
timeline 工具简介¶
本地使用¶
在训练的主循环外加上
profiler.start_profiler(...)和profiler.stop_profiler(...)。运行之后,代码会在/tmp/profile目录下生成一个 profile 的记录文件。提示: 请不要在 timeline 记录信息时运行太多次迭代,因为 timeline 中的记录数量和迭代次数是成正比的。
import numpy as np import paddle import paddle.fluid as fluid from paddle.fluid import profiler place = fluid.CPUPlace() def reader(): for i in range(100): yield [np.random.random([4]).astype('float32'), np.random.random([3]).astype('float32')], main_program = fluid.Program() startup_program = fluid.Program() with fluid.program_guard(main_program, startup_program): data_1 = fluid.layers.data(name='data_1', shape=[1, 2, 2]) data_2 = fluid.layers.data(name='data_2', shape=[1, 1, 3]) out = fluid.layers.fc(input=[data_1, data_2], size=2) # ... feeder = fluid.DataFeeder([data_1, data_2], place) exe = fluid.Executor(place) exe.run(startup_program) pass_num = 10 for pass_id in range(pass_num): for batch_id, data in enumerate(reader()): if pass_id == 0 and batch_id == 5: profiler.start_profiler("All") elif pass_id == 0 and batch_id == 10: profiler.stop_profiler("total", "/tmp/profile") outs = exe.run(program=main_program, feed=feeder.feed(data), fetch_list=[out])运行
python paddle/tools/timeline.py来处理/tmp/profile,这个程序默认会生成一个/tmp/timeline文件,你也可以用命令行参数来修改这个路径,请参考timeline.py。
python Paddle/tools/timeline.py --profile_path=/tmp/profile --timeline_path=timeline
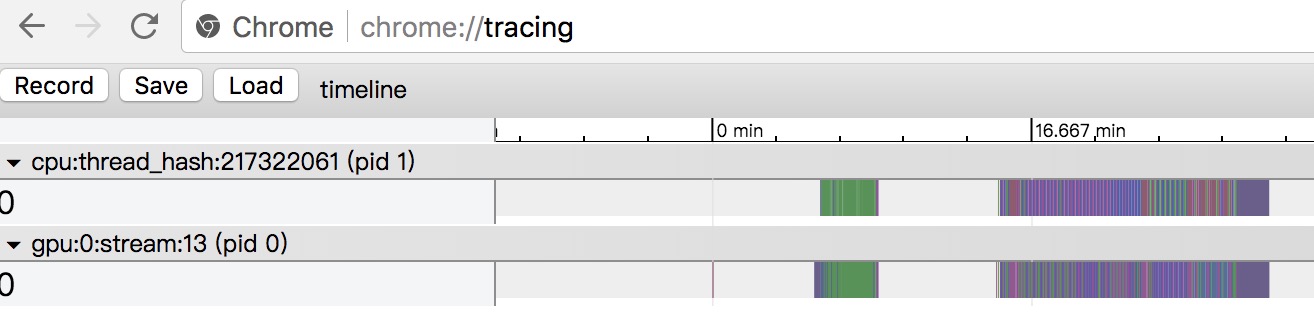
打开 chrome 浏览器,访问chrome://tracing/,用
load按钮来加载生成的timeline文件。结果如下图所示,可以放大来查看 timeline 的细节信息。
分布式使用¶
一般来说,分布式的训练程序都会有两种程序:pserver 和 trainer。我们提供了把 pserver 和 trainer 的 profile 日志用 timeline 来显示的方式。
trainer 打开方式与本地使用部分的第 1 步相同
pserver 可以通过加两个环境变量打开 profile,例如:
FLAGS_rpc_server_profile_period=10 FLAGS_rpc_server_profile_path=./tmp/pserver python train.py
把 pserver 和 trainer 的 profile 文件生成一个 timeline 文件,例如:
python /paddle/tools/timeline.py
--profile_path trainer0=local_profile_10_pass0_0,trainer1=local_profile_10_pass0_1,pserver0=./pserver_0,pserver1=./pserver_1
--timeline_path ./dist.timeline
在 chrome 中加载 dist.timeline 文件,方法和本地使用第 4 步相同。