►►►
飞桨开源框架2.4版发布
以底层技术创新持续优化性能表现
►►►
端到端大模型开发套件
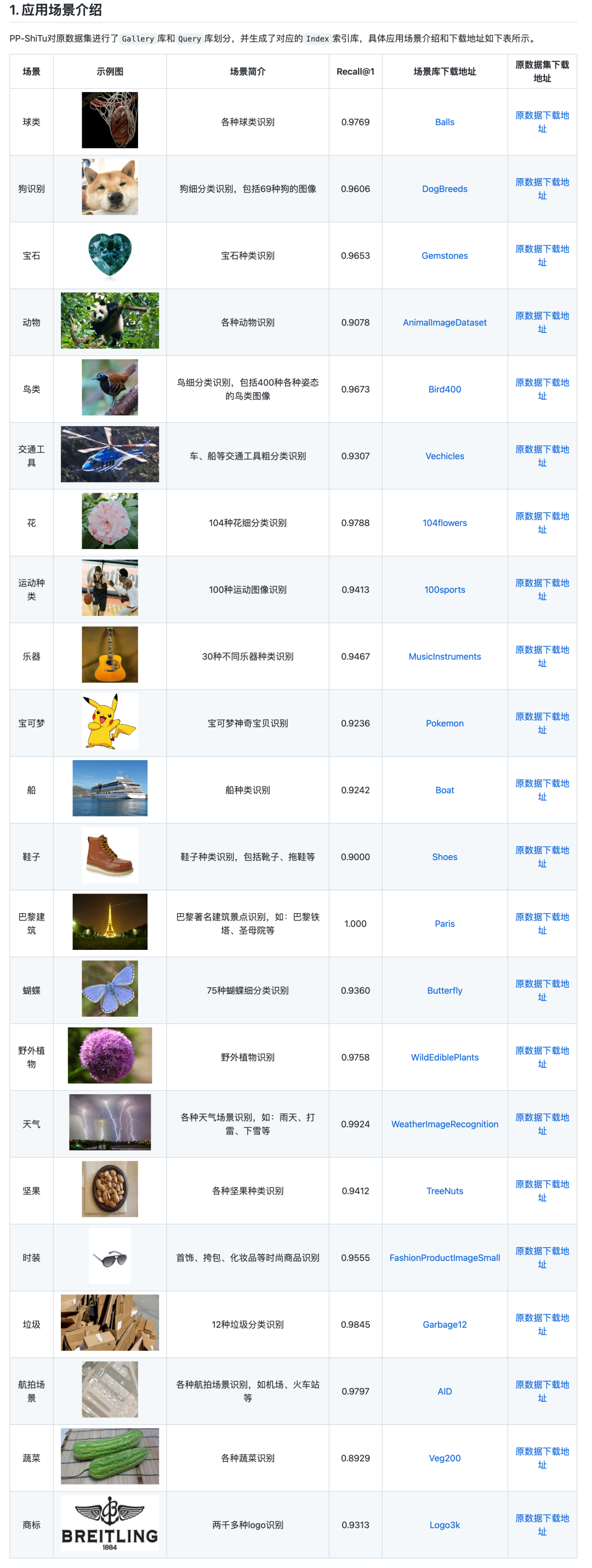
PaddleFleetX重磅发布
PaddleFleetX无缝对接飞桨并行策略并支持定制化组合,可以扩展支持更多类型的大模型,开发者可以根据模型结构的特点自行选择并行策略组合,并且支持GPU/NPU/DCU等多硬件平台的多云环境的训练调试。同时,PaddleFleetX还支持自适应分布式推理技术,真正做到了分布式策略的训推一体,大可支持超大模型的服务化部署,小可协同训压推结合的丰富小型化策略,实现端侧轻量化部署。
►►►
全场景高性能AI部署工具FastDeploy
三行代码搞定150+模型部署
https://github.com/PaddlePaddle/FastDeploy
►►►
飞桨图像分割开源套件
PaddleSeg重磅升级!
