2016年9月,飞桨框架正式开源。飞桨框架建设并非只靠百度工程师,也离不开热爱飞桨、热爱开源的开发者们,他们用自己的方式参与飞桨框架建设,与飞桨共同成长。作为大型开源项目,飞桨社区十分欢迎各位开发者积极提出需求或不足,并主动提交pr解决。本文将由开发者李其睿介绍贡献API的经验。
感兴趣的同学可以直接参考PR:
C++部分
paddle/phi/kernels: 这个目录下是算子的实现部分,分别需要实现“.h”文件(头文件)、 “.cc”文件(CPU算子)、“.cu”文件(GPU算子) 这三个部分;
paddle/phi/infermeta: 这个目录下的文件是推理一个API的输出参数的meta数据,例如:数据维度、数据type等。该目录下有多个文件,根据算子输入Tensor的参数数量确定InferMeta函数放置位置,比如算子输入Tensor参数是0个,那推理函数需要放在nullary.cc/h中;如果是Tensor参数有2个,则需要放在binary.cc/h中;
Python部分
python/paddle/tensor/creation.py: 这个文件主要是用来构造该API在Python端调用时的接口,其中包含了入参的校验、算子的调用过程。另外英文版的API文档也在这里进行编写;
python/paddle/_init_.py:初始化文件;
文档
一个API的完整构建,除了代码的开发外,其文档的撰写也是非常必要的。飞桨的中文文档位于PaddlePaddle/docs仓库中。
docs/api/paddle/Overview_cn.rst中用一句话对API的功能进行简要概述;
撰写提案
关于设计,有以下几点需要注意:
正式开发
拉代码并成功编译
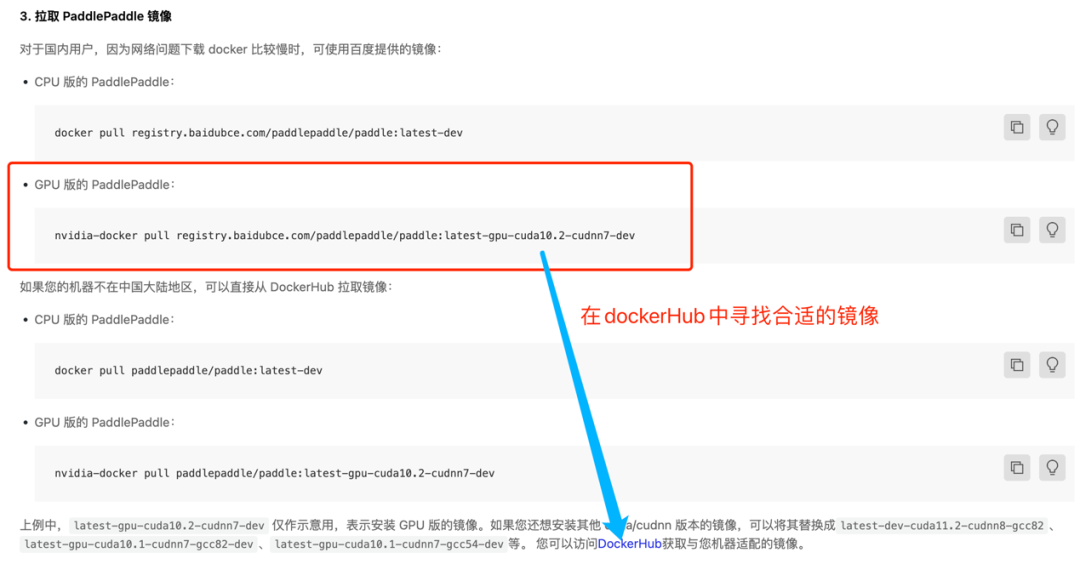
然后在Docker镜像内clone,并切换到develop分支(最好在做每个任务时从develop分支checkout一个新分支,会更方便)。
到此就可以正式开始写代码
kernel需要在phi这个命名空间下;
受Python书写习惯影响,有时会输出return。更好的方式是将输出需要用到的内存分配后作为参数传入kernel;
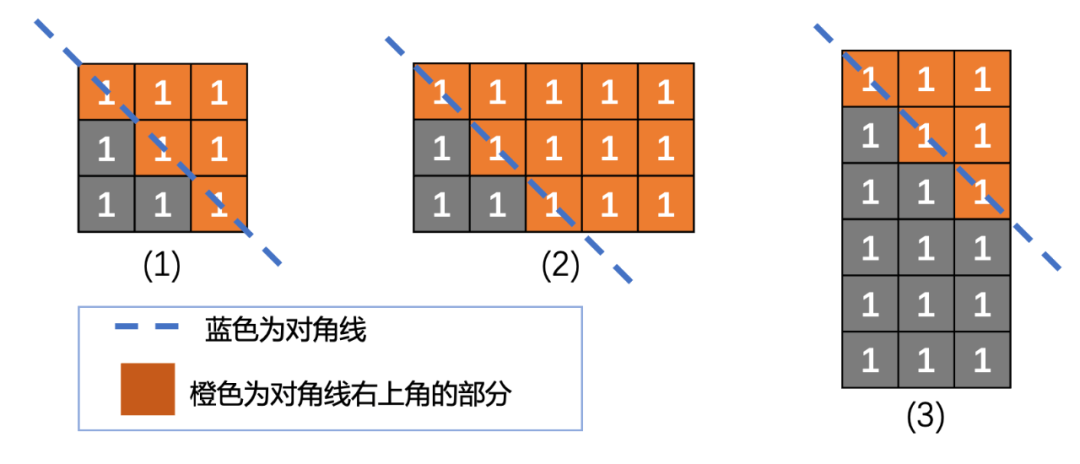
需要多关注边界条件,以及不要受惯性思维限制。比如Tensor不一定是正方形,对角线也不一定是主对角线,对于这类非常规情况的处理需要格外注意,这些情况可能也是需要代码量最多的地方(如下图所示);
第三步:接下来需要实现GPU端的kernel:triu_indices_kernel.cu。
两本入门书:《CUDA By Example》《Professional CUDA C Programming》
def triu_indices(row, col=None, offset=0, dtype='int64'):
"""
英文文档部分
"""
# 校验各入参类型
# 根据计算图类型引用算子
# 返回计算结果
)
return out
import paddle
data1 = paddle.triu_indices(
4,
4,
0)
print(data1)
Tensor(shape=[
2,
10], dtype=int64, place=Place(cpu), stop_gradient=True,
Output:
[[0, 0, 0, 0, 1, 1, 1, 2, 2, 3],
[0, 1, 2, 3, 1, 2, 3, 2, 3, 3]])
单测的编写
函数功能在各种参数配置下是否都正确,可以与NumPy、PyTorch进行比较;
