


本文整理自北京航空航天大学软件开发环境国家重点实验室副教授罗杰的主题分享——基于大模型的代码生成及其发展趋势。
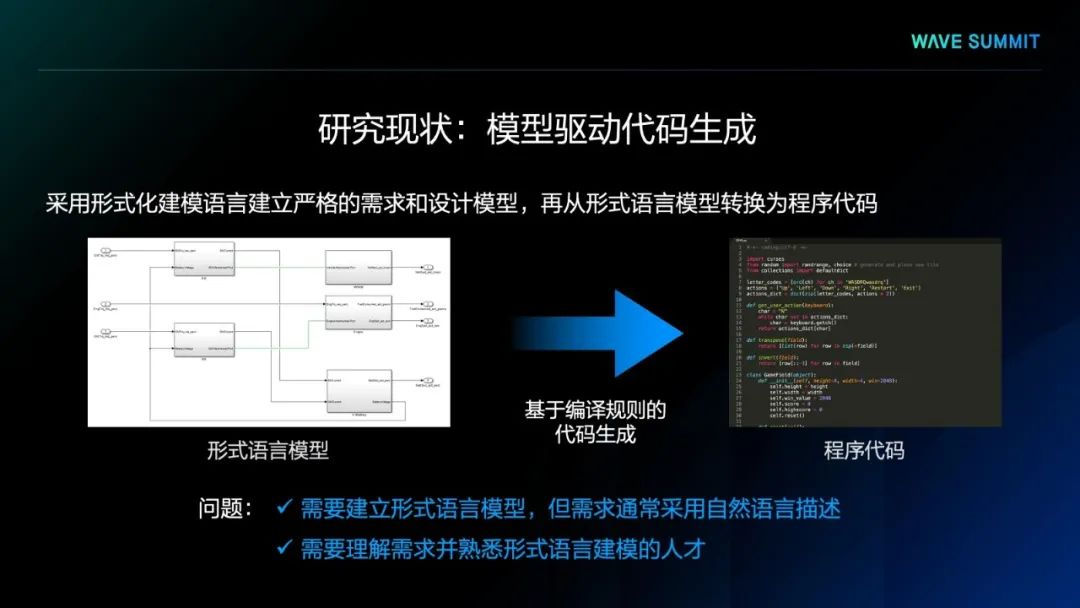
代码生成问题是软件工程和人工智能领域的一个经典难题,其核心在于针对给定的程序需求说明,生成符合需求的程序代码。
基于大模型的
代码生成
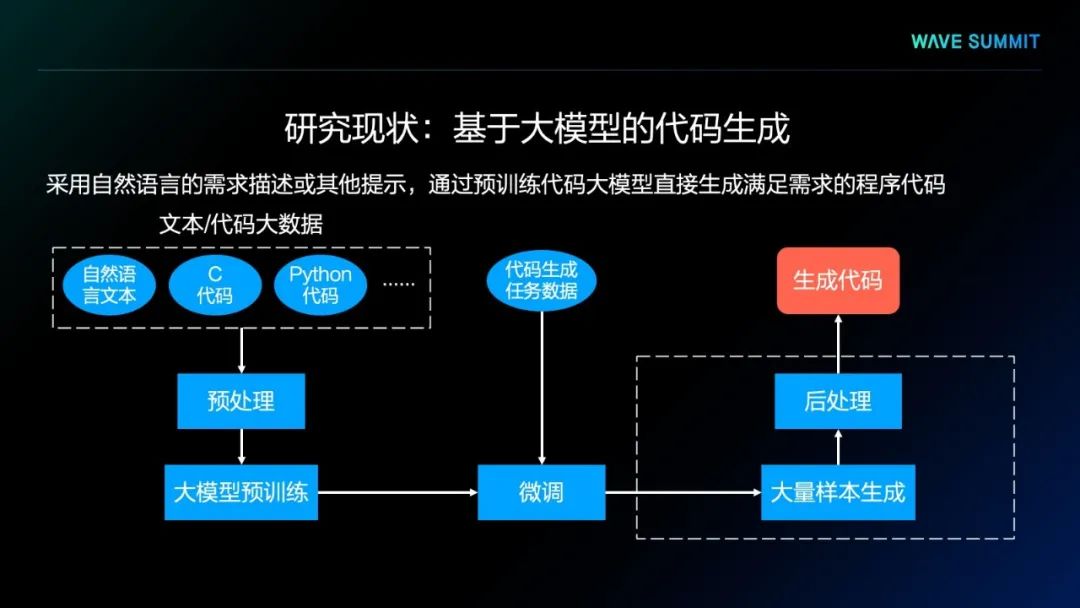
如上图所示,这种方法首先会通过自然语言文本、一种或多种程序语言代码进行模型预训练,生成预训练语言模型,将模型在面向具体任务的数据上进行一些微调,就可以得到面向具体代码生成任务的生成模型。通过该模型大量生成的代码样本,可以通过某种后处理程序,从大量的样本中筛选出正确的代码,并作为最终的生成结果。

左到右语言模型,比如GPT系列模型,典型代表比如CodeParrot、Codex、PolyCoder模型,均采用了此种语言模型架构。
编解码的语言模型,比如最近DeepMind推出的AlphaCode,就是基于编解码模型架构来进行实现。
掩码语言模型,这类方法主要是基于BERT架构来进行实现。
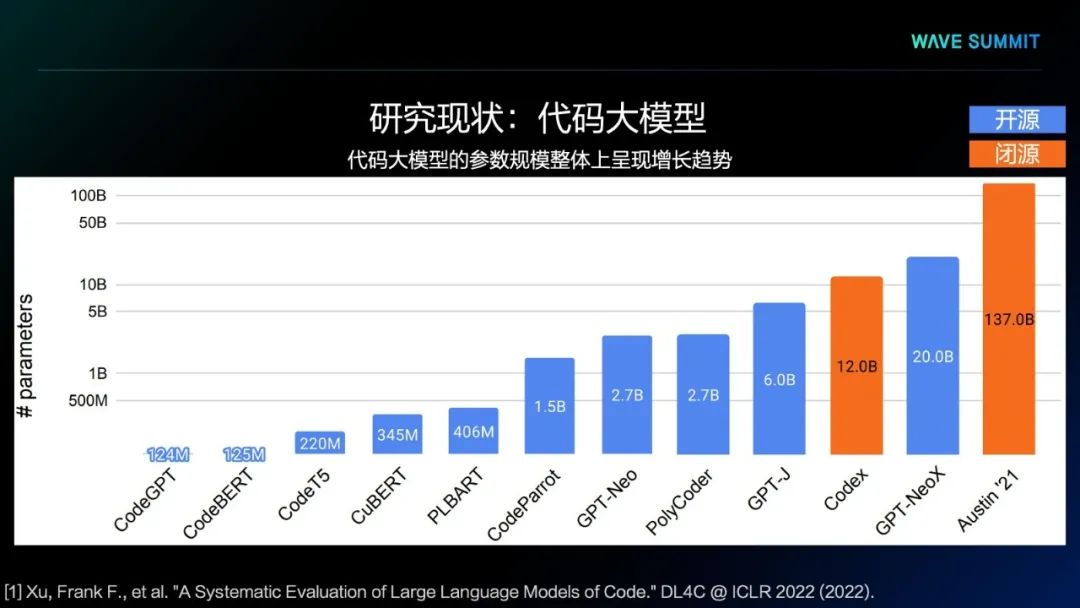
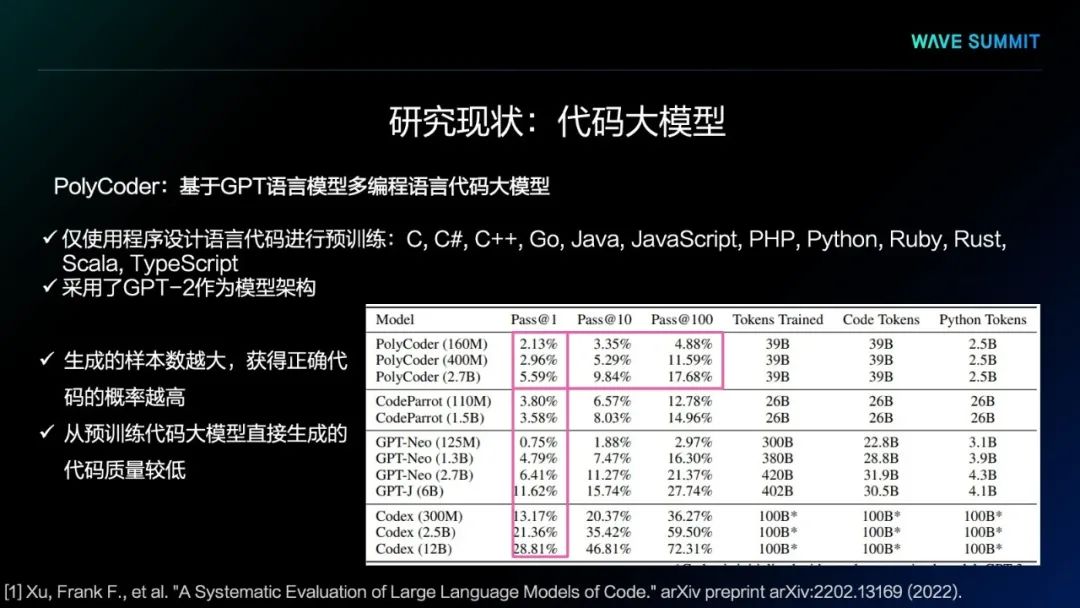
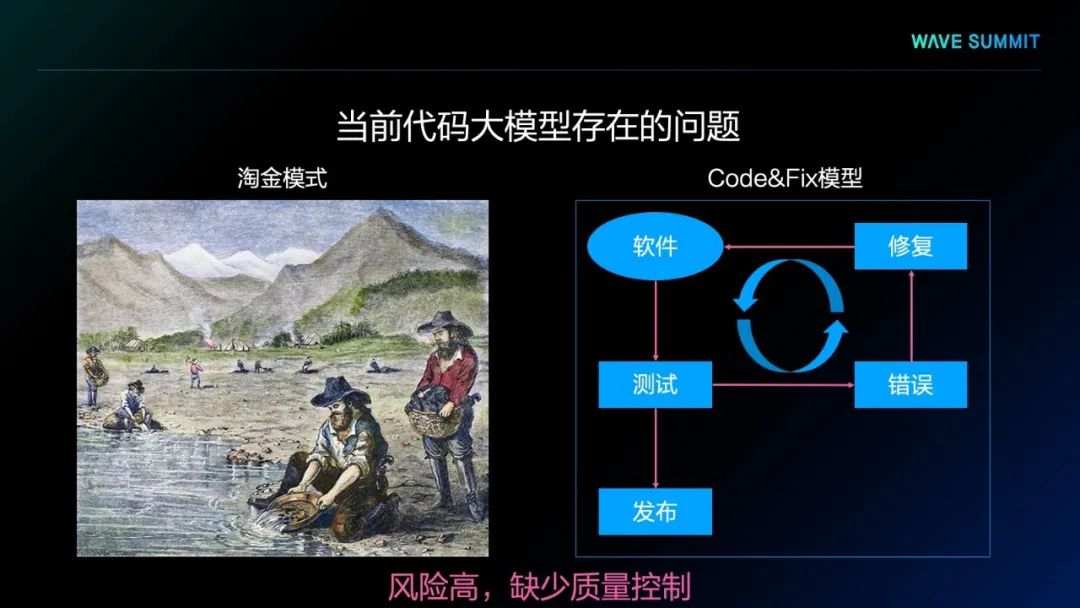
第一个模型是MIT提出的PolyCoder模型,它采用了GPT-2架构,使用程序设计语言的代码进行预训练,使用了12种程序设计语言的代码,却并没有使用任何自然语言的文本进行预训练。可以看出,这样的代码大模型,用它生成程序测试时,能够直接通过测试的概率非常低,虽然生成更多的样本,测试通过概率会更高,但本质上看,它的正确率整体来说还是非常低。所以,预训练代码大模型直接生成的程序代码质量相对较低。

