


我是一个深度学习爱好者,目前对自然语言处理感兴趣,热衷于了解一些人工智能中的数学推导和经典论文复现,正在成长的“小趴菜”一枚,在PPDE指导计划中,创作了中医文献阅读理解项目,下面将由我介绍在项目创作过程中的一些思考。



{
2
"id": 98,
3
"text":
"黄帝道:什麽叫重实?岐伯说:所谓重实,如大热病人,邪气甚热,而脉象又盛满,内外俱实,便叫重实",
4
"annotations": [
5 {
6
"Q":
"重实是指什么?",
7
"A":
"所谓重实,如大热病人,邪气甚热,而脉象又盛满,内外俱实,便叫重实"
8 },
9 {
10
"Q":
"重实之人的脉象是什么样?",
11
"A":
"脉象又盛满"
12 }
13 ],
14
"source":
"黄帝内经翻译版"
15 }

PaddleNLP
RoBERTa阅读理解模型
训练时间更长,batch size更大,训练数据更多;
移除了next predict loss;
训练序列更长;
动态调整Masking机制。
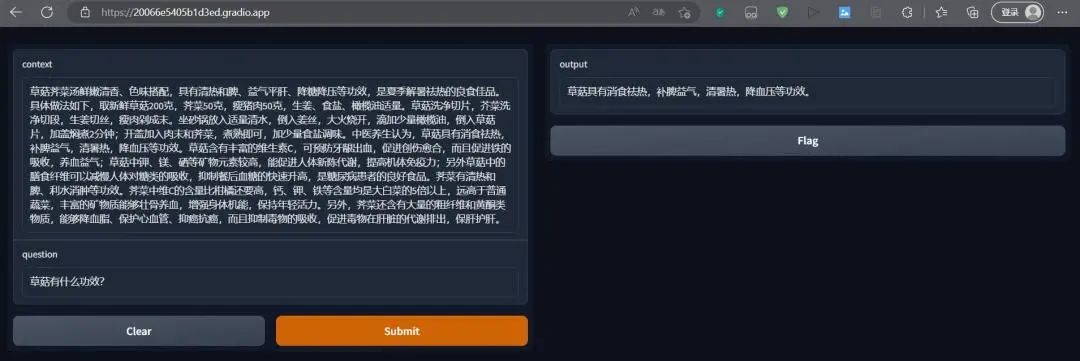
基于Gradio实现AI算法可视化部署
最终效果呈现


{
'id':
'xx',
'title':
'xxx',
'context':
'xxxx',
'question':
'xxxxx',
'answers': [
'xxxx'],
'answer_starts': [xxx]
}

设置Fine-tune优化策略
# 参数配置
# 训练过程中的最大学习率
learning_rate = 3e-5
# 训练轮次
epochs = 2
# 学习率预热比例
warmup_proportion = 0.1
# 权重衰减系数,类似模型正则项策略,避免模型过拟合
weight_decay = 0.01
num_training_steps = len(train_data_loader) * epochs
lr_scheduler = ppnlp.transformers.LinearDecayWithWarmup(learning_rate, num_training_steps, warmup_proportion)
# Generate parameter names needed to perform weight decay.
# All bias and LayerNorm parameters are excluded.
decay_params = [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in [
"bias",
"norm"])
]
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in decay_params)
设计损失函数
class CrossEntropyLossForSQuAD(paddle.nn.Layer):
def init (self):
super(CrossEntropyLossForSQuAD,
self). init ()
def forward(self, y, label):
start_logits, end_logits = y
# both shape are [batch_size, seq_len]
start_position, end_position = label
start_position = paddle.unsqueeze(start_position, axis=-
1) end_position = paddle.unsqueeze(end_position, axis=-
1)
start_loss = paddle.nn.functional.softmax_with_cross_entropy(
logits=start_logits, label=start_position, soft_label=False) start_loss = paddle.mean(start_loss)
end_loss = paddle.nn.functional.softmax_with_cross_entropy( logits=end_logits, label=end_position, soft_label=False)
end_loss = paddle.mean(end_loss)
loss = (start_loss + end_loss) /
2
return loss
模型训练


import Gradio
as gr
def question_answer(context, question):
pass
# Implement your question-answering model here...
gr.Interface(fn=question_answer, inputs=[
"text",
"text"], outputs=[
"textbox",
"text"]).launch(share=
True)



模型Benchmark地址
使用方法参考
数据
项目部署
模型优化
更多
开源项目地址
参考文献
我是一个深度学习爱好者,目前对自然语言处理感兴趣,热衷于了解一些人工智能中的数学推导和经典论文复现,正在成长的“小趴菜”一枚,在PPDE指导计划中,创作了中医文献阅读理解项目,下面将由我介绍在项目创作过程中的一些思考。
{
2
"id": 98,
3
"text":
"黄帝道:什麽叫重实?岐伯说:所谓重实,如大热病人,邪气甚热,而脉象又盛满,内外俱实,便叫重实",
4
"annotations": [
5 {
6
"Q":
"重实是指什么?",
7
"A":
"所谓重实,如大热病人,邪气甚热,而脉象又盛满,内外俱实,便叫重实"
8 },
9 {
10
"Q":
"重实之人的脉象是什么样?",
11
"A":
"脉象又盛满"
12 }
13 ],
14
"source":
"黄帝内经翻译版"
15 }
PaddleNLP
RoBERTa阅读理解模型
训练时间更长,batch size更大,训练数据更多;
移除了next predict loss;
训练序列更长;
动态调整Masking机制。
基于Gradio实现AI算法可视化部署
最终效果呈现
{
'id':
'xx',
'title':
'xxx',
'context':
'xxxx',
'question':
'xxxxx',
'answers': [
'xxxx'],
'answer_starts': [xxx]
}
设置Fine-tune优化策略
# 参数配置
# 训练过程中的最大学习率
learning_rate = 3e-5
# 训练轮次
epochs = 2
# 学习率预热比例
warmup_proportion = 0.1
# 权重衰减系数,类似模型正则项策略,避免模型过拟合
weight_decay = 0.01
num_training_steps = len(train_data_loader) * epochs
lr_scheduler = ppnlp.transformers.LinearDecayWithWarmup(learning_rate, num_training_steps, warmup_proportion)
# Generate parameter names needed to perform weight decay.
# All bias and LayerNorm parameters are excluded.
decay_params = [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in [
"bias",
"norm"])
]
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in decay_params)
设计损失函数
class CrossEntropyLossForSQuAD(paddle.nn.Layer):
def init (self):
super(CrossEntropyLossForSQuAD,
self). init ()
def forward(self, y, label):
start_logits, end_logits = y
# both shape are [batch_size, seq_len]
start_position, end_position = label
start_position = paddle.unsqueeze(start_position, axis=-
1) end_position = paddle.unsqueeze(end_position, axis=-
1)
start_loss = paddle.nn.functional.softmax_with_cross_entropy(
logits=start_logits, label=start_position, soft_label=False) start_loss = paddle.mean(start_loss)
end_loss = paddle.nn.functional.softmax_with_cross_entropy( logits=end_logits, label=end_position, soft_label=False)
end_loss = paddle.mean(end_loss)
loss = (start_loss + end_loss) /
2
return loss
模型训练
import Gradio
as gr
def question_answer(context, question):
pass
# Implement your question-answering model here...
gr.Interface(fn=question_answer, inputs=[
"text",
"text"], outputs=[
"textbox",
"text"]).launch(share=
True)
模型Benchmark地址
使用方法参考
数据
项目部署
模型优化
更多
开源项目地址
参考文献
