YOLO历史回顾


此次Ultralytics从YOLOv5到YOLOv8的升级,主要包括结构算法、命令行界面、Python API等,精度上YOLOv8相比YOLOv5高出一大截,但速度略有下降。
仅看检测方向的话,简单总结下YOLOv8在结构算法上相比YOLOv5的升级:
骨干网络部分
选用梯度流更丰富的C2f结构替换了YOLOv5中的C3结构,为了轻量化也缩减了骨干网络中最大stage的blocks数,同时不同缩放因子N/S/M/L/X的模型不再是共用一套模型参数,M/L/X大模型还缩减了最后一个stage的输出通道数,进一步减少参数量和计算量。
标签分配和Loss部分
从Anchor-Based换成了Anchor-Free,采用了TAL(Task Alignment Learning)动态匹配,并引入了DFL(Distribution Focal Loss)结合CIoU Loss做回归分支的损失函数,使得分类和回归任务之间具有较高的一致性。
训练策略
训练的数据增强部分最后10 epoch关闭Mosaic增强更有利于模型收敛的稳定,同时训练epoch数从300增大到500使得模型训练更充分。
就在YOLOv8发布的当晚,飞桨PaddleDetection团队就支持了YOLOv8的推理部署,并正在研发可训练版本中。
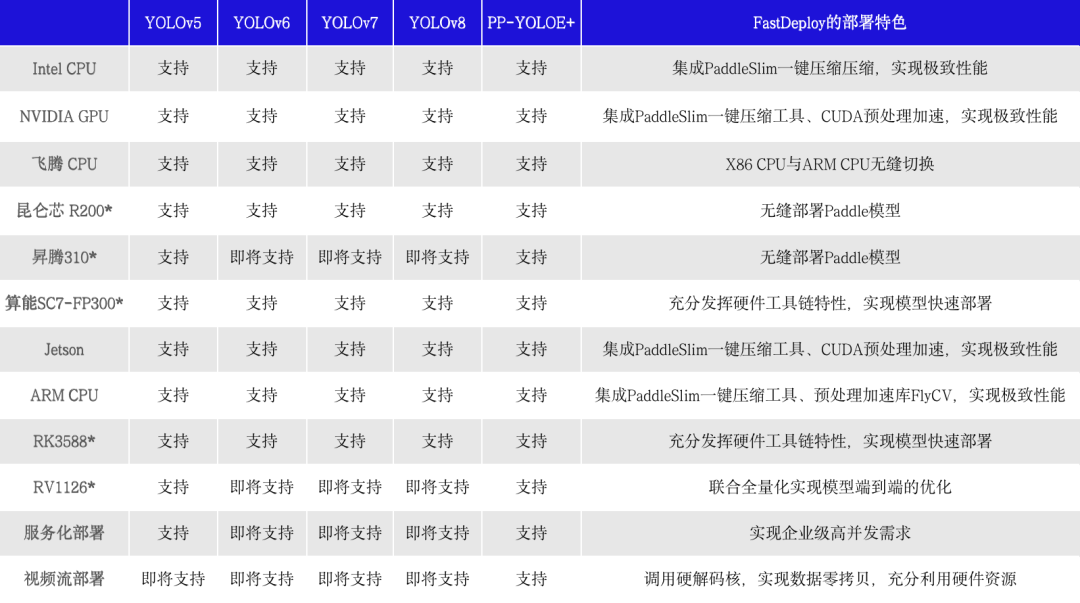
YOLO系列多硬件部署示例下载链接

为了方便统一YOLO系列模型的开发测试基准,以及模型选型,百度飞桨推出了PaddleYOLO开源模型库,支持YOLO系列模型一键快速切换,并提供对应ONNX模型文件,充分满足各类部署需求。
此外YOLOv5、YOLOv6、YOLOv7和YOLOv8在评估和部署过程中使用了不同的后处理配置,因而可能造成评估结果虚高,而这些模型在PaddleYOLO中实现了统一,保证实际部署效果和模型评估指标的一致性,并对这几类模型的代码进行了重构,统一了代码风格,提高了代码易读性。下面的讲解内容也将围绕PaddleYOLO相关测试数据进行分析。
