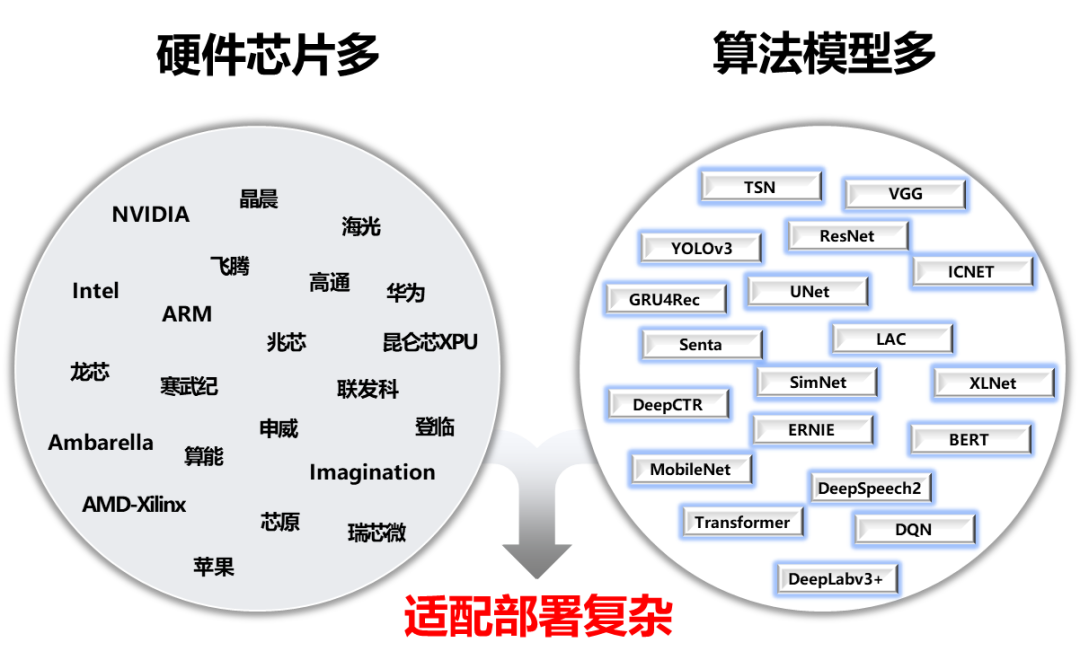
人工智能产业应用发展的越来越快,开发者需要面对的适配部署工作也越来越复杂。层出不穷的算法模型、各种架构的AI硬件、不同场景的部署需求(服务器、服务化、嵌入式、移动端等)、不同操作系统和开发语言,为AI开发者项目落地带来不小的挑战。
为了解决AI部署落地难题,我们发起了FastDeploy项目。FastDeploy针对产业落地场景中的重要AI模型,将模型API标准化,提供下载即可运行的Demo示例。相比传统推理引擎,做到端到端的推理性能优化。FastDeploy还支持在线(服务化部署)和离线部署形态,满足不同开发者的部署需求。
经过为期一年的高密度打磨,FastDeploy目前具备3类特色能力:
https://github.com/PaddlePaddle/FastDeploy
以下将对该3大特性做进一步技术解读,全文大约2100字,预计阅读时长3分钟。
一. 3大特性篇
二. 3步部署实战篇,抢先看
RK3588部署实战(RV1126、晶晨A311D等NPU类似)
全场景:
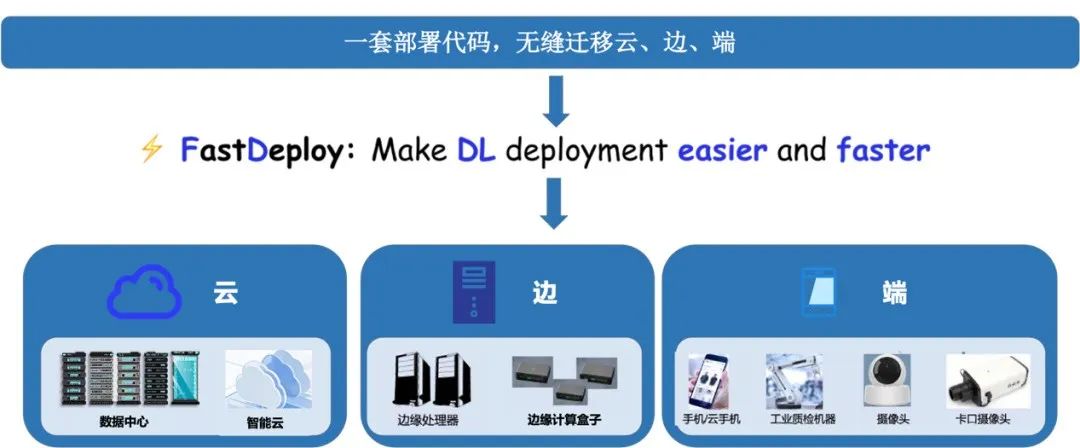
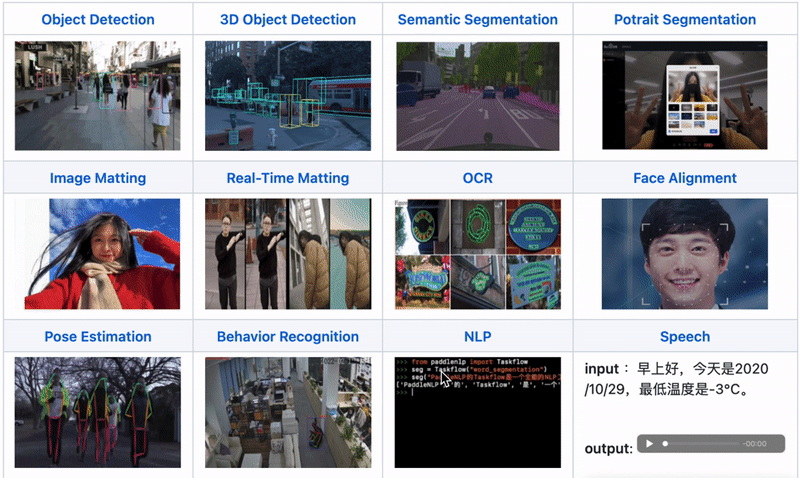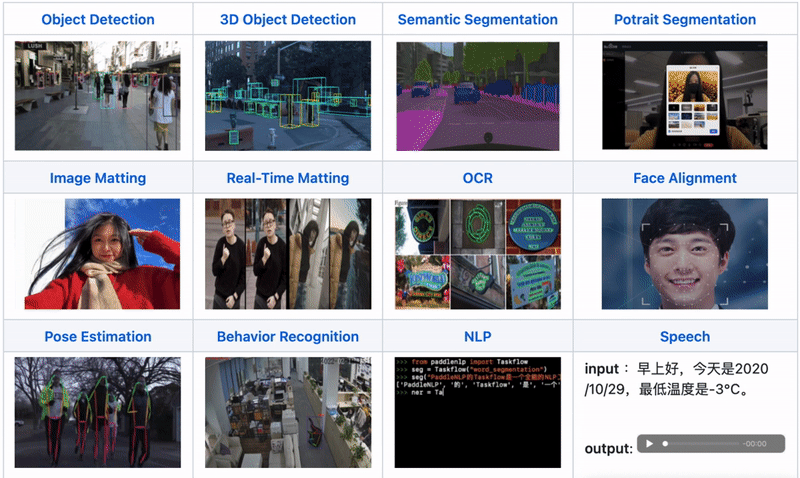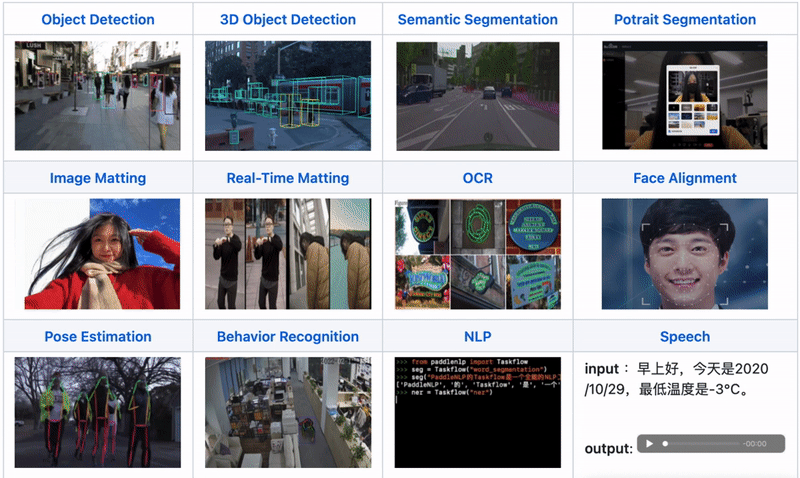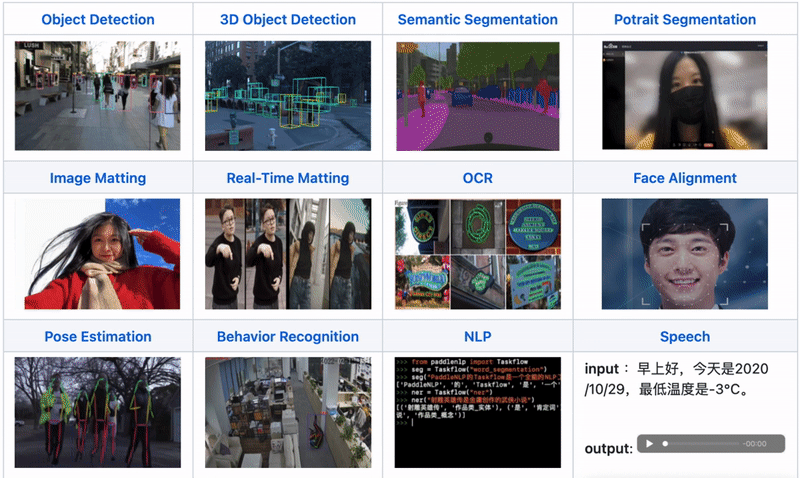
支持Paddle Inference、TensorRT、OpenVINO、ONNX Runtime、Paddle Lite、RKNN等后端,覆盖常见的NVIDIA GPU、x86 CPU 、ARM CPU(移动端、ARM开发板)、瑞芯微NPU(RK3588、RK3568、RV1126、RV1109、RK1808)、晶晨NPU(A311D、S905D)等云边端场景的多类几十款AI硬件部署。同时支持服务化部署、离线CPU/GPU部署、端侧和移动端部署方式。针对不同硬件,统一API保证1套代码在数据中心、边缘部署和端侧部署无缝切换。
易用灵活
# PP-YOLOE的部署
import fastdeploy as fd
import cv2
model = fd.vision.detection.PPYOLOE("model.pdmodel",
"model.pdiparams",
"infer_cfg.yml")
im = cv2.imread("test.jpg")
result = model.predict(im)
# YOLOv7的部署
import fastdeploy as fd
import cv2
model = fd.vision.detection.YOLOv7("model.onnx")
im = cv2.imread("test.jpg")
result = model.predict(im)
# PP-YOLOE的部署
import fastdeploy as fd
import cv2
option = fd.RuntimeOption()
option.use_cpu()
option.use_openvino_backend() # 一行命令切换使用 OpenVINO部署
model = fd.vision.detection.PPYOLOE("model.pdmodel",
"model.pdiparams",
"infer_cfg.yml",
runtime_option=option)
im = cv2.imread("test.jpg")
result = model.predict(im)
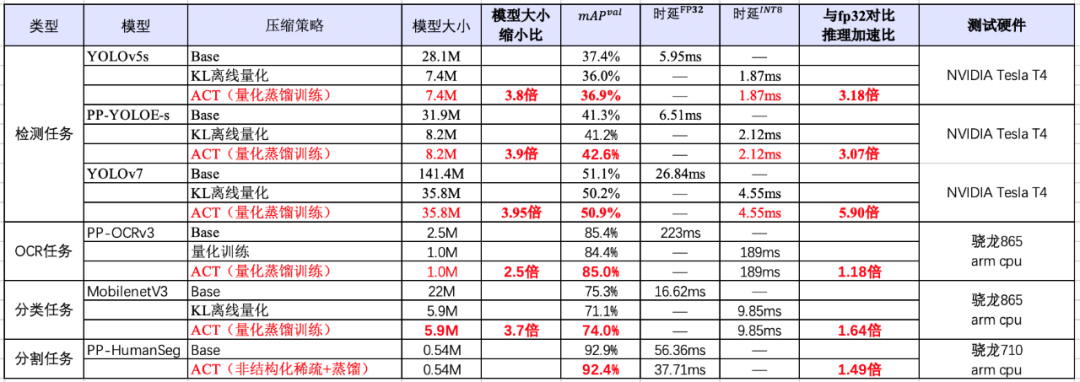
极致高效

3步部署实战篇
CPU/GPU部署实战(以YOLOv7为例)
pip install fastdeploy-gpu-python -f https://www.paddlepaddle.org.cn/whl/fastdeploy.html
git clone https://github.com/PaddlePaddle/FastDeploy.git
cd examples/vision/detection/yolov7/python/
wget https://bj.bcebos.com/paddlehub/fastdeploy/yolov7.onnx
wget https://gitee.com/paddlepaddle/PaddleDetection/raw/release/2.4/demo/000000014439.jpg
# CPU推理
python infer.py --model yolov7.onnx --image 000000014439.jpg --device cpu
# GPU推理
python infer.py --model yolov7.onnx --image 000000014439.jpg --device gpu
# GPU上使用TensorRT推理
python infer.py --model yolov7.onnx --image 000000014439.jpg --device gpu --use_trt True

Jetson部署实战(以YOLOv7为例)
git clone https://github.com/PaddlePaddle/FastDeploy cd FastDeploy
mkdir build && cd build
cmake .. DBUILD_ON_JETSON=ON DENABLE_VISION=ON DCMAKE_INSTALL_PREFIX=${PWD}/install make j8
make install
cd FastDeploy/build/install
source fastdeploy_init.sh
wget https://bj.bcebos.com/paddlehub/fastdeploy/yolov7.onnx
wget https://gitee.com/paddlepaddle/PaddleDetection/raw/release/2.4/demo/000000014439.jpg
cd examples/vision/detection/yolov7/cpp
cmake .. DFASTDEPLOY_INSTALL_DIR=${FASTDEPOLY_DIR}
mkdir build && cd build
make j
# 使用TensorRT推理(当模型不支持TensorRT时会自动转成使用CPU推理)
./infer_demo yolov7s.onnx 000000014439.jpg 2

RK3588部署实战
以轻量化检测网络PicoDet为例
安装FastDeploy部署包,下载部署示例(可选,也可3行API实现部署代码)
# 参考编译文档,完成FastDeploy编译安装
# 参考文档链接:
https://github.com/PaddlePaddle/FastDeploy/blob/develop/docs/cn/build_and_install/rknpu2.md
# 下载部署示例代码
git clone https://github.com/PaddlePaddle/FastDeploy.git
cd examples/vision/detection/paddledetection/rknpu2/python
wget https://bj.bcebos.com/fastdeploy/models/rknn2/picodet_s_416_coco_npu.zip
unzip -qo picodet_s_416_coco_npu.zip
## 下载Paddle静态图模型并解压
wget https://bj.bcebos.com/fastdeploy/models/rknn2/picodet_s_416_coco_npu.zip
unzip -qo picodet_s_416_coco_npu.zip
# 静态图转ONNX模型,注意,这里的save_file请和压缩包名对齐
paddle2onnx --model_dir picodet_s_416_coco_npu \
--model_filename model.pdmodel \
--params_filename model.pdiparams \
--save_file picodet_s_416_coco_npu/picodet_s_416_coco_npu.onnx \
--enable_dev_version True
python -m paddle2onnx.optimize --input_model picodet_s_416_coco_npu/picodet_s_416_coco_npu.onnx \
--output_model picodet_s_416_coco_npu/picodet_s_416_coco_npu.onnx \
--input_shape_dict "{'image':[1,3,416,416]}"
# ONNX模型转RKNN模型
# 转换模型,模型将生成在picodet_s_320_coco_lcnet_non_postprocess目录下
python tools/rknpu2/export.py --config_path tools/rknpu2/config/RK3588/picodet_s_416_coco_npu.yaml
# 下载图片
wget https://gitee.com/paddlepaddle/PaddleDetection/raw/release/2.4/demo/000000014439.jpg
python3 infer.py --model_file ./picodet _3588/picodet_3588.rknn \
--config_file ./picodet_3588/deploy.yaml \
--image images/000000014439.jpg
加入FastDeploy
技术交流群
入群福利
欢迎大家扫码报名

WAVE SUMMIT⁺2022
WAVE SUMMIT⁺2022将于11月30日在深圳举办,欢迎大家扫码关注飞桨公众号,回复WAVE提前加入官方社群了解详情。
【WAVE SUMMIT⁺2022报名入口】

人工智能产业应用发展的越来越快,开发者需要面对的适配部署工作也越来越复杂。层出不穷的算法模型、各种架构的AI硬件、不同场景的部署需求(服务器、服务化、嵌入式、移动端等)、不同操作系统和开发语言,为AI开发者项目落地带来不小的挑战。
为了解决AI部署落地难题,我们发起了FastDeploy项目。FastDeploy针对产业落地场景中的重要AI模型,将模型API标准化,提供下载即可运行的Demo示例。相比传统推理引擎,做到端到端的推理性能优化。FastDeploy还支持在线(服务化部署)和离线部署形态,满足不同开发者的部署需求。
经过为期一年的高密度打磨,FastDeploy目前具备3类特色能力:
https://github.com/PaddlePaddle/FastDeploy
以下将对该3大特性做进一步技术解读,全文大约2100字,预计阅读时长3分钟。
一. 3大特性篇
二. 3步部署实战篇,抢先看
RK3588部署实战(RV1126、晶晨A311D等NPU类似)
全场景:
支持Paddle Inference、TensorRT、OpenVINO、ONNX Runtime、Paddle Lite、RKNN等后端,覆盖常见的NVIDIA GPU、x86 CPU 、ARM CPU(移动端、ARM开发板)、瑞芯微NPU(RK3588、RK3568、RV1126、RV1109、RK1808)、晶晨NPU(A311D、S905D)等云边端场景的多类几十款AI硬件部署。同时支持服务化部署、离线CPU/GPU部署、端侧和移动端部署方式。针对不同硬件,统一API保证1套代码在数据中心、边缘部署和端侧部署无缝切换。
易用灵活
# PP-YOLOE的部署
import fastdeploy as fd
import cv2
model = fd.vision.detection.PPYOLOE("model.pdmodel",
"model.pdiparams",
"infer_cfg.yml")
im = cv2.imread("test.jpg")
result = model.predict(im)
# YOLOv7的部署
import fastdeploy as fd
import cv2
model = fd.vision.detection.YOLOv7("model.onnx")
im = cv2.imread("test.jpg")
result = model.predict(im)
# PP-YOLOE的部署
import fastdeploy as fd
import cv2
option = fd.RuntimeOption()
option.use_cpu()
option.use_openvino_backend() # 一行命令切换使用 OpenVINO部署
model = fd.vision.detection.PPYOLOE("model.pdmodel",
"model.pdiparams",
"infer_cfg.yml",
runtime_option=option)
im = cv2.imread("test.jpg")
result = model.predict(im)
极致高效
3步部署实战篇
CPU/GPU部署实战(以YOLOv7为例)
pip install fastdeploy-gpu-python -f https://www.paddlepaddle.org.cn/whl/fastdeploy.html
git clone https://github.com/PaddlePaddle/FastDeploy.git
cd examples/vision/detection/yolov7/python/
wget https://bj.bcebos.com/paddlehub/fastdeploy/yolov7.onnx
wget https://gitee.com/paddlepaddle/PaddleDetection/raw/release/2.4/demo/000000014439.jpg
# CPU推理
python infer.py --model yolov7.onnx --image 000000014439.jpg --device cpu
# GPU推理
python infer.py --model yolov7.onnx --image 000000014439.jpg --device gpu
# GPU上使用TensorRT推理
python infer.py --model yolov7.onnx --image 000000014439.jpg --device gpu --use_trt True
Jetson部署实战(以YOLOv7为例)
git clone https://github.com/PaddlePaddle/FastDeploy cd FastDeploy
mkdir build && cd build
cmake .. DBUILD_ON_JETSON=ON DENABLE_VISION=ON DCMAKE_INSTALL_PREFIX=${PWD}/install make j8
make install
cd FastDeploy/build/install
source fastdeploy_init.sh
wget https://bj.bcebos.com/paddlehub/fastdeploy/yolov7.onnx
wget https://gitee.com/paddlepaddle/PaddleDetection/raw/release/2.4/demo/000000014439.jpg
cd examples/vision/detection/yolov7/cpp
cmake .. DFASTDEPLOY_INSTALL_DIR=${FASTDEPOLY_DIR}
mkdir build && cd build
make j
# 使用TensorRT推理(当模型不支持TensorRT时会自动转成使用CPU推理)
./infer_demo yolov7s.onnx 000000014439.jpg 2
RK3588部署实战
以轻量化检测网络PicoDet为例
安装FastDeploy部署包,下载部署示例(可选,也可3行API实现部署代码)
