
PIR 基本概念和开发¶
在 3.0 版本下,飞桨研发了基于 MLIR 范式的新一代中间表示技术,即 Paddle IR(下简称 PIR)。这项技术对底层的核心概念如 Operation、Attribute 等进行了系统性的抽象,为开发者提供了灵活的基础组件;同时,通过引入 Dialect 这一概念,飞桨能够全面、分层次管理框架各模块对中间表示的需求,并支持开发者根据需求定制化扩展 Dialect,显著提升了框架的扩展性。PIR 遵循 SSA(即 Static Single Assignment)原则,统一了顶层结构,实现“算子顺序性”和“计算图语义”的兼容表示。此外,PIR 还提供了更加简洁、低成本的 Pass 开发体系,并内置了一系列丰富且功能完备的 Pass 优化策略,为大模型的极致性能优化提供了强有力支撑。
一、基础概念¶

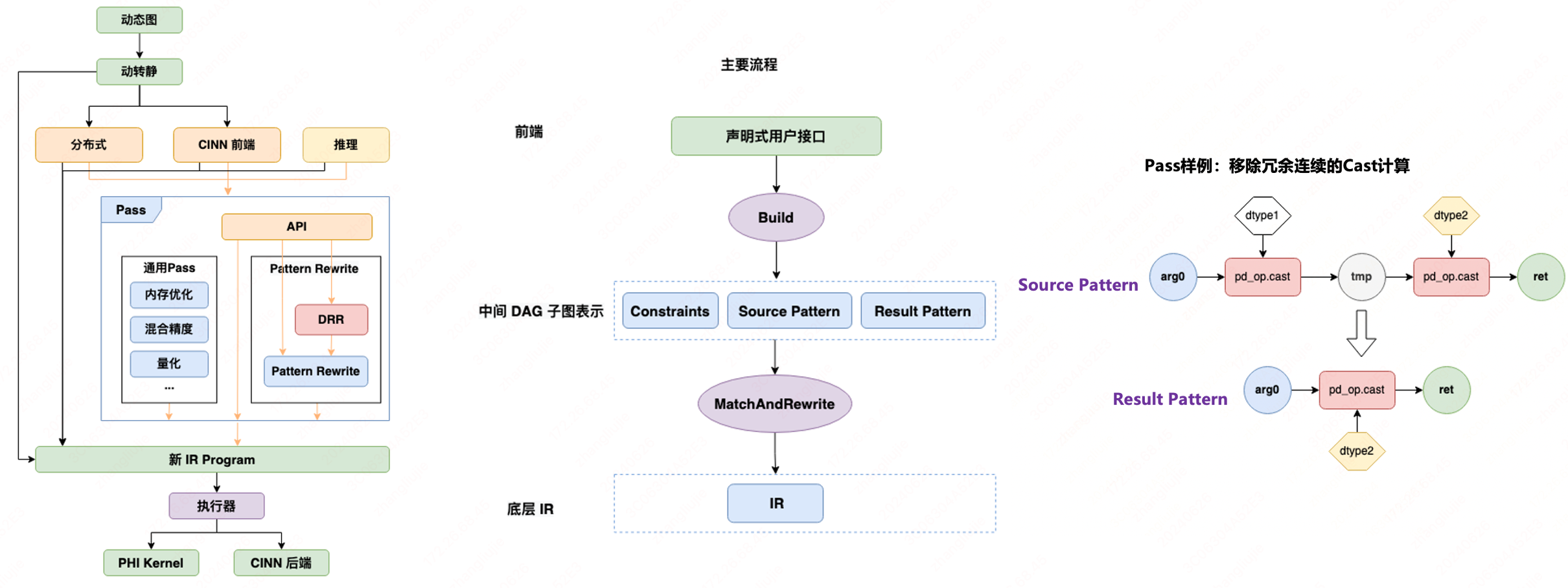
在深度学习框架 IR 概念中,「顺序性」和「图语义」是两个非常高频常用的概念。旧的中间表示体系由「顺序性」ProgramDesc 和「图语义」Graph 两个核心类共同承载。用户在静态图 API 或者动转静模块下,产生的中间表示是 Op-by-Op 的 Program,如果要应用更高层面的优化策略(比如算子融合、inplace 策略、剪枝等),框架会将由 Program 构造出 Graph,其由数据节点、算子节点和彼此关联的边构成。 在新的 Paddle IR 中,飞桨在底层抽象了一套高度可扩展的基础组件,包括 Type、Attrbute、Op、Trait 和 Interface,并引入了 Dialect 的概念,支持开发者灵活扩展、自由定制,提供了完备鲁邦的语义表达能力;在模型表示层,通过多 Dialect 模块化管理,统一多端表示,实现了训推一体的全架构统一表示,无缝衔接组合算子和编译器,支持自动优化和多硬件适配;在图变换层,通过统一底层模块,简化基础概念,向用户提供了低成本开发、易用高性能、丰富可插拔的 Pass 优化机制。 飞桨的新一代的 IR 表示坚持 SSA(静态单赋值)原则,模型等价于一个有向无环图。并以 Value、Operation 对计算图进行抽象, Operation 为节点,Value 为边。
Operation 表示计算图中的节点:一个 Operation 表示一个算子,它里面包含了零个或多个 Region;Region 表示一个闭包,它里面包含了零个或多个 Block;Block 表示一个符合 SSA 的基本块,里面包含了零个或多个 Operation;三者循环嵌套,可以实现任意复杂的语法结构
Value 表示计算图中的有向边:用来将两个 Operaton 关联起来,描述了程序中的 UD 链(即 Use-Define 链);OpResult 表示定义端,定义了一个 Value,OpOperand 表示使用端,描述了对一个 Value 的使用。
二、设计初衷¶
计算图中间表示(Intermediate Representation,即 IR)是深度学习框架性能优化、推理部署、编译器等方向的重要基石。近些年来,越来越多的框架和研究者将编译器技术引入到深度学习的神经网络模型优化中,并在此基础上借助编译器的理念、技术和工具对神经网络进行自动优化和代码生成。飞桨历史上在架构层面并存着多套不同的中间表示体系,其表达能力各不相同、Pass 开发维护成本较高,代码复用性较差,缺乏统一规范,存在严重的框架稳定性问题。

因此在 3.0 版本下,飞桨在基础架构层面规范了中间表示 IR 定义,实现全架构统一表示,实现上下游各个方向共享开发成果:
推理部署 :简化抽象计算图,解决有环问题,降低 Pass 的开发成本
分布式侧 :多 Dialect 管理算子,支持分布式属性的灵活标记
编译器侧 :严格遵循 SSA 原则,灵活支撑编译优化鲁棒性
飞桨的新一代 IR 架构聚焦于高度灵活和高扩展性两个重要维度,通过更加完备且鲁邦的语义表达能力、训推全架构统一表示和高效可插拔的性能优化策略(Pass)开发机制,实现复杂语义支持,更便捷地支撑大模型自动并行下丰富的切分策略,无缝对接神经网络编译器实现自动性能优化和多硬件适配。
