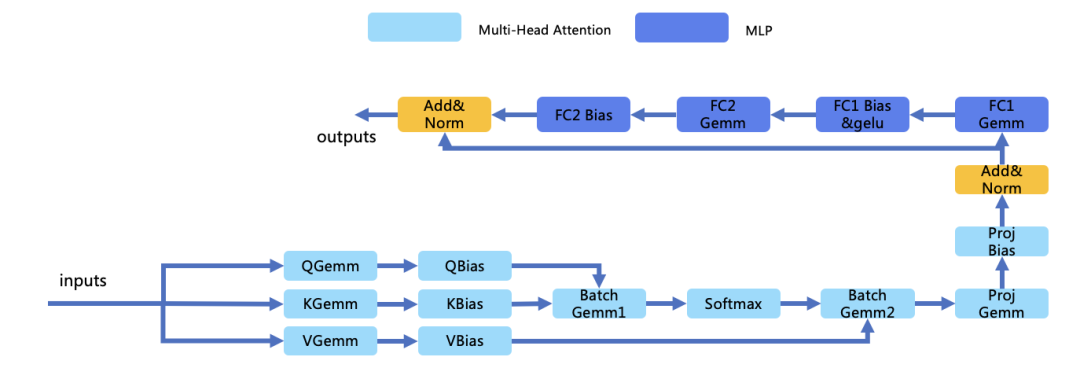
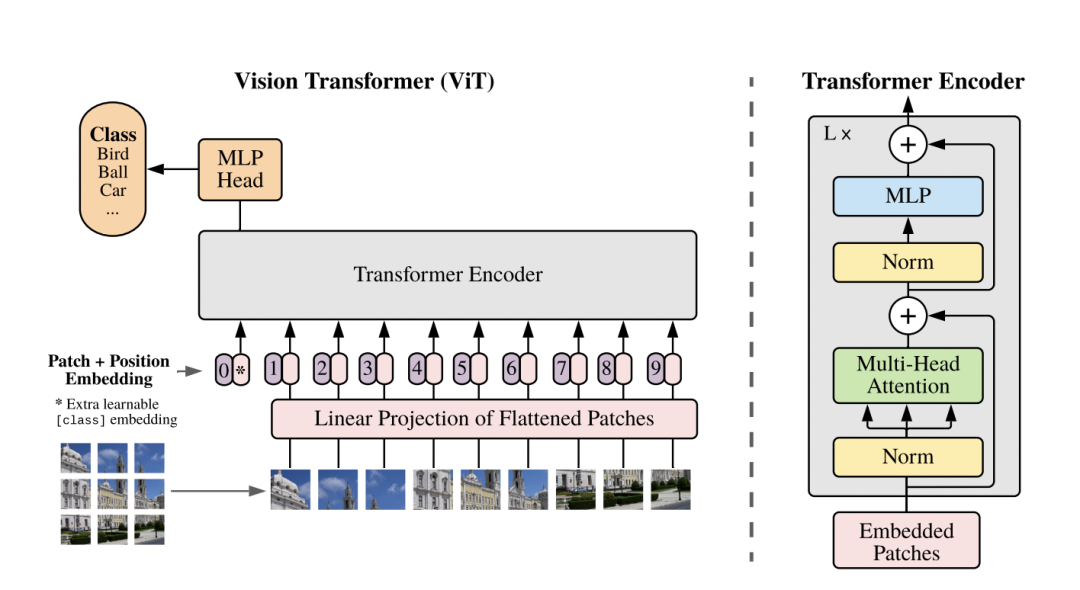
ViT模型结构分析
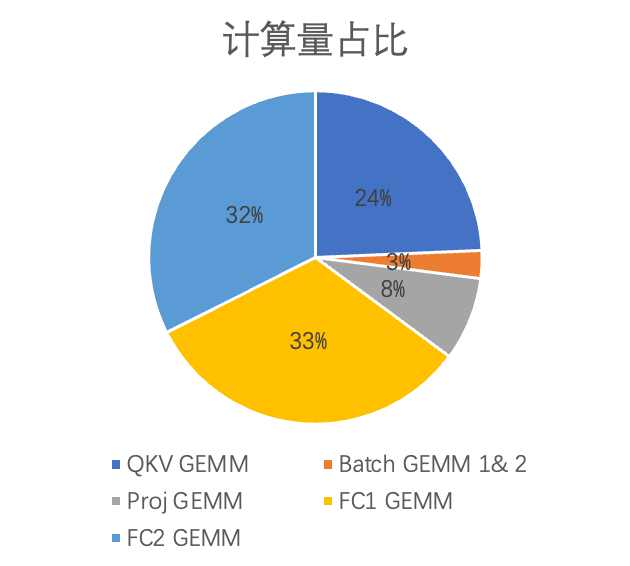
计算量分析
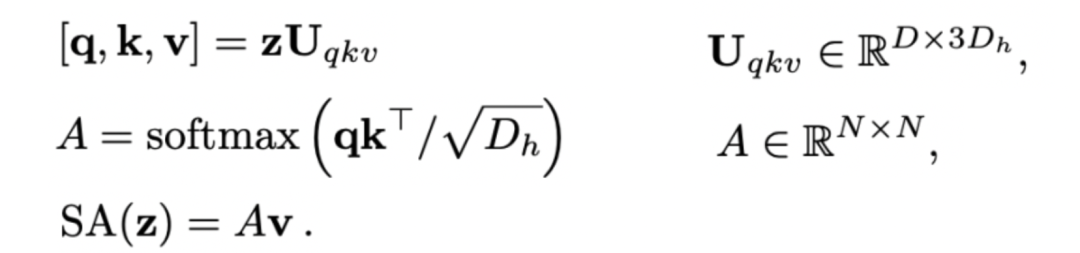
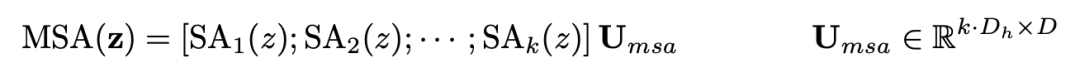
MLP计算公式如下:
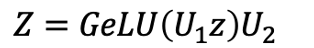
量化
方式一:离线量化
剪枝
蒸馏
准备待压缩模型
准备数据读取模块
from ppcls.data import build_dataloader
data_config = config.get_config(global_config['reader_config'], show=False)
train_loader = build_dataloader(data_config[
"DataLoader"],
"Train", device)
定义策略配置文件
策略自动组合
策略组合一:量化蒸馏训练配置
1
Distillation: #蒸馏
2
node: softmax_12.tmp_0
3
4
QuantAware: #量化
5
use_pact: true
6
onnx_format: true
7
quantize_op_types: [conv2d, matmul_v2]
1
Distillation:
2
node: softmax_12.tmp_0
3
TransformerPrune:
4
pruned_ratio: 0.25
策略自动选择
完整ViT自动压缩量化压缩配置文件链接:
两行核心自动压缩代码
1ac=AutoCompression(model_dir=global_config[
