
NLP - 快速上手¶
本文以经典网络 Bert 为例,结合代码来详细介绍如何从 PyTorch 迁移到飞桨,以便快速掌握迁移的基本思路和解决方法。
一、概述¶
1.1 框架对比¶
在介绍迁移之前,先以一个典型网络为例,对比一下飞桨与 PyTorch 的训练代码。
from functools import partial
import numpy as np
import paddle
from paddlenlp.datasets import load_dataset
from paddlenlp.transformers import BertForSequenceClassification, AutoTokenizer
# 定义数据集
train_ds = load_dataset("chnsenticorp", splits=["train"])
# 定义模型
model = BertForSequenceClassification.from_pretrained("bert-wwm-chinese", num_classes=len(train_ds.label_list))
# 定义 Tokenizer,实现文本到 ID 的转化
tokenizer = AutoTokenizer.from_pretrained("bert-wwm-chinese")
# 数据处理,从文本到处理好的数据,input_ids,token_type_ids
def convert_example(example, tokenizer):
encoded_inputs = tokenizer(text=example["text"], max_seq_len=512, pad_to_max_seq_len=True)
return tuple([np.array(x, dtype="int64") for x in [
encoded_inputs["input_ids"], encoded_inputs["token_type_ids"], [example["label"]]]])
train_ds = train_ds.map(partial(convert_example, tokenizer=tokenizer))
# 定义 BatchSampler,组合 batch,shuffle 数据
batch_sampler = paddle.io.BatchSampler(dataset=train_ds, batch_size=8, shuffle=True)
train_data_loader = paddle.io.DataLoader(dataset=train_ds, batch_sampler=batch_sampler, return_list=True)
# 定义 optimizer 优化器
optimizer = paddle.optimizer.AdamW(learning_rate=0.001, parameters=model.parameters())
# 定义 loss
criterion = paddle.nn.loss.CrossEntropyLoss()
# 训练
for input_ids, token_type_ids, labels in train_data_loader():
logits = model(input_ids, token_type_ids)
loss = criterion(logits, labels)
loss.backward()
optimizer.step()
optimizer.clear_grad()
import numpy as np
import pandas as pd
import torch
from datasets import Dataset
from transformers import BertTokenizer
from transformers import DataCollatorWithPadding
from transformers import BertForSequenceClassification
from torch.optim import AdamW
from datasets import load_dataset
# 定义模型
model = BertForSequenceClassification.from_pretrained(
"hfl/chinese-bert-wwm-ext", num_labels=2)
# 定义 Tokenizer,实现文本到 ID 的转化
tokenizer = BertTokenizer.from_pretrained("hfl/chinese-bert-wwm-ext")
# 数据处理,从文本到处理好的数据,input_ids,token_type_ids
def preprocess_function(examples):
result = tokenizer(
examples["text"],
padding=False,
max_length=128,
truncation=True,
return_token_type_ids=True, )
if "label" in examples:
result["labels"] = [examples["label"]]
return result
# 定义数据集
dataset = load_dataset("seamew/ChnSentiCorp")["train"]
dataset = dataset.map(
preprocess_function,
batched=False,
remove_columns=dataset.column_names,
desc="Running tokenizer on dataset", )
dataset.set_format(
"np", columns=["input_ids", "token_type_ids", "labels"])
# 定义 BatchSampler,组合 batch,shuffle 数据
sampler = torch.utils.data.SequentialSampler(dataset)
collate_fn = DataCollatorWithPadding(tokenizer)
data_loader = torch.utils.data.DataLoader(
dataset,
batch_size=4,
sampler=sampler,
num_workers=0,
collate_fn=collate_fn, )
# 定义 loss
criterion = torch.nn.CrossEntropyLoss()
# 定义 optimizer 优化器
optimizer = AdamW(params=model.parameters(), lr=3e-5)
# 训练
for batch in data_loader:
output = model(**batch).logits
loss = criterion(output, batch['labels'].reshape(-1))
loss.backward()
print(loss)
optimizer.step()
optimizer.zero_grad()
通过上面的代码对比可以看到:
使用飞桨搭训练神经网络流程与 PyTorch 类似,主要包括:构建数据集对象、定义正向网络结构、定义 Loss、定义优化器、迭代数据集对象、执行正向传播、输出 Loss、执行反向传播计算梯度、优化器更新参数。
飞桨支持的算子在命名或者功能上与 PyTorch 存在一定差异。
1.2 迁移任务简介¶
Bert 是 NLP 中经典的深度神经网络,有较多开发者关注和复现,因此,本任务以 Bert 为例 。任务目标是参考 Bert 的论文,将 PyTorch 实现的模型迁移为飞桨模型,在 GPU 单卡下通过模型训练、评估和预测,并在相同条件下迁移后的模型训练精度达到预期效果。
需要注意的是对于部分网络,使用相同的硬件环境和脚本代码,由于数据增广、模型初始化的随机性,最终达到的收敛精度和性能也可能与原项目的结果有细微差别,这属于正常的波动范围。
论文:https://arxiv.org/abs/1810.04805
PyTorch 源代码:https://github.com/huggingface/transformers/blob/main/src/transformers/models/bert/modeling_bert.py
说明:
Hugging Face 开发的基于 PyTorch 的 Transformers 项目,是目前 NLP 领域比较好用和便捷的开源库,因此本次迁移使用的是 Hugging Face 中 Transformers 代码。
【迁移任务解析】
根据模型训练的常规流程,可将整个迁移任务划分为:模型前向对齐、数据读取对齐、评估指标对齐、损失函数对齐、反向梯度对齐、训练精度对齐。
模型组网对齐:PyTorch 的大部分 API 在飞桨中可找到对应 API,可以参考 PyTorch-PaddlePaddle API 映射表,模型组网部分代码直接进行手动转换即可;为了判断转换后的 飞桨模型组网能获得和 PyTorch 参考实现同样的输出,可将两个模型参数固定,并输入相同伪数据,观察两者的产出差异是否在阈值内。
数据读取对齐:相同的神经网络使用不同的数据训练和测试得到的结果往往会存在较大差异。为了能完全复现原始的模型,需要保证使用的数据完全相同,包括数据集的版本、使用的数据增强方式。
模型训练对齐:为了验证迁移后的模型能达到相同的精度,需要确保迁移模型使用的评价指标、损失函数与原模型相同,以便原模型与迁移后的模型对比。
评估指标对齐:飞桨提供了一系列 Metric 计算类,而 PyTorch 中目前可以通过组合的方式实现。应确保使用的指标与原代码含义一致,以便对照精度。
损失函数对齐:训练迁移后的模型时,需要使用与原代码相同的损失函数。飞桨与 PyTorch 均提供了常用的损失函数,二者的 API 对应关系可参考 Loss 类 API 映射列表。
超参对齐:训练过程中需要保证学习率、优化器、正则化系统等超参对齐。飞桨中的 optimizer 有
paddle.optimizer等一系列实现,PyTorch 中则有torch.optim等一系列实现。对照PaddlePaddle 正则化 API 文档与参考代码的优化器实现进行对齐,用之后的反向梯度对齐统一验证该模块的正确性。反向梯度对齐:前向对齐完成后,还需进行反向对齐,即确保迁移后的模型反向传播、权重更新与原模型一致。可以通过两轮训练进行检查,若迁移前后的模型第二轮训练的 loss 一致,则可以认为二者反向已对齐。
训练精度对齐:对比迁移前后模型的训练精度,若二者的差值在可以接受的误差范围内,则精度对齐完成。
训练性能对齐:在相同的硬件条件下,迁移前后的模型训练速度应接近。若二者差异非常大,则需要排查原因。
为了更方便地对齐验证,飞桨提供了 reprod_log 差异核验工具辅助查看飞桨 和 PyTorch 模型在同样输入下的输出是否相同,这样的查看方式具有标准统一、比较过程方便等优势。
【迁移任务结果】
迁移后的飞桨实现:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/examples/torch_migration
二、迁移准备工作¶
模型迁移前,需要准备运行环境,并准备好参考代码以及模型对齐所需的数据集。
2.1 准备环境¶
准备环境包括安装飞桨、安装 PyTorch 和安装差异核验工具 reprod_log。
1.安装飞桨
# 安装 GPU 版本的 PaddlePaddle,使用下面的命令
# pip install paddlepaddle-gpu==2.2.0.post112 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html
运行 python,输入下面的命令。
import paddle
paddle.utils.run_check()
print(paddle.__version__)
如果输出下面的内容,则说明 PaddlePaddle 安装成功。
PaddlePaddle is installed successfully! Let's start deep learning with PaddlePaddle now.2.2.0
2.安装 PyTorch
对于 PyTorch 的安装,请参阅 PyTorch 官网,选择操作系统和 CUDA 版本,使用相应的命令安装。
运行 Python,输入下面的命令,如果可以正常输出,则说明 PyTorch 安装成功。
import torch
print(torch.__version__)
# 如果安装的是 gpu 版本,可以按照下面的命令确认 torch 是否安装成功
# 期望输出为 tensor([1.], device='cuda:0')
print(torch.Tensor([1.0]).cuda())
3.安装差异核验工具 reprod_log
在对齐验证的流程中,依靠 差异核验工具 reprod_log 查看飞桨和 PyTorch 同样输入下的输出是否相同,这样的查看方式具有标准统一,比较过程方便等优势。
reprod_log 是一个用于 numpy 数据记录和对比工具,通过传入需要对比的两个 numpy 数组就可以在指定的规则下得到数据之差是否满足期望的结论。其主要接口的说明可以查看其 GitHub 主页。
安装 reprod_log 的命令如下。
pip3 install reprod_log --force-reinstall
2.2 准备数据¶
了解该模型输入输出格式:Bert 句子分类任务为例,模型输入为句子组,也就是维度为
[batch_size, sequence_length]的 tensor,而其中具体的值单词需要通过 tokenizer 转换为数字 id, 类型为 int64,label 为[batch_size, ]的 label,类型为int64。准备伪输入数据(fake input data)以及伪标签(fake label):通过运行生成伪数据的参考代码:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/examples/torch_migration/pipeline/fake_data/gen_fake_data.py ,生成和模型输入 shape、type 等保持一致的伪数据,并保存在本地,用于后续模型前反向对齐时同时作为两个模型的输入。这样的方式能够使保证模型对齐不会受到输入数据的影响,有助于将模型结构对齐和数据对齐解耦,更为方便地排查问题。伪数据可以通过如下代码生成。