第二个模型是DeepMind提出的AlphaCode,它的框架基于编解码器架构,与PolyCoder相同,也是基于多种程序设计语言进行模型的预训练,使用了12种不同的程序设计语言。在AlphaCode编解码器设计架构时,采用了异构与非对称结构,在编码器部分,虽然使用的层数较少,但维度较大,这部分主要用于处理输入的自然语言描述的需求和提示。在解码器部分,采用了比较多的层数,但比较小的维度,专门用来生成代码。通过这种架构,就能够在同样的参数规模下更好地提高代码生成质量。
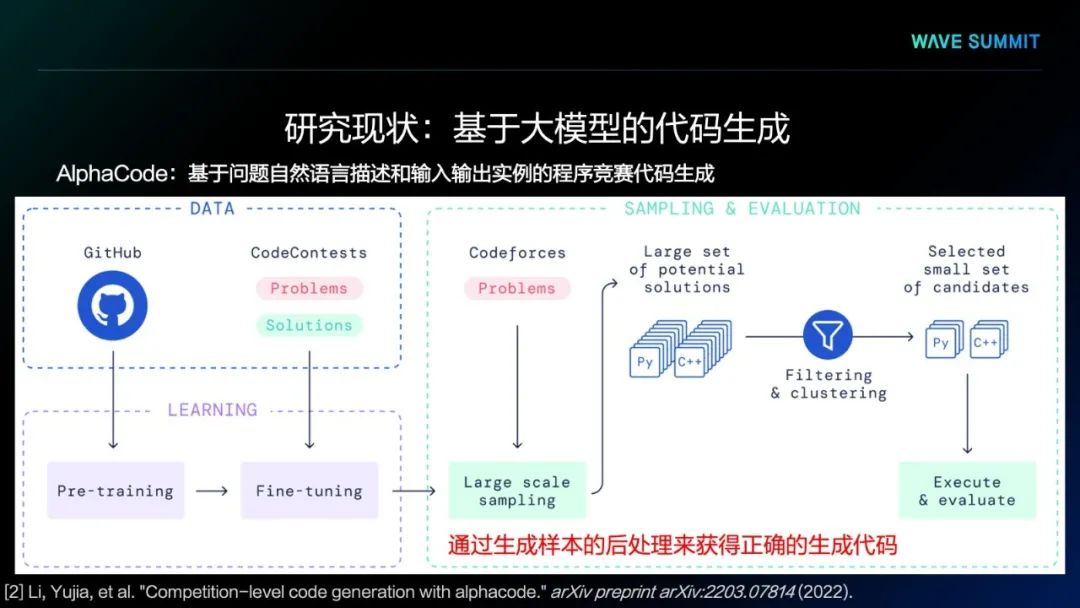
DeepMind的研究人员同样发现了从预训练语言模型里生成的代码质量相对较低。所以,他们采用了后处理的策略进行筛选和过滤,以得到正确的代码。他们试图通过生成海量样本的形式,从中找到正确的生成代码。
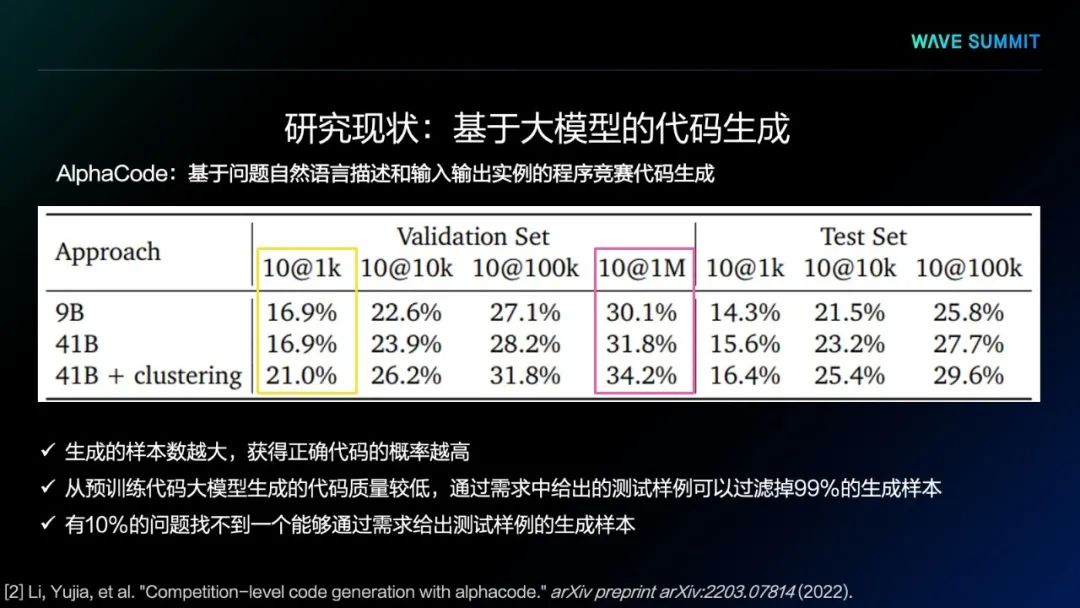
从实验结果中得出,生成的样本数量越大,获得正确代码的概率越高,甚至已经可以从百万级代码中筛选正确代码。同时我们发现,通过需求中给出的测试样例可以过滤掉99%的生成样本,在所有问题里,有10%的问题找不到一个能够通过需求给出测试样例的生成样本,更找不到正确的代码生成结果。因此,预训练语言模型直接输出代码的质量还是不太理想。

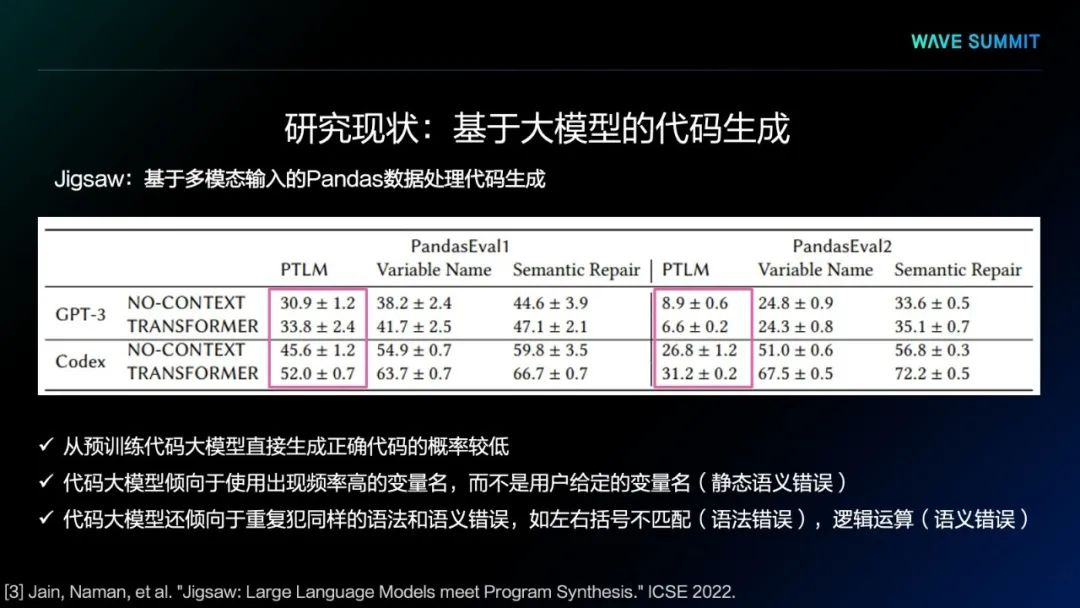
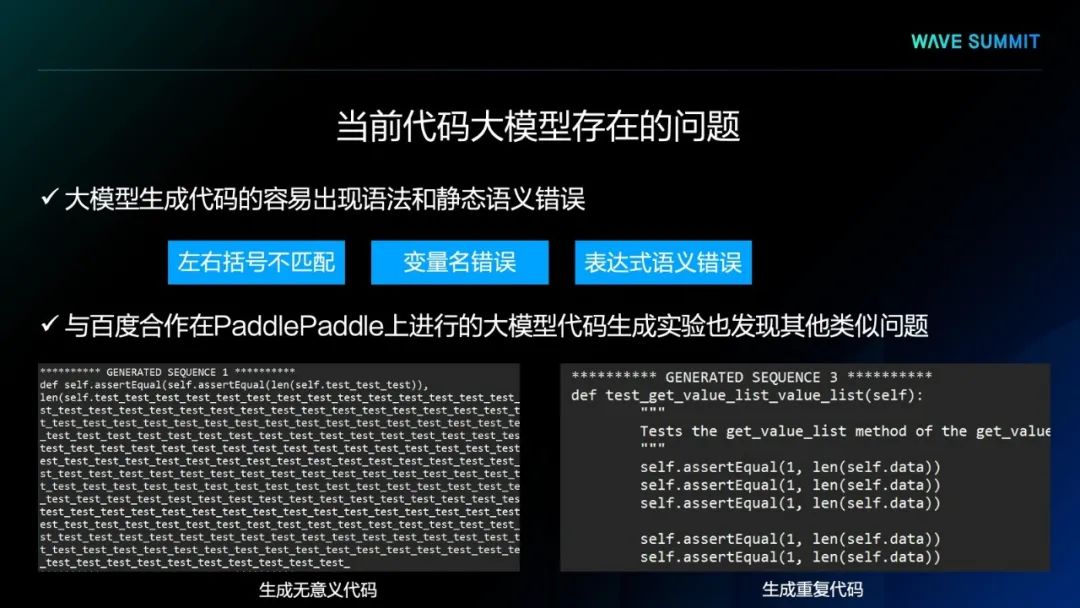
实验结果中可以看到,从预训练代码大模型直接生成代码正确的概率较低。代码大模型倾向于使用出现频率高的变量名,而不是用户给定的变量名,可能会导致静态语义错误。代码大模型还倾向于重复犯同样的语法和语义错误,如左右括号不匹配的语法错误),逻辑运算的语义错误。
