解读网络结构转换
模型组网是深度学习任务中的重要一环,本文以一些经典网络为例对比 PyTorch 和飞桨在网络构建的差异,并提供网络结构转化的思路和方法,帮助开发者加深对网络结构转换的理解。
一、网络结构概述
模型网络结构相当于模型的假设空间,即模型能够表达的关系集合,定义了神经网络的层次结构、数据从输入到输出的计算过程(即前向计算)等。
为了提高开发效率,避免重复造轮子,飞桨提供了以下几种 API 快速构建网络结构:
基础 API:飞桨以 API(内置的模块、函数等)的形式提供了丰富的神经网络层帮助开发者快速构建网络,如卷积网络相关的 Conv1D、Conv2D、Conv3D,循环神经网络相关的 RNN、LSTM、GRU 等。在搭建神经网络时,通过使用飞桨提供的 API,可以快速完成网络的开发。常用的基础 API 可分为以下几类:
| 类别 | 简介 | 举例 |
|---|---|---|
| 基础操作类 | 主要为paddle.XX类 API |
paddle.to_tensor, paddle.reshape, paddle.mean |
| 组网类 | 主要为paddle.nn.XX类下组网相关的 API |
paddle.nn.Conv2D, paddle.nn.Linear, paddle.nn.BatchNorm2D |
| Loss 类 | 主要为paddle.nn.XX类下 loss 相关的 API |
paddle.nn.MSELoss, paddle.nn.CrossEntropyLoss |
| 数据读取类 | 主要为paddle.io.XX类 API |
paddle.io.Dataset, paddle.io.DataLoader, paddle.io.BatchSampler |
高层 API:
CV:飞桨内置了计算机视觉领域的经典模型,见 paddle.vision.models ,只需一行代码即可完成网络构建和初始化,满足深度学习初阶用户感受模型的输入和输出形式、了解模型的性能。
NLP:飞桨提供自然语言处理领域常用的预训练模型如
BERT、ERNIE、ALBERT、RoBERTa、XLNet等,见 paddlenlp.transformers,方便开发者采用统一的 API 进行加载、训练和调用。
>>> import paddle
>>> print('飞桨框架内置模型:', paddle.vision.models.__all__)
飞桨框架内置模型: ['ResNet', 'resnet18', 'resnet34', 'resnet50', 'resnet101', 'resnet152', 'VGG', 'vgg11', 'vgg13', 'vgg16', 'vgg19', 'MobileNetV1', 'mobilenet_v1', 'MobileNetV2', 'mobilenet_v2', 'LeNet']
说明:
除此之外,飞桨还提供了丰富的官方模型库,包含经过产业实践长期打磨的主流模型以及在国际竞赛中的夺冠模型,算法总数超过 500 多个,详细请参考链接:https://www.paddlepaddle.org.cn/modelbase。
二、飞桨和 PyTorch 网络结构对比
为了更直观了解飞桨和 PyTorch 的差异,我们以LeNet网络为例进行下文的讲解。LeNet是一个非常简单的卷积神经网络,由卷积层Conv2d、最大池化层MaxPool2d、ReLu激活函数及全连接层Linear组成。
飞桨和 PyTorch 都集成了这个模型,下面我们对比看一下两者的实现细节。
2.1 基于飞桨的网络结构
在飞桨中,paddle.nn 提供了常见神经网络层的实现,如卷积网络相关的 Conv1D、Conv2D、Conv3D,循环神经网络相关的 RNN、LSTM、GRU 等,基于这些 API 可完成大多数神经网络的搭建,详细清单可在 API 文档 中查看。同时,飞桨提供继承类(class)的方式构建网络,paddle.nn.Layer 类是构建所有网络的基类,通过构建一个继承基类的子类,并在子类中添加层(layer,如卷积层、全连接层等)即可实现网络的构建。飞桨中的组网 API 与 PyTorch 的 API 较为相似,部分 API 在参数名或功能上存在一定差异。部分 API 在完整的飞桨与 PyTorch 组网类 API 映射表请参考组网类 API 映射列表。
使用飞桨构建网络的步骤如下:
创建一个继承自 paddle.nn.Layer 的类;
在类的构造函数
__init__中定义组网用到的神经网络层(layer);在类的前向计算函数
forward中使用定义好的 layer 执行前向计算。
以 LeNet 模型为例,可通过如下代码组网:
import paddle
from paddle import nn
class LeNet(nn.Layer):
def __init__(self, num_classes=10):
super(LeNet, self).__init__()
self.num_classes = num_classes
self.features = nn.Sequential(