def gen_fake_data():
fake_data = np.random.randint(1, 30522, size=(4, 64)).astype(np.int64)
fake_label = np.array([0, 1, 1, 0]).astype(np.int64)
np.save("fake_data.npy", fake_data)
np.save("fake_label.npy", fake_label)
2.3 分析并运行参考代码¶
需在特定设备(CPU/GPU)上,利用少量伪数据,跑通参考代码的预测过程(前向)以及至少 2 轮(iteration)迭代过程,用于生成和迁移代码进行对比的结果。
PyTorch 的实现:bert_torch
项目的目录结构如下:
bert_torch
|-accuracy.py # 评价指标
|-train.py # 模型训练代码
|-utils.py # 工具类及函数
|-log.log #日志记录
|-glue.py #数据生成代码
|-train.sh #启动训练的 bash 脚本
完成以上迁移准备之后,通过下面对应训练流程的拆解步骤进行迁移对齐。
三、 模型前向对齐¶
模型前向对齐,是指给定相同的输入数据和权重,迁移后的模型与原模型前向传播的输出结果一致。前向对齐一般分为 3 个主要步骤:
网络结构代码转换
权重转换
模型组网正确性验证
下面详细介绍这 3 个部分。
3.1 网络结构代码转换¶
由于以 Bert 为基础的深度模型网络结构较为复杂,参数众多。为了方便用户使用和模型可扩展性的建设,PyTorch 和飞桨都采用套件的形式来构建模型,两者的主要结构基本相同。为方便用户转换,这里提供了简化版本的实现,方便用户对照修改。
PyTorch 模块通常继承torch.nn.Module,飞桨模块通常继承paddle.nn.Layer;二者对模块的定义方法是类似的,即在 __init__中定义模块中用到的子模块,然后 forward函数中定义前向传播的方式。因此,网络结构代码转换,主要工作是 API 的转换,即将调用的 PyTorch API 替换成对应的飞桨 API 即可。PyTorch 的 API 和飞桨的 API 非常相似,可以参考PyTorch-飞桨 API 映射表,直接对组网部分代码进行手动转换。
【转换前】
本教程提供了简化版的代码,BERT 网络结构的 PyTorch 实现: torch_bert。
原始代码参考自:huggingface modeling_bert.py
【转换后】
对应转换后的 PaddlePaddle 实现: paddle_bert。
飞桨 PaddleNLP 官方实现的代码请参考:paddlenlp bert/modeling.py
【源码分析】
分析 Bert 网络代码,主要分为以下几个模块:
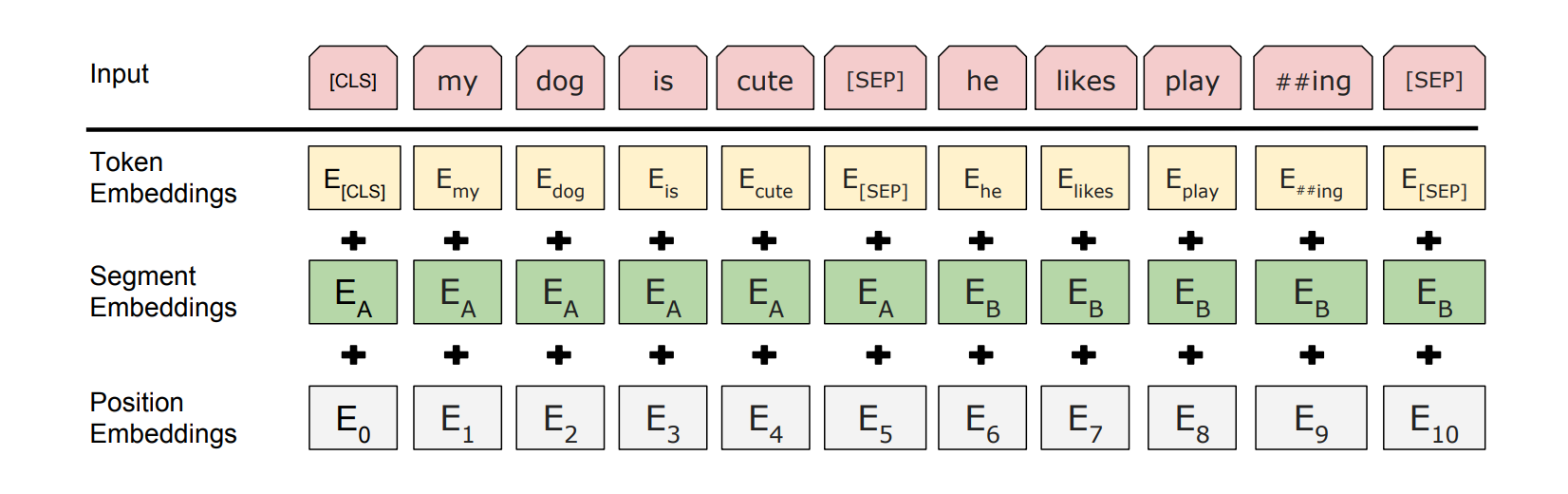
BertEmbedding:定义了 BERT 输入的分布式表示。输入嵌入是 Token 嵌入、Segment 嵌入和 Position 嵌入的总和。
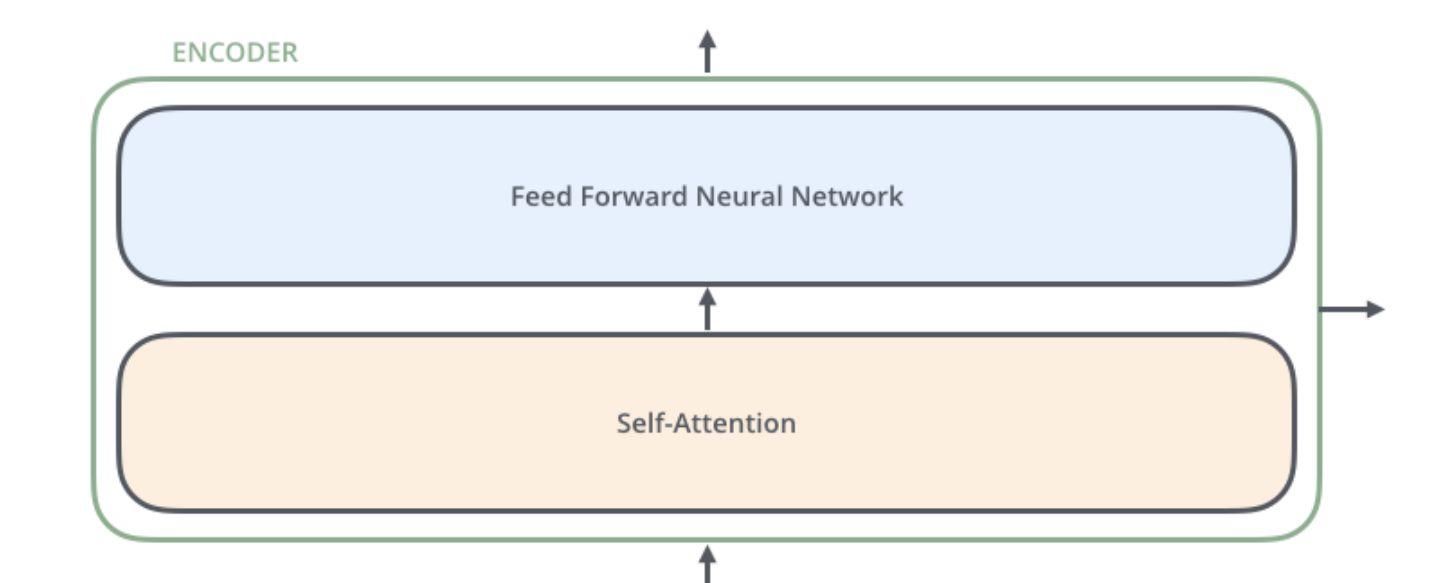
EncoderLayer:继承自
torch.nn.Layer,是 Bert 网络中基本模块,由 MultiHeadAttention、FeedForward 组成。后者由 LayerNorm,Dropout,Linear 层和激活函数构成。
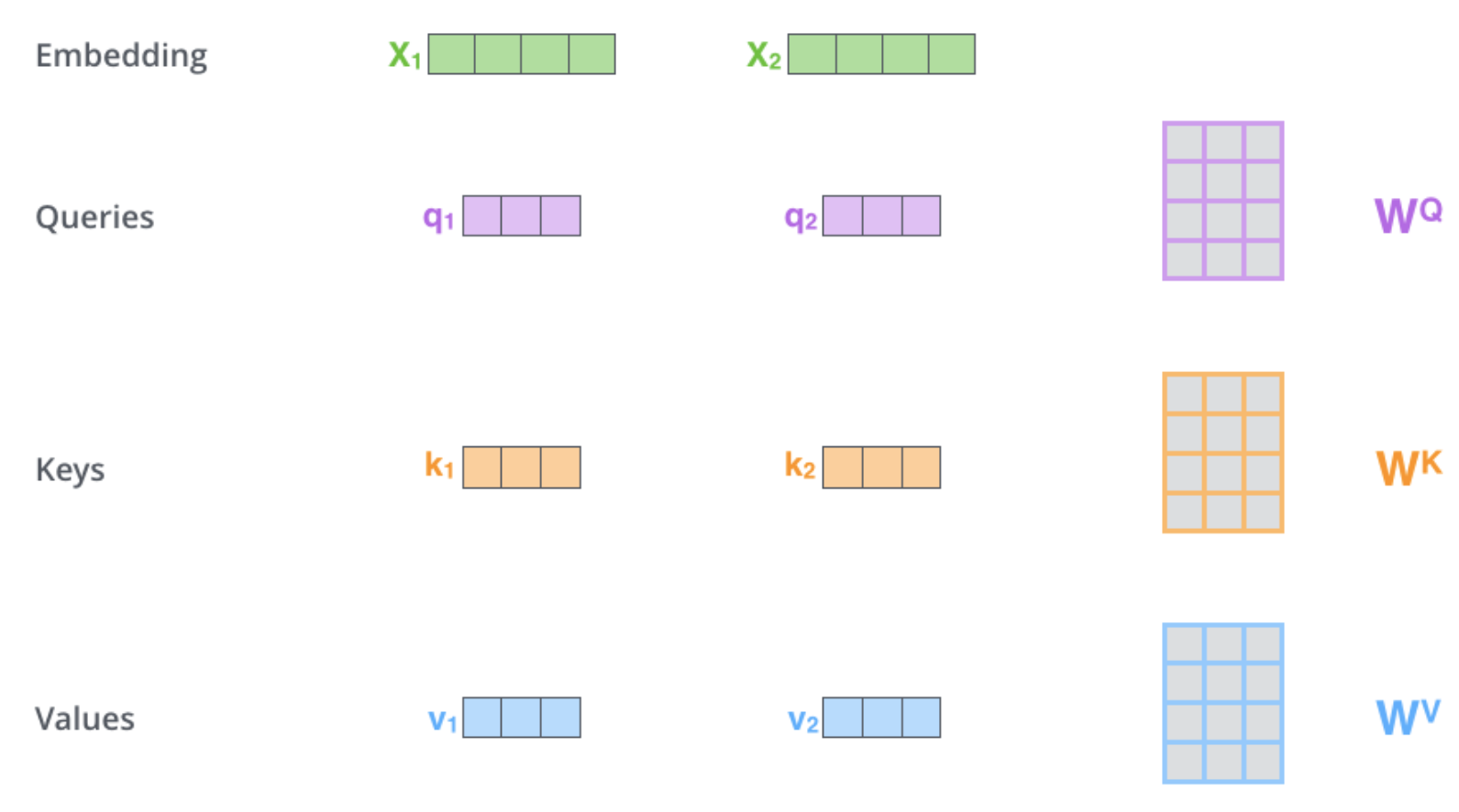
SelfAttention 层的 K,Q,V 矩阵用于计算单词之间的相关性分数,他们由 Linear 层组成。
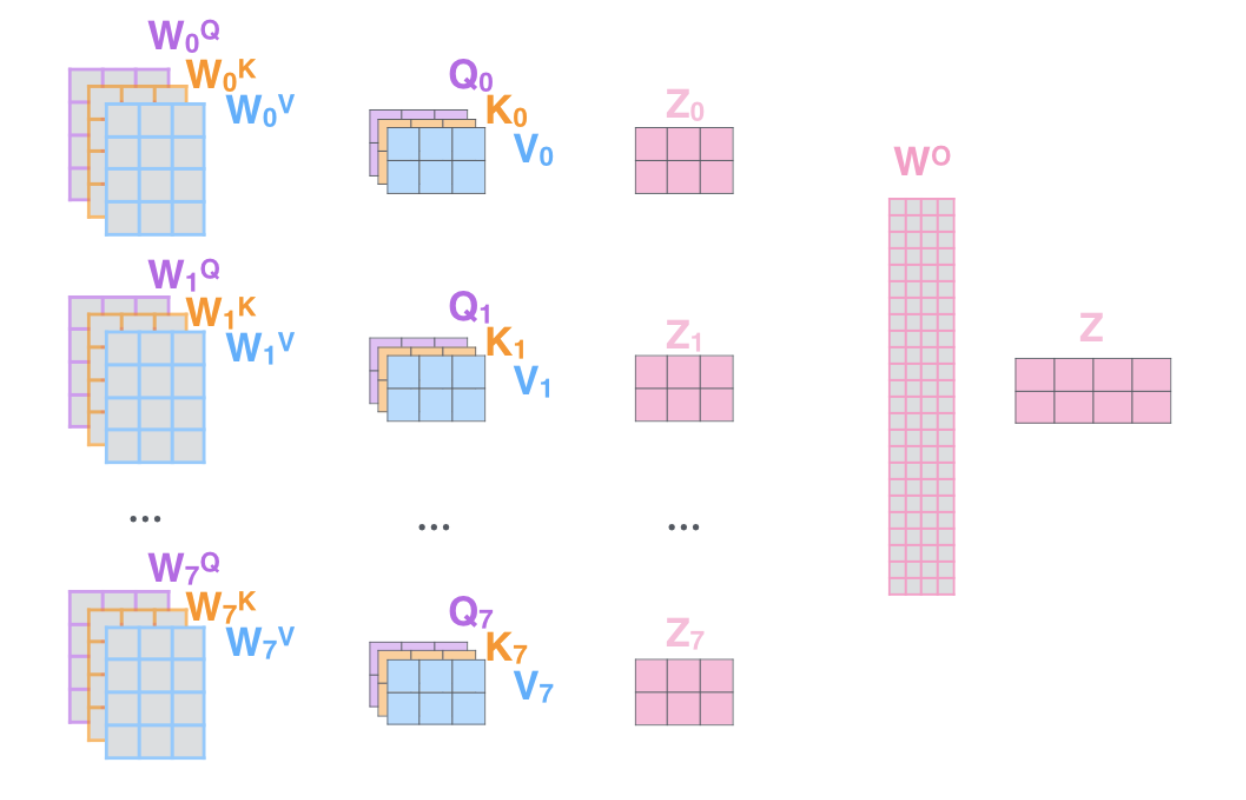
MultiHeadAttention:由 SelfAttention 层和 Softmax 函数构成。
Pooler模块:pooler 模块在最后一层 encoder 之后,是对最后一层 encoder 输出的池化操作。
Linear模块:将从 encoder 模块得到的单词表示用于最后一步的分类 classify。
BertForSequenceClassification:定义了整体网络架构。封装了BertEmbedding,EncoderLayer模块以及 Pooler,Linear模块。
【转换步骤】
基于以上子网划分,参考 PyTorch 与飞桨 API 映射表,完成上述模块的转换:
对于 BertEmbedding 模块,需要将继承的基类由
torch.nn.Module改成paddle.nn.Layer,并且 PyTorch 模型参数形式是由 config 字典传入参数,而 Paddle 需要传入该模块对应参数即可对于 MultiHeadAttention模块,需要将继承的基类由
torch.nn.Module改成paddle.nn.Layer,并且 PyTorch 模型参数形式是由 config 字典传入参数,而 Paddle 需要传入该模块对应参数即可对于 Linear模块,需要注意 Paddle
bias默认为 True对于LayerNorm)模块,要注意 Paddle 和 PyTorch 对于参数 epsilon 默认值不同
对于BertForSequenceClassification,需要将继承的基类由
torch.nn.Module改成paddle.nn.Layer,由于飞桨的nn.Hardswish和nn.Dropout不提供inplace参数,因此需要将 PyTorch 代码中的inplace=True参数删去。权重初始化
飞桨的权重初始化定义方式与 PyTorch 存在区别
PyTorch 初始化包含一些其他配置
def _init_weights(self, module):
"""初始化权重"""
#分情况讨论模型具体层
if isinstance(module, nn.Linear):
# cf https://github.com/pytorch/pytorch/pull/5617
module.weight.data.normal_(mean=0.0,
std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0,
std=self.config.initializer_range)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
飞桨在定义模块时加载模型初始化
def _init_weights(self, module):
"""初始化权重"""
normal_init = nn.initializer.Normal(mean=0.0,
std=self.config.initializer_range)
zero_init = nn.initializer.Constant(0.)
one_init = nn.initializer.Constant(1.)
