



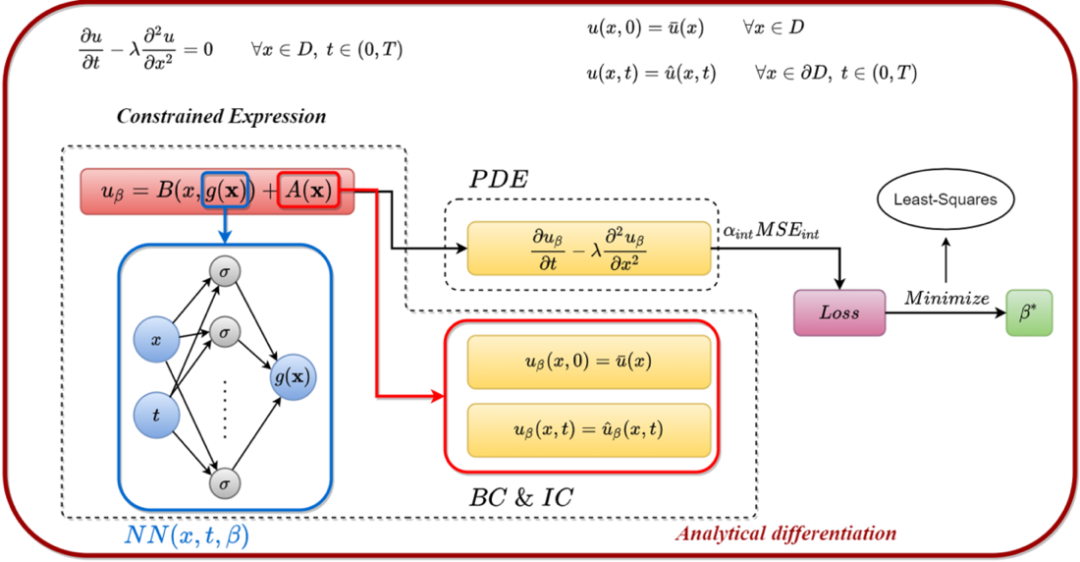
 PINN方法基础原理
PINN方法基础原理


 用例验证及评估流程
用例验证及评估流程
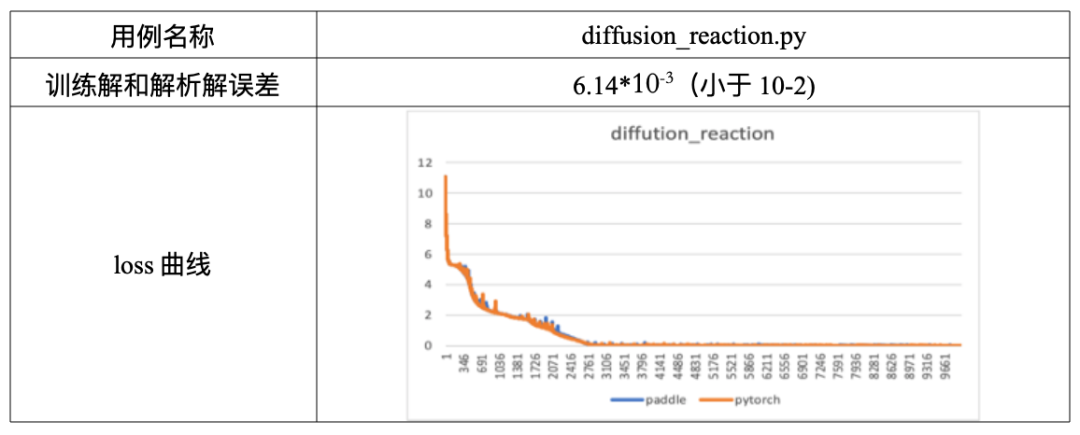
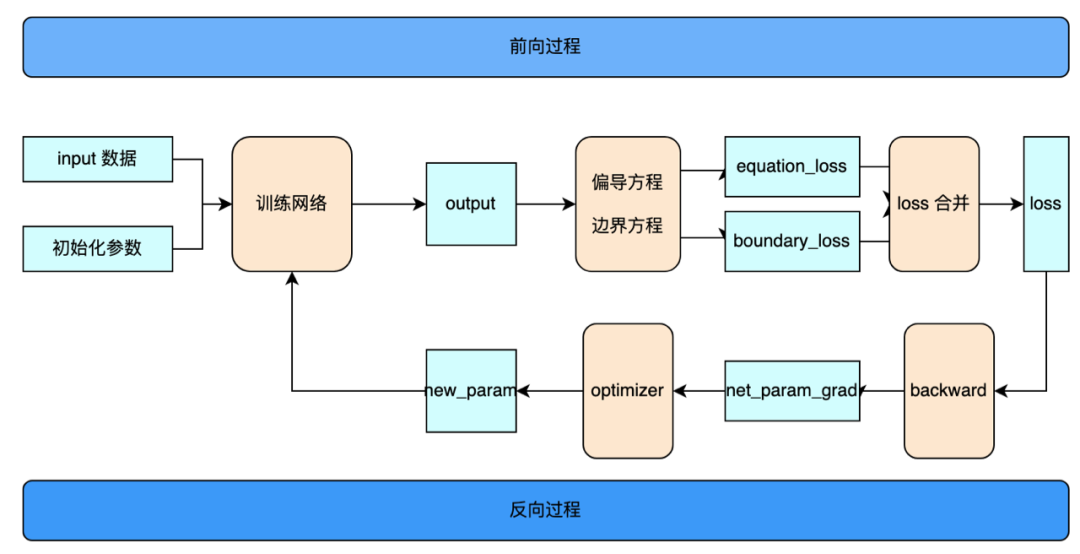 用例训练过程
用例训练过程
训练网络
偏导方程和边界方程
def Possion(x,y):
dy_xx = dde.grad.hessian(y,x)
return -dy_xx - np.pi **
2 * bkd.sin(np.pi * x)
equation_loss = pde(inputs,outputs_)
boundary_condition_loss = boundary(inputs,outputs_)
loss计算、反向传播及参数更新
loss = paddle.sum(equation_loss ,boundary_condition_loss)
反向传播
loss
.backward()
参数更新
paddle
.optimizer
.Adam
.step()
paddle
.optimizer
