
Lite 预测流程¶
Lite是一种轻量级、灵活性强、易于扩展的高性能的深度学习预测框架,它可以支持诸如ARM、OpenCL、NPU等等多种终端,同时拥有强大的图优化及预测加速能力。如果您希望将Lite框架集成到自己的项目中,那么只需要如下几步简单操作即可。
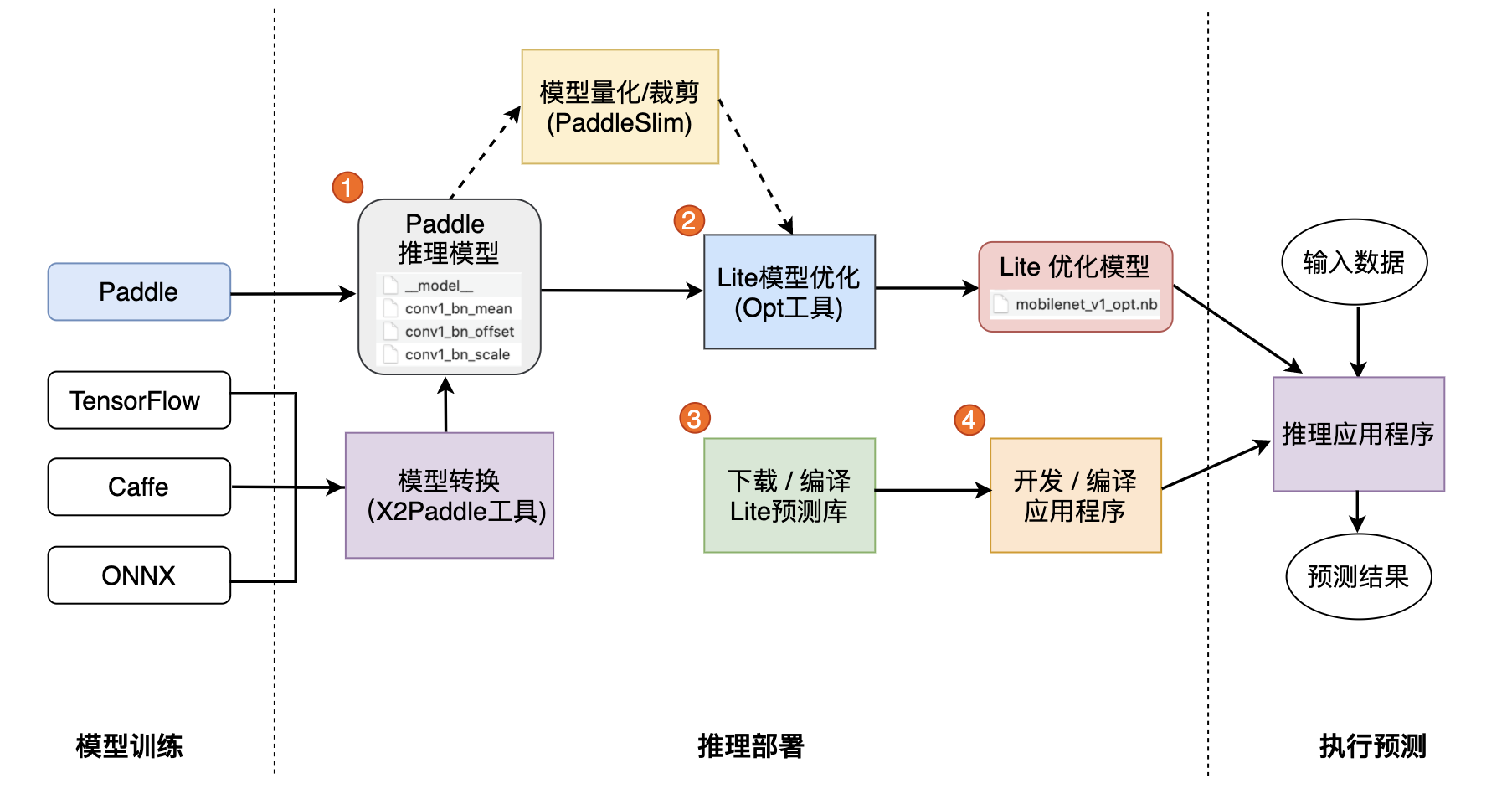
一. 准备模型
Paddle Lite框架直接支持模型结构为PaddlePaddle深度学习框架产出的模型格式。目前PaddlePaddle用于推理的模型是通过save_inference_model这个API保存下来的。 如果您手中的模型是由诸如Caffe、Tensorflow、PyTorch等框架产出的,那么您可以使用 X2Paddle 工具将模型转换为PadddlePaddle格式。
二. 模型优化
Paddle Lite框架拥有优秀的加速、优化策略及实现,包含量化、子图融合、Kernel优选等优化手段。优化后的模型更轻量级,耗费资源更少,并且执行速度也更快。 这些优化通过Paddle Lite提供的opt工具实现。opt工具还可以统计并打印出模型中的算子信息,并判断不同硬件平台下Paddle Lite的支持情况。您获取PaddlePaddle格式的模型之后,一般需要通该opt工具做模型优化。opt工具的下载和使用,请参考 模型优化方法。
注意: 为了减少第三方库的依赖、提高Lite预测框架的通用性,在移动端使用Lite API您需要准备Naive Buffer存储格式的模型。
三. 下载或编译
Paddle Lite提供了Android/iOS/X86平台的官方Release预测库下载,我们优先推荐您直接下载 Paddle Lite预编译库。
您也可以根据目标平台选择对应的源码编译方法。Paddle Lite 提供了源码编译脚本,位于 lite/tools/文件夹下,只需要 准备环境 和 调用编译脚本 两个步骤即可一键编译得到目标平台的Paddle Lite预测库。
四. 开发应用程序
Paddle Lite提供了C++、Java、Python三种API,只需简单五步即可完成预测(以C++ API为例):
声明
MobileConfig,设置第二步优化后的模型文件路径,或选择从内存中加载模型创建
Predictor,调用CreatePaddlePredictor接口,一行代码即可完成引擎初始化准备输入,通过
predictor->GetInput(i)获取输入变量,并为其指定输入大小和输入值执行预测,只需要运行
predictor->Run()一行代码,即可使用Lite框架完成预测执行获得输出,使用
predictor->GetOutput(i)获取输出变量,并通过data<T>取得输出值
Paddle Lite提供了C++、Java、Python三种API的完整使用示例和开发说明文档,您可以参考示例中的说明快速了解使用方法,并集成到您自己的项目中去。
针对不同的硬件平台,Paddle Lite提供了各个平台的完整示例:
您也可以下载以下基于Paddle-Lite开发的预测APK程序,安装到Andriod平台上,先睹为快: