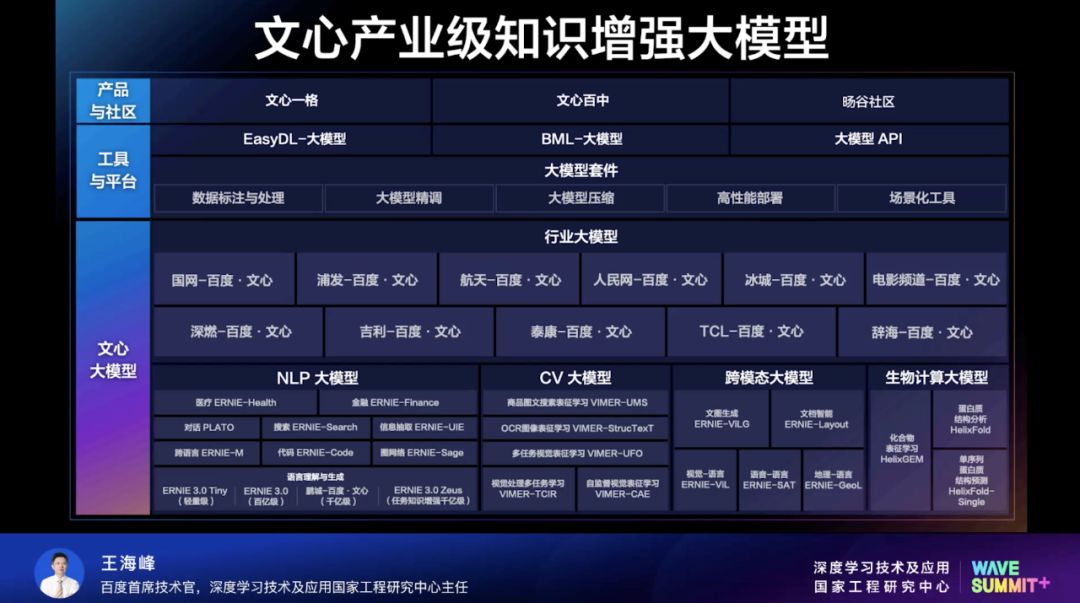
高文院士指出,开发者是开源生态发展的核心力量,也是技术创新的骨干力量。现阶段,建设好我国自主创新的软硬件基础平台至关重要。飞桨全面开源开放,凝聚众多开发者,核心技术扎实,面向产业做了很多领先的工作,并积极探索与科学计算等基础研究的结合。文心多个大模型将上线鹏城云脑,并联合发布飞桨-鹏城云脑发行版。
丁文华院士在致辞中表示,深度学习技术及应用国家工程研究中心,是国家科技创新体系的重要组成部分。飞桨平台作为工程研究中心的核心研究成果,在保障国家信息科技安全、推动人工智能应用大规模落地方面发挥了重要作用。AI领域的底层核心技术,发展主动权必须掌握在自己手里。具有自主知识产权的核心技术,是核心竞争力的源头活水。
王海峰公布了飞桨生态的最新进展:截至目前,飞桨已凝聚535万开发者,服务20万家企事业单位,基于飞桨创建了67万个模型。开发者、科研院所、企事业单位、技术伙伴、硬件厂商等等,既是飞桨生态的建设者,也是受益者。飞桨构建了全方位的生态体系,产学研协同,共创、共生、共赢。

大模型产业化夯实数实融合基座
“让大模型的落地像流水线一样高效”
在大模型迅猛发展的当下,支撑大模型开发、训练和推理部署的飞桨深度学习平台也在持续进化,优势更加显著:动静统一的开发范式、自适应分布式架构、异构设备负载均衡等,实现大模型的灵活开发和高效训练;高并发弹性服务化部署、软硬协同稀疏量化加速、自适应蒸馏裁剪等,实现高效部署。
高文院士指出,开发者是开源生态发展的核心力量,也是技术创新的骨干力量。现阶段,建设好我国自主创新的软硬件基础平台至关重要。飞桨全面开源开放,凝聚众多开发者,核心技术扎实,面向产业做了很多领先的工作,并积极探索与科学计算等基础研究的结合。文心多个大模型将上线鹏城云脑,并联合发布飞桨-鹏城云脑发行版。
丁文华院士在致辞中表示,深度学习技术及应用国家工程研究中心,是国家科技创新体系的重要组成部分。飞桨平台作为工程研究中心的核心研究成果,在保障国家信息科技安全、推动人工智能应用大规模落地方面发挥了重要作用。AI领域的底层核心技术,发展主动权必须掌握在自己手里。具有自主知识产权的核心技术,是核心竞争力的源头活水。
王海峰公布了飞桨生态的最新进展:截至目前,飞桨已凝聚535万开发者,服务20万家企事业单位,基于飞桨创建了67万个模型。开发者、科研院所、企事业单位、技术伙伴、硬件厂商等等,既是飞桨生态的建设者,也是受益者。飞桨构建了全方位的生态体系,产学研协同,共创、共生、共赢。
大模型产业化夯实数实融合基座
“让大模型的落地像流水线一样高效”
在大模型迅猛发展的当下,支撑大模型开发、训练和推理部署的飞桨深度学习平台也在持续进化,优势更加显著:动静统一的开发范式、自适应分布式架构、异构设备负载均衡等,实现大模型的灵活开发和高效训练;高并发弹性服务化部署、软硬协同稀疏量化加速、自适应蒸馏裁剪等,实现高效部署。