.Adam
.clear_grad()
单独框架自测验证
验证注意点
dde
.set_random_seed (100)
 用例问题排查方法
用例问题排查方法
设置1(随机数种子)
设置2 (数据类型)
dde.
config.set_default_float(
'float64')
设置3(初始化参数)
weight_attr_ = paddle.ParamAttr(initializer = paddle.nn.initializer.Constant(0.2345))
self.linears.append(paddle.nn.Linear(layer_sizes[i - 1],layer_sizes[i],weight_attr=weight_attr_,bias_attr=False))
self.linears.append(
torch.nn.Linear(layer_sizes[i -
1],layer_sizes[i],bias=
False,dtype=torch.float64)
)
torch.nn.init.constant_(
self.linears[
-1].weight.data,
0.2345)
设置4(控制合理误差)
设置5(降低验证难度)

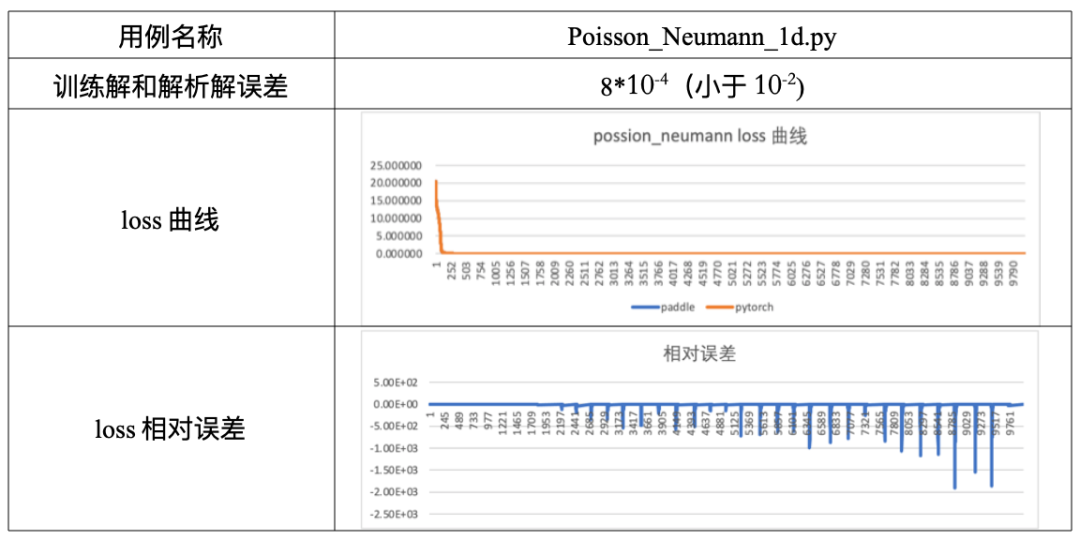
loss曲线吻合
loss曲线后期出现波动
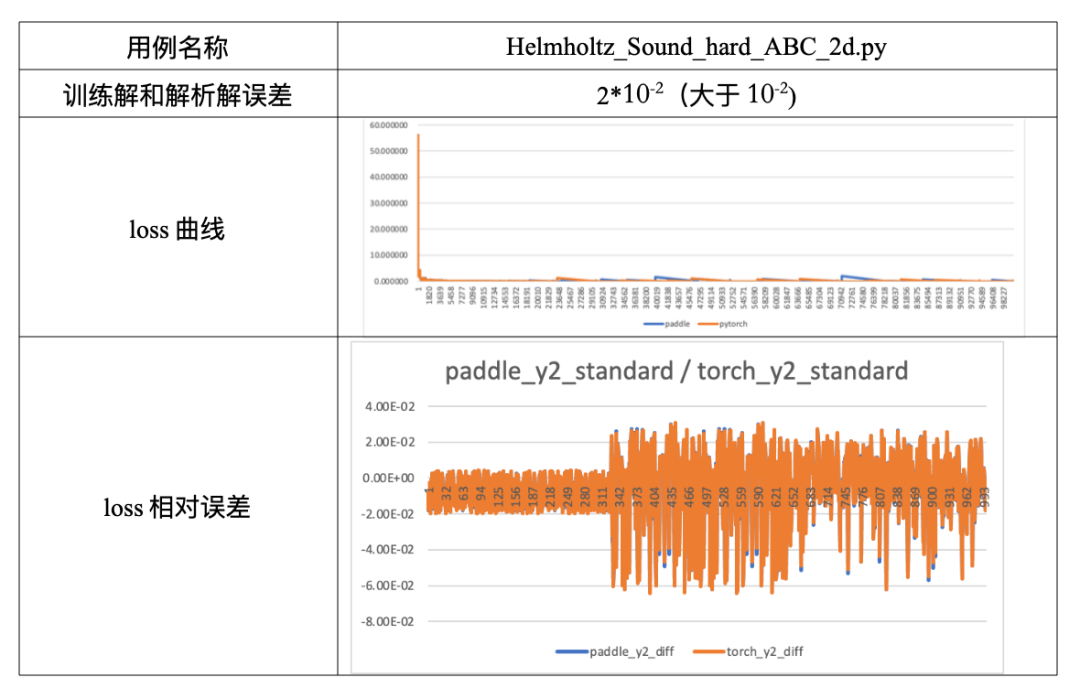
Loss 曲线中间出现部分波动,导致曲线没有严格吻合
 总结
总结
 附录
附录
class NN
class NN(paddle.nn.Layer):
"""Base class for all neural network modules."""
def __init__(self):
super().__init__()
self._input_transform =
None
self._output_transform =
None
def apply_feature_transform(self,transform):
"""Compute the features by appling a transform to the network inputs,i.e.,
features = transform(inputs). Then,outputs = network(features).