开源NeurIPS 2022顶会发表的语义分割官方实现模型RTFormer,结合CNN和Transformer的优点,该模型设计并使用了高效的RTFormer Block。对比其他实时语义分割模型,RTFormer在多个数据集上实现SOTA精度和速度。
针对标注数据的难题,发布智能标注平台EISeg正式版,支持医疗、遥感、工业质检等领域的分割标注,新增视频分割标注,分割标注效率提升超过过10倍。
针对人像分割场景,发布实时人像分割SOTA方案PP-HumanSegV2,推理
速度提升87.15%,分割精度达到96.63%,可视化效果更佳,可与商业收方费方案媲美。
针对抠图场景,发布百度自研轻量级抠图模型PP-MattingV2,推理速度提升44.6%,平均误差减小17.91%,超越此前SOTA模型,支持零成本开箱即用,并构建了Matting模型库和Benchmark。
►►►
飞桨文字识别套件PaddleOCR发布PP-StructureV2智能文档分析系统

关键信息抽取:设计视觉无关模型结构,语义实体识别精度提升2.8%,关系抽取精度提升超过9.1%。
►►►
车辆分析工具
Paddle-Vehicle开源上新
 PP-Vehicle功能全景图
PP-Vehicle功能全景图
►►►
较YOLOv7精度提升1.9%
54.7mAP的PP-YOLOE+强势登场
PP-YOLOE+是基于飞桨云边一体高精度模型PP-YOLOE迭代优化升级的版本,具备以下特点:
超强性能
训练收敛加速:使用Objects365预训练模型,减少训练轮数,训练收敛速度提升3.75倍。
下游任务泛化性显著提升:在农业、夜间安防、工业等不同场景数据集上验证,精度最高提升8.1%。
高性能部署能力:本次升级PP-YOLOE+支持多种部署方式,包括Python/C++、Serving、ONNX Runtime、ONNX-TRT、INT8量化等部署能力。
►►►
三行代码建模,训练虚度提升200%
时序预测神器PaddleTS开源!
效果好:时序专属的自动建模与集成预测效果突出
https://github.com/PaddlePaddle/PaddleTS/
►►►
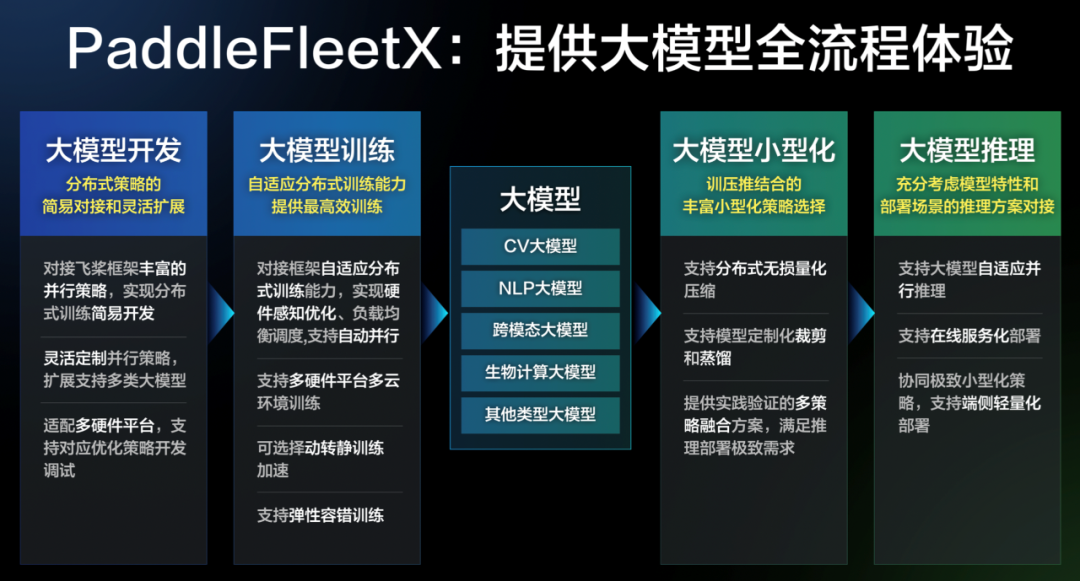
AI模型自动压缩工具
两行代码完成AI模型压缩

►►►
无需训练、APP可玩
商品、车辆、菜品20+场景一键识别
难点一:针对海量数据,不同场景均实现优秀的表征能力,能否一套方案全搞定?
