
使用Paddle-TensorRT库预测¶
NVIDIA TensorRT 是一个高性能的深度学习预测库,可为深度学习推理应用程序提供低延迟和高吞吐量。PaddlePaddle 采用子图的形式对TensorRT进行了集成,即我们可以使用该模块来提升Paddle模型的预测性能。在这篇文章中,我们会介绍如何使用Paddle-TRT子图加速预测。
概述¶
当模型加载后,神经网络可以表示为由变量和运算节点组成的计算图。如果我们打开TRT子图模式,在图分析阶段,Paddle会对模型图进行分析同时发现图中可以使用TensorRT优化的子图,并使用TensorRT节点替换它们。在模型的推断期间,如果遇到TensorRT节点,Paddle会调用TensorRT库对该节点进行优化,其他的节点调用Paddle的原生实现。TensorRT除了有常见的OP融合以及显存/内存优化外,还针对性的对OP进行了优化加速实现,降低预测延迟,提升推理吞吐。
目前Paddle-TRT支持静态shape模式以及/动态shape模式。在静态shape模式下支持图像分类,分割,检测模型,同时也支持Fp16, Int8的预测加速。在动态shape模式下,除了对动态shape的图像模型(FCN, Faster rcnn)支持外,同时也对NLP的Bert/Ernie模型也进行了支持。
Paddle-TRT的现有能力:
1)静态shape:
支持模型:
分类模型 |
检测模型 |
分割模型 |
|---|---|---|
Mobilenetv1 |
yolov3 |
ICNET |
Resnet50 |
SSD |
UNet |
Vgg16 |
Mask-rcnn |
FCN |
Resnext |
Faster-rcnn |
|
AlexNet |
Cascade-rcnn |
|
Se-ResNext |
Retinanet |
|
GoogLeNet |
Mobilenet-SSD |
|
DPN |
Fp16:
Calib Int8:
优化信息序列化:
加载PaddleSlim Int8模型:
2)动态shape:
支持模型:
图像 |
NLP |
|---|---|
FCN |
Bert |
Faster_RCNN |
Ernie |
Fp16:
Calib Int8:
优化信息序列化:
加载PaddleSlim Int8模型:
Note:
从源码编译时,TensorRT预测库目前仅支持使用GPU编译,且需要设置编译选项TENSORRT_ROOT为TensorRT所在的路径。
Windows支持需要TensorRT 版本5.0以上。
使用Paddle-TRT的动态shape输入功能要求TRT的版本在6.0以上。
一:环境准备¶
使用Paddle-TRT功能,我们需要准备带TRT的Paddle运行环境,我们提供了以下几种方式:
1)linux下通过pip安装
请从 whl list 下载带trt且与自己环境一致的whl包,并通过pip安装
2)使用docker镜像
# 拉取镜像,该镜像预装Paddle 2.2 Python环境,并包含c++的预编译库,lib存放在主目录~/ 下。
docker pull paddlepaddle/paddle:latest-dev-cuda11.0-cudnn8-gcc82
sudo nvidia-docker run --name your_name -v $PWD:/paddle --network=host -it paddlepaddle/paddle:latest-dev-cuda11.0-cudnn8-gcc82 /bin/bash