'model_dir'],
2 model_filename=global_config[
'model_filename'],
3 params_filename=global_config[
'params_filename'],
4 save_dir=args.save_dir,
5 config=all_config,
6 train_dataloader=train_dataloader,
7 eval_callback=eval_function
if rank_id==
0
else
None,
8 eval_dataloader=eval_dataloader)
9ac.compress()
算子融合
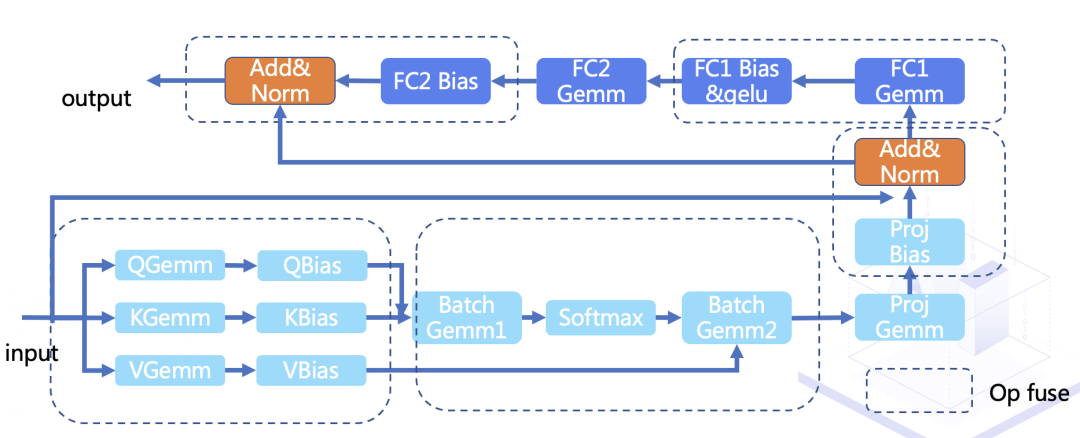
基于硬件特性调优
实现高效计算算子

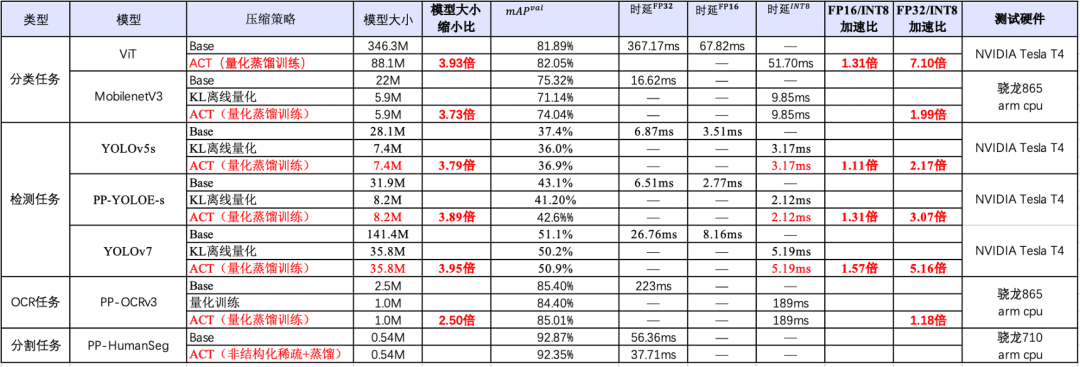
飞桨自动化压缩工具ACT将支持更多AI模型的压缩,扩展支持的模型数量和应用场景。
将ACT的各种能力(包括模型剪枝、非结构化稀疏等压缩方法)在不同类型模型上进行验证。
升级ACT能力,增加更多前沿的压缩算法。
支持完善更多部署方法,包括ONNX Runtime、OpenVINO等,进一步助力AI模型工程落地。
项目地址
GitHub
Gitee
参考文献

ViT模型结构分析
计算量分析
MLP计算公式如下:
量化
方式一:离线量化
剪枝
蒸馏
准备待压缩模型
准备数据读取模块
from ppcls.data import build_dataloader
data_config = config.get_config(global_config['reader_config'], show=False)
train_loader = build_dataloader(data_config[
"DataLoader"],
"Train", device)
