all_gather¶
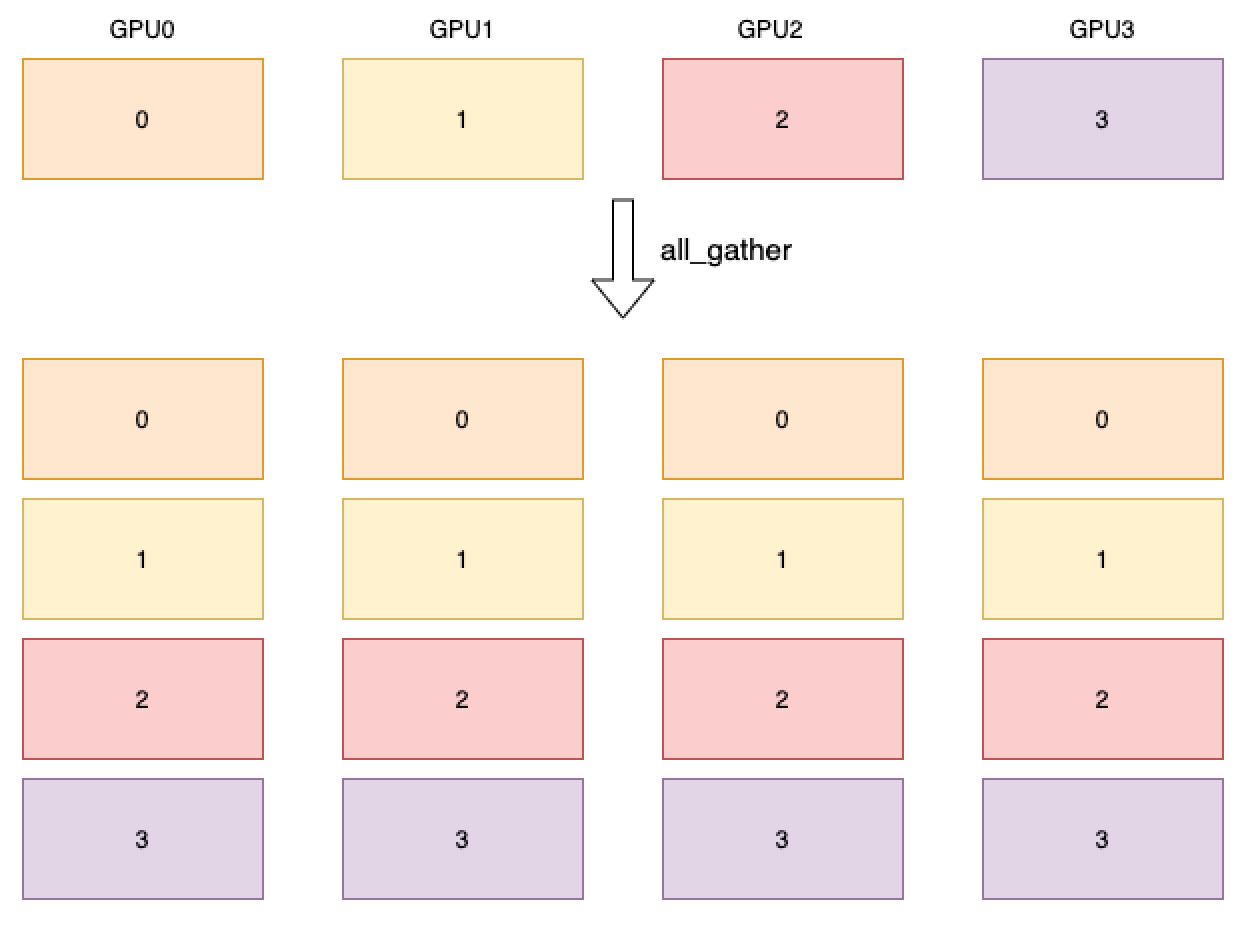
进程组内所有进程的指定 tensor 进行聚合操作,并返回给所有进程聚合的结果。 如下图所示,4 个 GPU 分别开启 4 个进程,每张卡上的数据用卡号代表, 经过 all_gather 算子后,每张卡都会拥有所有卡的数据。
参数¶
tensor_list (list) - 操作的输出 Tensor 列表。列表中的每个元素均为 Tensor,每个 Tensor 的数据类型为:float16、float32、float64、int32、int64、int8、uint8、bool、complex64、complex128。
tensor (Tensor) - 操作的输入 Tensor。Tensor 的数据类型为:float16、float32、float64、int32、int64、int8、uint8、bool、complex64、complex128。
group (int,可选) - 工作的进程组编号,默认为 0。
返回¶
无
代码示例¶
# required: distributed
import paddle
import paddle.distributed as dist
dist.init_parallel_env()
tensor_list = []
if dist.get_rank() == 0:
data = paddle.to_tensor([[4, 5, 6], [4, 5, 6]])
else:
data = paddle.to_tensor([[1, 2, 3], [1, 2, 3]])
dist.all_gather(tensor_list, data)
print(tensor_list)
# [[[4, 5, 6], [4, 5, 6]], [[1, 2, 3], [1, 2, 3]]] (2 GPUs)