3)手动编译 编译的方式请参照 编译文档
Note1: cmake 期间请设置 TENSORRT_ROOT (即TRT lib的路径), WITH_PYTHON (是否产出python whl包, 设置为ON)选项。
Note2: 编译期间会出现TensorRT相关的错误。
需要手动在 NvInfer.h (trt5) 或 NvInferRuntime.h (trt6) 文件中为 class IPluginFactory 和 class IGpuAllocator 分别添加虚析构函数:
virtual ~IPluginFactory() {};
virtual ~IGpuAllocator() {};
需要将 NvInferRuntime.h (trt6)中的 protected: ~IOptimizationProfile() noexcept = default;
改为
virtual ~IOptimizationProfile() noexcept = default;
二:API使用介绍¶
在 预测流程 一节中,我们了解到Paddle Inference预测包含了以下几个方面:
配置推理选项
创建predictor
准备模型输入
模型推理
获取模型输出
使用Paddle-TRT 也是遵照这样的流程。我们先用一个简单的例子来介绍这一流程(我们假设您已经对Paddle Inference有一定的了解,如果您刚接触Paddle Inference,请访问 这里 对Paddle Inference有个初步认识。):
import numpy as np
import paddle.inference as paddle_infer
def create_predictor():
config = paddle_infer.Config("./resnet50/model", "./resnet50/params")
config.enable_memory_optim()
config.enable_use_gpu(1000, 0)
# 打开TensorRT。此接口的详细介绍请见下文
config.enable_tensorrt_engine(workspace_size = 1 << 30,
max_batch_size = 1,
min_subgraph_size = 3,
precision_mode=paddle_infer.PrecisionType.Float32,
use_static = False, use_calib_mode = False)
predictor = paddle_infer.create_predictor(config)
return predictor
def run(predictor, img):
# 准备输入
input_names = predictor.get_input_names()
for i, name in enumerate(input_names):
input_tensor = predictor.get_input_handle(name)
input_tensor.reshape(img[i].shape)
input_tensor.copy_from_cpu(img[i].copy())
# 预测
predictor.run()