难点二:不同物品的差别极其微小,或者同类物品由于受到外界干扰却呈现不同形态,究竟如何进行有效区分?
难点三:识别需求更新频繁,使用单一模型必须不断重训模型,怎样才能降低开发成本,快速跟上迭代步伐?
上下滑动查看更多应用场景
►►►
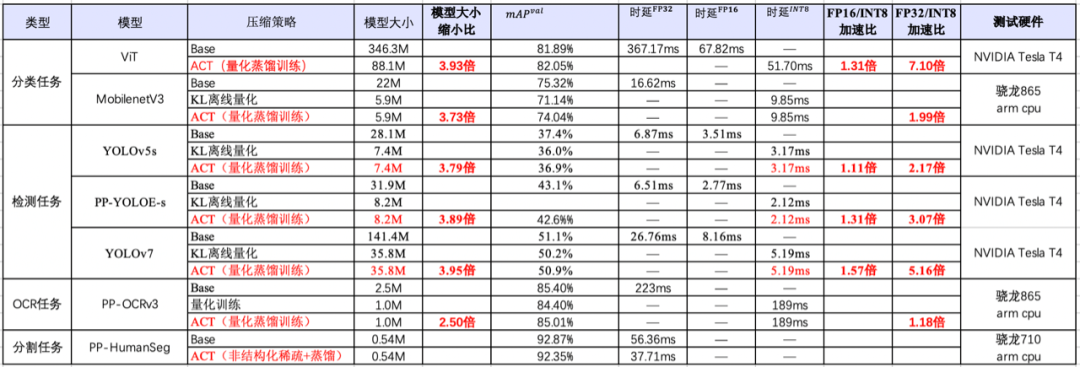
PaddleNLP重大升级!覆盖信息抽取、文本分类、语义检索等领域
对于复杂目标,可以标注少量数据(Few-shot)进行模型训练,以进一步提升效果。PaddleNLP打通了从数据标注-训练-部署全流程,方便大家进行定制化训练。以金融领域事件抽取任务为例,仅仅标注5条样本,F1值就提升了25个点!
1.文心ERNIE-Layout多语言版跨模态布局增强文档预训练大模型
2.DocPrompt开放文档抽取问答模型(基于文心ERNIE-Layout)
►►►
定制音库成本骤降98%
PaddleSpeech小样本语音合成方案
随着以语音为交互渠道的产业不断升级,企业对语音合成有着越来越多的需求,比如智能语音助手、手机地图导航、有声书播报等场景都需要用到语音合成技术。通过语音合成技术想要得到一个新的音色,需要定制音库,但是定制音库所耗费的人力成本和时间成本巨大,成为产业升级的屏障。
语音-语言跨模态大模型文心ERNIE-SAT:采用语音-文本联合训练的方式在多语言的数据集上训练,合成声音更加自然,可以承接多种下游任务,支持个性化合成、跨语言合成、语音编辑,可有效降低定制化音库所需数据量。
【AI产业应用技术方案和学习资料大礼包】
✅OCR场景应用模型库
✅10+工业安防交通全流程项目实操(含代码)
✅PaddleNLP历史直播课合集
✅分割垂类场景解决方案
✅PaddleSpeech语音技术实战
✅图像分类课程回访与优秀项目集锦




►►►
飞桨开源框架2.4版发布
以底层技术创新持续优化性能表现
►►►
端到端大模型开发套件
PaddleFleetX重磅发布
PaddleFleetX无缝对接飞桨并行策略并支持定制化组合,可以扩展支持更多类型的大模型,开发者可以根据模型结构的特点自行选择并行策略组合,并且支持GPU/NPU/DCU等多硬件平台的多云环境的训练调试。同时,PaddleFleetX还支持自适应分布式推理技术,真正做到了分布式策略的训推一体,大可支持超大模型的服务化部署,小可协同训压推结合的丰富小型化策略,实现端侧轻量化部署。
►►►
全场景高性能AI部署工具FastDeploy
三行代码搞定150+模型部署
https://github.com/PaddlePaddle/FastDeploy
►►►
飞桨图像分割开源套件
PaddleSeg重磅升级!