"""
self._input_transform = transform
def apply_output_transform(self,transform):
"""Apply a transform to the network outputs,i.e.,
outputs = transform(inputs,outputs).
"""
self._output_transform = transform
class FNN
class FNN(NN):
"""Fully-connected neural network."""
def __init__(self,layer_sizes,activation,kernel_initializer):
super().__init_
_()
self.activation = activations.get(activation)
self.layer_size = layer_sizes
initializer = initializers.get(kernel_initializer)
initializer_zero = initializers.get(
"zeros")
self.linears = paddle.nn.LayerList()
for i
in range(
1,len(layer_sizes)):
self.linears.append(
paddle.nn.Linear(
layer_sizes[i -
1],
layer_sizes[i],
)
)
initializer(
self.linears[-
1].weight)
initializer_zero(
self.linears[-
1].bias)
def forward(self,inputs):
x = inputs
if
self._input_transform is
not
None:
x =
self._input_transform(x)
for linear
in
self.linears[
:-1]:
x =
self.activation(linear(x))
x =
self.linears[-
1](x)
if
self._output_transform is
not
None:
x =
self._output_transform(inputs,x)
return x
inputs = paddle.to_tensor(inputs, stop_gradient=False)
outputs
_ =
self.net(inputs)
self.net.train()
框架参数转换
import numpy
as np
import torch
import paddle
def torch2paddle():
torch_path =
"./data/mobilenet_v3_small-047dcff4.pth"
paddle_path =
"./data/mv3_small_paddle.pdparams"
torch_state_dict = torch.load(torch_path)
fc_names = [
"classifier"]
paddle_state_dict = {}
for k
in torch_state_dict:
if
"num_batches_tracked"
in k:
continue
v = torch_state_dict[k].detach().cpu().numpy()
flag = [i
in k
for i
in fc_names]
if any(flag)
and
"weight"
in k:
# ignore bias
new_shape = [
1,
0] + list(range(
2,v.ndim))
print(
f"name: {k},ori shape: {v.shape},new shape: {v.transpose(new_shape).shape}")
v = v.transpose(new_shape)
k = k.replace(
"running_var",
"_variance")
k = k.replace(
"running_mean",
"_mean")
# if k not in model_state_dict:
if
False:
print(k)
else:
paddle_state_dict[k] = v
paddle.save(paddle_state_dict,paddle_path)
if __name__ ==
"__main__":
torch2paddle()
layer_size = [
2] + [num_dense_nodes] * num_dense_layers + [
2]
# paddle init param
w_array = []
// linear层的所有weight数据
b_array = []
// linear层的所有bias数据
input_str = []
file_name1 = sys.argv[
1]
with open(file_name1,mode=
'r')
as f1:
for line
in f1:
input_str.append(line)
j =
0
for i
in range(
1,len(layer_size)):
shape_weight = (layer_size[i
-1],layer_size[i])
w_line = input_str[j]
w = []
tmp = w_line.split(
',')
for
num
in tmp:
w.append(np.float(
num))
w = np.array(w).reshape(shape_weight)
w_array.append(w)
print(
"w . shape :",w.shape)
j = j+
1
bias_weight = (layer_size[i])
b_line = input_str[j]
b = []
tmp = b_line.split(
',')
for
num
in tmp:
b.append(np.float(
num))
b = np.array(b).reshape(bias_weight)
b_array.append(b)
print(
"b . shape :",b.shape)
j = j+
1
初始化参数读入
def __init__(self,layer_sizes,activation,kernel_initializer,w_array=[],b_array=[]):
super().__init_
_()
self.activation = activations.get(activation)
initializer = initializers.get(kernel_initializer)
initializer_zero = initializers.get(
"zeros")
self.linears = paddle.nn.LayerList()
for i
in range(
1,len(layer_sizes)):
weight_attr
_ = paddle.ParamAttr(initializer = paddle.nn.initializer.Assign(w_array[i-
1]))
bias_attr
_ = paddle.ParamAttr(initializer = paddle.nn.initializer.Assign(b_array[i-
1]))
self.linears.append(paddle.nn.Linear(layer_sizes[i -
1],layer_sizes[i],weight_attr=weight_attr
_,bias_attr=bias_attr
_))
# 参数输出为文件
if paddle.in_dynamic_mode():
import os
f = open(
'paddle_dygraph_param.log',
'ab')
for linear
in
self.