总体来说,选择合适的模型,要明确自己项目的要求和标准,精度和速度一般是最重要的两个指标,但还有模型参数量、FLOPs计算量等也需要考虑。接下来就具体讲一讲这几个关键点。

看精度

看速度
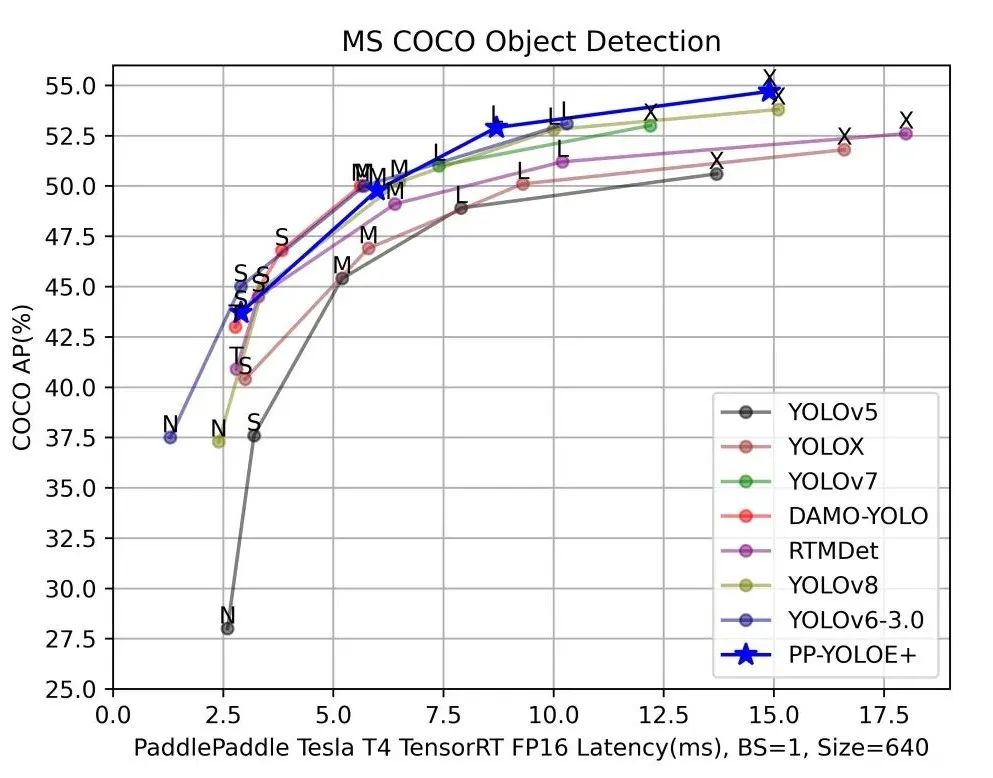
速度不像精度很快就能复现证明的,鉴于各大YOLO模型发布的测速环境也不同,还是得统一测试环境进行实测。上图是飞桨团队在飞桨框架对齐各大模型精度的基础上,统一在Tesla T4上开启TensorRT以FP16进行的测试。
另外需要注意的是,各大YOLO模型发布的速度只是纯模型速度,是去除NMS(非极大值抑制)的后处理和图片前处理的,实际应用端到端的耗时还是要加上NMS后处理和图片前处理的时间,以及将数据从CPU拷贝到GPU/XPU等加速卡上和将数据从加速卡拷贝到CPU的时间。通常NMS的参数对速度影响极大,尤其是score threshold(置信度阈值) 、NMS的IoU阈值、top-k框数(参与NMS的最多框数)以及max_dets(每张图保留的最多框数) 等参数。
比如最常用的是调score threshold,一般为了提高 Recall(召回率) 都会设置成0.001、0.01之类的,但其实这种置信度范围的低分框对实际应用来说意义不大;如果设置成0.1、0.2则会提前过滤掉众多的低分框,这样NMS速度和整个端到端部署的速度就会显著上升,代价是掉一些mAP,但对于结果可视化在视觉效果上其实影响很小。
总之实际应用中都需要自己实践,加上NMS等前后处理,不能只看论文中提供的纯模型速度。(具体可见下图"Part4. YOLO系列模型多硬件快速部署”实测数据)
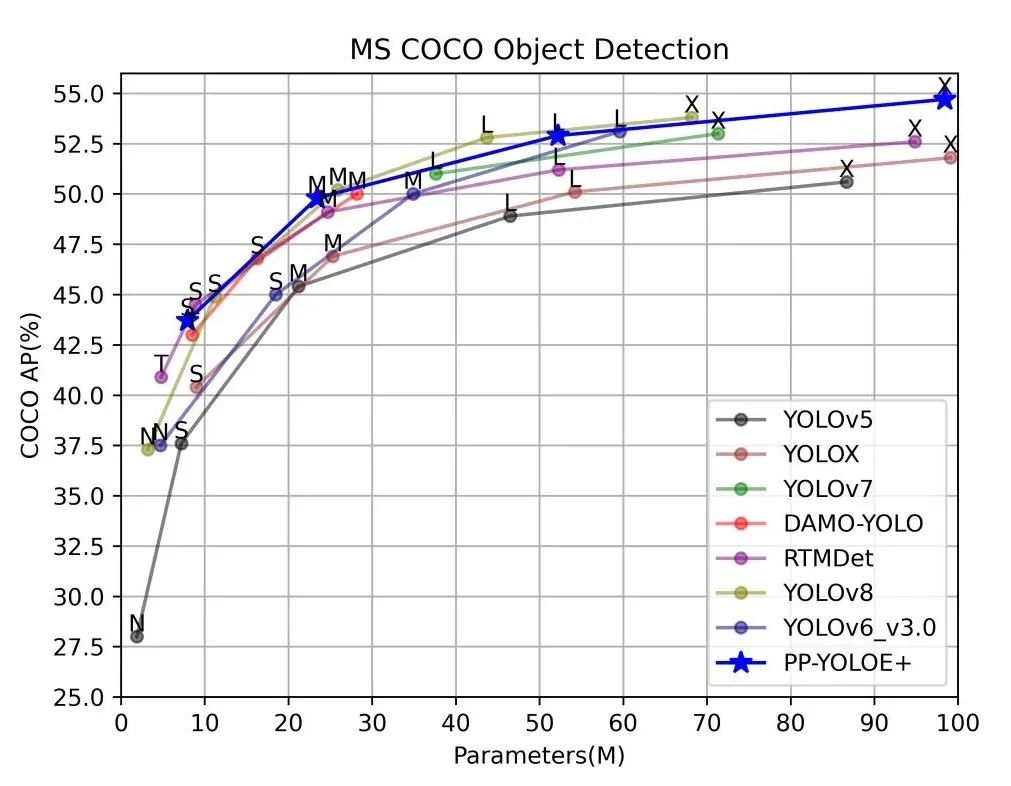
 看参数量、计算量
看参数量、计算量
这方面在学术研究场景中一般不会着重考虑,但是在产业应用场景中就非常重要,需要注意设备的硬件限制。例如堆叠一些模块结构来改造原模型,增加了2~3倍参数量提高了一点点mAP,这是AI竞赛常用的“套路”,精度虽然有少许提升,但速度变慢了很多,参数量和FLOPs也都变大了很多,对于产业应用来说意义不大,又如一些特殊模块,例如ConvNeXt,参数量极大但是FLOPs很小,虽然可以提升精度,但也会降低速度,参数量也可能受设备容量限制。
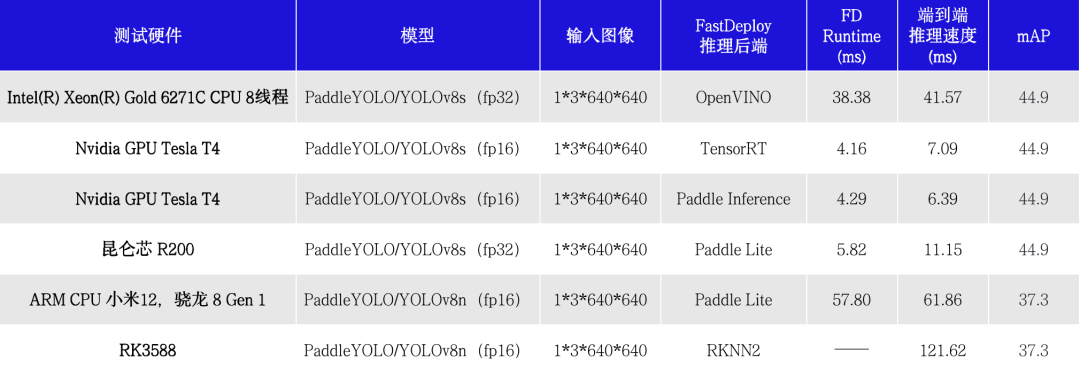
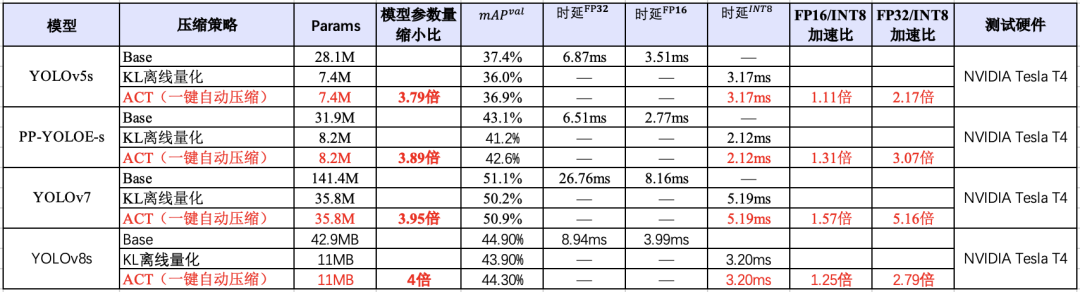
在对资源、显存及其敏感的场景,除了选择参数量较小的模型,也需要考虑和压缩工具联合使用。如下图所示,在YOLO系列模型上,使用PaddleSlim自动压缩工具(ACT)压缩后,可以在尽量保证精度的同时,降低模型大小和显存占用,并且该能力已经在飞桨全场景高性能AI部署工具FastDeploy中集成,实现一键压缩。
总之,在这YOLO“内卷时期”要保持平常心,无论新出来什么模型,都需要大致了解下改进点和优劣势后再谨慎选择,针对自己的需求选适合自己的模型。
 YOLO系列模型多硬件快速部署
YOLO系列模型多硬件快速部署
10+工业安防交通全流程项目实操(含源码)

YOLO历史回顾
此次Ultralytics从YOLOv5到YOLOv8的升级,主要包括结构算法、命令行界面、Python API等,精度上YOLOv8相比YOLOv5高出一大截,但速度略有下降。
仅看检测方向的话,简单总结下YOLOv8在结构算法上相比YOLOv5的升级:
骨干网络部分
选用梯度流更丰富的C2f结构替换了YOLOv5中的C3结构,为了轻量化也缩减了骨干网络中最大stage的blocks数,同时不同缩放因子N/S/M/L/X的模型不再是共用一套模型参数,M/L/X大模型还缩减了最后一个stage的输出通道数,进一步减少参数量和计算量。
标签分配和Loss部分
