
精度核验与问题追查¶
本文档将向您介绍在推理部署过程中可以完成推理,但是结果不一致,出现影响到最终指标的 diff 的情况下,如何进行精度问题的追查。
1 追查准备工作¶
在追查出现精度问题原因前需要对齐所有的推理配置项,控制其他变量一致,其中包括:
(1) paddle版本
(2) 硬件环境
(3) 模型
(4) 预处理和模型输入
如果是 C++ 和 Python 结果不一致,请使用同一硬件环境;如果是不同硬件结果不一致,请使用同样的测试代码。
2 追查具体步骤¶
以正确结果为基准(训练前向,或不开任何优化的推理结果),不断按如下步骤调整错误结果的配置从而复现问题。
2.1 预处理和模型输入对齐¶
打印模型输入数据,确定预处理对齐(比对两种情况下的全部模型输入是否完全一致)。
2.2 关闭所有优化¶
关闭所有优化(对应 API 如下),不开启 TensorRT,排查结果是否对齐,此种情况下约等于使用训练前向进行推理。
| API | 内存显存优化 | IR | TensorRT |
|---|---|---|---|
| C++ | //config.EnableMemoryOptim() 不开启 | config.SwitchIrOptim(false) | No |
| Python | #config.enable_memory_optim() 不开启 | config.switch_ir_optim(False) | No |
结果分析
(1) 如果此步骤发现结果不对齐或报错,可以在同样环境下用训练前向的 paddle.static.Executor 接口加载模型,跑训练前向验证一下结果是否一致,结果仍不一致则为原生 OP 实现问题,结果一致但是推理接口出错则是推理问题。
(2) 定位引起不一致的具体 OP : 可以通过裁剪模型的方式,尝试进一步定位引发结果出错的具体 OP。裁剪网络方式可以使用二分法,或者针对网络结构设计容易快速定位 OP 的方式(如果裁剪重复结构的分界线,backbone 等)。模型裁剪可以通过组网代码,或者使用我们研发使用的模型裁剪工具。
2.3 开启内存显存优化¶
配置选项:
| API | 内存显存优化 | IR | TensorRT |
|---|---|---|---|
| C++ | config.EnableMemoryOptim() 开启 | config.SwitchIrOptim(false) | No |
| Python | config.enable_memory_optim() 开启 | config.switch_ir_optim(False) | No |
模型推理在是否开启内存显存优化的情况下均可正常使用,不会影响性能,只可能影响显存的大小,在使用 TensorRT 的情况下,对显存影响也不大。若开启内存显存优化情况下,结果出现不一致,请您能够提交相关的样例至 issue,协助我们解决框架问题。
2.4 开启IR优化¶
配置选项:
| API | 内存显存优化 | IR | TensorRT |
|---|---|---|---|
| C++ | config.EnableMemoryOptim() 开启 | config.SwitchIrOptim(true) | No |
| Python | config.enable_memory_optim() 开启 | config.switch_ir_optim(True) | No |
IR 优化会涉及到具体的 Pass 优化,如果开启 IR 优化后出现结果不一致的情况,下一步需要定位引发问题的具体 Pass。
(1) C++ API
config.pass_builder()->DeletePass("xxx_fuse_pass")
(2) Python API
config.delete_pass("xxxx_fuse_pass")