三、使用指南¶
飞桨新的一代 IR 是基础架构层面的升级,对于用户在 API 层面的使用是无感的,用户可保持之前动转静(即 paddle.jit.to_static)或静态图代码不变,3.0.0 版本默认使用新 IR 功能, 在前置 3.0 系列版本下需额外通过 export FLAGS_enable_pir_api=1 开启新 IR 功能即可,如下是一个简单的使用样例。
# test_add_relu.py
import unittest
import numpy as np
import paddle
from paddle.static import InputSpec
class SimpleNet(paddle.nn.Layer):
def __init__(self):
super().__init__()
def forward(self, x, y):
z = x + y
out = paddle.nn.functional.relu(z)
return out
# Step 1: 构建模型对象,并应用动转静策略
specs = [InputSpec(shape=(-1, -1)), InputSpec(shape=(-1, -1))]
net = paddle.jit.to_static(SimpleNet(), specs)
# Step 2: 准备输入,执行 forward
x = paddle.rand(shape=[16, 64], dtype=paddle.float32)
y = paddle.rand(shape=[16, 64], dtype=paddle.float32)
out = net(x, y)
print(out)
将上述文件保存为 test_add_relu.py,执行如下命令: FLAGS_enable_pir_api=1 python test_add_relu.py 即可。开发者可额外指定 GLOG_v=6 输出日志,查看新一代 IR 下的 Program 表示,如下所示,在动转静或静态图模式下,用户的代码经过组网 API 下会先生成 Operator Dialect 下计算图表示,在执行时飞桨会将其转换为给定硬件下的 Kernel Dialect,然后交给执行器去依次调度对应的 PHI 算子库,计算最终结果。
{ // Operator Dialect
(%0) = "pd_op.data" () {dtype:(pd_op.DataType)float32,name:"x",place:(pd_op.Place)Place(undefined:0),shape:(pd_op.IntArray)[-1,-1],stop_gradient:[true]} : () -> builtin.tensor<-1x-1xf32>
(%1) = "pd_op.data" () {dtype:(pd_op.DataType)float32,name:"y",place:(pd_op.Place)Place(undefined:0),shape:(pd_op.IntArray)[-1,-1],stop_gradient:[true]} : () -> builtin.tensor<-1x-1xf32>
(%2) = "pd_op.add" (%0, %1) {stop_gradient:[true]} : (builtin.tensor<-1x-1xf32>, builtin.tensor<-1x-1xf32>) -> builtin.tensor<-1x-1xf32>
(%3) = "pd_op.relu" (%2) {stop_gradient:[true]} : (builtin.tensor<-1x-1xf32>) -> builtin.tensor<-1x-1xf32>
() = "builtin.shadow_output" (%3) {output_name:"output_0"} : (builtin.tensor<-1x-1xf32>) ->