函数在动态图、静态图中是否都可以正常使用;
函数是否能正常报错。
文档编写


2016年9月,飞桨框架正式开源。飞桨框架建设并非只靠百度工程师,也离不开热爱飞桨、热爱开源的开发者们,他们用自己的方式参与飞桨框架建设,与飞桨共同成长。作为大型开源项目,飞桨社区十分欢迎各位开发者积极提出需求或不足,并主动提交pr解决。本文将由开发者李其睿介绍贡献API的经验。
感兴趣的同学可以直接参考PR:
C++部分
paddle/phi/kernels: 这个目录下是算子的实现部分,分别需要实现“.h”文件(头文件)、 “.cc”文件(CPU算子)、“.cu”文件(GPU算子) 这三个部分;
paddle/phi/infermeta: 这个目录下的文件是推理一个API的输出参数的meta数据,例如:数据维度、数据type等。该目录下有多个文件,根据算子输入Tensor的参数数量确定InferMeta函数放置位置,比如算子输入Tensor参数是0个,那推理函数需要放在nullary.cc/h中;如果是Tensor参数有2个,则需要放在binary.cc/h中;
Python部分
python/paddle/tensor/creation.py: 这个文件主要是用来构造该API在Python端调用时的接口,其中包含了入参的校验、算子的调用过程。另外英文版的API文档也在这里进行编写;
python/paddle/_init_.py:初始化文件;
文档
一个API的完整构建,除了代码的开发外,其文档的撰写也是非常必要的。飞桨的中文文档位于PaddlePaddle/docs仓库中。
docs/api/paddle/Overview_cn.rst中用一句话对API的功能进行简要概述;
撰写提案
关于设计,有以下几点需要注意:
正式开发
拉代码并成功编译
然后在Docker镜像内clone,并切换到develop分支(最好在做每个任务时从develop分支checkout一个新分支,会更方便)。
到此就可以正式开始写代码
kernel需要在phi这个命名空间下;
受Python书写习惯影响,有时会输出return。更好的方式是将输出需要用到的内存分配后作为参数传入kernel;
需要多关注边界条件,以及不要受惯性思维限制。比如Tensor不一定是正方形,对角线也不一定是主对角线,对于这类非常规情况的处理需要格外注意,这些情况可能也是需要代码量最多的地方(如下图所示);
第三步:接下来需要实现GPU端的kernel:triu_indices_kernel.cu。
两本入门书:《CUDA By Example》《Professional CUDA C Programming》
def triu_indices(row, col=None, offset=0, dtype='int64'):
"""
英文文档部分
"""
# 校验各入参类型
# 根据计算图类型引用算子
# 返回计算结果
)
return out
import paddle
data1 = paddle.triu_indices(
4,
4,
0)
print(data1)
Tensor(shape=[
2,
10], dtype=int64, place=Place(cpu), stop_gradient=True,
Output:
[[0, 0, 0, 0, 1, 1, 1, 2, 2, 3],
[0, 1, 2, 3, 1, 2, 3, 2, 3, 3]])
单测的编写
函数功能在各种参数配置下是否都正确,可以与NumPy、PyTorch进行比较;
函数在动态图、静态图中是否都可以正常使用;
函数是否能正常报错。
文档编写