linears:
np.savetxt(f,linear.weight.numpy().reshape(
1,-
1),delimiter=
",")
np.savetxt(f,linear.bias.numpy().reshape(
1,-
1),delimiter=
",")
f.close()
同类框架对齐代码
def __init__(self,layer_sizes,activation,kernel_initializer,w_array=[],b_array=[]):
super().__init_
_()
self.activation = activations.get(activation)
initializer = initializers.get(kernel_initializer)
initializer_zero = initializers.get(
"zeros")
self.linears = torch.nn.ModuleList()
for i
in range(
1,len(layer_sizes)):
print(
"init i :",i,
"self.linears :",
self.linears)
self.linears.append(
torch.nn.Linear(
layer_sizes[i -
1],layer_sizes[i],bias=False,dtype=torch.float64
)
)
self.linears[-
1].weight = torch.nn.parameter.Parameter(torch.Tensor(w_array[i-
1]).transpose(
0,
1))
self.linears[-
1].bias = torch.nn.parameter.Parameter(torch.Tensor(b_array[i-
1]))
import os
f = open(
'pytorch_param.log',
'ab')
for linear
in
self.
linears:
# general initilizer :
tmp
0 = linear.weight.cpu().detach().numpy()
tmp
0 = np.transpose(tmp
0)
np.savetxt(f,tmp
0.reshape(
1,-
1),delimiter=
",")
np.savetxt(f,tmp1.reshape(
1,-
1),delimiter=
",")
f.close()
对比脚本
import sys
import numpy
as np
file_name1 = sys.argv[
1]
file_name2 = sys.argv[
2]
comp_file_name = sys.argv[
3]
paddle_data=[]
pytorch_data=[]
with open(file_name1,mode=
'r')
as f1:
for line
in f1:
#pytorch_data.append(float(line))
tmp = line.split(
',')
for
num
in tmp:
pytorch_data.append(float(
num))
with open(file_name2,mode=
'r')
as f2:
for line
in f2:
tmp = line.split(
',')
for
num
in tmp:
paddle_data.append(float(
num))
compare_data=[]
for i
in range(len(pytorch_data)):
if pytorch_data[i] ==
0.0:
tmp = np.inf
else:
tmp = (pytorch_data[i] - paddle_data[i]) / pytorch_data[i]
compare_data.append(tmp)
with open(comp_file_name,mode=
'w')
as f3:
compare_data = np.array(compare_data)
np.savetxt(f3,compare_data)
引用
拓展阅读
相关地址
PINN方法基础原理
用例验证及评估流程
用例训练过程
训练网络
偏导方程和边界方程
def Possion(x,y):
dy_xx = dde.grad.hessian(y,x)
return -dy_xx - np.pi **
2 * bkd.sin(np.pi * x)
equation_loss = pde(inputs,outputs_)
boundary_condition_loss = boundary(inputs,outputs_)
loss计算、反向传播及参数更新
loss = paddle.sum(equation_loss ,boundary_condition_loss)
反向传播
loss
.backward()
参数更新
paddle
.optimizer
.Adam
.step()
paddle
.optimizer
.Adam
.clear_grad()
单独框架自测验证
验证注意点
dde
.set_random_seed (100)
用例问题排查方法
设置1(随机数种子)
设置2 (数据类型)
dde.