定义策略配置文件
策略自动组合
策略组合一:量化蒸馏训练配置
1
Distillation: #蒸馏
2
node: softmax_12.tmp_0
3
4
QuantAware: #量化
5
use_pact: true
6
onnx_format: true
7
quantize_op_types: [conv2d, matmul_v2]
1
Distillation:
2
node: softmax_12.tmp_0
3
TransformerPrune:
4
pruned_ratio: 0.25
策略自动选择
完整ViT自动压缩量化压缩配置文件链接:
两行核心自动压缩代码
1ac=AutoCompression(model_dir=global_config[
'model_dir'],
2 model_filename=global_config[
'model_filename'],
3 params_filename=global_config[
'params_filename'],
4 save_dir=args.save_dir,
5 config=all_config,
6 train_dataloader=train_dataloader,
7 eval_callback=eval_function
if rank_id==
0
else
None,
8 eval_dataloader=eval_dataloader)
9ac.compress()
算子融合
基于硬件特性调优
实现高效计算算子
飞桨自动化压缩工具ACT将支持更多AI模型的压缩,扩展支持的模型数量和应用场景。
将ACT的各种能力(包括模型剪枝、非结构化稀疏等压缩方法)在不同类型模型上进行验证。
升级ACT能力,增加更多前沿的压缩算法。
支持完善更多部署方法,包括ONNX Runtime、OpenVINO等,进一步助力AI模型工程落地。
项目地址
GitHub
Gitee
参考文献