results = []
# 获取输出
output_names = predictor.get_output_names()
for i, name in enumerate(output_names):
output_tensor = predictor.get_output_handle(name)
output_data = output_tensor.copy_to_cpu()
results.append(output_data)
return results
if __name__ == '__main__':
pred = create_predictor()
img = np.ones((1, 3, 224, 224)).astype(np.float32)
result = run(pred, [img])
print ("class index: ", np.argmax(result[0][0]))
通过例子我们可以看出,我们通过 enable_tensorrt_engine 接口来打开TensorRT选项的。
config.enable_tensorrt_engine(workspace_size = 1 << 30,
max_batch_size = 1,
min_subgraph_size = 3,
precision_mode=paddle_infer.PrecisionType.Float32,
use_static = False, use_calib_mode = False)
接下来让我们看下该接口中各个参数的作用:
workspace_size,类型:int,默认值为1 << 30 (1G)。指定TensorRT使用的工作空间大小,TensorRT会在该大小限制下筛选最优的kernel执行预测运算。
max_batch_size,类型:int,默认值为1。需要提前设置最大的batch大小,运行时batch大小不得超过此限定值。
min_subgraph_size,类型:int,默认值为3。Paddle-TRT是以子图的形式运行,为了避免性能损失,当子图内部节点个数大于 min_subgraph_size 的时候,才会使用Paddle-TRT运行。
precision_mode,类型:paddle_infer.PrecisionType, 默认值为 paddle_infer.PrecisionType.Float32。指定使用TRT的精度,支持FP32(Float32),FP16(Half),Int8(Int8)。若需要使用Paddle-TRT int8离线量化校准,需设定precision为 paddle_infer.PrecisionType.Int8 , 且设置 use_calib_mode 为True。
use_static,类型:bool, 默认值为False。如果指定为True,在初次运行程序的时候会将TRT的优化信息进行序列化到磁盘上,下次运行时直接加载优化的序列化信息而不需要重新生成。
use_calib_mode,类型:bool, 默认值为False。若要运行Paddle-TRT int8离线量化校准,需要将此选项设置为True。
Int8量化预测¶
神经网络的参数在一定程度上是冗余的,在很多任务上,我们可以在保证模型精度的前提下,将Float32的模型转换成Int8的模型,从而达到减小计算量降低运算耗时、降低计算内存、降低模型大小的目的。使用Int8量化预测的流程可以分为两步:1)产出量化模型;2)加载量化模型进行Int8预测。下面我们对使用Paddle-TRT进行Int8量化预测的完整流程进行详细介绍。
1. 产出量化模型
目前,我们支持通过两种方式产出量化模型:
使用TensorRT自带Int8离线量化校准功能。校准即基于训练好的FP32模型和少量校准数据(如500~1000张图片)生成校准表(Calibration table),预测时,加载FP32模型和此校准表即可使用Int8精度预测。生成校准表的方法如下:
指定TensorRT配置时,将 precision_mode 设置为 paddle_infer.PrecisionType.Int8 并且设置 use_calib_mode 为 True。
config.enable_tensorrt_engine( workspace_size=1<<30, max_batch_size=1, min_subgraph_size=5, precision_mode=paddle_infer.PrecisionType.Int8, use_static=False, use_calib_mode=True)准备500张左右的真实输入数据,在上述配置下,运行模型。(Paddle-TRT会统计模型中每个tensor值的范围信息,并将其记录到校准表中,运行结束后,会将校准表写入模型目录下的 _opt_cache 目录中)
如果想要了解使用TensorRT自带Int8离线量化校准功能生成校准表的完整代码,请参考 这里 的demo。
使用模型压缩工具库PaddleSlim产出量化模型。PaddleSlim支持离线量化和在线量化功能,其中,离线量化与TensorRT离线量化校准原理相似;在线量化又称量化训练(Quantization Aware Training, QAT),是基于较多数据(如>=5000张图片)对预训练模型进行重新训练,使用模拟量化的思想,在训练阶段更新权重,实现减小量化误差的方法。使用PaddleSlim产出量化模型可以参考文档:
离线量化的优点是无需重新训练,简单易用,但量化后精度可能受影响;量化训练的优点是模型精度受量化影响较小,但需要重新训练模型,使用门槛稍高。在实际使用中,我们推荐先使用TRT离线量化校准功能生成量化模型,若精度不能满足需求,再使用PaddleSlim产出量化模型。
2. 加载量化模型进行Int8预测
加载量化模型进行Int8预测,需要在指定TensorRT配置时,将 precision_mode 设置为 paddle_infer.PrecisionType.Int8 。
若使用的量化模型为TRT离线量化校准产出的,需要将 use_calib_mode 设为 True :
config.enable_tensorrt_engine( workspace_size=1<<30, max_batch_size=1, min_subgraph_size=5, precision_mode=paddle_infer.PrecisionType.Int8, use_static=False, use_calib_mode=True)完整demo请参考 这里 。
若使用的量化模型为PaddleSlim量化产出的,需要将 use_calib_mode 设为 False :
