python调用opt转化模型¶
安装了paddle-lite 的python库后,可以通过python调用 opt 工具转化模型。(支持MAC&Ubuntu系统)


功能一:转化模型为Paddle-Lite格式¶
opt可以将Paddle原生模型转化为Paddle-Lite 支持的移动端模型:
存储格式转换,有效降低模型体积
执行“量化、子图融合、混合调度、Kernel优选”等优化操作,降低运行耗时与内存消耗
(1) 准备待优化的PaddlePaddle模型
opt 支持下列5种模型格式
用
--model_dir=指定模型文件夹位置
# contents in model directory should be in one of these formats:
(1) __model__ + var1 + var2 + etc.
(2) model + var1 + var2 + etc.
(3) model.pdmodel + model.pdiparams
(4) model + params
(5) model + weights
其他格式:
用
--model_file=指定模型文件位置用
--param_file=指定参数文件位置
eg. model + param
# 加载这种非标准格式时: 需要指定 模型和参数文件 位置
paddle_lite_opt --model_file=./model --param_file=./param
(2) 终端中执行opt命令转化模型
使用示例:转化mobilenet_v1模型
paddle_lite_opt --model_dir=./mobilenet_v1 \
--valid_targets=arm \
--optimize_out=mobilenet_v1_opt
以上命令可将mobilenet_v1转化为arm平台模型,优化后的模型文件是mobilenet_v1_opt.nb:

注意:若转化失败,提示模型格式不正确时
用
--model_file=指定模型文件位置用
--param_file=指定参数文件位置

(3) 更详尽的转化命令总结:
paddle_lite_opt \
--model_dir=<model_param_dir> \
--model_file=<model_path> \
--param_file=<param_path> \
--optimize_out_type=(protobuf|naive_buffer) \
--optimize_out=<output_optimize_model_dir> \
--valid_targets=(arm|opencl|x86|npu|xpu|huawei_ascend_npu|imagination_nna|intel_fpga)\
--enable_fp16=(true|false) \
--quant_model=(true|false) \
--quant_type=(QUANT_INT16|QUANT_INT8)
| 选项 | 说明 |
|---|---|
| --model_dir | 待优化的PaddlePaddle模型(非combined形式)的路径 |
| --model_file | 待优化的PaddlePaddle模型(combined形式)的网络结构文件路径。 |
| --param_file | 待优化的PaddlePaddle模型(combined形式)的权重文件路径。 |
| --optimize_out_type | 输出模型类型,目前支持两种类型:protobuf和naive_buffer,其中naive_buffer是一种更轻量级的序列化/反序列化实现。若您需要在mobile端执行模型预测,请将此选项设置为naive_buffer。默认为protobuf。 |
| --optimize_out | 优化模型的输出路径。 |
| --valid_targets | 指定模型可执行的backend,默认为arm。可以同时指定多个backend(以逗号分隔),opt将会自动选择最佳方式。如果需要支持华为NPU(Kirin 810/990 Soc搭载的达芬奇架构NPU),应当设置为"npu,arm"。 |
| --enable_fp16 | 设置是否使用opt中的Float16 低精度量化功能,Float16量化会提高速度提高、降低内存占用,但预测精度会有降低 |
| --quant_model | 设置是否使用opt中的动态离线量化功能。 |
| --quant_type | 指定opt中动态离线量化功能的量化类型,可以设置为QUANT_INT8和QUANT_INT16,即分别量化为8比特和16比特。 量化为int8对模型精度有一点影响,模型体积大概减小4倍。量化为int16对模型精度基本没有影,模型体积大概减小2倍。 |
如果待优化的fluid模型是非combined形式,请设置
--model_dir,忽略--model_file和--param_file。如果待优化的fluid模型是combined形式,请设置
--model_file和--param_file,忽略--model_dir。naive_buffer的优化后模型为以.nb名称结尾的单个文件。protobuf的优化后模型为文件夹下的model和params两个文件。将model重命名为__model__用Netron打开,即可查看优化后的模型结构。删除
prefer_int8_kernel的输入参数,opt自动判别是否是量化模型,进行相应的优化操作。opt中的动态离线量化功能和PaddleSlim中动态离线量化功能相同,opt提供该功能是为了用户方便使用。
功能二:统计模型算子信息、判断是否支持¶
opt可以统计并打印出model中的算子信息、判断Paddle-Lite是否支持该模型。并可以打印出当前Paddle-Lite的算子支持情况。
(1)使用opt统计模型中算子信息
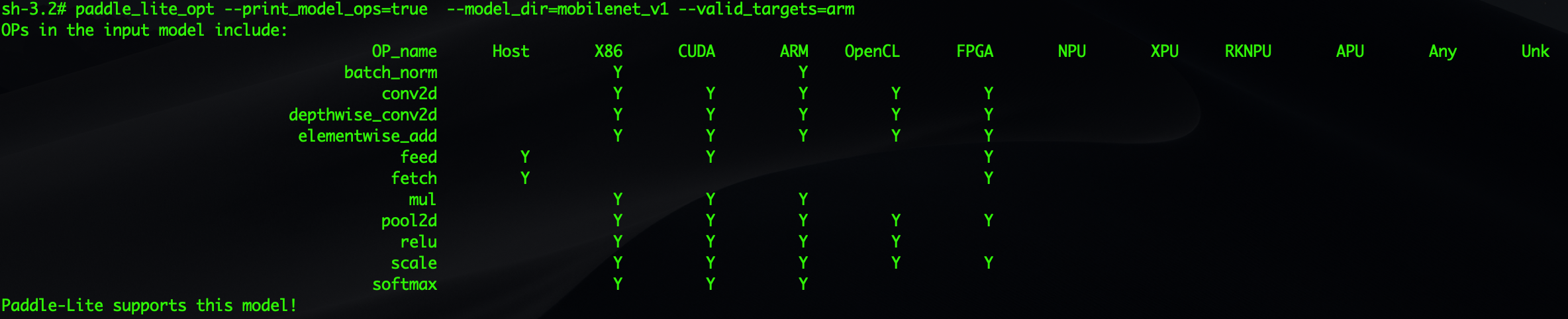
下面命令可以打印出mobilenet_v1模型中包含的所有算子,并判断在硬件平台valid_targets下Paddle-Lite是否支持该模型
paddle_lite_opt --print_model_ops=true --model_dir=mobilenet_v1 --valid_targets=arm
(2)使用opt打印当前Paddle-Lite支持的算子信息
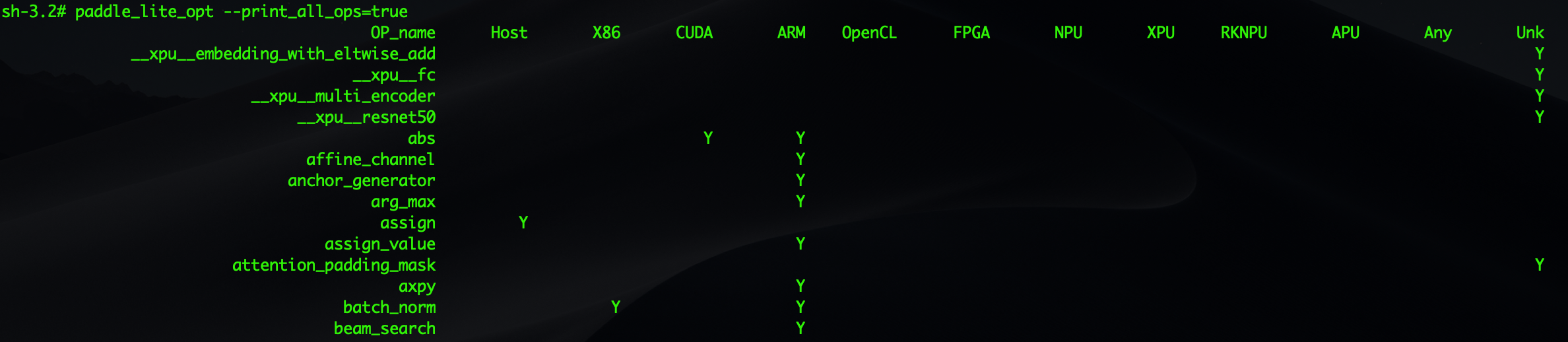
paddle_lite_opt --print_all_ops=true
以上命令可以打印出当前Paddle-Lite支持的所有算子信息,包括OP的数量和每个OP支持哪些硬件平台:

paddle_lite_opt --print_supported_ops=true --valid_targets=x86
以上命令可以打印出当valid_targets=x86时Paddle-Lite支持的所有OP: