
华为麒麟 NPU 部署示例¶
Paddle Lite 是首款支持华为自研达芬奇架构 NPU(Kirin 810/990 SoC 搭载的 NPU)的预测框架。 原理是在线分析 Paddle 模型,首先将 Paddle 算子转成 NNAdapter 标准算子,其次再转换为 HiAI IR,最后调用HiAI IR/Builder/Runtime APIs 生成并执行 HiAI 模型。
支持现状¶
已支持的芯片¶
Kirin 810/820/985/990/990 5G/9000E/9000
已支持的设备¶
Kirin 9000:HUAWEI Mate 40pro 系列
Kirin 9000E:HUAWEI Mate 40 系列
Kirin 990 5G:HUAWEI Mate 30pro 系列,P40pro 系列
Kirin 990:HUAWEI Mate 30 系列,荣耀 V20 系列,nova 6 系列,P40 系列,Mate Xs
Kirin 985:HUAWEI nova 7 5G,nova 7 Pro 5G,荣耀 30
Kirin 820:HUAWEI nova 7 SE 5G,荣耀 30S
Kirin 810:HUAWEI nova 5 系列,nova 6 SE,荣耀 9X 系列,荣耀 Play4T Pro
已支持的 Paddle 模型¶
性能¶
测试环境
编译环境
Ubuntu 16.04,NDK-r17c with GCC for Android arm64-v8a
HIAI DDK 版本:v510
硬件环境
Kirin 810
HUAWEI Nova 5,Kirin 810
CPU:2 x Cortex A76 2.27GHz + 6 x Cortex A55 1.88GHz
NPU:Da Vinci 架构,1 x Ascend D100 Lite
Kirin 990
HUAWEI Mate 30,Kirin 990
CPU:2 x Cortex-A76 Based 2.86 GHz + 2 x Cortex-A76 Based 2.09 GHz + 4 x Cortex-A55 1.86 GHz
NPU:Da Vinci 架构,1 x Ascend Lite + 1 x Ascend Tiny
Kirin 990 5G
HUAWEI P40pro,Kirin 990 5G
CPU:2 x Cortex-A76 Based 2.86GHz + 2 x Cortex-A76 Based 2.36GHz + 4 x Cortex-A55 1.95GHz
NPU:Da Vinci 架构,2 x Ascend Lite + 1 x Ascend Tiny
测试方法
warmup=1, repeats=5,统计平均时间,单位是 ms
线程数为1,
paddle::lite_api::PowerMode CPU_POWER_MODE设置为paddle::lite_api::PowerMode::LITE_POWER_HIGH分类模型的输入图像维度是{1, 3, 224, 224},检测模型的维度是{1, 3, 300, 300}
测试结果
| 模型 | Kirin 810 | Kirin 990 | Kirin 990 5G | |||
|---|---|---|---|---|---|---|
| CPU(ms) | NPU(ms) | CPU(ms) | NPU(ms) | CPU(ms) | NPU(ms) | |
| mobilenet_v1_fp32_224 | 38.358801 | 5.903400 | 30.234800 | 3.352000 | 31.567600 | 2.992200 |
| resnet50_fp32_224 | 224.719998 | 18.087400 | 176.660199 | 9.825800 | 186.572998 | 7.645400 |
| ssd_mobilenet_v1_relu_voc_fp32_300 | 80.059001 | 30.157600 | 63.044600 | 22.901200 | 68.458200 | 21.399200 |
已支持(或部分支持)NNAdapter 的 Paddle 算子¶
您可以查阅 NNAdapter 算子支持列表获得各算子在不同新硬件上的最新支持信息。
不经过 NNAdapter 标准算子转换,而是直接将 Paddle 算子转换成 HiAI IR 的方案可点击链接。
参考示例演示¶
测试设备(HUAWEI Mate30 5G)¶

运行图像分类示例程序¶
下载 Paddle Lite 通用示例程序 PaddleLite-generic-demo.tar.gz ,解压后目录主体结构如下:
- PaddleLite-generic-demo - image_classification_demo - assets - images - tabby_cat.jpg # 测试图片 - tabby_cat.raw # 经过 convert_to_raw_image.py 处理后的 RGB Raw 图像 - labels - synset_words.txt # 1000 分类 label 文件 - models - mobilenet_v1_fp32_224 # Paddle non-combined 格式的 mobilenet_v1 float32 模型 - __model__ # Paddle fluid 模型组网文件,可使用 netron 查看网络结构 - conv1_bn_mean # Paddle fluid 模型参数文件 - subgraph_partition_config_file.txt # 自定义子图分割配置文件 ... - shell - CMakeLists.txt # 示例程序 CMake 脚本 - build.android.arm64-v8a # arm64-v8a 编译工作目录 - image_classification_demo # 已编译好的,适用于 amd64-v8a 的示例程序 - build.android.armeabi-v7a # armeabi-v7a 编译工作目录 - image_classification_demo # 已编译好的,适用于 arm64 的示例程序 ... ... - image_classification_demo.cc # 示例程序源码 - build.sh # 示例程序编译脚本 - run_with_adb.sh # 示例程序 adb 运行脚本 - libs - PaddleLite - android - arm64-v8a - include # Paddle Lite 头文件 - lib - huawei_kirin_npu # 华为麒麟 NPU HiAI DDK、NNAdapter 运行时库、device HAL 库 - libnnadapter.so # NNAdapter 运行时库 - libhuawei_kirin_npu.so # NNAdapter device HAL 库 - libhiai.so # HiAI DDK ... - libpaddle_full_api_shared.so # 预编译 Paddle Lite full api 库 - libpaddle_light_api_shared.so # 预编译 Paddle Lite light api 库 - libc++_shared.so - armeabi-v7a - include - lib ... - OpenCV # OpenCV 预编译库 - ssd_detection_demo # 基于 ssd 的目标检测示例程序Android shell 端的示例程序
按照以下命令分别运行转换后的 ARM CPU 模型和华为 Kirin NPU 模型,比较它们的性能和结果;
1)由于 HiAI 的限制,需要 root 权限才能执行 shell 示例程序。 2)`run_with_adb.sh` 只能在连接设备的系统上运行,不能在 Docker 环境执行(可能无法找到设备),也不能在设备上运行。 3)`build.sh` 需要在 Docker 环境中执行,否则,需要将 `build.sh` 的 ANDROID_NDK 修改为当前环境下的 NDK 路径。 4)`build.sh` 根据入参生成针对不同操作系统、体系结构的二进制程序,需查阅注释信息配置正确的参数值。 5)`run_with_adb.sh` 入参包括模型名称、操作系统、体系结构、目标设备、设备序列号等,需查阅注释信息配置正确的参数值。 6)对于需要使能自定义子图分割文件的模型,请注意将 `run_with_adb.sh` 中 line12 行首 '#' 删除。 运行适用于 ARM CPU 的 mobilenetv1 模型 $ cd PaddleLite-generic-demo/image_classification_demo/shell $ ./run_with_adb.sh mobilenet_v1_fp32_224 android arm64-v8a ... iter 0 cost: 30.349001 ms iter 1 cost: 30.517000 ms iter 2 cost: 30.040001 ms iter 3 cost: 30.358000 ms iter 4 cost: 30.187000 ms warmup: 1 repeat: 5, average: 30.290200 ms, max: 30.517000 ms, min: 30.040001 ms results: 3 Top0 tabby, tabby cat - 0.529131 Top1 Egyptian cat - 0.419681 Top2 tiger cat - 0.045173 Preprocess time: 0.576000 ms Prediction time: 30.290200 ms Postprocess time: 0.100000 ms 运行适用于华为 Kirin NPU 的 mobilenetv1 模型 $ cd PaddleLite-generic-demo/image_classification_demo/shell $ ./run_with_adb.sh mobilenet_v1_fp32_224 android arm64-v8a huawei_kirin_npu ... iter 0 cost: 3.503000 ms iter 1 cost: 3.406000 ms iter 2 cost: 3.401000 ms iter 3 cost: 3.402000 ms iter 4 cost: 3.423000 ms warmup: 1 repeat: 5, average: 3.427000 ms, max: 3.503000 ms, min: 3.401000 ms results: 3 Top0 tabby, tabby cat - 0.534180 Top1 Egyptian cat - 0.416016 Top2 tiger cat - 0.044525 Preprocess time: 0.572000 ms Prediction time: 3.427000 ms Postprocess time: 0.099000 ms
如果需要更改测试图片,可将图片拷贝到
PaddleLite-generic-demo/image_classification_demo/assets/images目录下,然后调用convert_to_raw_image.py生成相应的 RGB Raw 图像,最后修改run_with_adb.sh的 IMAGE_NAME 变量即可;重新编译示例程序:
注意: 1)请根据 `buid.sh` 配置正确的参数值。 2)需在 `Docker` 环境中编译。 # 对于 arm64-v8a ./build.sh android arm64-v8a # 对于 armeabi-v7a ./build.sh android armeabi-v7a
注意:opt 生成的模型只是标记了华为 Kirin NPU 支持的 Paddle 算子,并没有真正生成华为 Kirin NPU 模型,只有在执行时才会将标记的 Paddle 算子转成
HiAI IR并组网得到HiAI IRGraph,然后生成并执行华为 Kirin NPU 模型(具体原理请参考 Pull Request#2576);不同模型,不同型号(ROM 版本)的华为手机,在执行阶段,由于某些 Paddle 算子无法完全转成
HiAI IR,或目标手机的 HiAI 版本过低等原因,可能导致 HiAI 模型无法成功生成,在这种情况下,Paddle Lite 会调用 ARM CPU 版算子进行运算完成整个预测任务。
更新支持华为 Kirin NPU 的 Paddle Lite 库¶
下载 Paddle Lite 源码和最新版 HiAI DDK
$ git clone https://github.com/PaddlePaddle/Paddle-Lite.git $ cd Paddle-Lite $ git checkout <release-version-tag> $ wget https://paddlelite-demo.bj.bcebos.com/devices/huawei/kirin/hiai_ddk_lib_510.tar.gz $ tar -xvf hiai_ddk_lib_510.tar.gz编译并生成
PaddleLite+NNAdapter+HuaweiKirinNPUfor armv8 and armv7 的部署库For armv8
tiny_publish 编译
$ ./lite/tools/build_android.sh --toolchain=clang --android_stl=c++_shared --with_extra=ON --with_log=ON --with_nnadapter=ON --nnadapter_with_huawei_kirin_npu=ON --nnadapter_huawei_kirin_npu_sdk_root=$(pwd)/hiai_ddk_lib_510
full_publish 编译
$ ./lite/tools/build_android.sh --toolchain=clang --android_stl=c++_shared --with_extra=ON --with_log=ON --with_nnadapter=ON --nnadapter_with_huawei_kirin_npu=ON --nnadapter_huawei_kirin_npu_sdk_root=$(pwd)/hiai_ddk_lib_510 full_publish
替换头文件和库
# 替换 include 目录 $ cp -rf build.lite.android.armv8.clang/inference_lite_lib.android.armv8.nnadapter/cxx/include/ PaddleLite-generic-demo/libs/PaddleLite/android/arm64-v8a/include/ # 替换 NNAdapter 运行时库 $ cp -rf build.lite.android.armv8.clang/inference_lite_lib.android.armv8.nnadapter/cxx/lib/libnnadapter.so PaddleLite-generic-demo/libs/PaddleLite/android/arm64-v8a/lib/huawei_kirin_npu/ # 替换 NNAdapter device HAL 库 $ cp -rf build.lite.android.armv8.clang/inference_lite_lib.android.armv8.nnadapter/cxx/lib/libhuawei_kirin_npu.so PaddleLite-generic-demo/libs/PaddleLite/android/arm64-v8a/lib/huawei_kirin_npu/ # 替换 libpaddle_light_api_shared.so $ cp -rf build.lite.android.armv8.clang/inference_lite_lib.android.armv8.nnadapter/cxx/lib/libpaddle_light_api_shared.so PaddleLite-generic-demo/libs/PaddleLite/android/arm64-v8a/lib/ # 替换 libpaddle_full_api_shared.so (仅在 full_publish 编译方式下) $ cp -rf build.lite.android.armv8.clang/inference_lite_lib.android.armv8.nnadapter/cxx/lib/libpaddle_full_api_shared.so PaddleLite-generic-demo/libs/PaddleLite/android/arm64-v8a/lib/
For armv7
tiny_publish 编译
$ ./lite/tools/build_android.sh --arch=armv7 --toolchain=clang --android_stl=c++_shared --with_extra=ON --with_log=ON --with_nnadapter=ON --nnadapter_with_huawei_kirin_npu=ON --nnadapter_huawei_kirin_npu_sdk_root=$(pwd)/hiai_ddk_lib_510
full_publish 编译
$ ./lite/tools/build_android.sh --arch=armv7 --toolchain=clang --android_stl=c++_shared --with_extra=ON --with_log=ON --with_nnadapter=ON --nnadapter_with_huawei_kirin_npu=ON --nnadapter_huawei_kirin_npu_sdk_root=$(pwd)/hiai_ddk_lib_510 full_publish
替换头文件和库
# 替换 include 目录 $ cp -rf build.lite.android.armv7.clang/inference_lite_lib.android.armv7.nnadapter/cxx/include/ PaddleLite-generic-demo/libs/PaddleLite/android/armeabi-v7a/include/ # 替换 NNAdapter 运行时库 $ cp -rf build.lite.android.armv7.clang/inference_lite_lib.android.armv7.nnadapter/cxx/lib/libnnadapter.so PaddleLite-generic-demo/libs/PaddleLite/android/armeabi-v7a/lib/huawei_kirin_npu/ # 替换 NNAdapter device HAL 库 $ cp -rf build.lite.android.armv7.clang/inference_lite_lib.android.armv7.nnadapter/cxx/lib/libhuawei_kirin_npu.so PaddleLite-generic-demo/libs/PaddleLite/android/armeabi-v7a/lib/huawei_kirin_npu/ # 替换 libpaddle_light_api_shared.so $ cp -rf build.lite.android.armv7.clang/inference_lite_lib.android.armv7.nnadapter/cxx/lib/libpaddle_light_api_shared.so PaddleLite-generic-demo/libs/PaddleLite/android/armeabi-v7a/lib/ # 替换 libpaddle_full_api_shared.so (仅在 full_publish 编译方式下) $ cp -rf build.lite.android.armv7.clang/inference_lite_lib.android.armv7.nnadapter/cxx/lib/libpaddle_full_api_shared.so PaddleLite-generic-demo/libs/PaddleLite/android/armeabi-v7a/lib/
备注:由于 HiAI DDK 的 so 库均基于
c++_shared构建,建议将 android stl 设置为c++_shared,更多选项还可以通过./lite/tools/build_android.sh help查看。
替换头文件后需要重新编译示例程序
Paddle Lite 是如何支持华为 Kirin NPU的?¶
Paddle Lite 是如何加载 Paddle 模型并执行一次推理的?