# 参考编译文档,完成FastDeploy编译安装
# 参考文档链接:
https://github.com/PaddlePaddle/FastDeploy/blob/develop/docs/cn/build_and_install/rknpu2.md
# 下载部署示例代码
git clone https://github.com/PaddlePaddle/FastDeploy.git
cd examples/vision/detection/paddledetection/rknpu2/python
wget https://bj.bcebos.com/fastdeploy/models/rknn2/picodet_s_416_coco_npu.zip
unzip -qo picodet_s_416_coco_npu.zip
## 下载Paddle静态图模型并解压
wget https://bj.bcebos.com/fastdeploy/models/rknn2/picodet_s_416_coco_npu.zip
unzip -qo picodet_s_416_coco_npu.zip
# 静态图转ONNX模型,注意,这里的save_file请和压缩包名对齐
paddle2onnx --model_dir picodet_s_416_coco_npu \
--model_filename model.pdmodel \
--params_filename model.pdiparams \
--save_file picodet_s_416_coco_npu/picodet_s_416_coco_npu.onnx \
--enable_dev_version True
python -m paddle2onnx.optimize --input_model picodet_s_416_coco_npu/picodet_s_416_coco_npu.onnx \
--output_model picodet_s_416_coco_npu/picodet_s_416_coco_npu.onnx \
--input_shape_dict "{'image':[1,3,416,416]}"
# ONNX模型转RKNN模型
# 转换模型,模型将生成在picodet_s_320_coco_lcnet_non_postprocess目录下
python tools/rknpu2/export.py --config_path tools/rknpu2/config/RK3588/picodet_s_416_coco_npu.yaml
# 下载图片
wget https://gitee.com/paddlepaddle/PaddleDetection/raw/release/2.4/demo/000000014439.jpg
python3 infer.py --model_file ./picodet _3588/picodet_3588.rknn \
--config_file ./picodet_3588/deploy.yaml \
--image images/000000014439.jpg
加入FastDeploy
技术交流群
入群福利
欢迎大家扫码报名
WAVE SUMMIT⁺2022
WAVE SUMMIT⁺2022将于11月30日在深圳举办,欢迎大家扫码关注飞桨公众号,回复WAVE提前加入官方社群了解详情。
【WAVE SUMMIT⁺2022报名入口】