#分情况讨论模型具体层
if isinstance(module, nn.Linear):
normal_init(module.weight)
if module.bias is not None:
zero_init(module.bias)
elif isinstance(module, nn.Embedding):
normal_init(module.weight)
if module._padding_idx is not None:
with paddle.no_grad():
module.weight[module._padding_idx] = 0
elif isinstance(module, nn.LayerNorm):
zero_init(module.bias)
one_init(module.weight)
【API 对比】
部分 PyTorch 与飞桨 API 对比如下表所示:
| PyTorch 组网 API | 飞桨组网 API | 主要差异说明 |
|---|---|---|
| torch.nn.Softmax | paddle.nn.Softmax | 功能一致,参数名不一致。 |
| torch.nn.Dropout | paddle.nn.Dropout | PyTorch 有 inplace 参数,表示在不更改变量的内存地址的情况下,直接修改变量的值,飞桨无此参数。 |
| torch.nn.Linear | paddle.nn.Linear | PyTorch bias默认为 True,表示使用可更新的偏置参数。飞桨 weight_attr/bias_attr默认使用默认的权重/偏置参数属性,否则为指定的权重/偏置参数属性,具体用法参见ParamAttr;当bias_attr设置为 bool 类型与 PyTorch 的作用一致。 |
| torch.nn.LayerNorm | paddle.nn.LayerNorm | 注意参数 epsilon 不同模型参数值,可能不同,对模型精度影响大。 |
| torch.nn.Embedding | paddle.nn.Embedding | PyTorch:当 max_norm 不为None时,如果 Embeddding 向量的范数(范数的计算方式由 norm_type 决定)超过了 max_norm 这个界限,就要再进行归一化。PaddlePaddle:PaddlePaddle 无此要求,因此不需要归一化。PyTorch:若 scale_grad_by_freq 设置为True,会根据单词在 mini-batch 中出现的频率,对梯度进行放缩。 PaddlePaddle:PaddlePaddle 无此功能。 |
3.2 权重转换¶
【转换前】
PyTorch 和 Paddle 都是用套件的形式来进行 Bert 模型组装,在 3.1 通过替换模型组件就可以完成模型网络迁移,而相应的模型权重只需要通过转换脚本就能得到,需要首先下载 Huggingface 的 BERT 预训练模型到该目录下,下载地址为:https://huggingface.co/bert-base-uncased/blob/main/pytorch_model.bin
【转换后】
转换后的飞桨模型权重保存为:model_state.pdparams
【转换流程】
将 PyTorch 格式的 Bert 模型参数 torch_weight.bin 保存在本地,代码可以参考torch_bert_weight.py,执行后即可得到 Bert 模型参数 torch_weight.bin。
from transformers import BertModel
import torch
hf_model = BertModel.from_pretrained("bert-base-uncased")
hf_model.eval()
PATH = './torch_weight.bin'
torch.save(hf_model.state_dict(), PATH)
执行 torch2paddle.py进行权重转换。
运行完成之后,会在当前目录生成model_state.pdparams文件,即为转换后的 PaddlePaddle 预训练模型。
代码实现如下:本代码首先下载好待转换的 PyTorch 模型,并加载模型得到torch_state_dict;paddle_state_dict 和
paddle_model_path 则定义了转换后的 state dict 和模型文件路径;代码中 keys_dict 定义了两者 keys 的映射关系(可以通过上面的表格对比得到)。
下一步就是最关键的 paddle_state_dict 的构建,我们对 torch_state_dict 里的每一个 key 都进行映射,得到对应的 paddle_state_dict 的 key。获取 paddle_state_dict 的 key 之后我们需要对 torch_state_dict 的 value 进行转换,如果 key 对应的结构是 nn.Linear 模块的话,我们还需要进行 value 的 transpose 操作。
最后我们保存得到的 paddle_state_dict 就能得到对应的 Paddle 模型。至此我们已经完成了模型的转换工作,得到了 Paddle 框架下的模型"model_state.pdparams" 。
def convert_pytorch_checkpoint_to_paddle(
pytorch_checkpoint_path="pytorch_model.bin",
paddle_dump_path="model_state.pdparams",
version="old",
):
do_not_transpose = []
if version == "old":
hf_to_paddle.update({
"predictions.bias": "predictions.decoder_bias",
".gamma": ".weight",
".beta": ".bias",
})
do_not_transpose = do_not_transpose + ["predictions.decoder.weight"]
pytorch_state_dict = torch.load(pytorch_checkpoint_path, map_location="cpu")
paddle_state_dict = OrderedDict()
for k, v in pytorch_state_dict.items():
is_transpose = False
if k[-7:] == ".weight":
# embeddings.weight and LayerNorm.weight do not transpose
if all(d not in k for d in do_not_transpose):
if ".embeddings." not in k and ".LayerNorm." not in k:
if v.ndim == 2:
if 'embeddings' not in k:
v = v.transpose(0, 1)
is_transpose = True
is_transpose = False
oldk = k
print(f"Converting: {oldk} => {k} | is_transpose {is_transpose}")
paddle_state_dict[k] = v.data.numpy()
paddle.save(paddle_state_dict, paddle_dump_path)
3.3 模型组网正确性验证¶
为了判断模型组网部分能获得和原论文同样的输出,将两个模型参数固定,并输入相同伪数据,观察飞桨模型产出的 logit 是否和 PyTorch 模型一致。该步骤可使用 reprod_log 工具验证。
【验证步骤】
使用脚本:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/examples/torch_migration/pipeline/Step1
运行如下命令,验证 BERT 模型前向对齐效果。
# 进入文件夹并生成 torch 的 bert 模型权重
cd pipeline/weights/ && python torch_bert_weights.py
# 进入文件夹并将 torch 的 bert 模型权重转换为 paddle
cd pipeline/weights/ && python torch2paddle.py
# 进入文件夹并生成 classifier 权重
cd pipeline/classifier_weights/ && python generate_classifier_weights.py
# 进入 Step1 文件夹
cd pipeline/Step1/
# 生成 paddle 的前向数据
python pd_forward_bert.py
# 生成 torch 的前向数据
python pt_forward_bert.py
# 对比生成 log
python check_step1.py
验证结果存放的日志文件:forward_diff.log
具体操作步骤如下:
准备输入:fake data
使用参考代码的 dataloader,生成一个 batch 的数据,保存下来,在前向对齐时,直接从文件中读入。
固定随机数种子,生成 numpy 随机矩阵,转化 tensor
可以参考 2.2“准备数据”章节生成的伪数据 (fake_data.npy 和 fake_label.npy)
def gen_fake_data():
fake_data = np.random.randint(1, 30522, size=(4, 64)).astype(np.int64)
fake_label = np.array([0, 1, 1, 0]).astype(np.int64)
np.save("fake_data.npy", fake_data)
np.save("fake_label.npy", fake_label)
保存输出:
PaddlePaddle/PyTorch:dict,key 为 tensor 的 name(自定义),value 为 tensor 的值。最后将 dict 保存到文件中。将准备好的数据送入 PyTorch 模型获取输出。
import sys
import os
import numpy as np
from reprod_log import ReprodLogger
import torch
CURRENT_DIR = os.path.split(os.path.abspath(__file__))[0] # 当前目录
CONFIG_PATH = CURRENT_DIR.rsplit('/', 1)[0]
sys.path.append(CONFIG_PATH)
from models.pt_bert import BertConfig, BertForSequenceClassification
if __name__ == "__main__":
# def logger
reprod_logger = ReprodLogger()
pytorch_dump_path = '../weights/torch_weight.bin'
config = BertConfig()
model = BertForSequenceClassification(config)
checkpoint = torch.load(pytorch_dump_path)
model.bert.load_state_dict(checkpoint)
classifier_weights = torch.load(
"../classifier_weights/torch_classifier_weights.bin")
model.load_state_dict(classifier_weights, strict=False)
model.eval()
# read or gen fake data
fake_data = np.load("../fake_data/fake_data.npy")
fake_data = torch.from_numpy(fake_data)
# forward
out = model(fake_data)[0]
reprod_logger.add("logits", out.cpu().detach().numpy())
reprod_logger.save("forward_torch.npy")
将准备好的数据送入 Paddle 模型获取输出。
import sys
import os
import numpy as np
import paddle
from reprod_log import ReprodLogger
CURRENT_DIR = os.path.split(os.path.abspath(__file__))[0] # 当前目录
CONFIG_PATH = CURRENT_DIR.rsplit('/', 1)[0]
sys.path.append(CONFIG_PATH)
from models.pd_bert import BertConfig, BertForSequenceClassification
if __name__ == "__main__":
paddle.set_device("cpu")
# def logger
reprod_logger = ReprodLogger()
paddle_dump_path = '../weights/paddle_weight.pdparams'
config = BertConfig()
model = BertForSequenceClassification(config)
checkpoint = paddle.load(paddle_dump_path)
model.bert.load_dict(checkpoint)
classifier_weights = paddle.load(
"../classifier_weights/paddle_classifier_weights.bin")
model.load_dict(classifier_weights)
model.eval()
# read or gen fake data
fake_data = np.load("../fake_data/fake_data.npy")
fake_data = paddle.to_tensor(fake_data)
# forward
out = model(fake_data)[0]
reprod_logger.add("logits", out.cpu().detach().numpy())
reprod_logger.save("forward_paddle.npy")
使用 reprod_log 加载 2 个文件,使用 report 功能,记录结果到日志文件中,观察 diff,二者 diff 小于特定的阈值即可。
# https://github.com/littletomatodonkey/AlexNet-Prod/blob/master/pipeline/Step1/check_step1.py
# 使用 reprod_log 排查 difffromreprod_logimportReprodDiffHelperif__name__=="__main__":
diff_helper=ReprodDiffHelper()
torch_info=diff_helper.load_info("./forward_torch.npy")
paddle_info=diff_helper.load_info("./forward_paddle.npy")
diff_helper.compare_info(torch_info, paddle_info)
diff_helper.report(path="forward_diff.log")
查看日志文件
Step1/forward_diff.log。
[2022/10/20 15:58:01] root INFO: logits:
[2022/10/20 15:58:01] root INFO: mean diff: check passed: True, value: 5.476176738739014e-07
[2022/10/20 15:58:01] root INFO: diff check passed
通过以上结果,可以判断网络已前向对齐。
四、数据读取对齐¶
BERT 模型复现过程中,数据处理是很重要的部分,对齐数据输入我们才能进一步对齐模型效果。相同的神经网络使用不同的数据训练和测试得到的结果往往会存在较大差异。为了能复现原始模型的结果,需要保证迁移后的数据加载与原始代码一致,包括数据集的版本、使用的数据增强方式、数据的采样方式。
4.1 小数据集准备¶
为快速验证数据读取以及后续的训练/评估/预测,可以准备一个小数据集(对句子二分类,其中包括 32 个句子以及他们对应的标签),数据位于 https://github.com/PaddlePaddle/PaddleNLP/tree/develop/examples/torch_migration/pipeline/Step2/demo_sst2_sentence/demo.tsv
4.2 数据读取代码转换¶
读取相同的输入,比较经过分词,填充或者截断后输出之间的差异,即可验证预处理是否和参考实现保持一致。
【源码分析】
PyTorch 实现的数据加载代码:
def build_torch_data_pipeline():
tokenizer = HFBertTokenizer.from_pretrained("bert-base-uncased")
def preprocess_function(examples):
result = tokenizer(
examples["sentence"],
padding=False,
max_length=128,
truncation=True,
return_token_type_ids=True, )#构建分词器
if "label" in examples:
result["labels"] = [examples["label"]]
return result
# 加载数据
dataset_test = Dataset.from_csv("demo_sst2_sentence/demo.tsv", sep="\t")
dataset_test = dataset_test.map(
preprocess_function,
batched=False,
remove_columns=dataset_test.column_names,
desc="Running tokenizer on dataset", )#构造数据集
dataset_test.set_format(
"np", columns=["input_ids", "token_type_ids", "labels"])
test_sampler = torch.utils.data.SequentialSampler(dataset_test)
collate_fn = DataCollatorWithPadding(tokenizer)
data_loader_test = torch.utils.data.DataLoader(
dataset_test,
batch_size=4,
sampler=test_sampler,
num_workers=0,
collate_fn=collate_fn, )#装载分好 batch 的数据
return dataset_test, data_loader_test
这里采用了 HFBertTokenizer 来生成 tokenizer,DataCollatorWithPadding 对数据进行 Padding,为了保证数据读取对齐,从前面准备好的小数据集文件夹中读取数据构建数据集,并采用 SequentialSampler 顺序采样方式,DataLoader 的 batch_size 设为 4。
【转换步骤】
对于数据处理部分,代码转换前后最主要的区别在于飞桨使用 BatchSampler 来确定 batch 大小,而 PyTorch 在 DataLoader 中确定 batch 大小。
转换后的飞桨实现如下。基本处理逻辑与之前 PyTorch 相同。
def build_paddle_data_pipeline():
from paddlenlp.data import DataCollatorWithPadding
def read(data_path):
df = pd.read_csv(data_path, sep="\t")
for _, row in df.iterrows():
yield {"sentence": row["sentence"], "labels": row["label"]}
def convert_example(example, tokenizer, max_length=128):
labels = [example["labels"]]
#labels = np.array([example["labels"]], dtype="int64")
example = tokenizer(example["sentence"], max_seq_len=max_length)
example["labels"] = labels
return example
# 加载 tokenizer
tokenizer = PPNLPBertTokenizer.from_pretrained("bert-base-uncased")#构建分词器
# 加载 数据集
dataset_test = ppnlp_load_dataset(
read, data_path='demo_sst2_sentence/demo.tsv', lazy=False)#构造数据集
trans_func = partial(convert_example, tokenizer=tokenizer, max_length=128)
# 使用 tokenize 转换数据
dataset_test = dataset_test.map(trans_func, lazy=False)
# 定义 sampler,采样、shuffle 数据
test_sampler = paddle.io.SequenceSampler(dataset_test)
test_batch_sampler = paddle.io.BatchSampler(
sampler=test_sampler, batch_size=4)
# 定义 数据组合成 batch 的函数
data_collator = DataCollatorWithPadding(tokenizer)
# 定义 DataLoader
data_loader_test = paddle.io.DataLoader(
dataset_test,
batch_sampler=test_batch_sampler,
num_workers=0,
collate_fn=data_collator, ) #装载分好 batch 的数据
return dataset_test, data_loader_test
【API 对比】
数据读取 API 比较可以参考以下表格:
| PyTorch 数据读取相关 API | 飞桨数据读取相关 API | 主要差异说明 | 作用 |
|---|---|---|---|
| torch.utils.data.Dataset | paddle.io.Dataset | - | 提供多种已有的数据集用于后续加载,可以理解为官方构建的 Dataset 类 |
| torch.utils.data.DataLoader | paddle.io.DataLoader | 飞桨没有 pin_memory 参数飞桨增加了 use_shared_memory 参数用于选择是否使用共享内存加速数据加载过程 | 进行数据加载,将数据分成批数据,并提供加载过程中的采样方式 |
4.3 数据读取对齐验证¶
读取相同的输入,比较经过分词,填充或者截断后输出之间的差异,即可验证预处理是否和参考实现保持一致
【验证步骤】
执行以下命令运行 Step2/test_data.py ,检查数据读取部分对齐。
python test_data.py
运行脚本后,查看日志文件 result/log/data_diff.log,如果输出以下命令行,说明验证结果满足预期,数据读取部分验证通过。
[2022/10/16 08:16:01] root INFO: length:
[2022/10/16 08:16:01] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/16 08:16:01] root INFO: dataset_0_input_ids:
[2022/10/16 08:16:01] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/16 08:16:01] root INFO: dataset_0_token_type_ids:
[2022/10/16 08:16:01] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/16 08:16:01] root INFO: dataset_0_labels:
[2022/10/16 08:16:01] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/16 08:16:01] root INFO: dataset_1_input_ids:
[2022/10/16 08:16:01] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/16 08:16:01] root INFO: dataset_1_token_type_ids:
[2022/10/16 08:16:01] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/16 08:16:01] root INFO: dataset_1_labels:
[2022/10/16 08:16:01] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/16 08:16:01] root INFO: dataset_2_input_ids:
[2022/10/16 08:16:01] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/16 08:16:01] root INFO: dataset_2_token_type_ids:
[2022/10/16 08:16:01] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/16 08:16:01] root INFO: dataset_2_labels:
[2022/10/16 08:16:01] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/16 08:16:01] root INFO: dataset_3_input_ids:
[2022/10/16 08:16:01] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/16 08:16:01] root INFO: dataset_3_token_type_ids:
[2022/10/16 08:16:01] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/16 08:16:01] root INFO: dataset_3_labels:
[2022/10/16 08:16:01] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/16 08:16:01] root INFO: dataset_4_input_ids:
[2022/10/16 08:16:01] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/16 08:16:01] root INFO: dataset_4_token_type_ids:
[2022/10/16 08:16:01] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/16 08:16:01] root INFO: dataset_4_labels:
[2022/10/16 08:16:01] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/16 08:16:01] root INFO: dataloader_0_input_ids:
[2022/10/16 08:16:01] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/16 08:16:01] root INFO: dataloader_0_token_type_ids:
[2022/10/16 08:16:01] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/16 08:16:01] root INFO: dataloader_0_labels:
[2022/10/16 08:16:01] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/16 08:16:01] root INFO: dataloader_1_input_ids:
[2022/10/16 08:16:01] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/16 08:16:01] root INFO: dataloader_1_token_type_ids:
[2022/10/16 08:16:01] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/16 08:16:01] root INFO: dataloader_1_labels:
[2022/10/16 08:16:01] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/16 08:16:01] root INFO: dataloader_2_input_ids:
[2022/10/16 08:16:01] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/16 08:16:01] root INFO: dataloader_2_token_type_ids:
[2022/10/16 08:16:01] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/16 08:16:01] root INFO: dataloader_2_labels:
[2022/10/16 08:16:01] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/16 08:16:01] root INFO: dataloader_3_input_ids:
[2022/10/16 08:16:01] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/16 08:16:01] root INFO: dataloader_3_token_type_ids:
[2022/10/16 08:16:01] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/16 08:16:01] root INFO: dataloader_3_labels:
[2022/10/16 08:16:01] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/16 08:16:01] root INFO: dataloader_4_input_ids:
[2022/10/16 08:16:01] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/16 08:16:01] root INFO: dataloader_4_token_type_ids:
[2022/10/16 08:16:01] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/16 08:16:01] root INFO: dataloader_4_labels:
[2022/10/16 08:16:01] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/16 08:16:01] root INFO: diff check passed
验证脚本 test_data.py 主要执行以下操作:
分别调用
build_paddle_data_pipeline和build_torch_data_pipeline生成数据集和 DataLoader。分别取两个 Dataset,两个 DataLoader 产生的前 5 个 batch 的数据,转换为 numpy 数组,写入文件中。
利用
ReprodDiffHelper检查两个文件中的数据是否一致。
test_data.py 代码实现如下:
from functools import partial
import numpy as np
import paddle
import pandas as pd
import torch
from datasets import Dataset
from paddlenlp.data import Dict, Pad, Stack
from paddlenlp.datasets import load_dataset as ppnlp_load_dataset
from paddlenlp.transformers import BertTokenizer as PPNLPBertTokenizer
from reprod_log import ReprodDiffHelper, ReprodLogger
from transformers import BertTokenizer as HFBertTokenizer
from transformers import DataCollatorWithPadding
def build_paddle_data_pipeline():
def read(data_path):
df = pd.read_csv(data_path, sep="\t")
for _, row in df.iterrows():
yield {"sentence": row["sentence"], "labels": row["label"]}
#数据转换函数
def convert_example(example, tokenizer, max_length=128):
labels = np.array([example["labels"]], dtype="int64")
example = tokenizer(example["sentence"], max_seq_len=max_length)
return {
"input_ids": np.array(
example["input_ids"], dtype="int64"),
"token_type_ids": np.array(
example["token_type_ids"], dtype="int64"),
"labels": labels,
}
# 加载分词器
tokenizer = PPNLPBertTokenizer.from_pretrained("bert-base-uncased")
# 加载数据
dataset_test = ppnlp_load_dataset(
read, data_path='demo_sst2_sentence/demo.tsv', lazy=False)
trans_func = partial(convert_example, tokenizer=tokenizer, max_length=128)
# 对数据进行分词
dataset_test = dataset_test.map(trans_func, lazy=False)
collate_fn = lambda samples, fn=Dict({
"input_ids": Pad(axis=0, pad_val=tokenizer.pad_token_id),
"token_type_ids": Pad(axis=0, pad_val=tokenizer.pad_token_type_id),
"labels": Stack(dtype="int64"), }): fn(samples)
test_sampler = paddle.io.SequenceSampler(dataset_test)
test_batch_sampler = paddle.io.BatchSampler(
sampler=test_sampler, batch_size=4)
data_loader_test = paddle.io.DataLoader(
dataset_test,
batch_sampler=test_batch_sampler,
num_workers=0,
collate_fn=collate_fn, )
return dataset_test, data_loader_test
def build_torch_data_pipeline():
tokenizer = HFBertTokenizer.from_pretrained("bert-base-uncased")
#数据转换函数
def preprocess_function(examples):
result = tokenizer(
examples["sentence"],
padding=False,
max_length=128,
truncation=True,
return_token_type_ids=True, )
if "label" in examples:
result["labels"] = [examples["label"]]
return result
# 加载数据
dataset_test = Dataset.from_csv("demo_sst2_sentence/demo.tsv", sep="\t")
dataset_test = dataset_test.map(
preprocess_function,
batched=False,
remove_columns=dataset_test.column_names,
desc="Running tokenizer on dataset", )
dataset_test.set_format(
"np", columns=["input_ids", "token_type_ids", "labels"])
test_sampler = torch.utils.data.SequentialSampler(dataset_test)
collate_fn = DataCollatorWithPadding(tokenizer)
data_loader_test = torch.utils.data.DataLoader(
dataset_test,
batch_size=4,
sampler=test_sampler,
num_workers=0,
collate_fn=collate_fn, )
return dataset_test, data_loader_test
def test_data_pipeline():
diff_helper = ReprodDiffHelper()
paddle_dataset, paddle_dataloader = build_paddle_data_pipeline()
torch_dataset, torch_dataloader = build_torch_data_pipeline()
logger_paddle_data = ReprodLogger()
logger_torch_data = ReprodLogger()
logger_paddle_data.add("length", np.array(len(paddle_dataset)))
logger_torch_data.add("length", np.array(len(torch_dataset)))
# 迭代五轮验证
for idx in range(5):
rnd_idx = np.random.randint(0, len(paddle_dataset))
for k in ["input_ids", "token_type_ids", "labels"]:
logger_paddle_data.add(f"dataset_{idx}_{k}",
paddle_dataset[rnd_idx][k])
logger_torch_data.add(f"dataset_{idx}_{k}",
torch_dataset[rnd_idx][k])
for idx, (paddle_batch, torch_batch
) in enumerate(zip(paddle_dataloader, torch_dataloader)):
if idx >= 5:
break
for i, k in enumerate(["input_ids", "token_type_ids", "labels"]):
logger_paddle_data.add(f"dataloader_{idx}_{k}",
paddle_batch[i].numpy())
logger_torch_data.add(f"dataloader_{idx}_{k}",
torch_batch[k].cpu().numpy())
diff_helper.compare_info(logger_paddle_data.data, logger_torch_data.data)
diff_helper.report()
if __name__ == "__main__":
test_data_pipeline()
五、模型训练对齐¶
5.1 评估指标对齐¶
5.1.1 评估指标代码转换¶
飞桨提供了一系列 Metric 计算类,比如说Accuracy, Auc, Precision, Recall等,而 PyTorch 中,目前可以通过组合的方式实现 metric 计算,或者调用huggingface-datasets,在论文复现的过程中,需要注意保证对于该模块,给定相同的输入,二者输出完全一致。
【转换前】
PyTorch 准确率评估指标使用的是 huggingface 的 datasets 库。
import torch
import numpy as np
from datasets import load_metric
hf_metric = load_metric("accuracy.py")
logits = np.random.normal(0, 1, size=(64, 2)).astype("float32")
labels = np.random.randint(0, 2, size=(64,)).astype("int64")
hf_metric.add_batch(predictions=torch.from_numpy(logits).argmax(dim=-1), references=torch.from_numpy(labels))#利用 argmax 从而计算准确率
hf_accuracy = hf_metric.compute()["accuracy"]
print(hf_accuracy)
【转换后】
转换后的飞桨实现:使用 paddle.metric 中的 Accuracy 替换即可。
import paddle
import numpy as np
from paddle.metric import Accuracy
pd_metric = Accuracy()
pd_metric.reset()
logits = np.random.normal(0, 1, size=(64, 2)).astype("float32")
labels = np.random.randint(0, 2, size=(64,)).astype("int64")
correct = pd_metric.compute(paddle.to_tensor(logits), paddle.to_tensor(labels))#计算指标
pd_metric.update(correct)
pd_accuracy = pd_metric.accumulate()
print(pd_accuracy)
5.1.2 评估指标正确性验证¶
【生成指标评估文件】
使用该文件生成 paddle 和 pytorch 指标:test_metric.py
【生成对比日志的文件】
使用该文件生成对齐结果日志文件:check_step2.py
【验证步骤】
对脚本test_metric.py执行以下命令,验证评估指标对齐效果。
# 生成 paddle 和 pytorch 指标
python test_metric.py
# 对比生成 log
python check_step2.py
验证后结果存放的日志文件:Step2/metric_diff.log。查看metric_diff.log,若输出以下结果,则说明评估指标的实现正确。
[2022/10/20 15:54:03] root INFO: accuracy:
[2022/10/20 15:54:03] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/20 15:54:03] root INFO: diff check passed
验证脚本 test_metric.py 的代码实现如下:通过制造随机的数据,比较两者的 metric 计算是否一致。
import numpy as np
import paddle
import torch
from datasets import load_metric
from paddle.metric import Accuracy
from reprod_log import ReprodLogger
def generate():
pd_metric = Accuracy()
pd_metric.reset()
hf_metric = load_metric("accuracy.py")
for i in range(4):
logits = np.random.normal(0, 1, size=(64, 2)).astype("float32")
labels = np.random.randint(0, 2, size=(64, )).astype("int64")
# paddle 指标
correct = pd_metric.compute(
paddle.to_tensor(logits), paddle.to_tensor(labels))
pd_metric.update(correct)
# hf 指标
hf_metric.add_batch(
predictions=torch.from_numpy(logits).argmax(dim=-1),
references=torch.from_numpy(labels), )
pd_accuracy = pd_metric.accumulate()
hf_accuracy = hf_metric.compute()["accuracy"]
reprod_logger = ReprodLogger()
reprod_logger.add("accuracy", np.array([pd_accuracy]))
reprod_logger.save("metric_paddle.npy")
reprod_logger = ReprodLogger()
reprod_logger.add("accuracy", np.array([hf_accuracy]))
reprod_logger.save("metric_torch.npy")
if __name__ == "__main__":
generate()
5.2 损失函数对齐¶
5.2.1 损失函数代码转换¶
【转换前】
PyTorch 实现的损失函数代码:
loss = torch.nn.CrossEntropyLoss(
output, torch.tensor(
labels, dtype=torch.int64))
【转换后】
转换后的飞桨实现:
loss = paddle.nn.CrossEntropyLoss(
output, paddle.to_tensor(
labels, dtype="int64"))
【转换步骤】
本例采用的是分类任务中最常用的交叉熵损失函数。PyTorch 与飞桨均提供了这一函数。
转换步骤:
将
torch.nn.CrossEntropyLoss替换成paddle.nn.CrossEntropyLoss。将
torch.tensor函数替换成paddle.to_tensor。将
torch.int64改为字符串"int64"。
【API 对比】
| PyTorch | 飞桨 | 主要差异 | 作用 |
|---|---|---|---|
| torch.nn.CrossEntropyLoss | paddle.nn.CrossEntropyLoss | 飞桨提供了对软标签、指定 softmax 计算维度的支持 | 计算预测向量与标签之间的交叉熵损失 |
5.2.2 损失函数正确性验证¶
【验证步骤】
对脚本Step3/check_step3.py执行如下命令,验证损失函数的输出是否一致。
# 生成 paddle 的前向 loss 结果
python paddle_loss.py
# 生成 torch 的前向 loss 结果
python torch_loss.py
# 对比生成 log
python check_step3.py