开源NeurIPS 2022顶会发表的语义分割官方实现模型RTFormer,结合CNN和Transformer的优点,该模型设计并使用了高效的RTFormer Block。对比其他实时语义分割模型,RTFormer在多个数据集上实现SOTA精度和速度。
针对标注数据的难题,发布智能标注平台EISeg正式版,支持医疗、遥感、工业质检等领域的分割标注,新增视频分割标注,分割标注效率提升超过过10倍。
针对人像分割场景,发布实时人像分割SOTA方案PP-HumanSegV2,推理
速度提升87.15%,分割精度达到96.63%,可视化效果更佳,可与商业收方费方案媲美。
针对抠图场景,发布百度自研轻量级抠图模型PP-MattingV2,推理速度提升44.6%,平均误差减小17.91%,超越此前SOTA模型,支持零成本开箱即用,并构建了Matting模型库和Benchmark。
►►►
飞桨文字识别套件PaddleOCR发布PP-StructureV2智能文档分析系统
关键信息抽取:设计视觉无关模型结构,语义实体识别精度提升2.8%,关系抽取精度提升超过9.1%。
►►►
车辆分析工具
Paddle-Vehicle开源上新
PP-Vehicle功能全景图
►►►
较YOLOv7精度提升1.9%
54.7mAP的PP-YOLOE+强势登场
PP-YOLOE+是基于飞桨云边一体高精度模型PP-YOLOE迭代优化升级的版本,具备以下特点:
超强性能
训练收敛加速:使用Objects365预训练模型,减少训练轮数,训练收敛速度提升3.75倍。
下游任务泛化性显著提升:在农业、夜间安防、工业等不同场景数据集上验证,精度最高提升8.1%。
高性能部署能力:本次升级PP-YOLOE+支持多种部署方式,包括Python/C++、Serving、ONNX Runtime、ONNX-TRT、INT8量化等部署能力。
►►►
三行代码建模,训练虚度提升200%
时序预测神器PaddleTS开源!
效果好:时序专属的自动建模与集成预测效果突出
https://github.com/PaddlePaddle/PaddleTS/
►►►
AI模型自动压缩工具
两行代码完成AI模型压缩
►►►
无需训练、APP可玩
商品、车辆、菜品20+场景一键识别
难点一:针对海量数据,不同场景均实现优秀的表征能力,能否一套方案全搞定?
难点二:不同物品的差别极其微小,或者同类物品由于受到外界干扰却呈现不同形态,究竟如何进行有效区分?
难点三:识别需求更新频繁,使用单一模型必须不断重训模型,怎样才能降低开发成本,快速跟上迭代步伐?
上下滑动查看更多应用场景
►►►
PaddleNLP重大升级!覆盖信息抽取、文本分类、语义检索等领域
对于复杂目标,可以标注少量数据(Few-shot)进行模型训练,以进一步提升效果。PaddleNLP打通了从数据标注-训练-部署全流程,方便大家进行定制化训练。以金融领域事件抽取任务为例,仅仅标注5条样本,F1值就提升了25个点!
1.文心ERNIE-Layout多语言版跨模态布局增强文档预训练大模型
2.DocPrompt开放文档抽取问答模型(基于文心ERNIE-Layout)
►►►
定制音库成本骤降98%
PaddleSpeech小样本语音合成方案
随着以语音为交互渠道的产业不断升级,企业对语音合成有着越来越多的需求,比如智能语音助手、手机地图导航、有声书播报等场景都需要用到语音合成技术。通过语音合成技术想要得到一个新的音色,需要定制音库,但是定制音库所耗费的人力成本和时间成本巨大,成为产业升级的屏障。
语音-语言跨模态大模型文心ERNIE-SAT:采用语音-文本联合训练的方式在多语言的数据集上训练,合成声音更加自然,可以承接多种下游任务,支持个性化合成、跨语言合成、语音编辑,可有效降低定制化音库所需数据量。
【AI产业应用技术方案和学习资料大礼包】
✅OCR场景应用模型库
✅10+工业安防交通全流程项目实操(含代码)
✅PaddleNLP历史直播课合集
✅分割垂类场景解决方案
✅PaddleSpeech语音技术实战
✅图像分类课程回访与优秀项目集锦