为了快速定位出问题的 Pass,有两种思路:
(1) 二分法。一次注释一半的 Pass,二分法查找。Pass 全集见运行日志中的 ir_analysis_pass 部分。
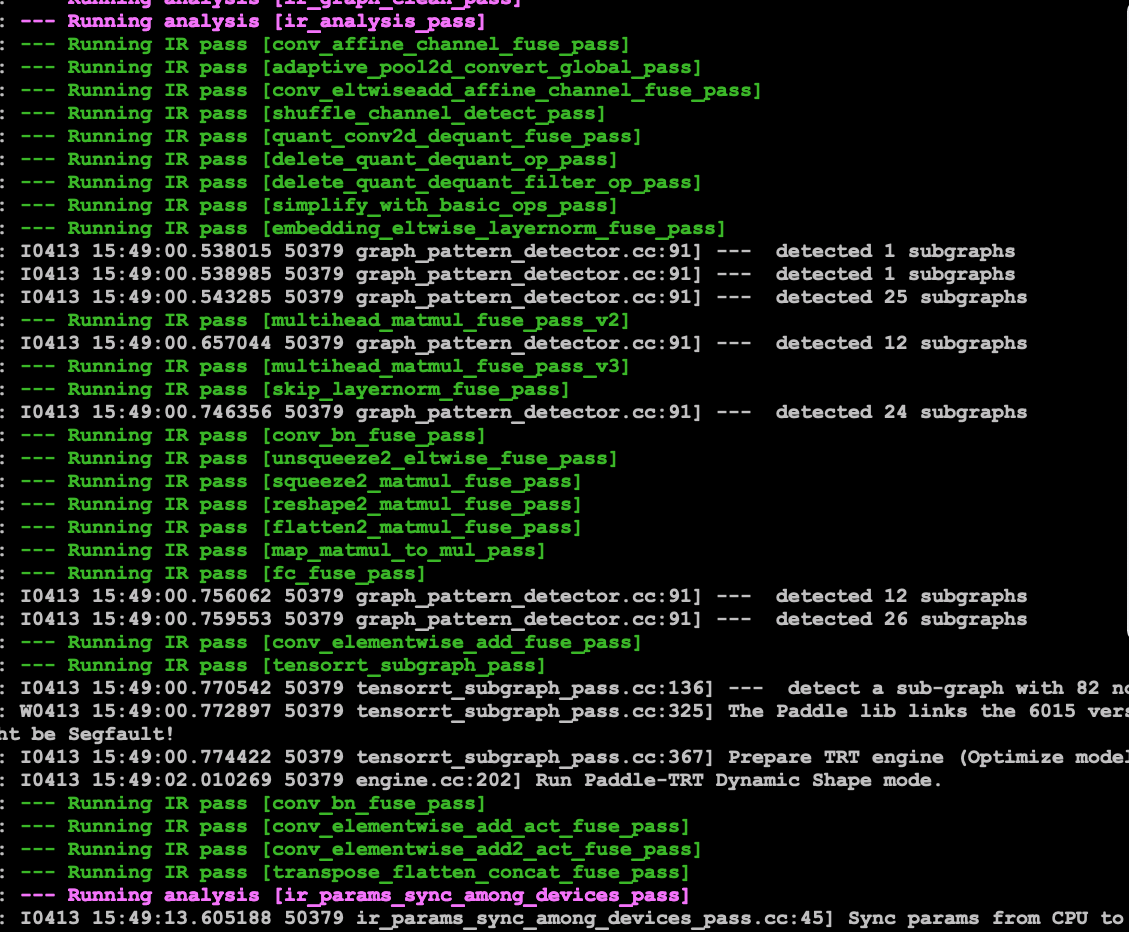
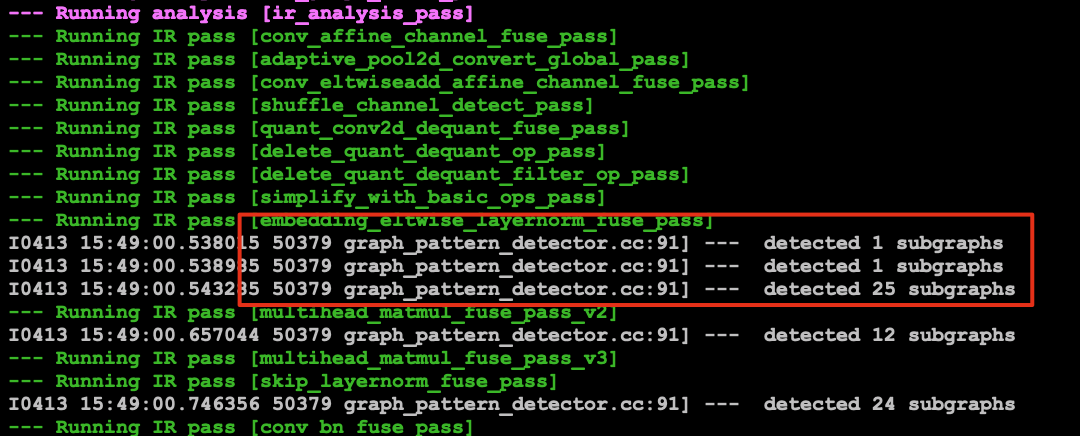
(2) 逐个查找。delete 命中的 Pass(有命中日志的 Pass ),如下图。
2.5 开启 TensorRT¶
开启 TensorRT,一般不会出现精度问题,会出现推理出错的情况。
2.5.1 动态 shape 输入¶
如果开启 TensorRT 后有如下报错,请参考日志设置正确动态 shape 输入变量。

(1) c++ API
std::map<std::string, std::vector<int>> min_input_shape = {
{"data", {1, 3, 224, 224}}};
std::map<std::string, std::vector<int>> max_input_shape = {
{"data", {1, 3, 224, 224}}};
std::map<std::string, std::vector<int>> opt_input_shape = {
{"data", {1, 3, 224, 224}}};
config.SetTRTDynamicShapeInfo(min_input_shape, max_input_shape,
opt_input_shape);
(2) Python API
min_input_shape = {"data":[1, 3, 224, 224]}
max_input_shape = {"data":[1, 3, 224, 224]}
opt_input_shape = {"data":[1, 3, 224, 224]}
config.set_trt_dynamic_shape_info(min_input_shape, max_input_shape, opt_input_shape)
或者使用推理自动生成动态 shape 的方式进行操作,对应 API 如下,先调用 CollectShapeRangeInfo 接口生成动态 shape 文件,在推理时将 CollectShapeRangeInfo 接口删掉,使用 EnableTunedTensorRtDynamicShape 接口调用动态 shape 输入即可。
(1) c++ API
//config.CollectShapeRangeInfo("shape_range_info.pbtxt");
config.EnableTunedTensorRtDynamicShape("shape_range_info.pbtxt", 1);
(2) Python API
#config.collect_shape_range_info("shape_range_info.pbtxt")
config.enable_tuned_tensorrt_dynamic_shape("shape_range_info.pbtxt", True)
2.5.2 禁止 OP 进入 TensorRT¶
若推理报错结果显示某个具体 OP 推理出现问题,可将此 OP 移出进入 TensorRT 的列表,使用原生 GPU 进行推理。
(1) c++ API
config.Exp_DisableTensorRtOPs({"concat"});
(2) Python API
config.exp_disable_tensorrt_ops(["concat"])
2.6 其他¶
如果通过以上步骤仍未解决您的问题,请再仔细检查各步骤是否完全对齐或者可提交 issue,将您的具体问题、单测以及模型等提供给 Paddle Inference 框架同学,感谢。