如下图左半部分所示,Paddle 模型的读取和执行,经历了 Paddle 推理模型文件的加载和解析、计算图的转化、图分析和优化、运行时程序的生成和执行等步骤:
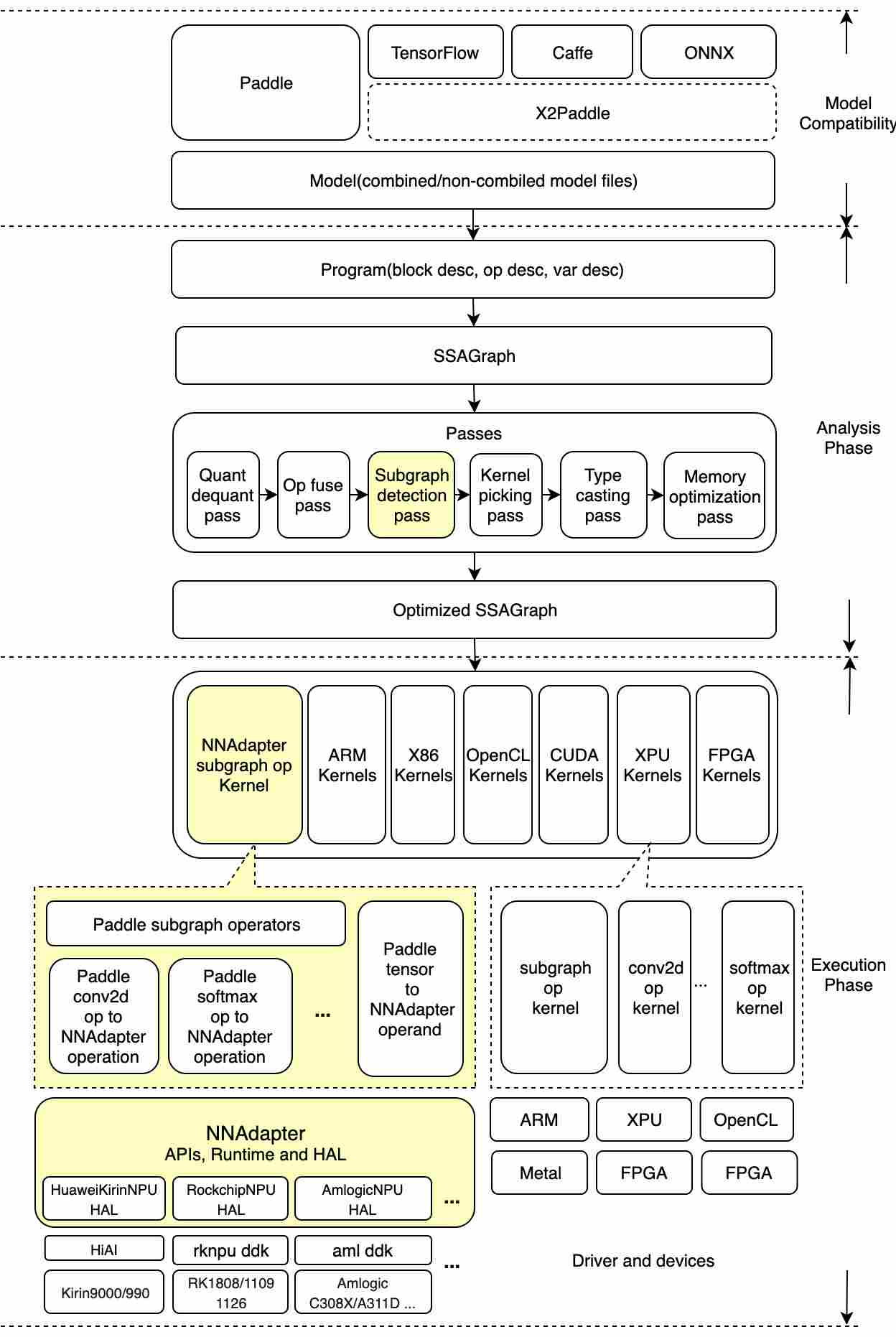
Paddle 推理模型文件的加载和解析:基于 ProtoBuf 协议对 Paddle 推理模型文件进行反序列化,解析生成网络结构(描述算子和张量的关系)和参数信息(包括算子属性和权重张量);
计算图的转化:为了更好的描述网络拓扑结构和方便后续的优化,依据算子的输入、出张量关系,构建一个由算子节点、张量节点组成的有向无环图;
图分析和优化:由一些列 pass(优化器)组成,pass 是用于描述一个计算图优化生成另一个计算图的过程;例如
conv2d_bn_fuse_pass,它用于将模型中每一个conv2d、batch_norm相连的算子对融合成一个conv2d算子以便获得性能上的提升;运行时程序的生成和执行:按照拓扑顺序遍历最终优化后的计算图,生成算子 kernel 列表,依次执行每一个算子 kernel 后即完成一次模型的推理。
Paddle Lite 是如何支持华为 NPU 呢?