nn.Conv2D(1, 6, 3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2D(2, 2),
nn.Conv2D(6, 16, 5, stride=1, padding=0),
nn.ReLU(),
nn.MaxPool2D(2, 2)
)
self.fc = nn.Sequential(
nn.Linear(400, 120),
nn.Linear(120, 84), nn.Linear(84, num_classes))
def forward(self, inputs):
x = self.features(inputs)
x = paddle.flatten(x, 1)
x = self.fc(x)
return x
通过 paddle.summary 可以查看飞桨网络结构。
# 模型组网并初始化网络
lenet = paddle.vision.models.LeNet(num_classes=10)
# 可视化模型组网结构和参数
paddle.summary(lenet,(1, 1, 28, 28))
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv2D-1 [[1, 1, 28, 28]] [1, 6, 28, 28] 60
ReLU-1 [[1, 6, 28, 28]] [1, 6, 28, 28] 0
MaxPool2D-1 [[1, 6, 28, 28]] [1, 6, 14, 14] 0
Conv2D-2 [[1, 6, 14, 14]] [1, 16, 10, 10] 2,416
ReLU-2 [[1, 16, 10, 10]] [1, 16, 10, 10] 0
MaxPool2D-2 [[1, 16, 10, 10]] [1, 16, 5, 5] 0
Linear-1 [[1, 400]] [1, 120] 48,120
Linear-2 [[1, 120]] [1, 84] 10,164
Linear-3 [[1, 84]] [1, 10] 850
===========================================================================
Total params: 61,610
Trainable params: 61,610
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.11
Params size (MB): 0.24
Estimated Total Size (MB): 0.35
---------------------------------------------------------------------------
{'total_params': 61610, 'trainable_params': 61610}
2.2 基于 PyTorch 的网络结构
PyTorch 模块通常继承torch.nn.Module,对模块的定义方法与飞桨类似,即在 __init__中定义模块中用到的子模块,然后 forward函数中定义前向传播的方式。
使用 PyTorch 构建网络的步骤如下:
创建一个继承自
torch.nn.Module的类。在类的构造函数
__init__中定义组网用到的神经网络层(layer)。在类的前向计算函数
forward中使用定义好的 layer 执行前向计算。
以 LeNet 模型为例,可通过如下代码组网:
import torch
from torch import nn
class LeNet(nn.Module):
def __init__(self, num_classes=10):
super(LeNet, self).__init__()
self.num_classes = num_classes
self.features = nn.Sequential(
nn.Conv2d(1, 6, 3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(6, 16, 5, stride=1, padding=0),
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
self.fc = nn.Sequential(
nn.Linear(400, 120),
nn.Linear(120, 84), nn.Linear(84, num_classes))
def forward(self, inputs):
x = self.features(inputs)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
>>> import torch
>>> from lenet import LeNet
>>> net = LeNet()
>>> print(net)
LeNet(
(features): Sequential(
(0): Conv2d(1, 6, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(4): ReLU()
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(fc): Sequential(
(0): Linear(in_features=400, out_features=120, bias=True)
(1): Linear(in_features=120, out_features=84, bias=True)
(2): Linear(in_features=84, out_features=10, bias=True)
)
)
如果需要打印类似于飞桨样式的网络结构,可以使用第三方库 torchsummary 中提供的 summary 方法实现。
首先需要安装 torchsummary 库:
pip install torchsummary
使用 summary 查看网络结构:
from lenet import LeNet
from torchsummary import summary
net = LeNet().cuda()
summary(net, (1, 28, 28))
输出结果如下:
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 6, 28, 28] 60
ReLU-2 [-1, 6, 28, 28] 0
MaxPool2d-3 [-1, 6, 14, 14] 0
Conv2d-4 [-1, 16, 10, 10] 2,416
ReLU-5 [-1, 16, 10, 10] 0
MaxPool2d-6 [-1, 16, 5, 5] 0
Linear-7 [-1, 120] 48,120
Linear-8 [-1, 84] 10,164
Linear-9 [-1, 10] 850
================================================================
Total params: 61,610
Trainable params: 61,610
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.11
Params size (MB): 0.24
Estimated Total Size (MB): 0.35
----------------------------------------------------------------
2.3 网络结构对比分析
PyTorch 中的网络模块继承torch.nn.Module,而飞桨的网络模块则继承paddle.nn.Layer。二者对网络结构的定义方式相似,都是在__init__中定义构成网络的各个子模块,并实现forward函数,定义网络的前向传播方式。LeNet 使用到的 PyTorch API 与对应的飞桨 API 如下表所示。
| PyTorch | 飞桨 |
|---|---|
| torch.nn.Module | paddle.nn.Layer |
| torch.nn.Conv2d | paddle.nn.Conv2D |
| torch.nn.ReLU | paddle.nn.ReLU |
| torch.nn.MaxPool2d | paddle.nn.MaxPool2D |
| torch.nn.Sequential | paddle.nn.Sequential |
| torch.nn.Linear | paddle.nn.Linear |
| torch.flatten | paddle.flatten |
从前面 LeNet 网络结构的实现对比来看,两者 API 命名基本一致,功能也一致。
三、网络结构转换
网络结构转换过程中,通常我们以神经网络作者本身的实现为准,确保转换后的网络结构与转换前完全一致。
以从 PyTorch 框架到 Paddle 框架的网络结构转换为例,转换的具体流程如下所说义。
3.1 分析网络结构
首先应通过阅读论文及源代码,分析网络结构的类型(CNN 或 Transformer)、组织结构(layer、block 等)、各模块的输入输出维度以及创新点等。
以 MobileNetV3 为例,首先通过阅读论文,得知其使用了与 MobileNetV2 类似的 Inverted Residual block 作为构成网络的基本模块,在此基础上加入了 Squeeze-and-Excite (SE) 模块,并且提出了 h-swish 替代 ReLU 作为激活函数。
下表为论文中给出的 MobileNetV3 的整体网络结构,从表中可以清楚地了解到组成网络的各个模块的参数及输出输出维度。
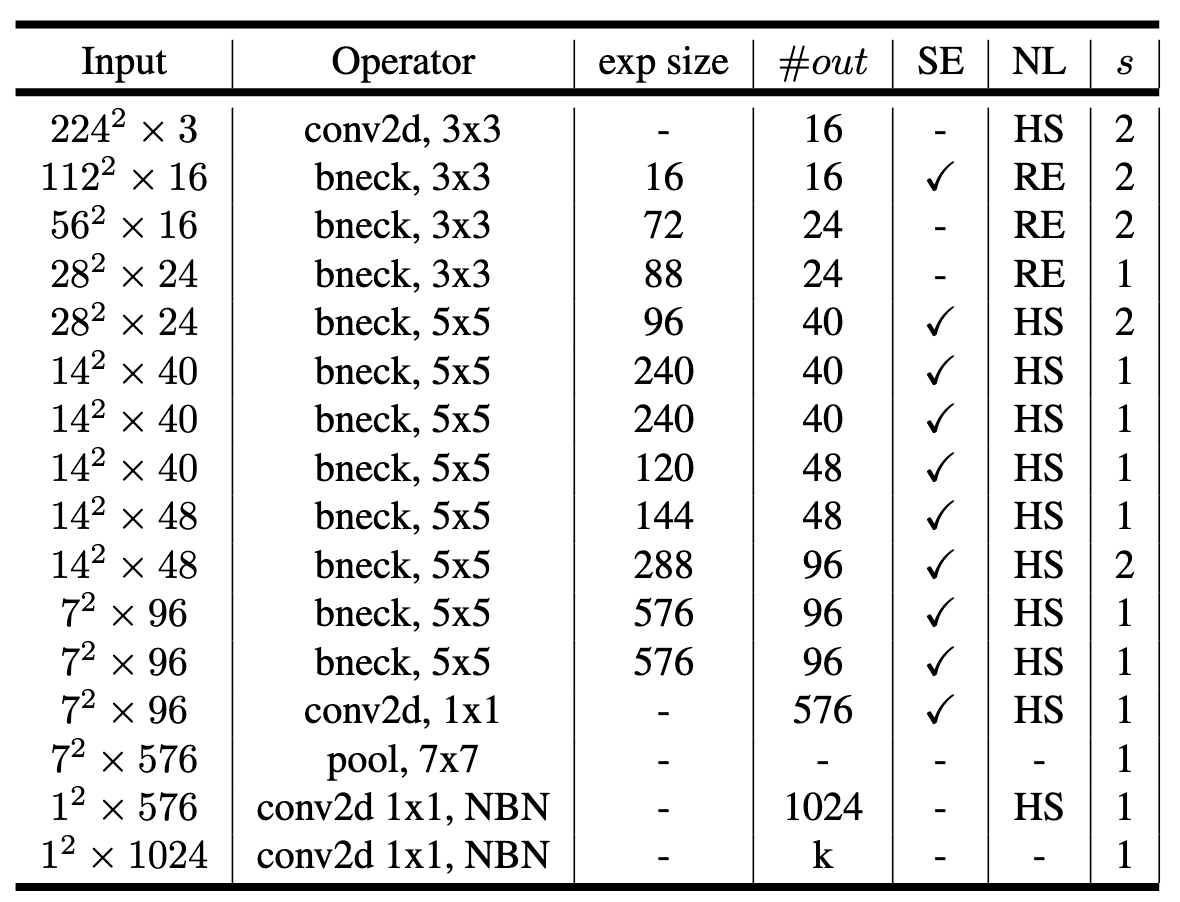
阅读完论文之后,还需要分析参考代码的实现方式。这里选择 torchvision 官方的 MobileNetV3 实现 作为参考代码。
通过阅读源代码,可以发现 MobileNetV3 的基本 block 是在 InvertedResidual 类中定义的,在 block 的搭建中又使用到了 Conv2dNormActivation 与 SqueezeExcitation 这两个模块(这两个模块是从 ..ops.misc 中 import 的,因此需要到 ../ops/misc.py 中查看这两个模块的实现;代码转换时,这两个模块也需一并转换)。MobileNetV3 类则使用前面定义好的 block 来搭建完整的网络。由此,我们可以知道,需要转换的模块(类)有 Conv2dNormActivation, SqueezeExcitation, InvertedResidual 以及 MobileNetV3。
在做下游任务模型(如检测、分割)转换时,需要留意原始代码是否使用了预训练模型。若使用了预训练模型,则需要将 PyTorch 的预训练权重转换为飞桨格式的模型权重。
此外,分析论文是否能通过飞桨已有模型或者少量修改即可实现。模型的实现具有相通性,迁移过程中可参考和借鉴飞桨已实现模型的代码,这样可以减少模型开发的工作量,提升模型迁移效率。
飞桨提供了丰富的官方模型库,覆盖了机器视觉、自然语言处理、语音、推荐系统等多个领域的主流模型,包含经过产业实践长期打磨的主流模型以及在国际竞赛中的夺冠模型,算法总数超过 500 多个,可以从以下链接查找是否有需要的模型:
https://www.paddlepaddle.org.cn/modelbase。
如果飞桨官方已实现,建议根据 PyTorch 代码重新实现一遍,一方面是对整体的模型结构更加熟悉,另一方面也保证模型结构和权重完全对齐。
3.2 分析 API 满足度
这里分析的 API 缺失专指网络执行图中的 API,包含飞桨的算子及高级封装 API,不包括数据处理中使用的 API。
3.2.1 查找 API 映射表
拿到参考代码实现后,可以通过过滤 torch, nn, F(torch.nn.functional) 等关键字获取使用到的 PyTorch API,然后对照PyTorch-飞桨 API 映射表查找对应的飞桨 API。
若参考代码调用了其他库的方法,则需要进一步分析。首先可以查看调用的方法是否与 PyTorch 相关,若与 PyTorch 无关,则可以直接调用,无需修改。若调用的 API 是基于 PyTorch 的(比如调用了 TIMM 中的模块),尽管飞桨的套件(如 PaddleClas、PaddleDetection)可能实现了这些 API,但由于实现的细节可能存在差异,仍建议抽取出使用到的库的源码,将其转换为基于飞桨的代码。
其他框架 API 的映射可以参考 API 命名与功能描述。注意,针对相同功能的 API,飞桨的命名可能与其他框架不同,同名 API 参数与功能也可能与其他框架有区别,均以官方描述为准。
如果没有找到对应的 API 接口,需要用具体的策略来处理 API 缺失的问题。
3.2.2 缺失 API 处理策略
有以下方法来处理缺失 API 的情况。
等价替换
在有些场景下 API 的功能是可以等价替换的,比如可以使用 paddle.put_along_axis 实现 torch.scatter API 的功能。
API 使用示例如下所示。二者对于相同的输入,输出相同。
import paddle import torch x = [[10, 30, 20], [60, 40, 50]] index = [[0, 0, 0]] value = 99 axis = 0 pd_x = paddle.to_tensor(x) pd_index = paddle.to_tensor(index) pd_result = paddle.put_along_axis(pd_x, pd_index, value, axis) print(pd_result) pt_x = torch.tensor(x) pt_index = torch.tensor(index) pt_result = torch.scatter(pt_x, axis, pt_index, value) print(pt_result) # 输出均为 # [[99, 99, 99], # [60, 40, 50]]
使用已有 API 包装等价功能逻辑
对于一些缺失的 API,可以基于飞桨已有的 API 实现等价功能。以 torch.std_mean 为例,该 API 可以返回 tensor 的均值与标准差,paddle 无对应实现,但是可以使用已有的 API 实现相同的功能。如下所示,使用 paddle.mean 与 paddle.std API 可以分别获得 tensor 的均值与标准差。
import numpy as np import paddle import torch np.random.seed(0) x = np.random.rand(3,4,5) pt_x = torch.tensor(x) pt_res = torch.std_mean(pt_x) print(pt_res) pd_x = paddle.to_tensor(x) pd_mean = pd_x.mean() pd_std = pd_x.std() print(pd_std, pd_mean)
自定义算子
当有些情况无法使用已有的 API 进行包装,或者用组合实现的方式性能较差,这个时候就需要使用自定义算子,详情请参考自定义算子指南。
社区求助
若遇到缺失算子,也可以向 PaddlePaddle 团队提 ISSUE,获得支持。开发人员会根据优先级进行开发。
3.3 手工转换 API
如果作者使用 PyTorch 基础 API 进行网络结构设计,由于 PyTorch 的 API 和飞桨的 API 非常相似,可以将调用的 PyTorch API 手工替换成对应的飞桨 API 。
手工转换 API 工作,可以参考PyTorch-飞桨 API 映射表,将原始代码中调用的 PyTorch API(即原始代码中 import 的 torch 包的类、函数,例如 torch.nn 中的模块及 torch.nn.functional 中的函数等)替换成相应的飞桨 API。
需要注意的是,飞桨的部分 API 与 PyTorch 中对应的 API 在功能与参数上存在一定区别,转换时需要留意。
仍然以 LeNet 模型为例,手工转化的具体操作如下。
通过阅读 PyTorch 源码可知,构建 LeNet 使用到的 PyTorch API 有:
nn.Module,nn.Sequential,nn.Conv2d,nn.ReLU,nn.MaxPool2d,nn.Linear以及torch.flatten。通过查找 PyTorch-飞桨 API 映射表,找到对应的飞桨 API:
| **PyTorch** | **飞桨** | 差异对比 |
| ------------------- | -------------------- | ------------------------------------------------------------ |
| torch.nn.Module | paddle.nn.Layer | - |
| torch.nn.Sequential | paddle.nn.Sequential | - |
| torch.nn.Conv2d | paddle.nn.Conv2D | [差异对比](https://github.com/PaddlePaddle/X2Paddle/tree/develop/docs/pytorch_project_convertor/API_docs/nn/torch.nn.Conv2d.md) |
| torch.nn.ReLU | paddle.nn.ReLU | 功能一致,PaddlePaddle 未定义`inplace`参数表示在不更改变量的内存地址的情况下,直接修改变量的值。此处不涉及此差异。 |
| torch.nn.MaxPool2d | paddle.nn.MaxPool2D | [差异对比](https://github.com/PaddlePaddle/X2Paddle/tree/develop/docs/pytorch_project_convertor/API_docs/nn/torch.nn.MaxPool2d.md) |
| torch.nn.Linear | paddle.nn.Linear | [差异对比](https://github.com/PaddlePaddle/X2Paddle/tree/develop/docs/pytorch_project_convertor/API_docs/nn/torch.nn.Linear.md) |
| torch.flatten | paddle.flatten | - |
由于使用到的 PyTorch API 均有对应的飞桨 API,只需根据上述映射表,将 PyTorch API 替换成相应的飞桨 API 即可。
import torch from torch import nn class LeNet(nn.Module): def __init__(self, num_classes=10): super(LeNet, self).__init__() self.num_classes = num_classes self.features = nn.Sequential( nn.Conv2d(1, 6, 3, stride=1, padding=1), nn.ReLU(), nn.MaxPool2d(2, 2), nn.Conv2d(6, 16, 5, stride=1, padding=0), nn.ReLU(), nn.MaxPool2d(2, 2) ) self.fc = nn.Sequential( nn.Linear(400, 120), nn.Linear(120, 84), nn.Linear(84, num_classes)) def forward(self, inputs): x = self.features(inputs) x = torch.flatten(x, 1) x = self.fc(x) return x
3.4 网络结构验证
转换网络结构后,我们还需要进行前向传播的对齐来验证我们上述转换的正确性。我们可以通过前向预测(和下游任务 fine-tuning 这两个任务)进行精度对齐验证。
为了判断转换后的飞桨模型组网能获得和 PyTorch 参考实现同样的输出,可对两个模型加载相同的参数,并输入相同伪数据,观察两者的产出差异是否在阈值内。
模型前向对齐
前向精度的对齐十分简单,我们只需要保证两者输入是一致的前提下,观察得到的输出是否一致。模型在前向对齐验证时,需要调用model.eval()方法,以消除随机因素的影响,比如 BatchNorm、Dropout 等。
下面以 MobileNetV3 为例,说明验证模型前向对齐的步骤。
获取 PyTorch 模型权重,保存为 mobilenet_v3_small.pth,并将 PyTorch 权重转换为飞桨权重,保存为 mv3_small_paddle.pdparams。这是为了前向对齐时保证两个网络加载的权重相同。对于权重转换的详细介绍,请参考:迁移经验汇总。
为了方便快速验证,可以根据模型的输入尺寸,利用 numpy 生成随机伪数据(包括输入图片及标签),并保存为 fake_data.npy 和 fake_label.npy。
将生成的伪数据 (fake_data.npy 和 fake_label.npy),送入 PyTorch 模型获取输出,使用 reprod_log 保存结果。
# 加载 torch 模型及权重 torch_model = mv3_small_torch() torch_model.eval() torch_state_dict = torch.load("./data/mobilenet_v3_small.pth") torch_model.load_state_dict(torch_state_dict) torch_model.to(torch_device) # 加载数据 inputs = np.load("./data/fake_data.npy") # 保存 torch 模型的输出结果 torch_out = torch_model( torch.tensor( inputs, dtype=torch.float32).to(torch_device)) reprod_logger.add("logits", torch_out.cpu().detach().numpy()) reprod_logger.save("./result/forward_ref.npy")
将生成的伪数据 (fake_data.npy 和 fake_label.npy),送入飞桨模型获取输出,使用 reprod_log 保存结果。
# 加载飞桨模型及权重 paddle_model = mv3_small_paddle() paddle_model.eval() paddle_state_dict = paddle.load("./data/mv3_small_paddle.pdparams") paddle_model.set_dict(paddle_state_dict) # 加载数据 inputs = np.load("./data/fake_data.npy") # 保存飞桨模型的输出结果 reprod_logger = ReprodLogger() paddle_out = paddle_model(paddle.to_tensor(inputs, dtype="float32")) reprod_logger.add("logits", paddle_out.cpu().detach().numpy()) reprod_logger.save("./result/forward_paddle.npy")
使用 reprod_log 检查两个 tensor 的 diff,小于阈值则核验通过。
# 分别加载两个模型的输出结果 diff_helper = ReprodDiffHelper() torch_info = diff_helper.load_info("./result/forward_ref.npy") paddle_info = diff_helper.load_info("./result/forward_paddle.npy") # 比较输出结果并生成日志文件 diff_helper.compare_info(torch_info, paddle_info) diff_helper.report( path="./result/log/forward_diff.log", diff_threshold=1e-5)
查看日志文件
result/log/forward_diff.log。INFO: logits: INFO: mean diff: check passed: True, value: 1.7629824924370041e-06 INFO: diff check passed
由于前向算子计算导致的微小的差异,一般而言前向误差在 1e-5 左右的 diff 是可以接受的。通过以上结果,可以判断网络已前向对齐。
下游任务 fine-tuning 验证(可选)
当我们对齐前向精度时,一般来说我们的模型转换就已经成功了。如果转换的是一个分类模型,为了验证模型的泛化能力,我们还可以将训练好的模型在下游任务上 fine-tuning 进行 double check。 同样的,我们需要使用相同的训练数据,设置相同的训练参数,在相同的训练环境下进行 fine-tuning 来对比两者的收敛指标。
FAQ
Q:飞桨已经有了对于经典模型结构的实现,我还要重新实现一遍么?
A:这里建议自己根据 PyTorch 代码重新实现一遍,一方面是对整体的模型结构更加熟悉,另一方面也保证模型结构和权重完全对齐。