验证后结果存放的日志文件为:Step3/loss_diff.log,查看 loss_diff.log,若输出以下结果,则说明损失函数的实现正确。
[2022/10/20 15:47:55] root INFO: loss:
[2022/10/20 15:47:55] root INFO: mean diff: check passed: True, value: 5.960464477539063e-08
[2022/10/20 15:47:55] root INFO: diff check passed
diff 为 5.96e-8,check 通过。
验证脚本执行的主要步骤包括:
定义 PyTorch 模型,加载权重,加载 fake data 和 fake label(或者固定 seed,基于 numpy 生成随机数),转换为 PyTorch 可以处理的 tensor,送入网络,获取 loss 结果,使用 reprod_log 保存结果。
定义 PaddlePaddle 模型,加载 fake data 和 fake label(或者固定 seed,基于 numpy 生成随机数),转换为 PaddlePaddle 可以处理的 tensor,送入网络,获取 loss 结果,使用 reprod_log 保存结果。
使用 reprod_log 排查 diff,小于阈值,即可完成自测。
验证脚本 torch_loss.py 的代码实现如下:
import sys
import os
import numpy as np
import paddle
import torch
import torch.nn as nn
from reprod_log import ReprodLogger
CURRENT_DIR = os.path.split(os.path.abspath(__file__))[0] # 当前目录
CONFIG_PATH = CURRENT_DIR.rsplit('/', 1)[0]
sys.path.append(CONFIG_PATH)
from models.pt_bert import BertConfig, BertForSequenceClassification
if __name__ == "__main__":
# def logger
reprod_logger = ReprodLogger()
criterion = nn.CrossEntropyLoss()
pytorch_dump_path = '../weights/torch_weight.bin'
config = BertConfig()
model = BertForSequenceClassification(config)
checkpoint = torch.load(pytorch_dump_path)
model.bert.load_state_dict(checkpoint)
classifier_weights = torch.load(
"../classifier_weights/torch_classifier_weights.bin")
model.load_state_dict(classifier_weights, strict=False)
model.eval()
# 读取 gen fake data
fake_data = np.load("../fake_data/fake_data.npy")
fake_data = torch.from_numpy(fake_data)
fake_label = np.load("../fake_data/fake_label.npy")
fake_label = torch.from_numpy(fake_label)
# 前向网络
out = model(fake_data)[0]
loss = criterion(out, fake_label)
reprod_logger.add("loss", loss.cpu().detach().numpy())
reprod_logger.save("loss_torch.npy")
验证脚本 paddle_loss.py 的源代码:
# paddle_loss.py
if __name__ == "__main__":
paddle.set_device("cpu")
# 定义 logger
reprod_logger = ReprodLogger()
model = BertForSequenceClassification.from_pretrained("bert-base-uncased", num_classes=2)
classifier_weights = paddle.load("../classifier_weights/paddle_classifier_weights.bin")
model.load_dict(classifier_weights)
model.eval()
criterion = nn.CrossEntropyLoss()
# 构造伪数据
fake_data = np.load("../fake_data/fake_data.npy")
fake_data = paddle.to_tensor(fake_data)
fake_label = np.load("../fake_data/fake_label.npy")
fake_label = paddle.to_tensor(fake_label)
# 向前得到模型输出
out = model(fake_data)
loss = criterion(out, fake_label)
reprod_logger.add("loss", loss.cpu().detach().numpy())
reprod_logger.save("loss_paddle.npy")
5.3 超参对齐¶
【转换前】
PyTorch 实现的优化器相关代码:
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [
p for n, p in model.named_parameters()
if not any(nd in n for nd in no_decay)
],
"weight_decay": 1e-2,#参数权重衰减
},
{
"params": [
p for n, p in model.named_parameters()
if any(nd in n for nd in no_decay)
],
"weight_decay": 0.0,
},
]
optimizer = AdamW(optimizer_grouped_parameters, lr=3e-5)
【转换后】
转换后的飞桨实现:将 LayerNorm 的参数,还有 Linear 的 bias 参数,设置不使用 weight_decay。
decay_params = [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
]
optimizer = paddle.optimizer.AdamW(
learning_rate=3e-5,
parameters=model.parameters(),
weight_decay=1e-2,#参数权重衰减
epsilon=1e-6,
apply_decay_param_fun=lambda x: x in decay_params, )
【注意事项】
pytorch 和飞桨在权重衰减参数方面传参形式有所不同,PyTorch 需要对不同权重的模型参数分别构建一个字典,而飞桨采用匿名函数的方式传入权重衰减的参数。
【API 对比】
飞桨与 PyTorch 优化器相关 API 对比:
| 飞桨 | PyTorch | 主要差异 | 作用 |
|---|---|---|---|
| paddle.optimizer.SGD | torch.optim.SGD | 飞桨增加对梯度裁剪(grad_clip)的支持飞桨不支持动量更新、动量衰减和 Nesterov 动量(需要使用 paddle.optimiaer.Momentum API) | 以随机梯度下降的方式更新参数 |
| paddle.optimizer.lr.StepDecay | torch.optim.lr_scheduler.StepLR | 二者参数不同,飞桨传入初始学习率 learning_rate,PyTorch 则是传入优化器 optimizer。 |
每隔固定轮次调整学习率下降 |
5.4 学习率对齐¶
学习率策略主要用于指定训练过程中的学习率变化曲线,这里可以将定义好的学习率策略,不断 step,即可得到对应的学习率值,可以将学习率值保存在列表或者矩阵中,使用reprod_log工具判断二者是否对齐。
【注意事项】
飞桨需要首先构建学习率策略,再传入优化器对象中;对于 PyTorch,如果希望使用更丰富的学习率策略,需要先构建优化器,再传入学习率策略类 API。
torch: https://github.com/PaddlePaddle/PaddleNLP/blob/develop/examples/torch_migration/pipeline/Step5/bert_torch/train.py#L232-L240 先定义 optimizer,再定义 lr_scheduler
paddle:
https://github.com/PaddlePaddle/PaddleNLP/blob/develop/examples/torch_migration/pipeline/Step5/bert_paddle/train.py#L204-L223 先定义 lr_scheduler,再定义 optimizer
【验证步骤】
对脚本Step4/test_lr_scheduler.py执行运行如下命令,验证学习率的输出是否一致。
python test_lr_scheduler.py
输出如下结果,linear 和 polynomial 方式衰减的学习率 diff 为 0,check 通过,cosine 方式衰减学习率可能由于计算误差未通过。
[2022/10/20 15:22:23] root INFO: step_100_linear_lr:
[2022/10/20 15:22:23] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/20 15:22:23] root INFO: step_300_linear_lr:
[2022/10/20 15:22:23] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/20 15:22:23] root INFO: step_500_linear_lr:
[2022/10/20 15:22:23] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/20 15:22:23] root INFO: step_700_linear_lr:
[2022/10/20 15:22:23] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/20 15:22:23] root INFO: step_900_linear_lr:
[2022/10/20 15:22:23] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/20 15:22:23] root INFO: step_100_cosine_lr:
[2022/10/20 15:22:23] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/20 15:22:23] root INFO: step_300_cosine_lr:
[2022/10/20 15:22:23] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/20 15:22:23] root INFO: step_500_cosine_lr:
[2022/10/20 15:22:23] root INFO: mean diff: check passed: False, value: 9.35605818719964e-06
[2022/10/20 15:22:23] root INFO: step_700_cosine_lr:
[2022/10/20 15:22:23] root INFO: mean diff: check passed: False, value: 1.3681476625617212e-05
[2022/10/20 15:22:23] root INFO: step_900_cosine_lr:
[2022/10/20 15:22:23] root INFO: mean diff: check passed: False, value: 1.8924391285779562e-05
[2022/10/20 15:22:23] root INFO: step_100_polynomial_lr:
[2022/10/20 15:22:23] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/20 15:22:23] root INFO: step_300_polynomial_lr:
[2022/10/20 15:22:23] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/20 15:22:23] root INFO: step_500_polynomial_lr:
[2022/10/20 15:22:23] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/20 15:22:23] root INFO: step_700_polynomial_lr:
[2022/10/20 15:22:23] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/20 15:22:23] root INFO: step_900_polynomial_lr:
[2022/10/20 15:22:23] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/20 15:22:23] root INFO: diff check failed
验证脚本 test_lr_scheduler.py 源代码:通过调用各自的 scheduler 函数,逐 step 对学习率的值进行核对。
import numpy as np
import paddle
import torch
# define paddle scheduler
from paddlenlp.transformers import (
CosineDecayWithWarmup,
LinearDecayWithWarmup,
PolyDecayWithWarmup, )
from reprod_log import ReprodDiffHelper, ReprodLogger
from torch.optim import AdamW
from transformers.optimization import get_scheduler as get_hf_scheduler
scheduler_type2cls = {
"linear": LinearDecayWithWarmup,
"cosine": CosineDecayWithWarmup,
"polynomial": PolyDecayWithWarmup,
}#定义不同调度器
def get_paddle_scheduler(
learning_rate,
scheduler_type,
num_warmup_steps=None,
num_training_steps=None,
**scheduler_kwargs, ):
if scheduler_type not in scheduler_type2cls.keys():
data = " ".join(scheduler_type2cls.keys())
raise ValueError(f"scheduler_type must be choson from {data}")
if num_warmup_steps is None:
raise ValueError(
f"requires `num_warmup_steps`, please provide that argument.")
if num_training_steps is None:
raise ValueError(
f"requires `num_training_steps`, please provide that argument.")