为了支持华为 Kirin NPU,我们额外增加了(如上图标黄的区域):NNAdapter subgraph detection pass、NNAdapter subgraph op kernel 和 Paddle2NNAdapter converters。其中 NNAdapter subgraph detection pass 是后续自定义子图划分涉及的关键步骤;
NNAdapter subgraph detection pass:该 pass 的作用是遍历计算图中所有的算子节点,标记能够转成 NNAdapter+HiAI 算子的节点,然后通过图分割算法,将那些支持转为
HiAI IR的、相邻的算子节点融合成一个subgraph(子图)算子节点(需要注意的是,这个阶段算子节点并没有真正转为HiAI IR,更没有生成HiAI模型);NNAdapter subgraph op kernel:根据 NNAdapter subgraph detection pass 的分割结果,在生成的算子 kernel 列表中,可能存在多个 subgraph 算子 kernel ;每个 subgraph 算子 kernel,都会将它所包裹的、能够转成 NNAdapter+HiAI 算子的 Paddle 算子,如上图右半部所示,依次调用对应的 converter,组网生成一个 NNAdapter+HiAI model,最终,调用 HiAI Runtime APIs 生成并执行华为 Kirin NPU 模型;
Paddle2NNAdapter converters:Paddle 算子/张量转 NNAdapter+HiAI 算子的桥接器,其目的是将 Paddle 算子、输入、输出张量最终转为 HiAI 组网 IR 和常量张量。
编写配置文件完成自定义子图分割,生成华为 Kirin NPU 与 ARM CPU 的异构模型¶
为什么需要进行手动子图划分?如果模型中存在不支持转 HiAI IR 的算子,NNAdapter subgraph detection pass 会在没有人工干预的情况下,可能将计算图分割为许多小的子图,而出现如下问题:
过多的子图会产生频繁的
CPU<->NPU数据传输和 NPU 任务调度,影响整体性能;由于华为 Kirin NPU 模型暂时不支持 dynamic shape,因此,如果模型中存在输入和输出不定长的算子(例如一些检测类算子,NLP 类算子),在模型推理过程中,可能会因输入、输出 shape 变化而不断生成 HiAI 模型,从而导致性能变差,更有可能使得 HiAI 模型生成失败。
Kirin NPU HiAI 内部存在少量 Bug,会导致 HiAI 模型生成失败或者错误的子图融合,最终导致模型推理失败或错误。
实现原理
NNAdapter subgraph detection pass 在执行分割任务前,通过读取指定配置文件的方式获得禁用华为 Kirin NPU 的算子列表,实现人为干预分割结果的目的。
具体步骤(以 ssd_mobilenet_v1_relu_voc_fp32_300 目标检测示例程序为例)
步骤1:查看 ssd_mobilenet_v1_relu_voc_fp32_300 的模型结构,具体是将 PaddleLite-generic-demo/ssd_detection_demo/assets/models/ssd_mobilenet_v1_relu_voc_fp32_300 目录下的
__model__拖入 Netron 页面即得到如下图所示的网络结构(部分):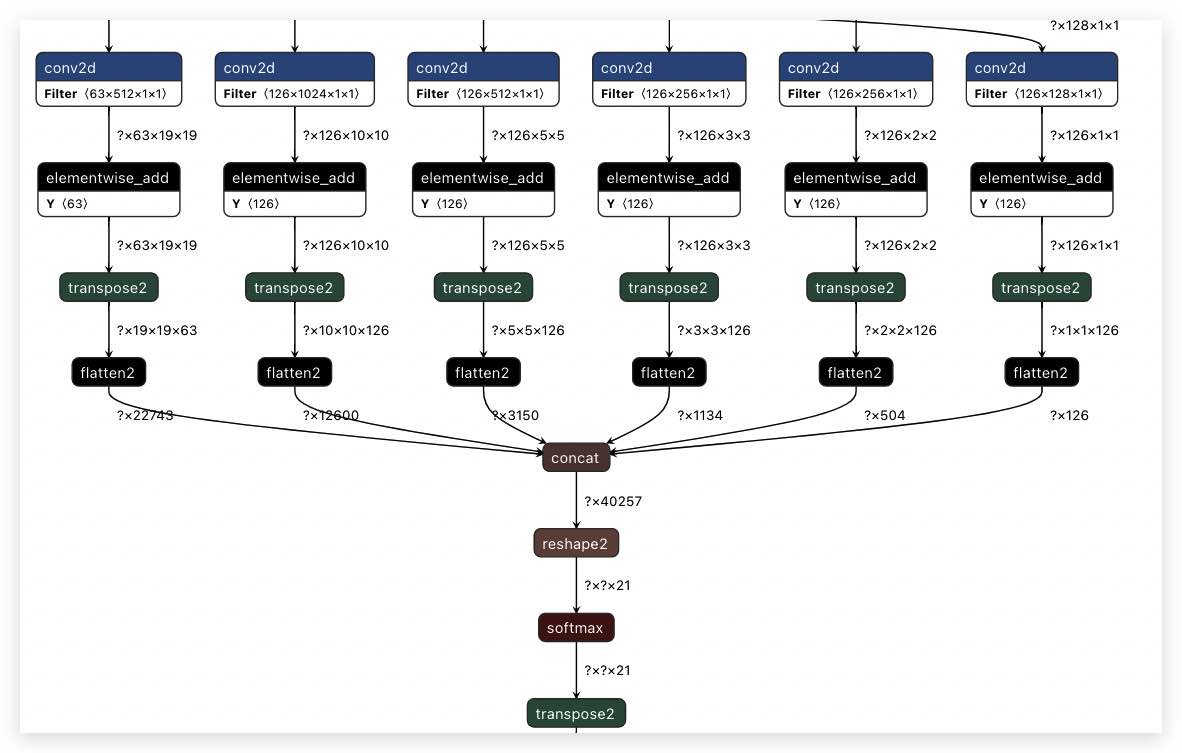
步骤2:由于 Kirin HiAI 内部进行了错误的子图融合,本例中将强制设置两个
transpose2算子运行在 ARM CPU 上。注意: 1. 在 `run_with_adb.sh` 可看到'#SUBGRAPH_PARTITION_CONFIG_FILE=subgraph_partition_config_file.txt', 删除 '#' 即可使能自定义子图分割配置文件。 2. demo 中已经包含了类似 opt 工具优化生成 nb 模型的功能。 # 如果不使用自定义子图分割配置文件,Kirin NPU 将得出错误的预测结果 $ cd PaddleLite-generic-demo/ssd_detection_demo/shell $ ./run_with_adb.sh ssd_mobilenet_v1_relu_voc_fp32_300 android arm64-v8a huawei_kirin_npu ... iter 0 cost: 14.114000 ms iter 1 cost: 14.051000 ms iter 2 cost: 13.990000 ms iter 3 cost: 16.572001 ms iter 4 cost: 16.872000 ms warmup: 1 repeat: 5, average: 15.119800 ms, max: 16.872000 ms, min: 13.990000 ms results: 200 ... [110] aeroplane - 1.000000 0.806027,0.228254,0.987190,0.485760 [111] aeroplane - 1.000000 0.881030,0.244493,1.077540,0.411632 [112] bicycle - 1.000000 -0.062173,-0.070797,0.224258,0.255616 ... [198] bicycle - 1.000000 0.656274,0.198462,0.854739,0.389812 [199] bicycle - 1.000000 0.704027,0.133047,0.802967,0.346298 Preprocess time: 1.038000 ms Prediction time: 15.119800 ms Postprocess time: 0.127000 ms -------------------------------------------------------------------- # 如果使用自定义子图分割配置文件,Kirin NPU 将得出正确的预测结果 $ cd PaddleLite-generic-demo/ssd_detection_demo/shell $ vim run_with_adb.sh 将'#SUBGRAPH_PARTITION_CONFIG_FILE=subgraph_partition_config_file.txt'行首'#'删除 $ ./run_with_adb.sh ssd_mobilenet_v1_relu_voc_fp32_300 android arm64-v8a huawei_kirin_npu ... iter 0 cost: 23.389999 ms iter 1 cost: 23.167999 ms iter 2 cost: 23.010000 ms iter 3 cost: 23.030001 ms iter 4 cost: 23.152000 ms warmup: 1 repeat: 5, average: 23.150000 ms, max: 23.389999 ms, min: 23.010000 ms results: 3 [0] bicycle - 0.998047 0.149730,0.234041,0.731353,0.802842 [1] car - 0.947266 0.600478,0.132399,0.900813,0.300571 [2] dog - 0.991211 0.166347,0.257502,0.434295,0.923455 Preprocess time: 1.078000 ms Prediction time: 23.150000 ms Postprocess time: 0.007000 ms
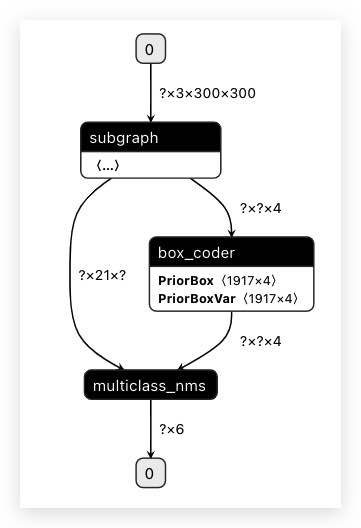
步骤3:如果直接使用 opt 工具生成华为 Kirin NPU 模型,会发现整个网络被分割成 1 个子图(即 1 个 subgraph op),它们都将运行在华为 Kirin NPU 上;
注意: 1)opt 工具日志中包含各个算子的详细信息。 2)为了方便查看优化后的模型,opt 命令将 `optimize_out_type` 参数设置为 protobuf,执行成功后将opt_model 目录下的 `model` 文件复制为 `__model__` 并拖入 Netron 页面进行可视化。 $ cd PaddleLite-generic-demo/ssd_detection_demo/assets/models $ GLOG_v=5 ./opt --model_dir=./ssd_mobilenet_v1_relu_voc_fp32_300 \ --optimize_out_type=protobuf \ --optimize_out=opt_model \ --valid_targets=huawei_kirin_npu,arm Loading topology data from ./ssd_mobilenet_v1_relu_voc_fp32_300/__model__ Loading non-combined params data from ./ssd_mobilenet_v1_relu_voc_fp32_300 1. Model is successfully loaded! subgraph clusters: 1 digraph G { node_1150[label="batch_norm_0.tmp_3"] node_1154[label="batch_norm_1.tmp_3"] node_1190[label="batch_norm_10.tmp_3"] node_1194[label="batch_norm_11.tmp_3"] ... node_1426->node_1427 node_1427->node_1428 node_1428->node_1429 } // end G subgraph operators: feed:feed:image conv2d:image,conv1_weights,conv1_bn_offset:batch_norm_0.tmp_3 depthwise_conv2d:batch_norm_0.tmp_3,conv2_1_dw_weights,conv2_1_dw_bn_offset:batch_norm_1.tmp_3 conv2d:batch_norm_1.tmp_3,conv2_1_sep_weights,conv2_1_sep_bn_offset:batch_norm_2.tmp_3 ... box_coder:concat_0.tmp_0,concat_1.tmp_0,reshape2_0.tmp_0:box_coder_0.tmp_0 multiclass_nms:box_coder_0.tmp_0,transpose_12.tmp_0:save_infer_model/scale_0.tmp_0 fetch:save_infer_model/scale_0.tmp_0:fetch
步骤4:为了获得正确的推理结果,我们需强制设置两个
transpose2算子运行在 ARM CPU 上。那么,我们就需要通过环境变量SUBGRAPH_CUSTOM_PARTITION_CONFIG_FILE设置『自定义子图分割配置文件』,实现人为干预分割结果;$ cd PaddleLite-generic-demo/ssd_detection_demo/assets/models $ cat ./ssd_mobilenet_v1_relu_voc_fp32_300/subgraph_custom_partition_config_file.txt transpose2:conv2d_22.tmp_1:transpose_0.tmp_0,transpose_0.tmp_1 transpose2:conv2d_23.tmp_1:transpose_1.tmp_0,transpose_1.tmp_1 $ export SUBGRAPH_CUSTOM_PARTITION_CONFIG_FILE=./ssd_mobilenet_v1_relu_voc_fp32_300/subgraph_partition_config_file.txt $ GLOG_v=5 ./opt --model_dir=./ssd_mobilenet_v1_relu_voc_fp32_300 \ --optimize_out_type=protobuf \ --optimize_out=opt_model \ --valid_targets=huawei_kirin_npu,arm ... [4 8/30 14:31:50.298 ...ite/lite/core/optimizer/mir/ssa_graph.cc:27 CheckBidirectionalConnection] node count 226 [4 8/30 14:31:50.299 ...e/optimizer/mir/generate_program_pass.cc:46 Apply] Statement feed host/any/any [4 8/30 14:31:50.299 ...e/optimizer/mir/generate_program_pass.cc:46 Apply] Statement subgraph nnadapter/any/NCHW [4 8/30 14:31:50.299 ...e/optimizer/mir/generate_program_pass.cc:46 Apply] Statement transpose2 arm/any/NCHW [4 8/30 14:31:50.299 ...e/optimizer/mir/generate_program_pass.cc:46 Apply] Statement subgraph nnadapter/any/NCHW [4 8/30 14:31:50.299 ...e/optimizer/mir/generate_program_pass.cc:46 Apply] Statement transpose2 arm/any/NCHW [4 8/30 14:31:50.299 ...e/optimizer/mir/generate_program_pass.cc:46 Apply] Statement subgraph nnadapter/any/NCHW [4 8/30 14:31:50.299 ...e/optimizer/mir/generate_program_pass.cc:46 Apply] Statement box_coder arm/float/NCHW [4 8/30 14:31:50.299 ...e/optimizer/mir/generate_program_pass.cc:46 Apply] Statement multiclass_nms host/float/NCHW [4 8/30 14:31:50.299 ...e/optimizer/mir/generate_program_pass.cc:46 Apply] Statement fetch host/any/any [1 8/30 14:31:50.299 ...re/optimizer/mir/generate_program_pass.h:41 GenProgram] insts.size: 1 [4 8/30 14:31:50.346 ...e-Lite/lite/model_parser/model_parser.cc:307 SaveModelPb] Save protobuf model in 'opt_model'' successfully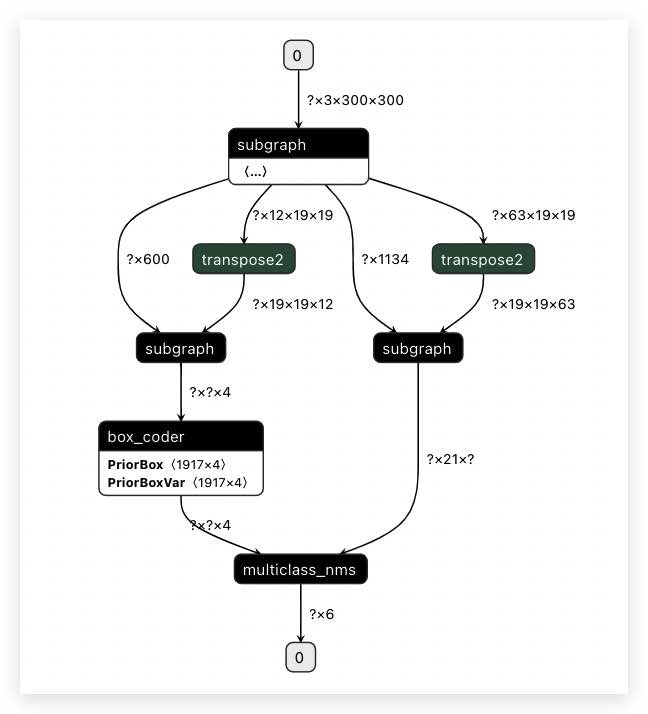
步骤5:上述步骤中,
PaddleLite-generic-demo/ssd_detection_demo/assets/models/ssd_mobilenet_v1_relu_voc_fp32_300/subgraph_partition_config_file.txt是示例自带的『自定义子图分割配置文件』,它的格式是什么样的呢?每行记录由『算子类型:输入张量名列表:输出张量名列表』组成(即以分号分隔算子类型、输入和输出张量名列表),以逗号分隔输入、输出张量名列表中的每个张量名;
可省略输入、输出张量名列表中的部分张量名(如果不设置任何输入、输出张量列表,则代表计算图中该类型的所有算子节点均被强制运行在 ARM CPU 上);
示例说明:
op_type0:var_name0,var_name1:var_name2 表示将算子类型为 op_type0、输入张量为var_name0 和 var_name1、输出张量为 var_name2 的节点强制运行在 ARM CPU 上 op_type1::var_name3 表示将算子类型为 op_type1、任意输入张量、输出张量为 var_name3 的节点强制运行在 ARM CPU 上 op_type2:var_name4 表示将算子类型为 op_type2、输入张量为 var_name4、任意输出张量的节点强制运行在 ARM CPU 上 op_type3 表示任意算子类型为 op_type3 的节点均被强制运行在 ARM CPU 上
步骤6:对于 ssd_mobilenet_v1_relu_voc_fp32_300 的模型,我们如何得到
PaddleLite-generic-demo/ssd_detection_demo/assets/models/ssd_mobilenet_v1_relu_voc_fp32_300/subgraph_partition_config_file.txt的配置呢?重新在 Netron 打开 PaddleLite-generic-demo/ssd_detection_demo/assets/models/ssd_mobilenet_v1_relu_voc_fp32_300 模型,以其中一个
transpose2节点为例,点击改节点即可在右侧看到输入、输出张量信息: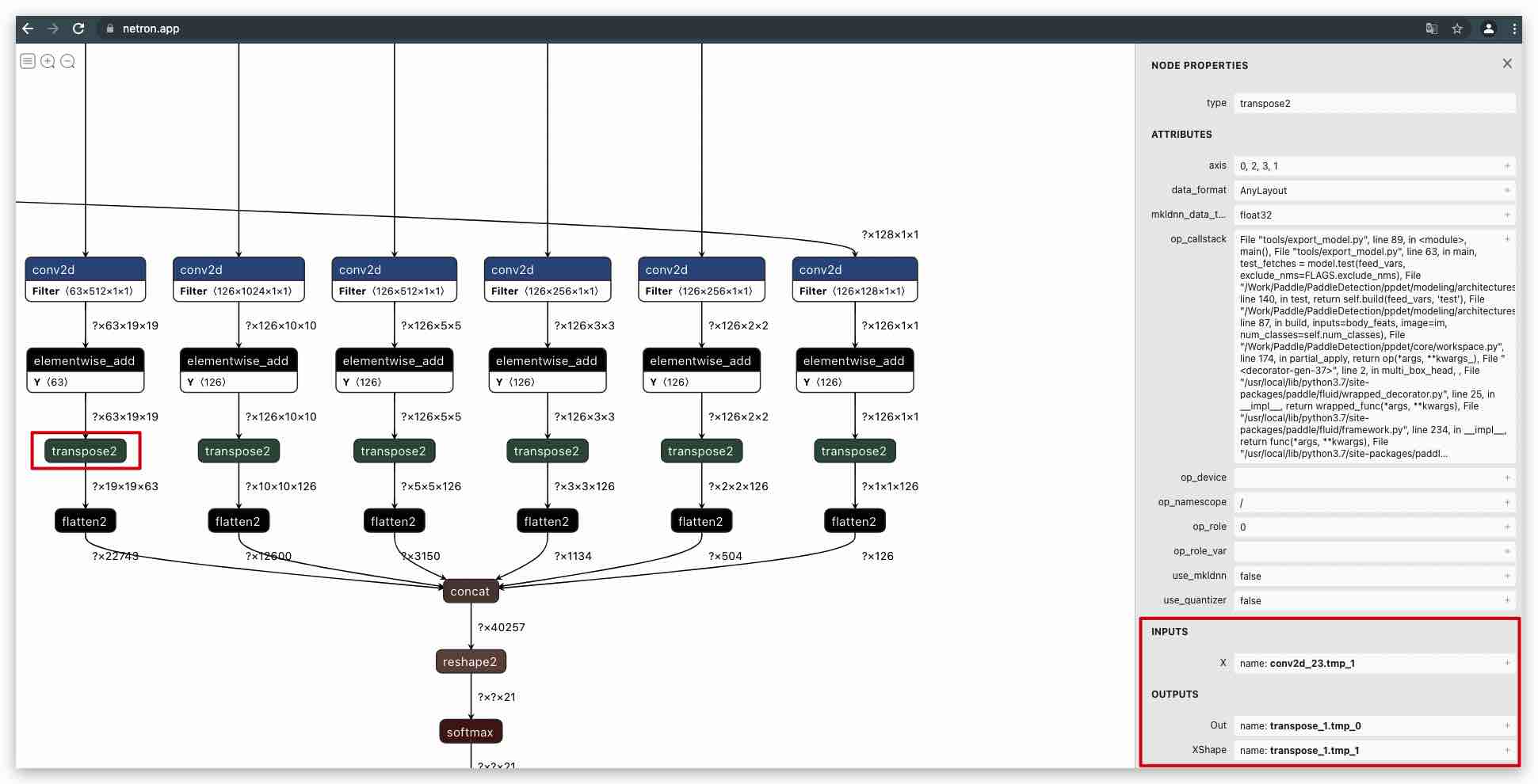
其它说明¶
华为达芬奇架构的 NPU 内部大量采用
float16进行运算,因此,预测结果会存在偏差,但大部分情况下精度不会有较大损失,可参考 Paddle-Lite-Demo 中Image Classification Demo for Android 对同一张图片 CPU 与华为 Kirin NPU 的预测结果。华为 Kirin 810/990 Soc 搭载的自研达芬奇架构的 NPU,与 Kirin 970/980 Soc 搭载的寒武纪 NPU 不一样,同样的,与 Hi3559A、Hi3519A 使用的 NNIE 也不一样,Paddle Lite 只支持华为自研达芬奇架构 NPU。
我们正在持续增加能够适配 HiAI IR 的 Paddle 算子
bridge/converter,以便适配更多 Paddle 模型,同时华为研发同学也在持续对HiAI IR性能进行优化。