


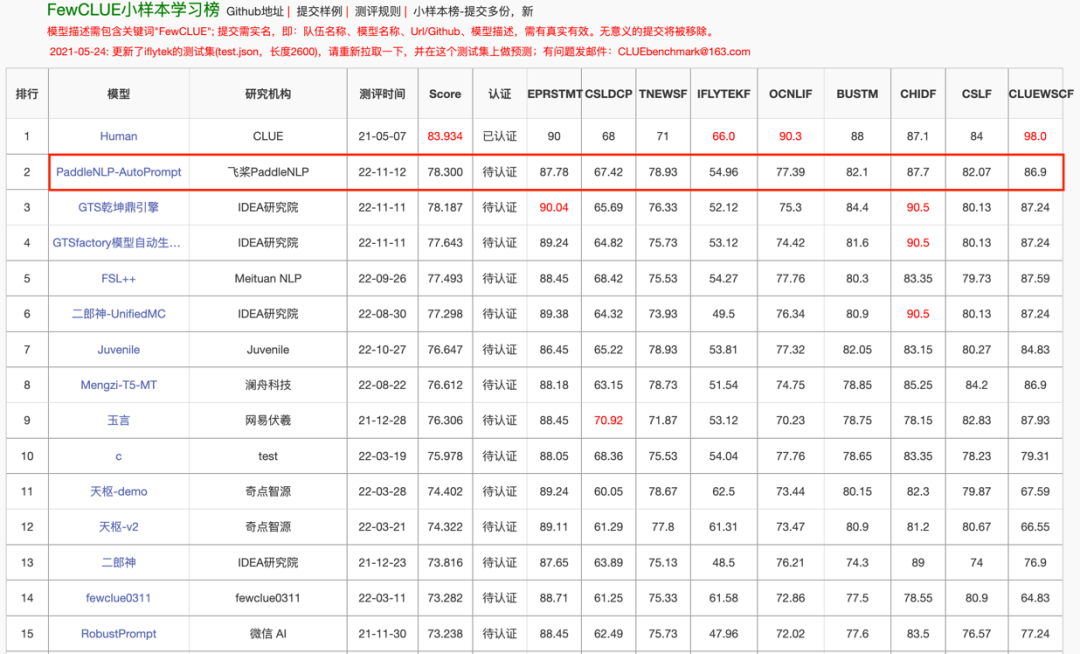
为什么选择
提示学习

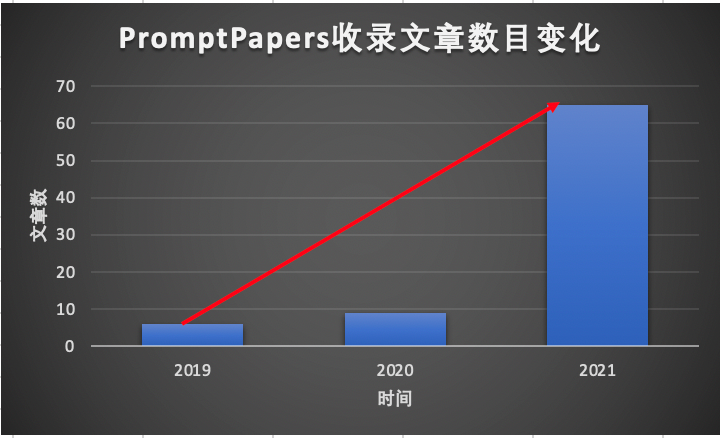
AutoPrompt的优势
灵活
Template String延续了字典结构设计,支持更丰富的提示设计,以满足不同任务的需求。预训练模型、Template、Verbalizer等实现模块化,支持各种灵活扩展。
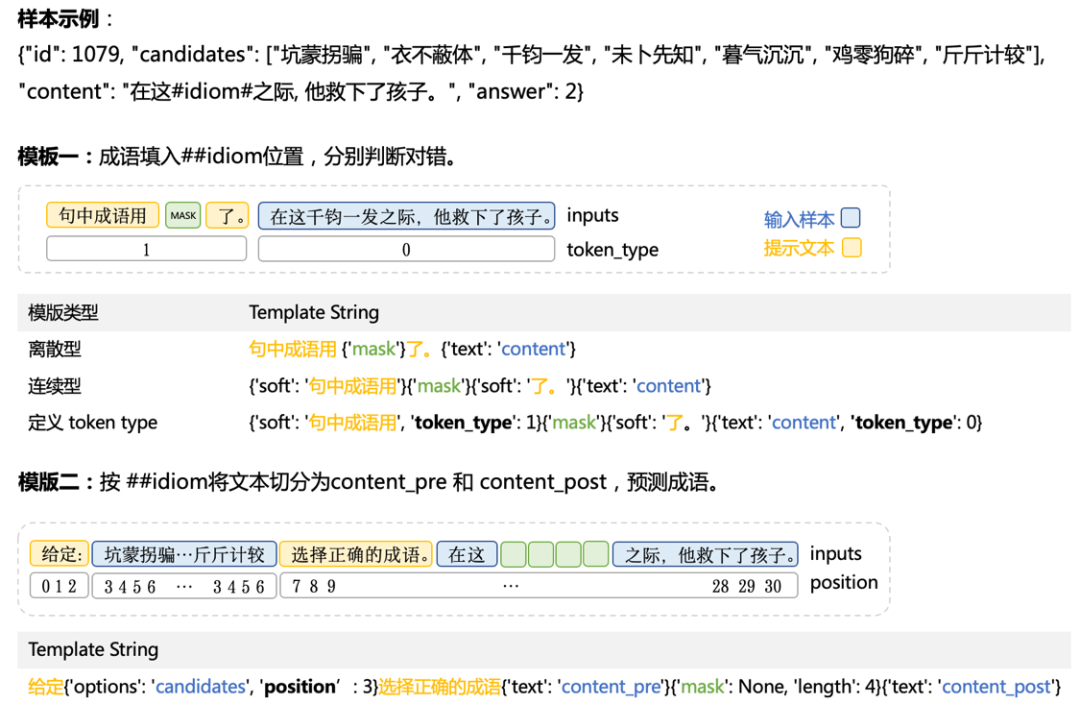
AutoPrompt支持多种prompt定义
易用
自动化
只需要准备相应格式的数据,定义模型、数据、策略的配置参数,以及Template String文件,即可一键运行。AutoPrompt框架可自动从定义的Template String中选择最佳Prompt,保存效果最优的模型。

AutoPrompt框架使用流程
技术私享会
11月17日,PaddleNLP工程师,AutoPrompt作者将在线分享提示学习相关前沿技术、AutoPrompt的“自动化”理念、FewCLUE打榜经验、以及提示学习产业落地案例,欢迎有兴趣的朋友扫码报名活动,参与线上交流。(为保证交流效果,限100席位)
FewCLUE
小样本学习实践

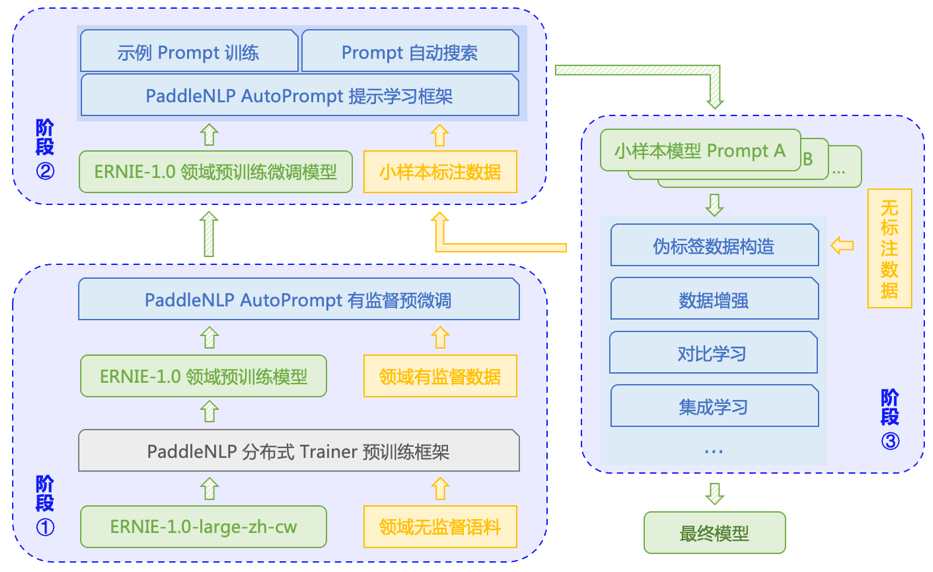
阶段一 :领域预训练
阶段二:提示学习
阶段三:数据增强&集成学习
领域预训练
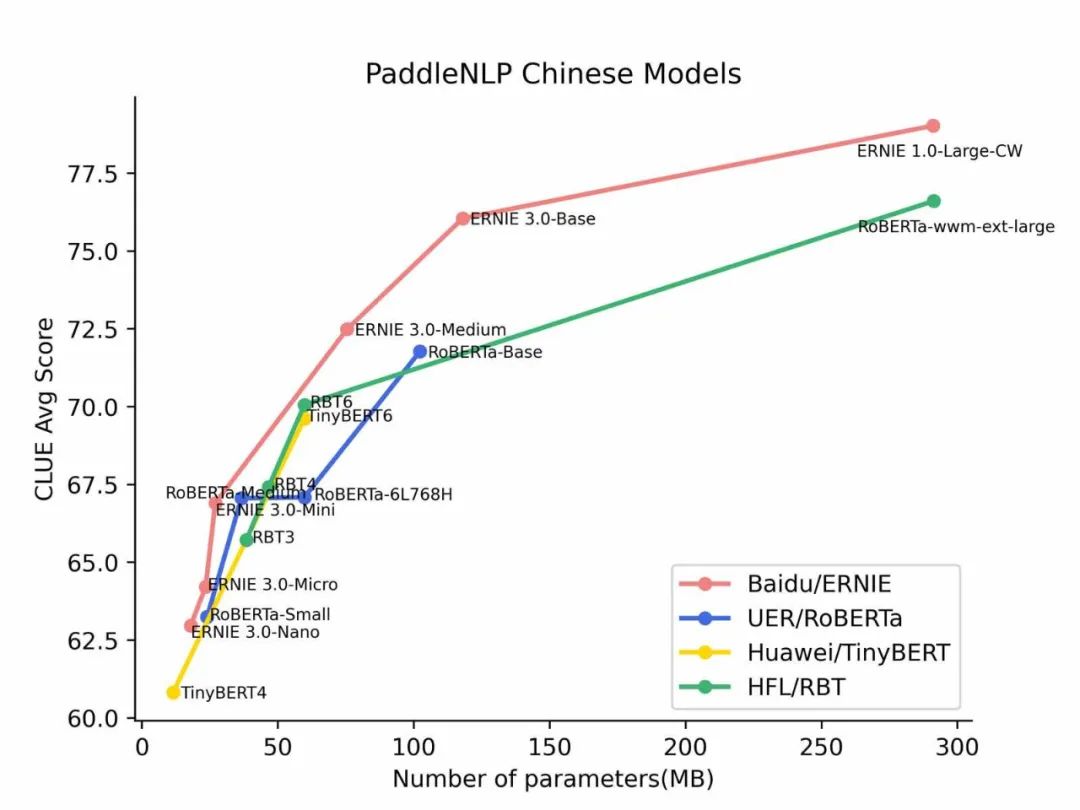
详细的中文全词表构造方法,提供20902个中文全字符词表制作流程
高性能预训练数据生成工具,16小时轻松搞定400G预训练数据制作
混合精度、分布式4D并行训练能力,支持超大语义理解模型训练
全面的CLUE Bencmark效果测评,覆盖大多数主流中文模型
源码及教程地址:
提示学习
{
"template": [
{
"text":
"“{'text': 'text_a'}”和“{'text': 'text_b'}”之间的逻辑关系是{'mask'}{'mask'}"},
{
"text":
"{'soft': '下边两句话之间有什么逻辑关系?'}{'mask'}{'mask'}“{'text': 'text_a'}”{'sep'}“{'text': 'text_b'}”"}
],
"verbalizer": {
"contradiction":
"矛盾",
"entailment":
"蕴含",
"neutral":
"中立"
}
}
PaddleNLP AutoPrompt使用文档
数据增强&模型集成
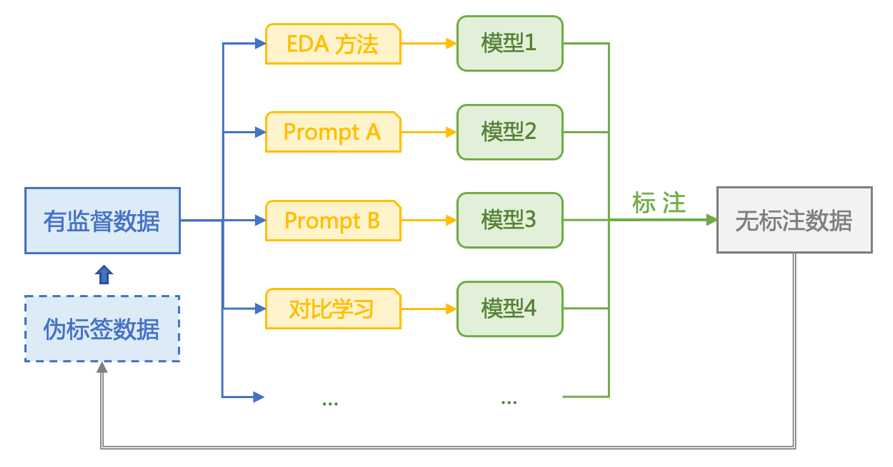

未来展望
相关地址
[1]https://github.com/thunlp/PromptPapers
[2]OpenPrompt: An Open-source Framework for Prompt-learning (Ding et al., ACL 2022, Best Demo)
[3]Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks (Gururangan et al., ACL 2020)
[4]Zero-Shot Learners for Natural Language Understanding via a Unified Multiple Choice Perspective (Yang et al., EMNLP 2022)
[5]GPT Understands, Too (Liu et al., 2021)
[6]EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks (Wei & Zou, EMNLP 2019)