return scheduler_type2cls[scheduler_type](
learning_rate=learning_rate,
total_steps=num_training_steps,
warmup=num_warmup_steps,
**scheduler_kwargs, )
def test_lr():
diff_helper = ReprodDiffHelper()
pd_reprod_logger = ReprodLogger()
hf_reprod_logger = ReprodLogger()
lr = 3e-5
num_warmup_steps = 345
num_training_steps = 1024
milestone = [100, 300, 500, 700, 900]
for scheduler_type in ["linear", "cosine", "polynomial"]:
torch_optimizer = AdamW(torch.nn.Linear(1, 1).parameters(), lr=lr)
hf_scheduler = get_hf_scheduler(#获取调度器
name=scheduler_type,
optimizer=torch_optimizer,
num_warmup_steps=num_warmup_steps,
num_training_steps=num_training_steps, )
pd_scheduler = get_paddle_scheduler(
learning_rate=lr,
scheduler_type=scheduler_type,
num_warmup_steps=num_warmup_steps,
num_training_steps=num_training_steps, )
for i in range(num_training_steps):
hf_scheduler.step()
pd_scheduler.step()
if i in milestone:
hf_reprod_logger.add(
f"step_{i}_{scheduler_type}_lr",
np.array([hf_scheduler.get_last_lr()[-1]]), )
pd_reprod_logger.add(f"step_{i}_{scheduler_type}_lr",
np.array([pd_scheduler.get_lr()]))
diff_helper.compare_info(hf_reprod_logger.data, pd_reprod_logger.data)
diff_helper.report()
if __name__ == "__main__":
test_lr()
5.5 反向梯度对齐¶
【验证步骤】
对脚本Step4/test_bp.py执行如下命令,验证反向传播对齐效果。
# 生成 paddle 和 torch 的前向数据
python test_bp.py
# 对比生成 log
python check_step4.py
验证结果存放的日志文件为:Step4/bp_align_diff.log,若输出如下结果,前面 10 轮的 loss diff 均等于 0,check 通过。
[2022/10/20 15:06:56] root INFO: loss_0:
[2022/10/20 15:06:56] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/20 15:06:56] root INFO: loss_1:
[2022/10/20 15:06:56] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/20 15:06:56] root INFO: loss_2:
[2022/10/20 15:06:56] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/20 15:06:56] root INFO: loss_3:
[2022/10/20 15:06:56] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/20 15:06:56] root INFO: loss_4:
[2022/10/20 15:06:56] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/20 15:06:56] root INFO: loss_5:
[2022/10/20 15:06:56] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/20 15:06:56] root INFO: loss_6:
[2022/10/20 15:06:56] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/20 15:06:56] root INFO: loss_7:
[2022/10/20 15:06:56] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/20 15:06:56] root INFO: loss_8:
[2022/10/20 15:06:56] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/20 15:06:56] root INFO: loss_9:
[2022/10/20 15:06:56] root INFO: mean diff: check passed: True, value: 0.0
[2022/10/20 15:06:56] root INFO: diff check passed
验证脚本 test_bp.py的主要步骤包括:
分别加载飞桨模型与 PyTorch 模型以及模型权重。
分别初始化飞桨与 PyTorch 的损失函数及优化器。
加载前面生成好的伪数据。
利用伪数据,分别训练飞桨与 PyTorch 模型,训练
max_iter(这里设置为 10)之后,分别将每一个 iter 的 loss 和学习率保存到文件中。利用
ReprodDiffHelper检查两个文件中的数据是否一致。
验证脚本的执行过程可用以下框图表示:

验证脚本 test_bp.py 的代码实现如下:
import sys
import os
import numpy as np
import paddle
import torch
from reprod_log import ReprodLogger
from transformers import AdamW
CURRENT_DIR = os.path.split(os.path.abspath(__file__))[0] # 当前目录
CONFIG_PATH = CURRENT_DIR.rsplit('/', 1)[0]
sys.path.append(CONFIG_PATH)
from models.pd_bert import (
BertForSequenceClassification as PDBertForSequenceClassification, )
from models.pd_bert import (
BertConfig as PDBertConfig, )
from models.pt_bert import (
BertForSequenceClassification as HFBertForSequenceClassification, )
from models.pt_bert import (
BertConfig as HFBertConfig, )
def pd_train_some_iters(model,
criterion,
optimizer,
fake_data,
fake_label,
max_iter=2):
paddle_dump_path = '../weights/paddle_weight.pdparams'
config = PDBertConfig()
model = PDBertForSequenceClassification(config)
checkpoint = paddle.load(paddle_dump_path)
model.bert.load_dict(checkpoint)
classifier_weights = paddle.load(
"../classifier_weights/paddle_classifier_weights.bin")
model.load_dict(classifier_weights)
model.eval()
criterion = paddle.nn.CrossEntropy()
decay_params = [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
]
optimizer = paddle.optimizer.AdamW(
learning_rate=3e-5,
parameters=model.parameters(),
weight_decay=1e-2,
epsilon=1e-6,
apply_decay_param_fun=lambda x: x in decay_params,
)
loss_list = []
for idx in range(max_iter):
input_ids = paddle.to_tensor(fake_data)
labels = paddle.to_tensor(fake_label)
output = model(input_ids)
loss = criterion(output, labels)
loss.backward()
optimizer.step()
optimizer.clear_grad()
loss_list.append(loss)
return loss_list
def hf_train_some_iters(fake_data, fake_label, max_iter=2):
pytorch_dump_path = '../weights/torch_weight.bin'
config = HFBertConfig()
model = HFBertForSequenceClassification(config)
checkpoint = torch.load(pytorch_dump_path)
model.bert.load_state_dict(checkpoint)
classifier_weights = torch.load(
"../classifier_weights/torch_classifier_weights.bin")
model.load_state_dict(classifier_weights, strict=False)
model.eval()
criterion = torch.nn.CrossEntropyLoss()
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [
p for n, p in model.named_parameters()
if not any(nd in n for nd in no_decay)
],
"weight_decay":
1e-2,
},
{
"params": [
p for n, p in model.named_parameters()
if any(nd in n for nd in no_decay)
],
"weight_decay":
0.0,
},
]
optimizer = AdamW(optimizer_grouped_parameters, lr=3e-5)
loss_list = []
for idx in range(max_iter):
input_ids = torch.from_numpy(fake_data)
labels = torch.from_numpy(fake_label)
output = model(input_ids)[0]
loss = criterion(output, labels)
loss.backward()
optimizer.step()
optimizer.zero_grad()
loss_list.append(loss)
return loss_list
if __name__ == "__main__":
print("Start training")
paddle.set_device("cpu")
fake_data = np.load("../fake_data/fake_data.npy")
fake_label = np.load("../fake_data/fake_label.npy")
hf_reprod_logger = ReprodLogger()
hf_loss_list = hf_train_some_iters(fake_data, fake_label, 10)
for idx, loss in enumerate(hf_loss_list):
hf_reprod_logger.add(f"loss_{idx}", loss.detach().cpu().numpy())
hf_reprod_logger.save("bp_align_torch.npy")
pd_reprod_logger = ReprodLogger()
pd_loss_list = hf_train_some_iters(fake_data, fake_label, 10)
for idx, loss in enumerate(pd_loss_list):
pd_reprod_logger.add(f"loss_{idx}", loss.detach().cpu().numpy())
pd_reprod_logger.save("bp_align_paddle.npy")
5.5 训练精度对齐¶
至此,模型、数据读取、评估指标、损失函数、超参、调度器、反向梯度的代码转换均已完成并验证正确。最后,需要分别训练迁移前后的模型,比较训练后的验证精度。
飞桨训练入口脚本:Step5/bert_paddle/train.sh
PyTorch 入口脚本:Step5/bert_torch/train.sh
【验证步骤】
首先运行下面的 python 代码,生成 train_align_torch.npy 和 train_align_paddle.npy 文件。
运行生成 paddle 结果
cd bert_paddle/
sh train.sh
运行生成 torch 结果
cd bert_torch/
sh train.sh
对比生成 log 执行下面的命令,运行训练脚本;之后使用 check_step5.py 进行精度 diff 验证。
python check_step5.py
这里需要注意的是,由于是精度对齐,SST-2 数据集的精度 diff 在 0.25%以内时,可以认为对齐,因此将 diff_threshold 参数修改为了 0.0025。
[2022/10/20 18:54:12] root INFO: acc:
[2022/10/20 18:54:12] root INFO: mean diff: check passed: True, value: 0.002293577981651418
[2022/10/20 18:54:12] root INFO: diff check passed
最终 diff 为 0.00229,小于阈值标准,检查通过。
若最终训练精度与原模型精度的差异在期望差异内,则说明迁移成功。
该任务为基于 SST-2 数据集的分类任务,可以看出 Paddle 的精度与原始代码的精度差异为 0.25%,在可接受范围内,因此认为迁移成功。
5.6 训练性能对齐¶
在相同的硬件条件下(相同的 GPU 型号和数量)训练相同的轮数,迁移前后的模型训练时间应当接近。若二者差异过大,且前面的步骤均已对齐,可以 Github Issues 的方式报告问题。
六、总结¶
本文以 Bert 为例,完成了一个完整的从 PyTorch 到飞桨的模型迁移实践流程,包括迁移准备、模型结构、数据处理、损失函数、超参、模型训练。希望通过这个简单的实例,让你对 NLP 领域的模型迁移有个初步的了解。