config.set_default_float(
'float64')
设置3(初始化参数)
weight_attr_ = paddle.ParamAttr(initializer = paddle.nn.initializer.Constant(0.2345))
self.linears.append(paddle.nn.Linear(layer_sizes[i - 1],layer_sizes[i],weight_attr=weight_attr_,bias_attr=False))
self.linears.append(
torch.nn.Linear(layer_sizes[i -
1],layer_sizes[i],bias=
False,dtype=torch.float64)
)
torch.nn.init.constant_(
self.linears[
-1].weight.data,
0.2345)
设置4(控制合理误差)
设置5(降低验证难度)
loss曲线吻合
loss曲线后期出现波动
Loss 曲线中间出现部分波动,导致曲线没有严格吻合
总结
附录
class NN
class NN(paddle.nn.Layer):
"""Base class for all neural network modules."""
def __init__(self):
super().__init__()
self._input_transform =
None
self._output_transform =
None
def apply_feature_transform(self,transform):
"""Compute the features by appling a transform to the network inputs,i.e.,
features = transform(inputs). Then,outputs = network(features).
"""
self._input_transform = transform
def apply_output_transform(self,transform):
"""Apply a transform to the network outputs,i.e.,
outputs = transform(inputs,outputs).
"""
self._output_transform = transform
class FNN
class FNN(NN):
"""Fully-connected neural network."""
def __init__(self,layer_sizes,activation,kernel_initializer):
super().__init_
_()
self.activation = activations.get(activation)
self.layer_size = layer_sizes
initializer = initializers.get(kernel_initializer)
initializer_zero = initializers.get(
"zeros")
self.linears = paddle.nn.LayerList()
for i
in range(
1,len(layer_sizes)):
self.linears.append(
paddle.nn.Linear(
layer_sizes[i -
1],
layer_sizes[i],
)
)
initializer(
self.linears[-
1].weight)
initializer_zero(
self.linears[-
1].bias)
def forward(self,inputs):
x = inputs
if
self._input_transform is
not
None:
x =
self._input_transform(x)
for linear
in
self.linears[
:-1]:
x =
self.activation(linear(x))
x =
self.linears[-
1](x)
if
self._output_transform is
not
None:
x =
self._output_transform(inputs,x)
return x
inputs = paddle.to_tensor(inputs, stop_gradient=False)
outputs
_ =
self.net(inputs)
self.net.train()
框架参数转换
import numpy
as np
import torch
import paddle
def torch2paddle():
torch_path =
"./data/mobilenet_v3_small-047dcff4.pth"
paddle_path =
"./data/mv3_small_paddle.pdparams"
torch_state_dict = torch.load(torch_path)
fc_names = [
"classifier"]
paddle_state_dict = {}
for k
in torch_state_dict:
if
"num_batches_tracked"
in k:
continue
v = torch_state_dict[k].detach().cpu().numpy()
flag = [i
in k
for i
in fc_names]
if any(flag)
and
"weight"
in k:
# ignore bias
new_shape = [
1,
0] + list(range(
2,v.ndim))
print(
f"name: {k},ori shape: {v.shape},new shape: {v.transpose(new_shape).shape}")
v = v.transpose(new_shape)
k = k.replace(
"running_var",
"_variance")
k = k.replace(
"running_mean",
"_mean")
# if k not in model_state_dict:
if
False:
print(k)
else:
paddle_state_dict[k] = v
paddle.save(paddle_state_dict,paddle_path)
if __name__ ==
"__main__":
torch2paddle()
layer_size = [
2] + [num_dense_nodes] * num_dense_layers + [
2]
# paddle init param
w_array = []
// linear层的所有weight数据
b_array = []
// linear层的所有bias数据
input_str = []
file_name1 = sys.argv[
1]
with open(file_name1,mode=
'r')
as f1:
for line
