
Python 完整示例¶
概述¶
本教程提供了用 Paddle Lite 执行推理的 Python 示例程序,通过输入、执行推理、打印推理结果的方式,演示了基于 Python API 接口的推理基本流程,用户能够快速了解 Paddle Lite 执行推理相关 API 的使用。
本教程以 mobilenetv1_light_api.py 和 mobilenetv1_full_api.py 为案例,介绍 Python API 推理流程,相关代码放置在 lite/demo/python 文件夹中。
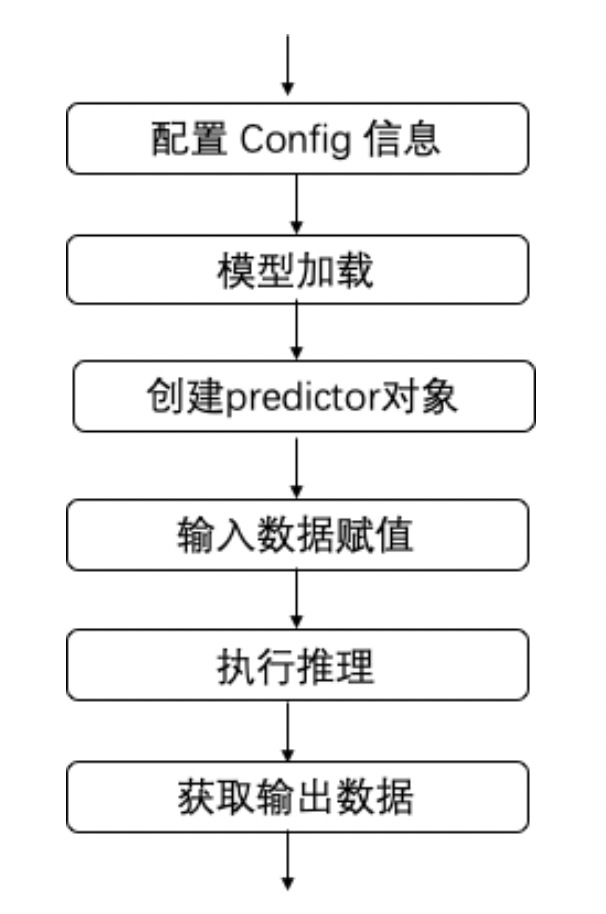
使用 Paddle Lite 执行推理主要包括以下步骤:
创建 config 对象:创建
<class 'paddlelite.lite.MobileConfig'>对象 ,用于配置模型路径、运行设备环境等相关信息模型加载:通过
config.set_model_from_file接口配置模型路径。创建 predictor 对象:通过
create_paddle_predictor接口创建<class 'paddlelite.lite.LightPredictor'>对象,完成模型解析和环境初始化。输入数据:推理之前需要向输入 tensor 中填充数据。即通过
predictor.get_input(num)接口获取第num个输入 tensor , 其类型为·<class 'paddlelite.lite.Tensor'>,调用 tensor 的from_numpy方法给其输入数据。执行推理:使用 predictor 对象的成员函数
run进行模型推理输出数据:推理执行结束后,通过
predictor.get_output(num)接口获取第num个输出 tensor。
其流程图如下:
Python 应用开发说明¶
Python 代码调用 Paddle Lite 执行预测库仅需以下五步:
(1) 引入必要的库
from paddlelite.lite import *
import numpy as np
(2) 指定模型文件,创建 predictor
# 1. Set config information
config = MobileConfig()
# 2. Set the path to the model generated by opt tools
config.set_model_from_file(args.model_dir)
# 3. Create predictor by config
predictor = create_paddle_predictor(config)
(3) 设置模型输入 (下面以全一输入为例)
input_tensor = predictor.get_input(0)
input_tensor.from_numpy(np.ones((1, 3, 224, 224)).astype("float32"))
如果模型有多个输入,每一个模型输入都需要准确设置 shape 和 data。
(4) 执行预测
predictor.run()
(5) 获得预测结果并将预测结果转化为 numpy 数组
output_tensor = predictor.get_output(0)
output_data = output_tensor.numpy()
print(output_data)
详细的 Python API 说明文档位于 Python API 文件夹内。
mobilenetv1_light_api.py 和 mobilenetv1_full_api.py 示例程序¶
Paddle Lite Python 版本支持的平台包括:Windows X86_CPU / macOS X86_CPU / Linux X86_CPU / Linux ARM_CPU (ARM Linux)。
1. 环境准备¶
如果是 Windows X86_CPU / macOS X86_CPU / Linux X86_CPU 平台,不需要进行特定环境准备。
如果是 ARM Linux 平台,需要编译 Paddle Lite ,环境配置参考 文档,推荐使用 docker。
2. 安装python预测库¶
PyPI 源目前仅提供 Windows X86_CPU / macOS X86_CPU / Linux X86_CPU 平台的 pip 安装包,执行如下命令。
# 当前最新版本是 2.10rc
python -m pip install paddlelite==2.10rc0
如果您需要使用 AMRLinux 平台的 Python 预测功能,请参考源码编译 (ARMLinux)编译、安装 Paddle Lite 的 python 包。
3. 准备预测部署模型¶
(1) 模型下载:下载 mobilenet_v1 模型后解压,得到 Paddle 非 combined 形式的模型,位于文件夹 mobilenet_v1 下。可通过模型可视化工具 Netron 打开文件夹下的 __model__ 文件,查看模型结构。
wget http://paddle-inference-dist.bj.bcebos.com/mobilenet_v1.tar.gz
tar zxf mobilenet_v1.tar.gz
(2) 模型转换:Paddle 原生模型需经 opt 工具转化为 Paddle Lite 可以支持的 naive_buffer 格式。
Linux X86_CPU 平台:通过 pip 安装 Paddle Lite 的同时就已获得
paddle_lite_opt可执行文件。
paddle_lite_opt --model_dir=./mobilenet_v1 \
--optimize_out=mobilenet_v1_opt \
--optimize_out_type=naive_buffer \
--valid_targets=x86
MAC X86_CPU 平台:
paddle_lite_opt工具使用方式同 Linux。Windows X86_CPU 平台:暂不支持命令行方式直接运行模型转换器,需编写 python 脚本
import paddlelite.lite as lite
a=lite.Opt()
# 非 combined 形式
a.set_model_dir("D:\\YOU_MODEL_PATH\\mobilenet_v1")
# conmbined 形式,具体模型和参数名称,请根据实际修改
# a.set_model_file("D:\\YOU_MODEL_PATH\\mobilenet_v1\\__model__")
# a.set_param_file("D:\\YOU_MODEL_PATH\\mobilenet_v1\\__params__")
a.set_optimize_out("mobilenet_v1_opt")
a.set_valid_places("x86")
a.run()
ARMLinux 平台:编写 python 脚本转换模型
import paddlelite.lite as lite
a=lite.Opt()
# 非 combined 形式
a.set_model_dir("D:\\YOU_MODEL_PATH\\mobilenet_v1")
# conmbined 形式,具体模型和参数名称,请根据实际修改
# a.set_model_file("D:\\YOU_MODEL_PATH\\mobilenet_v1\\__model__")
# a.set_param_file("D:\\YOU_MODEL_PATH\\mobilenet_v1\\__params__")
a.set_optimize_out("mobilenet_v1_opt")
a.set_valid_places("x86") # 设置为 x86
a.run()
以上命令执行成功之后将在同级目录生成名为 mobilenet_v1_opt.nb 的优化后模型文件。
4. 下载和运行预测示例程序¶
从 demo/python 下载预测示例文件 mobilenetv1_light_api.py 和 mobilenetv1_full_api.py,并运行此程序。
# light api 的输入为优化后模型文件 mobilenet_v1_opt.nb
python mobilenetv1_light_api.py --model_dir=mobilenet_v1_opt.nb
# 运行成功后,将在控制台输出类似如下内容
[[1.91309489e-04 5.92054741e-04 1.12302143e-04 6.27333211e-05
1.27506457e-04 1.32147770e-03 3.13812016e-05 6.52206727e-05
4.78084912e-05 2.58819520e-04 1.53155532e-03 1.12548303e-04
...
...
]]
# full api 的输入为未使用 paddle_lite_opt 工具优化前的模型文件夹 mobilenet_v1
python mobilenetv1_full_api.py --model_dir=./mobilenet_v1
# 运行成功后,将在控制台输出类似如下内容
Loading topology data from ./mobilenet_v1/__model__
Loading non-combined params data from ./mobilenet_v1
1. Model is successfully loaded!
[[1.91309489e-04 5.92054741e-04 1.12302143e-04 6.27333211e-05
1.27506457e-04 1.32147770e-03 3.13812016e-05 6.52206727e-05
...
...
]]