}
// IR after lowering
{ // Kernel Dialect
(%0) = "data(phi_kernel)" () {dtype:(pd_op.DataType)float32,kernel_key:<backend:Undefined|layout:Undefined(AnyLayout)|dtype:float32>,kernel_name:"data",name:"x",op_name:"pd_op.data",place:(pd_op.Place)Place(undefined:0),shape:(pd_op.IntArray)[-1,-1],stop_gradient:[true]} : () -> undefined_tensor<-1x-1xf32>
(%1) = "shadow_feed(phi_kernel)" (%0) {kernel_key:<backend:GPU|layout:Undefined(AnyLayout)|dtype:float32>,kernel_name:"shadow_feed",op_name:"pd_op.shadow_feed"} : (undefined_tensor<-1x-1xf32>) -> gpu_tensor<-1x-1xf32>
(%2) = "data(phi_kernel)" () {dtype:(pd_op.DataType)float32,kernel_key:<backend:Undefined|layout:Undefined(AnyLayout)|dtype:float32>,kernel_name:"data",name:"y",op_name:"pd_op.data",place:(pd_op.Place)Place(undefined:0),shape:(pd_op.IntArray)[-1,-1],stop_gradient:[true]} : () -> undefined_tensor<-1x-1xf32>
(%3) = "shadow_feed(phi_kernel)" (%2) {kernel_key:<backend:GPU|layout:Undefined(AnyLayout)|dtype:float32>,kernel_name:"shadow_feed",op_name:"pd_op.shadow_feed"} : (undefined_tensor<-1x-1xf32>) -> gpu_tensor<-1x-1xf32>
(%4) = "add(phi_kernel)" (%1, %3) {kernel_key:<backend:GPU|layout:NCHW|dtype:float32>,kernel_name:"add",op_name:"pd_op.add",stop_gradient:[true]} : (gpu_tensor<-1x-1xf32>, gpu_tensor<-1x-1xf32>) -> gpu_tensor<-1x-1xf32>
(%5) = "relu(phi_kernel)" (%4) {kernel_key:<backend:GPU|layout:NCHW|dtype:float32>,kernel_name:"relu",op_name:"pd_op.relu",stop_gradient:[true]} : (gpu_tensor<-1x-1xf32>) -> gpu_tensor<-1x-1xf32>
() = "builtin.shadow_output" (%5) {output_name:"output_0"} : (gpu_tensor<-1x-1xf32>) ->
}
四、架构原理¶
在大模型场景下,对深度学习框架中间表示的灵活性、扩展性和完备性提出了全新的需求。飞桨通过抽象核心结构,引入 Dialect 概念,实现多 Dialect 模块化,并提供了易用高性能、低成本开发、丰富可插拔的 Pass 优化策略,串联 AI 编译器,适配支持多异构硬件,面向大模型训推流程优化提速。