in f1:
input_str.append(line)
j =
0
for i
in range(
1,len(layer_size)):
shape_weight = (layer_size[i
-1],layer_size[i])
w_line = input_str[j]
w = []
tmp = w_line.split(
',')
for
num
in tmp:
w.append(np.float(
num))
w = np.array(w).reshape(shape_weight)
w_array.append(w)
print(
"w . shape :",w.shape)
j = j+
1
bias_weight = (layer_size[i])
b_line = input_str[j]
b = []
tmp = b_line.split(
',')
for
num
in tmp:
b.append(np.float(
num))
b = np.array(b).reshape(bias_weight)
b_array.append(b)
print(
"b . shape :",b.shape)
j = j+
1
初始化参数读入
def __init__(self,layer_sizes,activation,kernel_initializer,w_array=[],b_array=[]):
super().__init_
_()
self.activation = activations.get(activation)
initializer = initializers.get(kernel_initializer)
initializer_zero = initializers.get(
"zeros")
self.linears = paddle.nn.LayerList()
for i
in range(
1,len(layer_sizes)):
weight_attr
_ = paddle.ParamAttr(initializer = paddle.nn.initializer.Assign(w_array[i-
1]))
bias_attr
_ = paddle.ParamAttr(initializer = paddle.nn.initializer.Assign(b_array[i-
1]))
self.linears.append(paddle.nn.Linear(layer_sizes[i -
1],layer_sizes[i],weight_attr=weight_attr
_,bias_attr=bias_attr
_))
# 参数输出为文件
if paddle.in_dynamic_mode():
import os
f = open(
'paddle_dygraph_param.log',
'ab')
for linear
in
self.
linears:
np.savetxt(f,linear.weight.numpy().reshape(
1,-
1),delimiter=
",")
np.savetxt(f,linear.bias.numpy().reshape(
1,-
1),delimiter=
",")
f.close()
同类框架对齐代码
def __init__(self,layer_sizes,activation,kernel_initializer,w_array=[],b_array=[]):
super().__init_
_()
self.activation = activations.get(activation)
initializer = initializers.get(kernel_initializer)
initializer_zero = initializers.get(
"zeros")
self.linears = torch.nn.ModuleList()
for i
in range(
1,len(layer_sizes)):
print(
"init i :",i,
"self.linears :",
self.linears)
self.linears.append(
torch.nn.Linear(
layer_sizes[i -
1],layer_sizes[i],bias=False,dtype=torch.float64
)
)
self.linears[-
1].weight = torch.nn.parameter.Parameter(torch.Tensor(w_array[i-
1]).transpose(
0,
1))
self.linears[-
1].bias = torch.nn.parameter.Parameter(torch.Tensor(b_array[i-
1]))
import os
f = open(
'pytorch_param.log',
'ab')
for linear
in
self.
linears:
# general initilizer :
tmp
0 = linear.weight.cpu().detach().numpy()
tmp
0 = np.transpose(tmp
0)
np.savetxt(f,tmp
0.reshape(
1,-
1),delimiter=
",")
np.savetxt(f,tmp1.reshape(
1,-
1),delimiter=
",")
f.close()
对比脚本
import sys
import numpy
as np
file_name1 = sys.argv[
1]
file_name2 = sys.argv[
2]
comp_file_name = sys.argv[
3]
paddle_data=[]
pytorch_data=[]
with open(file_name1,mode=
'r')
as f1:
for line
in f1:
#pytorch_data.append(float(line))
tmp = line.split(
',')
for
num
in tmp:
pytorch_data.append(float(
num))
with open(file_name2,mode=
'r')
as f2:
for line
in f2:
tmp = line.split(
',')
for
num
in tmp:
paddle_data.append(float(
num))
compare_data=[]
for i
in range(len(pytorch_data)):
if pytorch_data[i] ==
0.0:
tmp = np.inf
else:
tmp = (pytorch_data[i] - paddle_data[i]) / pytorch_data[i]
compare_data.append(tmp)
with open(comp_file_name,mode=
'w')
as f3:
compare_data = np.array(compare_data)
np.savetxt(f3,compare_data)
引用
拓展阅读
相关地址