从Anchor-Based换成了Anchor-Free,采用了TAL(Task Alignment Learning)动态匹配,并引入了DFL(Distribution Focal Loss)结合CIoU Loss做回归分支的损失函数,使得分类和回归任务之间具有较高的一致性。
训练策略
训练的数据增强部分最后10 epoch关闭Mosaic增强更有利于模型收敛的稳定,同时训练epoch数从300增大到500使得模型训练更充分。
就在YOLOv8发布的当晚,飞桨PaddleDetection团队就支持了YOLOv8的推理部署,并正在研发可训练版本中。
YOLO系列多硬件部署示例下载链接
为了方便统一YOLO系列模型的开发测试基准,以及模型选型,百度飞桨推出了PaddleYOLO开源模型库,支持YOLO系列模型一键快速切换,并提供对应ONNX模型文件,充分满足各类部署需求。
此外YOLOv5、YOLOv6、YOLOv7和YOLOv8在评估和部署过程中使用了不同的后处理配置,因而可能造成评估结果虚高,而这些模型在PaddleYOLO中实现了统一,保证实际部署效果和模型评估指标的一致性,并对这几类模型的代码进行了重构,统一了代码风格,提高了代码易读性。下面的讲解内容也将围绕PaddleYOLO相关测试数据进行分析。
总体来说,选择合适的模型,要明确自己项目的要求和标准,精度和速度一般是最重要的两个指标,但还有模型参数量、FLOPs计算量等也需要考虑。接下来就具体讲一讲这几个关键点。
看精度
看速度
速度不像精度很快就能复现证明的,鉴于各大YOLO模型发布的测速环境也不同,还是得统一测试环境进行实测。上图是飞桨团队在飞桨框架对齐各大模型精度的基础上,统一在Tesla T4上开启TensorRT以FP16进行的测试。
