

图神经网络(Graph Neural Network,GNN)是近年来出现的一种利用深度学习直接对图结构数据进行学习的方法,通过在图中的节点和边上制定聚合的策略,GNN能够学习到图结构数据中节点以及边内在规律和更加深层次的语义特征。图神经网络不仅成为学术界研究热点,而且已经在工业界广泛应用落地。特别在搜索、推荐、地图等领域,采用大规模分布式图引擎对异构图结构进行建模,已经成为技术发展的新趋势。
目前,分布式图学习框架通常在CPU集群上部署分布式图服务以及参数服务器,来支持大规模图结构的存储以及特征的更新。然而,基于CPU算力的图学习框架在建设成本、训练速度、稳定性以及复杂算法支持等方面都存在不足。
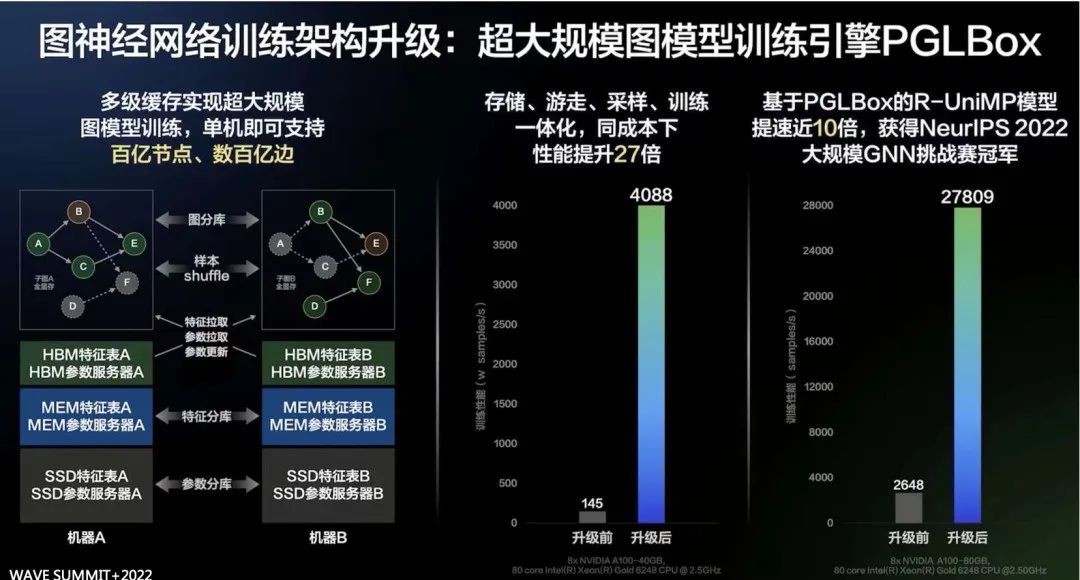
因此,百度飞桨推出了能够同时支持复杂图学习算法+超大图+超大离散模型的GPU大规模图学习训练框架PGLBox。该框架结合了百度移动生态模型团队在大规模业务技术的深耕,凝聚飞桨图学习PGL丰富的算法能力与应用经验,并依托飞桨深度学习平台通用的训练框架能力与灵活组网能力,不仅继承了飞桨前期开源的Graph4Rec[1]超大规模、灵活易用和适用性广的优点[2],更是在训练性能、图算法能力支持方面获得了显著提升。

 全面升级预置的图表示学习算法
全面升级预置的图表示学习算法

基于PGLBox的GNN技术获得了NeurIPS 2022大规模GNN挑战赛冠军[3],同时入选了百度Create2022十大黑科技,并在WAVE SUMMIT+2022上作为飞桨2.4版本最重要的框架新特性之一发布。凭借其超高性能、超大规模、超强图学习算法、灵活易用等特性,PGLBox在百度内大量业务场景实现广泛应用并取得显著业务收益,如百度推荐系统、百度APP、百度搜索、百度网盘、小度平台等。
在哪里可以找到我们~
看到这里相信大家已经迫不及待想要开箱试用了吧!PGLBox已全面开源,欢迎大家试用或转发推荐,详细代码库链接请戳下方链接或者点击阅读原文!
更多交流欢迎通过邮件pglbox@baidu.com与我们联系,感谢支持!
参考文献
图神经网络(Graph Neural Network,GNN)是近年来出现的一种利用深度学习直接对图结构数据进行学习的方法,通过在图中的节点和边上制定聚合的策略,GNN能够学习到图结构数据中节点以及边内在规律和更加深层次的语义特征。图神经网络不仅成为学术界研究热点,而且已经在工业界广泛应用落地。特别在搜索、推荐、地图等领域,采用大规模分布式图引擎对异构图结构进行建模,已经成为技术发展的新趋势。
目前,分布式图学习框架通常在CPU集群上部署分布式图服务以及参数服务器,来支持大规模图结构的存储以及特征的更新。然而,基于CPU算力的图学习框架在建设成本、训练速度、稳定性以及复杂算法支持等方面都存在不足。
因此,百度飞桨推出了能够同时支持复杂图学习算法+超大图+超大离散模型的GPU大规模图学习训练框架PGLBox。该框架结合了百度移动生态模型团队在大规模业务技术的深耕,凝聚飞桨图学习PGL丰富的算法能力与应用经验,并依托飞桨深度学习平台通用的训练框架能力与灵活组网能力,不仅继承了飞桨前期开源的Graph4Rec[1]超大规模、灵活易用和适用性广的优点[2],更是在训练性能、图算法能力支持方面获得了显著提升。
全面升级预置的图表示学习算法
基于PGLBox的GNN技术获得了NeurIPS 2022大规模GNN挑战赛冠军[3],同时入选了百度Create2022十大黑科技,并在WAVE SUMMIT+2022上作为飞桨2.4版本最重要的框架新特性之一发布。凭借其超高性能、超大规模、超强图学习算法、灵活易用等特性,PGLBox在百度内大量业务场景实现广泛应用并取得显著业务收益,如百度推荐系统、百度APP、百度搜索、百度网盘、小度平台等。
在哪里可以找到我们~
看到这里相信大家已经迫不及待想要开箱试用了吧!PGLBox已全面开源,欢迎大家试用或转发推荐,详细代码库链接请戳下方链接或者点击阅读原文!
更多交流欢迎通过邮件pglbox@baidu.com与我们联系,感谢支持!
参考文献