此外,Salesforce提出了CodeGen模型(A Conversational Paradigm for Program Synthesis),通过大型语言模型进行对话式程序生成的方法,将编写规范和程序的过程转换为用户和系统之间的多回合对话。它把程序生成看作一个序列预测问题,用自然语言表达规范,并对程序进行抽样生成。同时,CodeGen(16B)在HumanEval benchmark上已经超过OpenAI's Codex。
目前,PaddleNLP已经内置代码生成CodeGen模块,可以通过Taskflow一键调用。代码生成模型的好坏,一般可以通过求解一些算法题来评估。这里以 LeetCode第一题[1]为例,尝试让PaddleNLP模型自动补全代码。题目如下所示:
给定一个整数数组nums和一个整数目标值target,请你在该数组中找出和为目标值target的那两个整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。你可以按任意顺序返回答案。
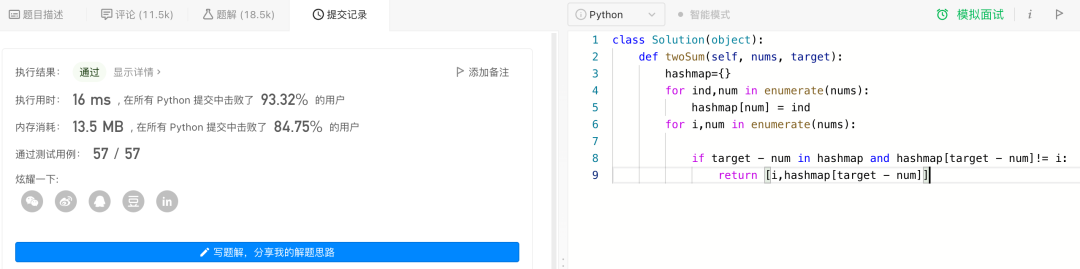
from paddlenlp import Taskflow#Taskflow调用codegen = Taskflow("code_generation", "Salesforce/codegen-2B-mono")prompt = "def twoSum(nums, target):\n hashmap={}\n for ind,num in enumerate(nums):\n hashmap[num] = ind\n for i,num in enumerate(nums):"code = codegen(prompt)print(prompt)print(code[0])
2.输出结果
def twoSum(nums, target): hashmap={} for ind,num in enumerate(nums): hashmap[num] = ind for i,num in enumerate(nums): if target - num in hashmap and hashmap[target - num]!= i: return [i,hashmap[target - num]]
3.提交到LeetCode验证,执行结果显示通过
def lengthOfLongestSubstring(self, s: str) -> int:
题目如下图所示:
给定一个字符串s,请你找出其中不含有重复字符的最长子串的长度。
示例 1:
输入: s = "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
除此之外,Prompt也可以为自然语言,例如注释、功能表述等,同样可以生成与之对应的代码。
Prompt = "# this function prints hello world"Model Output = def hello_world(): print("Hello World")hello_world()
当前代码大模型
存在的问题
北京航空航天大学软件开发环境国家重点实验室与百度合作,在飞桨平台上进行的大模型代码生成实验,也发现上述类似问题,比如会生成一些无意义的代码或者重复的代码。这些都会导致代码大模型的方法在进行应用时会出现问题。
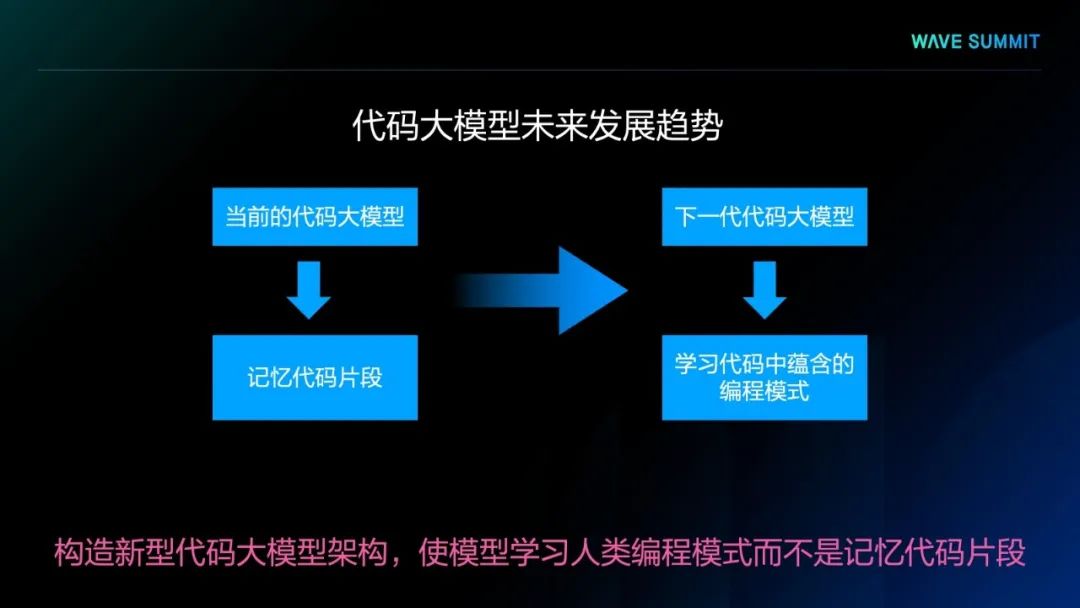
综上所述,我们可以思考,是否可以提出一些新的代码生成方法,以提高代码生成的效率,这是未来一个可能的研究方向。

本文转载自:AI大模型
本文根据2022年5月WAVE SUMMIT深度学习开发者峰会「AI大模型 智领未来」论坛嘉宾分享整理。最新一期WAVE SUMMIT+2022将于11月30日在深圳举办,欢迎大家扫码提前进入官方社群了解详情。
【2022WAVE SUMMIT+报名入口】
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~
本文整理自北京航空航天大学软件开发环境国家重点实验室副教授罗杰的主题分享——基于大模型的代码生成及其发展趋势。
代码生成问题是软件工程和人工智能领域的一个经典难题,其核心在于针对给定的程序需求说明,生成符合需求的程序代码。
基于大模型的
代码生成
如上图所示,这种方法首先会通过自然语言文本、一种或多种程序语言代码进行模型预训练,生成预训练语言模型,将模型在面向具体任务的数据上进行一些微调,就可以得到面向具体代码生成任务的生成模型。通过该模型大量生成的代码样本,可以通过某种后处理程序,从大量的样本中筛选出正确的代码,并作为最终的生成结果。
左到右语言模型,比如GPT系列模型,典型代表比如CodeParrot、Codex、PolyCoder模型,均采用了此种语言模型架构。
编解码的语言模型,比如最近DeepMind推出的AlphaCode,就是基于编解码模型架构来进行实现。
掩码语言模型,这类方法主要是基于BERT架构来进行实现。
第一个模型是MIT提出的PolyCoder模型,它采用了GPT-2架构,使用程序设计语言的代码进行预训练,使用了12种程序设计语言的代码,却并没有使用任何自然语言的文本进行预训练。可以看出,这样的代码大模型,用它生成程序测试时,能够直接通过测试的概率非常低,虽然生成更多的样本,测试通过概率会更高,但本质上看,它的正确率整体来说还是非常低。所以,预训练代码大模型直接生成的程序代码质量相对较低。
第二个模型是DeepMind提出的AlphaCode,它的框架基于编解码器架构,与PolyCoder相同,也是基于多种程序设计语言进行模型的预训练,使用了12种不同的程序设计语言。在AlphaCode编解码器设计架构时,采用了异构与非对称结构,在编码器部分,虽然使用的层数较少,但维度较大,这部分主要用于处理输入的自然语言描述的需求和提示。在解码器部分,采用了比较多的层数,但比较小的维度,专门用来生成代码。通过这种架构,就能够在同样的参数规模下更好地提高代码生成质量。
DeepMind的研究人员同样发现了从预训练语言模型里生成的代码质量相对较低。所以,他们采用了后处理的策略进行筛选和过滤,以得到正确的代码。他们试图通过生成海量样本的形式,从中找到正确的生成代码。
从实验结果中得出,生成的样本数量越大,获得正确代码的概率越高,甚至已经可以从百万级代码中筛选正确代码。同时我们发现,通过需求中给出的测试样例可以过滤掉99%的生成样本,在所有问题里,有10%的问题找不到一个能够通过需求给出测试样例的生成样本,更找不到正确的代码生成结果。因此,预训练语言模型直接输出代码的质量还是不太理想。
实验结果中可以看到,从预训练代码大模型直接生成代码正确的概率较低。代码大模型倾向于使用出现频率高的变量名,而不是用户给定的变量名,可能会导致静态语义错误。代码大模型还倾向于重复犯同样的语法和语义错误,如左右括号不匹配的语法错误),逻辑运算的语义错误。
此外,Salesforce提出了CodeGen模型(A Conversational Paradigm for Program Synthesis),通过大型语言模型进行对话式程序生成的方法,将编写规范和程序的过程转换为用户和系统之间的多回合对话。它把程序生成看作一个序列预测问题,用自然语言表达规范,并对程序进行抽样生成。同时,CodeGen(16B)在HumanEval benchmark上已经超过OpenAI's Codex。
目前,PaddleNLP已经内置代码生成CodeGen模块,可以通过Taskflow一键调用。代码生成模型的好坏,一般可以通过求解一些算法题来评估。这里以 LeetCode第一题[1]为例,尝试让PaddleNLP模型自动补全代码。题目如下所示:
给定一个整数数组nums和一个整数目标值target,请你在该数组中找出和为目标值target的那两个整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。你可以按任意顺序返回答案。
from paddlenlp import Taskflow#Taskflow调用codegen = Taskflow("code_generation", "Salesforce/codegen-2B-mono")prompt = "def twoSum(nums, target):\n hashmap={}\n for ind,num in enumerate(nums):\n hashmap[num] = ind\n for i,num in enumerate(nums):"code = codegen(prompt)print(prompt)print(code[0])
2.输出结果
def twoSum(nums, target): hashmap={} for ind,num in enumerate(nums): hashmap[num] = ind for i,num in enumerate(nums): if target - num in hashmap and hashmap[target - num]!= i: return [i,hashmap[target - num]]
3.提交到LeetCode验证,执行结果显示通过
def lengthOfLongestSubstring(self, s: str) -> int:
题目如下图所示:
给定一个字符串s,请你找出其中不含有重复字符的最长子串的长度。
示例 1:
输入: s = "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
除此之外,Prompt也可以为自然语言,例如注释、功能表述等,同样可以生成与之对应的代码。
Prompt = "# this function prints hello world"Model Output = def hello_world(): print("Hello World")hello_world()
当前代码大模型
存在的问题
北京航空航天大学软件开发环境国家重点实验室与百度合作,在飞桨平台上进行的大模型代码生成实验,也发现上述类似问题,比如会生成一些无意义的代码或者重复的代码。这些都会导致代码大模型的方法在进行应用时会出现问题。
综上所述,我们可以思考,是否可以提出一些新的代码生成方法,以提高代码生成的效率,这是未来一个可能的研究方向。
本文转载自:AI大模型
本文根据2022年5月WAVE SUMMIT深度学习开发者峰会「AI大模型 智领未来」论坛嘉宾分享整理。最新一期WAVE SUMMIT+2022将于11月30日在深圳举办,欢迎大家扫码提前进入官方社群了解详情。
【2022WAVE SUMMIT+报名入口】
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~