另外需要注意的是,各大YOLO模型发布的速度只是纯模型速度,是去除NMS(非极大值抑制)的后处理和图片前处理的,实际应用端到端的耗时还是要加上NMS后处理和图片前处理的时间,以及将数据从CPU拷贝到GPU/XPU等加速卡上和将数据从加速卡拷贝到CPU的时间。通常NMS的参数对速度影响极大,尤其是score threshold(置信度阈值) 、NMS的IoU阈值、top-k框数(参与NMS的最多框数)以及max_dets(每张图保留的最多框数) 等参数。
比如最常用的是调score threshold,一般为了提高 Recall(召回率) 都会设置成0.001、0.01之类的,但其实这种置信度范围的低分框对实际应用来说意义不大;如果设置成0.1、0.2则会提前过滤掉众多的低分框,这样NMS速度和整个端到端部署的速度就会显著上升,代价是掉一些mAP,但对于结果可视化在视觉效果上其实影响很小。
总之实际应用中都需要自己实践,加上NMS等前后处理,不能只看论文中提供的纯模型速度。(具体可见下图"Part4. YOLO系列模型多硬件快速部署”实测数据)
看参数量、计算量
这方面在学术研究场景中一般不会着重考虑,但是在产业应用场景中就非常重要,需要注意设备的硬件限制。例如堆叠一些模块结构来改造原模型,增加了2~3倍参数量提高了一点点mAP,这是AI竞赛常用的“套路”,精度虽然有少许提升,但速度变慢了很多,参数量和FLOPs也都变大了很多,对于产业应用来说意义不大,又如一些特殊模块,例如ConvNeXt,参数量极大但是FLOPs很小,虽然可以提升精度,但也会降低速度,参数量也可能受设备容量限制。
在对资源、显存及其敏感的场景,除了选择参数量较小的模型,也需要考虑和压缩工具联合使用。如下图所示,在YOLO系列模型上,使用PaddleSlim自动压缩工具(ACT)压缩后,可以在尽量保证精度的同时,降低模型大小和显存占用,并且该能力已经在飞桨全场景高性能AI部署工具FastDeploy中集成,实现一键压缩。
总之,在这YOLO“内卷时期”要保持平常心,无论新出来什么模型,都需要大致了解下改进点和优劣势后再谨慎选择,针对自己的需求选适合自己的模型。
YOLO系列模型多硬件快速部署
10+工业安防交通全流程项目实操(含源码)