KiB | 2.00 KiB/s, done.
Resolving deltas: 100% (103/103), completed with 45 local objects.
From https://github.com/PaddlePaddle/Paddle-Lite
a1527e8..d6cdb1e develop -> upstream/develop
2136df9..17a58b6 gh-pages -> upstream/gh-pages
1091ab8..55be873 image-sr-v2 -> upstream/image-sr-v2
* [new branch] release/v2.2.0 -> upstream/release/v2.2.0
* [new tag] v2.2.0 -> v2.2.0
$ git branch
develop
* hongming/print_ssa_graph
$ git pull upstream develop
From https://github.com/PaddlePaddle/Paddle-Lite
* branch develop -> FETCH_HEAD
Removing lite/kernels/npu/bridges/transpose_op_test.cc
Removing lite/kernels/npu/bridges/batch_norm_op_test.cc
Merge made by the 'recursive' strategy.
lite/kernels/npu/bridges/batch_norm_op_test.cc | 168 ------------------------------------------------------------------------------------------------
lite/kernels/npu/bridges/transpose_op.cc | 2 +-
lite/kernels/npu/bridges/transpose_op_test.cc | 153 ---------------------------------------------------------------------------------------
lite/tests/kernels/CMakeLists.txt | 4 +--
lite/tests/kernels/batch_norm_compute_test.cc | 2 ++
lite/tests/kernels/transpose_compute_test.cc | 44 ++++++++++++-------------
mobile/test/CMakeLists.txt | 6 ++++
mobile/test/net/test_mobilenet_male2fe.cpp | 66 ++++++++++++++++++++++++++++++++++++++
8 files changed, 99 insertions(+), 346 deletions(-)
delete mode 100644 lite/kernels/npu/bridges/batch_norm_op_test.cc
delete mode 100644 lite/kernels/npu/bridges/transpose_op_test.cc
create mode 100644 mobile/test/net/test_mobilenet_male2fe.cpp
Push 到远程仓库:将本地的修改推送到自己账户下的 Paddle Lite 仓库,即 https://github.com/UserName/Paddle-Lite 。
$ git branch
develop
* hongming/print_ssa_graph
$ git push origin hongming/print_ssa_graph
Counting objects: 8, done.
Delta compression using up to 2 threads.
Compressing objects: 100% (8/8), done.
Writing objects: 100% (8/8), 868 bytes | 0 bytes/s, done.
Total 8 (delta 6), reused 0 (delta 0)
remote: Resolving deltas: 100% (6/6), completed with 6 local objects.
remote:
remote: Create a pull request for 'hongming/print_ssa_graph' on GitHub by visiting:
remote: https://github.com/UserName/Paddle-Lite/pull/new/hongming/print_ssa_graph
remote:
To https://github.com/UserName/Paddle-Lite.git
* [new branch] hongming/print_ssa_graph -> hongming/print_ssa_graph
发起 Pull Request :登录 github ,在自己账户下找到并进入 UserName/Paddle-Lite 仓库,这时会自动提示创建 Pull Request ,点击 Create Pull Request 按钮,一般来说会自动选择比较更改的仓库和分支,如果需要手动设置,可将 base repository 选择为 PaddlePaddle/Paddle-Lite , base 分支为 develop ,然后将 head repository 选择为 UserName/Paddle-Lite ,compare分支为 hongming/print_ssa_graph 。 PR(Pull Request) 的标题必须用英文概括本次提交的修改内容,例如修复了什么问题,增加了什么功能。同时,为了便于其他人快速得知该PR影响了哪些模块,应该在标题前添加中括号 + 模块名称进行标识,例如 “[HuaweiKirinNPU][KunlunxinXPU] Temporarily toggle printing ssa graph, test=develop” 。 PR 的描述必须详细描述本次修改的原因/背景、解决方法、对其它模块会产生何种影响(例如生成库的大小增量是多少),性能优化的 PR 需要有性能对比数据等。
签署 CLA 协议:在首次向 Paddle Lite 提交 Pull Request 时,您需要您签署一次 CLA(Contributor License Agreement) 协议,以保证您的代码可以被合入。
等待 CI 测试完成:您在 Pull Request 中每提交一次新的 commit 后,都会触发一系列 CI 流水线(根据场景/硬件的不同,一般会有多个流水线),它将会在几个小时内完成,只需保证带有 Required 的流水线通过即可。例如下图所示,每项流水线测试通过后,都会在前面打勾,否则打叉,可点击 Details 查看日志定位错误原因:

PR Review :每个 PR 需要至少一个评审人 apporve 后才能进行代码合入,而且在请评审人 review 代码前,必须保证 CI 测试完成并通过全部测试项,否则评审人一般不做评审。根据 PR 修改的模块不同,代码评审人选择也不一样。例如:涉及到 Core 和 API 模块,需要 @Superjomn 进行 Review ,涉及到 Subgraph 相关的修改,需要 @hong19860320 或 @zhupengyang 进行 Review 。评审人的每个意见都必须回复,同意评审意见且按其修改完的,给个简单的 Done 即可,对评审意见不同意的,请给出您自己的反驳理由。
PR 合入:一般 PR 会有多次 commit ,原则上是尽量少的 commit ,且每个 commit 的内容不能太随意。在合入代码时,需要对多个 commit 进行 squash commits after push ,该 PR 在评审人 approve 且 CI 完全通过后,会出现 “Squash and Merge” 按钮,如上图所示,届时可以联系 Paddle 同学完成 PR 的合入。
硬件接入完成标志¶
代码合入到 develop 分支
提供完善的文档和 Demo
参考 ImaginationNNA 的格式编写文档并提供 Demo 压缩包(由 Paddle 同学上传到百度云)
如果编译环境的 docker 镜像与 Paddle Lite 所提供的不一致,需要额外提供构建docker镜像的 docker file ,保证用户能顺利编译获得产出
厂商提供测试设备,增加 CI 流水线(由 Paddle 同学负责)
双方兼容性认证