飞桨模型量化¶
深度学习技术飞速发展,在很多任务和领域都超越传统方法。但是,深度学习模型通常需要较大的存储空间和计算量,给部署应用带来了不小挑战。
模型量化作为一种常见的模型压缩方法,使用整数替代浮点数进行存储和计算,可以减少模型存储空间、加快推理速度、降低计算内存,助力深度学习应用的落地。
飞桨提供了模型量化全流程解决方案,首先使用PaddleSlim产出量化模型,然后使用Paddle Inference和Paddle Lite部署量化模型。

产出量化模型¶
飞桨模型量化全流程解决方案中,PaddleSlim负责产出量化模型。
PaddleSlim支持三种模型量化方法:动态离线量化方法、静态离线量化方法和量化训练方法。这三种量化方法的特点如下图。
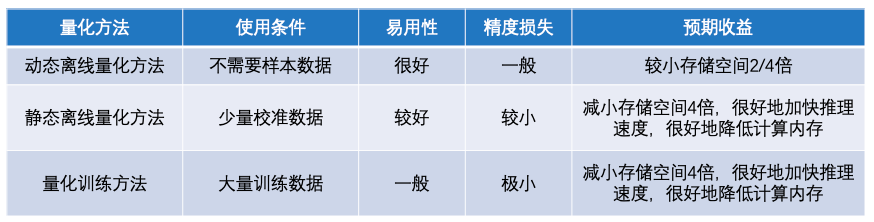
动态离线量化方法不需要使用样本数据,也不会对模型进行训练。在模型产出阶段,动态离线量化方法将模型权重从浮点数量化成整数。在模型部署阶段,将权重从整数反量化成浮点数,使用浮点数运算进行预测推理。这种方式主要减少模型存储空间,对权重读取费时的模型有一定加速作用,对模型精度影响较小。
静态离线量化方法要求有少量无标签样本数据,需要执行模型的前向计算,不会对模型进行训练。在模型产出阶段,静态离线量化方法使用样本数据执行模型的前向计算,同时对量化OP的输入输出进行采样,然后计算量化信息。在模型部署阶段,使用计算好的量化信息对输入进行量化,基于整数运算进行预测推理。静态离线量化方法可以减少模型存储空间、加快模型推理速度、降低计算内存,同时量化模型只存在较小的精度损失。
量化训练方法要求有大量有标签样本数据,需要对模型进行较长时间的训练。在模型产出阶段,量化训练方法使用模拟量化的思想,在模型训练过程中会更新权重,实现拟合、减少量化误差的目的。在模型部署阶段,量化训练方法和静态离线量化方法一致,采用相同的预测推理方式,在存储空间、推理速度、计算内存三方面实现相同的收益。更重要的是,量化训练方法对模型精度只有极小的影响。
根据使用条件和压缩目的,大家可以参考下图选用不同的模型量化方法产出量化模型。
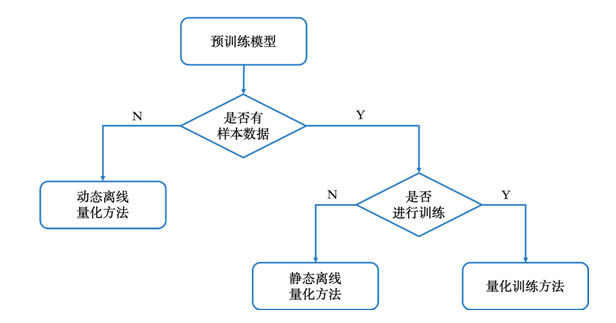
产出量化模型的使用方法、Demo和API,请参考PaddleSlim文档。
部署量化模型¶
飞桨模型量化全流程解决方案中,Paddle Inference负责在服务器端(X86 CPU和Nvidia GPU)部署量化模型,Paddle Lite负责在移动端(ARM CPU)上部署量化模型。
X86 CPU和Nvidia GPU上支持部署PaddleSlim静态离线量化方法和量化训练方法产出的量化模型。 ARM CPU上支持部署PaddleSlim动态离线量化方法、静态离线量化方法和量化训练方法产出的量化模型。
因为动态离线量化方法产出的量化模型主要是为了压缩模型体积,主要应用于移动端部署,所以在X86 CPU和Nvidia GPU上暂不支持这类量化模型。
NV GPU上部署量化模型¶
使用PaddleSlim静态离线量化方法和量化训练方法产出量化模型后,可以使用Paddle Inference在Nvidia GPU上部署该量化模型。
Nvidia GPU上部署常规模型的流程是:准备TensorRT环境、配置Config、创建Predictor、执行。Nvidia GPU上部署量化模型和常规模型大体相似,需要改动的是:指定TensorRT配置时将precision_mode设置为paddle_infer.PrecisionType.Int8,将use_calib_mode设为False。
config.enable_tensorrt_engine(
workspace_size=1<<30,
max_batch_size=1,
min_subgraph_size=5,
precision_mode=paddle_infer.PrecisionType.Int8,
use_static=False,
use_calib_mode=False)
Paddle Inference的详细说明,请参考文档。
Nvidia GPU上部署量化模型的详细说明,请参考文档。
X86 CPU上部署量化模型¶
使用PaddleSlim静态离线量化方法和量化训练方法产出量化模型后,可以使用Paddle Inference在X86 CPU上部署该量化模型。
X86 CPU上部署量化模型,首先检查X86 CPU支持指令集,然后转换量化模型,最后在X86 CPU上执行预测。
Paddle Inference的详细说明,请参考文档。
X86 CPU上部署量化模型的详细说明,请参考文档。
1)检查X86 CPU支持指令集
大家可以在命令行中输入lscpu查看本机支持指令。
在支持avx512、不支持avx512_vnni的X86 CPU上(如:SkyLake, Model name:Intel(R) Xeon(R) Gold X1XX),量化模型性能为原始模型性能的1.5倍左右。
在支持avx512和avx512_vnni的X86 CPU上(如:Casecade Lake, Model name: Intel(R) Xeon(R) Gold X2XX),量化模型的精度和性能最高,量化模型性能为原始模型性能的3~3.7倍。
2)转换量化模型
下载转换脚本到本地.