如上左图所示,新一代 IR 的整体设计自底向上分为三层:
1.灵活的基础组件¶
飞桨提供了 Trait 和 Interface 两种重要机制实现了对算子 Op 的特征和接口的抽象标记。 比如 InplaceTrait 表示一个 Op 具有 Inplace 特征, InferShapeInterface 表示一个算子定义了 InferShape 函数接口等,这二者都是可以任意扩展的,只要派生自相应的基类、遵循相应的实现规则即可;并对算子体系下核心概念抽出 Type、Attrbute、Op,这三者是基于 Trait 和 Interface 进行定义的。它们会对关联自己所拥有的相应 Trait 和 Interface ;Dialect 用来对 Type、Attribtue、Op 做模块化管理, 比如 BuiltinDialect、PaddleDialect、CinnDialect 等等。一个 Dialect 里面包含了一系列的 Type、Attribtue、Op 的定义。相应的,每个 Type、Attribtue、Op 都是定义在某个唯一的 Dialect 里面。对整个 IR 框架而言, Dialect 是可以随意插拔的,也是可以任意扩展的。
这一层是 IR 适应多种场景的基础。这一层的每一个要素都是可定制化扩展的,一般情况下,针对一个具体的场景,比如分布式、编译器。都需要定义自己需要用到的 Trait、Interfce,然后定义自己的 Dialect,在自己的 Dialect 里面,定义自己需要用到的 Type、Attribute、Op。
2.多层级的 Dialect¶
飞桨通过不同层级的 Dialect 来管理框架内不同领域的算子体系,比如 Built-in 下的 Shape Dialect 和 Control Flow Dialect,分别用户形状符号推导和控制流表示、与 PHI 算子库执行体系相关的 Operator Dialect 和 Kernel Dialect、与神经网络编译器领域相关的 CINN Dialect 等。在飞桨神经网络编译器中,主要以计算图 Operator Dialect 为输入,经过组合算子和 Pass Pipline 后,会转换为 CINN Dialect,并附加 Shape Dialect 中的符号信息,最后会 Lowering 成编译器的 AST IR。 上述这些多层级的 Dialect 内的算子 Op 会组成 Program ,并用来表示一个具体的模型。它包含两部分:计算图 和 权重 。
Value、Operation 用来对计算图进行抽象。Value 表示计算图中的有向边,他用来将两个 Operaton 关联起来,描述了程序中的 UD 链 ,Operation 表示计算图中的节点。一个 Operation 表示一个算子,它里面包含了零个或多个 Region 。Region 表示一个闭包,它里面包含了零个或多个 Block。Block 表示一个符合 SSA 的基本块,里面包含了零个或多个 Operation 。三者循环嵌套,可以实现任意复杂的语法结构。
Weight 用来对模型的权重参数进行单独存储,这也是深度学习框架和传统编译器不一样的地方。传统编译器会将数据段内嵌到程序里面。这是因为传统编译器里面,数据和代码是强绑定的,不可分割。但是对神经网络而言,一个计算图的每个 epoch 都会存在一份权重参数,多个计算图也有可能共同一份权重参数,二者不是强绑定的
3.功能完善的 Pass 体系¶
Pass 的核心是子图匹配和替换(即图变换),是将一个 Program 通过某种规则转换为另一个新的 Program。IR 中包含了计算图中全局信息,如上下游算子的邻接关系等,更有利于进行图优化,比如常量折叠、算子融合,Inplace 策略等:

飞桨内置了一系列计算图优化、显存优化、量化等通用 Pass,灵活可配置。并简化了基础概念,向用户提供了 2 种 Pass 开发范式:Pattern Rewriter 和 Declarative Rewrite Rule(简称 DRR),充分兼顾自定义灵活性和开发易用性,大幅降用户 Pass 优化策略的开发门槛和代码量。