WAVE SUMMIT+2022
WAVE SUMMIT+2022将于11月30日在深圳举办,欢迎大家扫码报名!关注飞桨公众号,后台回复关键词「WAVE」进入官网社群了解更多峰会详情!
【WAVE SUMMIT+2022报名入口】

为什么选择
提示学习
AutoPrompt的优势
灵活
Template String延续了字典结构设计,支持更丰富的提示设计,以满足不同任务的需求。预训练模型、Template、Verbalizer等实现模块化,支持各种灵活扩展。
AutoPrompt支持多种prompt定义
易用
自动化
只需要准备相应格式的数据,定义模型、数据、策略的配置参数,以及Template String文件,即可一键运行。AutoPrompt框架可自动从定义的Template String中选择最佳Prompt,保存效果最优的模型。
AutoPrompt框架使用流程
技术私享会
11月17日,PaddleNLP工程师,AutoPrompt作者将在线分享提示学习相关前沿技术、AutoPrompt的“自动化”理念、FewCLUE打榜经验、以及提示学习产业落地案例,欢迎有兴趣的朋友扫码报名活动,参与线上交流。(为保证交流效果,限100席位)
FewCLUE
小样本学习实践
阶段一 :领域预训练
阶段二:提示学习
阶段三:数据增强&集成学习
领域预训练
详细的中文全词表构造方法,提供20902个中文全字符词表制作流程
高性能预训练数据生成工具,16小时轻松搞定400G预训练数据制作
混合精度、分布式4D并行训练能力,支持超大语义理解模型训练
全面的CLUE Bencmark效果测评,覆盖大多数主流中文模型
源码及教程地址:
提示学习
{
"template": [
{
"text":
"“{'text': 'text_a'}”和“{'text': 'text_b'}”之间的逻辑关系是{'mask'}{'mask'}"},
{
"text":
"{'soft': '下边两句话之间有什么逻辑关系?'}{'mask'}{'mask'}“{'text': 'text_a'}”{'sep'}“{'text': 'text_b'}”"}
],
"verbalizer": {
"contradiction":
"矛盾",
"entailment":
"蕴含",
"neutral":
"中立"
}
}
PaddleNLP AutoPrompt使用文档
数据增强&模型集成
未来展望
相关地址
[1]https://github.com/thunlp/PromptPapers
[2]OpenPrompt: An Open-source Framework for Prompt-learning (Ding et al., ACL 2022, Best Demo)
[3]Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks (Gururangan et al., ACL 2020)
[4]Zero-Shot Learners for Natural Language Understanding via a Unified Multiple Choice Perspective (Yang et al., EMNLP 2022)
[5]GPT Understands, Too (Liu et al., 2021)
[6]EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks (Wei & Zou, EMNLP 2019)
WAVE SUMMIT+2022
WAVE SUMMIT+2022将于11月30日在深圳举办,欢迎大家扫码报名!关注飞桨公众号,后台回复关键词「WAVE」进入官网社群了解更多峰会详情!
【WAVE SUMMIT+2022报名入口】