wget https://github.com/PaddlePaddle/Paddle/blob/develop/python/paddle/fluid/contrib/slim/tests/save_quant_model.py
使用脚本转换量化模型,比如:
python save_quant_model.py \
--quant_model_path=/PATH/TO/PADDLESLIM/GENERATE/MODEL \
--int8_model_save_path=/PATH/TO/SAVE/CONVERTED/MODEL
3)执行预测
准备预测库,加载转换后的量化模型,创建Predictor,进行预测。
注意,在X86 CPU预测端部署量化模型,必须开启MKLDNN,不要开启IrOptim(模型已经转换好)。
4)数据展示
图像分类INT8模型在 Intel(R) Xeon(R) Gold 6271 上精度
| Model | FP32 Top1 Accuracy | INT8 Top1 Accuracy | Top1 Diff | FP32 Top5 Accuracy | INT8 Top5 Accuracy | Top5 Diff |
|---|---|---|---|---|---|---|
| MobileNet-V1 | 70.78% | 70.74% | -0.04% | 89.69% | 89.43% | -0.26% |
| MobileNet-V2 | 71.90% | 72.21% | 0.31% | 90.56% | 90.62% | 0.06% |
| ResNet101 | 77.50% | 77.60% | 0.10% | 93.58% | 93.55% | -0.03% |
| ResNet50 | 76.63% | 76.50% | -0.13% | 93.10% | 92.98% | -0.12% |
| VGG16 | 72.08% | 71.74% | -0.34% | 90.63% | 89.71% | -0.92% |
| VGG19 | 72.57% | 72.12% | -0.45% | 90.84% | 90.15% | -0.69% |
图像分类INT8模型在 Intel(R) Xeon(R) Gold 6271 单核上性能
| Model | FP32 (images/s) | INT8 (images/s) | Ratio (INT8/FP32) |
|---|---|---|---|
| MobileNet-V1 | 74.05 | 216.36 | 2.92 |
| MobileNet-V2 | 88.60 | 205.84 | 2.32 |
| ResNet101 | 7.20 | 26.48 | 3.68 |
| ResNet50 | 13.23 | 50.02 | 3.78 |
| VGG16 | 3.47 | 10.67 | 3.07 |
| VGG19 | 2.83 | 9.09 | 3.21 |
Ernie INT8 模型在 Intel(R) Xeon(R) Gold 6271 的精度结果
| Model | FP32 Accuracy | INT8 Accuracy | Accuracy Diff |
|---|---|---|---|
| Ernie | 80.20% | 79.44% | -0.76% |
Ernie INT8 模型在 Intel(R) Xeon(R) Gold 6271 上单样本耗时
| Threads | FP32 Latency (ms) | INT8 Latency (ms) | Ratio (FP32/INT8) |
|---|---|---|---|
| 1 thread | 237.21 | 79.26 | 2.99X |
| 20 threads | 22.08 | 12.57 | 1.76X |
ARM CPU上部署量化模型¶
Paddle Lite可以在ARM CPU上部署PaddleSlim动态离线量化方法、静态离线量化方法和量化训练方法产出的量化模型。
Paddle Lite部署量化模型的方法和常规非量化模型完全相同,主要包括使用opt工具进行模型优化、执行预测。
Paddle Lite的详细说明,请参考文档。
Paddle Lite部署动态离线量化方法产出的量化模型,请参考文档。
Paddle Lite部署静态离线量化方法产出的量化模型,请参考文档。
Paddle Lite部署量化训练方法产出的量化模型,请参考文档。
模型量化前后性能对比
| 骁龙855 | armv7(ms) | armv7(ms) | armv7(ms) | armv8(ms) | armv8(ms) | armv8(ms) |
|---|---|---|---|---|---|---|
| threads num | 1 | 2 | 4 | 1 | 2 | 4 |
| mobilenet_v1_fp32 | 32.19 | 18.75 | 11.02 | 29.50 | 17.50 | 9.58 |
| mobilenet_v1_int8 | 19.00 | 10.93 | 5.97 | 13.08 | 7.68 | 3.98 |
| mobilenet_v2_fp32 | 23.77 | 14.23 | 8.52 | 19.98 | 12.19 | 7.44 |
| mobilenet_v2_int8 | 17.68 | 10.49 | 5.93 | 12.76 | 7.70 | 4.36 |