config.enable_tensorrt_engine( workspace_size=1<<30, max_batch_size=1, min_subgraph_size=5, precision_mode=paddle_infer.PrecisionType.Int8, use_static=False, use_calib_mode=False)完整demo请参考 这里 。
运行Dynamic shape¶
从1.8 版本开始, Paddle对TRT子图进行了Dynamic shape的支持。 使用接口如下:
config.enable_tensorrt_engine(
workspace_size = 1<<30,
max_batch_size=1, min_subgraph_size=5,
precision_mode=paddle_infer.PrecisionType.Float32,
use_static=False, use_calib_mode=False)
min_input_shape = {"image":[1,3, 10, 10]}
max_input_shape = {"image":[1,3, 224, 224]}
opt_input_shape = {"image":[1,3, 100, 100]}
config.set_trt_dynamic_shape_info(min_input_shape, max_input_shape, opt_input_shape)
从上述使用方式来看,在 config.enable_tensorrt_engine 接口的基础上,新加了一个config.set_trt_dynamic_shape_info 的接口。
该接口用来设置模型输入的最小,最大,以及最优的输入shape。 其中,最优的shape处于最小最大shape之间,在预测初始化期间,会根据opt shape对op选择最优的kernel。
调用了 config.set_trt_dynamic_shape_info 接口,预测器会运行TRT子图的动态输入模式,运行期间可以接受最小,最大shape间的任意的shape的输入数据。
四:Paddle-TRT子图运行原理¶
PaddlePaddle采用子图的形式对TensorRT进行集成,当模型加载后,神经网络可以表示为由变量和运算节点组成的计算图。Paddle TensorRT实现的功能是对整个图进行扫描,发现图中可以使用TensorRT优化的子图,并使用TensorRT节点替换它们。在模型的推断期间,如果遇到TensorRT节点,Paddle会调用TensorRT库对该节点进行优化,其他的节点调用Paddle的原生实现。TensorRT在推断期间能够进行Op的横向和纵向融合,过滤掉冗余的Op,并对特定平台下的特定的Op选择合适的kernel等进行优化,能够加快模型的预测速度。
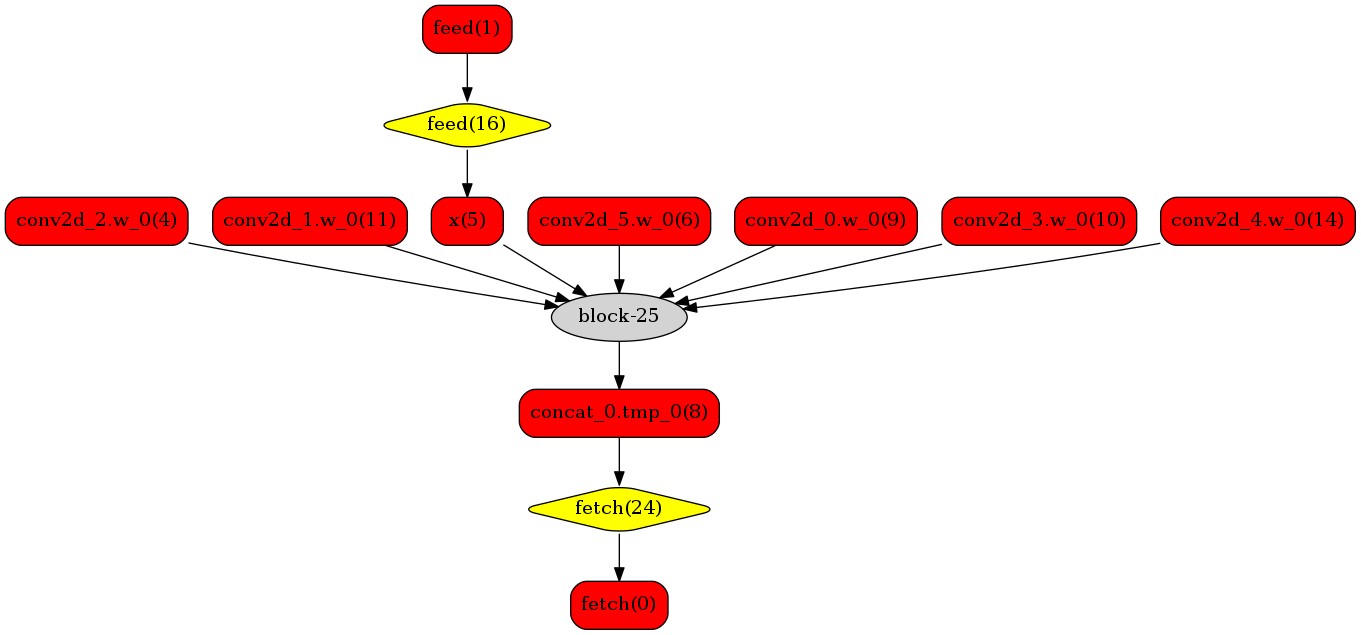
下图使用一个简单的模型展示了这个过程:
原始网络
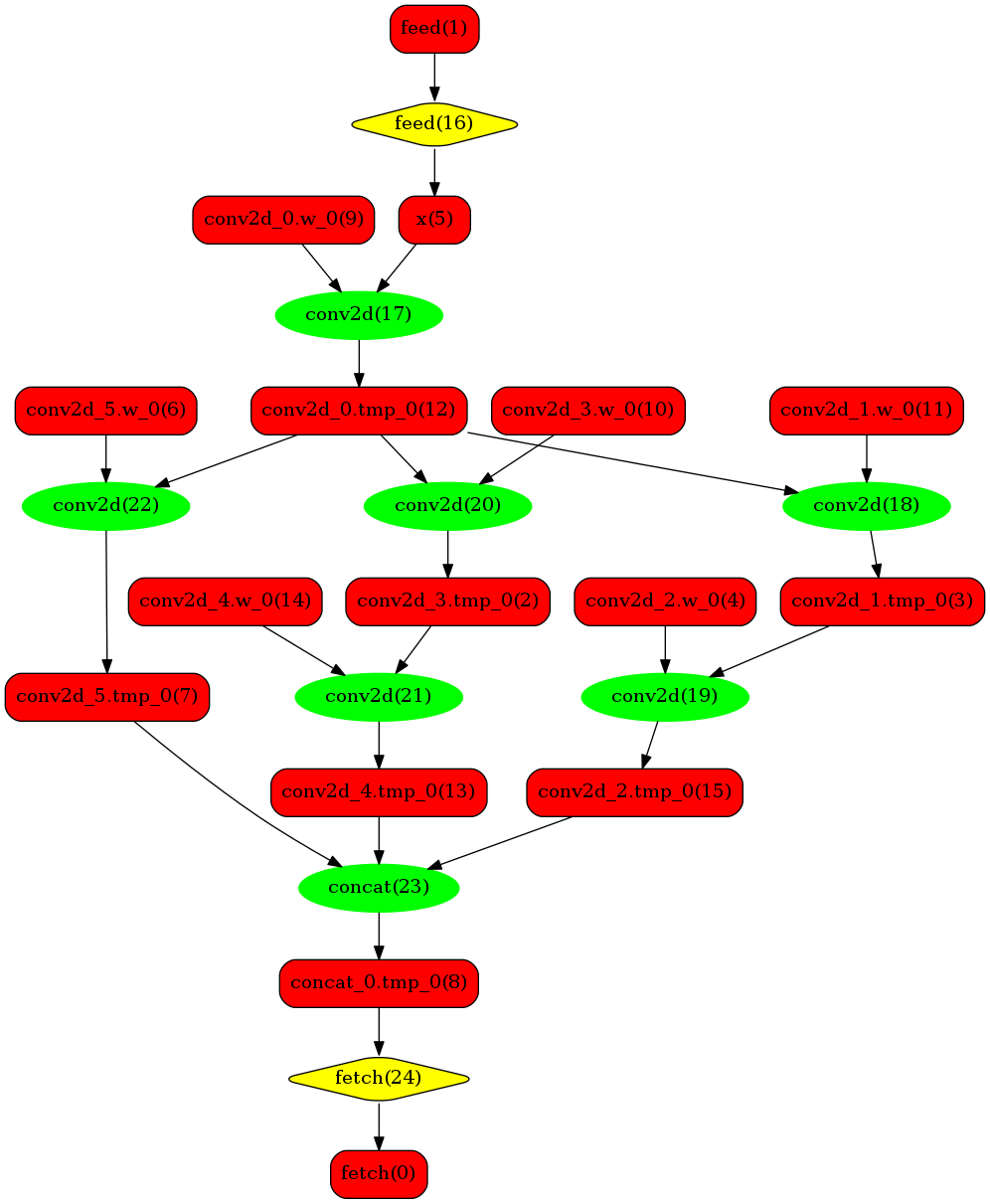
转换的网络
我们可以在原始模型网络中看到,绿色节点表示可以被TensorRT支持的节点,红色节点表示网络中的变量,黄色表示Paddle只能被Paddle原生实现执行的节点。那些在原始网络中的绿色节点被提取出来汇集成子图,并由一个TensorRT节点代替,成为转换后网络中的 block-25 节点。在网络运行过程中,如果遇到该节点,Paddle将调用TensorRT库来对其执行。