4.兼容性良好的 Save/Load 体系¶
基于 PIR 体系基本结构的 save_load 体系,支持 pir 模型结构的保存和加载,提供版本管理机制,支持常规 op 升级后的兼容推理。
1. Model 层面¶
a. 结合 PIR 的 IR 结构,设计简洁的序列化协议,保证正确反序列化的基础上降低存储内容。
b. 重构底层序列化和反序列化机制,实现 PIR 类型系统,模型结构增加删除修改灵活扩展时,saveload 体系灵活扩展,支持新功能的保存和加载。
paddle 3.0 beta 版之前,模型存储文件为 xxx.pdmodel,序列化协议为 protobuf;paddle 3.0 beta 版之后,模型存储文件为 xxx.json, 序列化协议为 json。
c. 拥有良好的版本管理和版本间修改的兼容体系,支持新版本兼容读取旧版本模型进行推理训练的功能。
2. Parameter 层面¶
a. C++ 层参数存储,采用二进制流的保存方式,存储文件为 xxx.pdiparams。
b. Python 层参数存储, 使用 pickle 序列化工具,存储文件为 xxx.pdparams。
五、二次开发注意事项¶
1.背景¶
PIR 组网过程中存在『插入隐式算子』的场景,所谓『隐式算子』是指:非用户直接调用 API 接口插入的对应算子,而是底层组网逻辑及执行逻辑中自动插入的算子,这里算子包括三类:
组网过程中:为可变 Attribute 插入的 pd_op.full / pd_op.full_int_array 算子
组网过程中:针对 pir::VectorType 插入的 builtin.combine / builtin.split 算子
执行过程中:为静态 kernel 选择插入的 pd_op.shadow_feed 算子
2.隐式算子介绍¶
| 插入的隐式算子 | 含义 |
|---|---|
| pd_op.full / pd_op.full_int_array | 飞桨的算子定义包含可变 Attribute 的概念,对于可变 Attribute,用户的组网 API 可传入一个常量、也可传入一个 Tensor/Value。在 PIR 的算子定义体系下,可变 Attribute 都将被视为输入变量,因此,当用户 API 传入一个常量的时候,将在组网代码中通过自动插入 pd_op.full / pd_op.full_int_array 将输入的常量转换为变量,再构造对应的算子。 包含可变 Attribute 的算子集合:在 paddle/phi/ops/yaml/op_compat.yaml 中搜索 scalar 及 int_array 标记的属性。 |
| builtin.combine / builtin.split | 这两个算子针对 pir::VectorType 引入的辅助算子,用于将一组具有相同 Type 的 Value 拼接成一个 VectorType 的 Value,或者将 VectorType 的 Value 拆分成多个具有相同 Type 的 Value。 算子定义过程中,会出现上述内容的都是输入/输出包含 Tensor[] 类型的算子,例如:concat 算子的输入 Tensor[] x。 |
| pd_op.shadow_feed | 为执行流程中全静态选 Kernel 所引入的隐式算子,该算子的签名是:out = shadow_feed(x, dst_place_type),作用是将输入 x 拷贝/共享到 dst_place_type,若 x 的 place 与 dst_place_type 不一致,则执行 memcpy,否则 out 直接与 x share data。 算子定义见:paddle/phi/ops/yaml/inconsistent/static_ops.yaml;Kernel 定义见:paddle/phi/kernels/impl/data_impl.h。 |