


近日,百度飞桨重磅发布了一款开源时序建模算法库——PaddleTS,可以帮助开发者实现时序数据处理、分析、建模、预测全流程,具有更优的使用体验:
时间序列是按照时间发生的先后顺序进行排列的数据点序列,简称时序。时间序列预测是最常见的时序问题之一,在很多行业都有时序预测的应用,且通常时序预测效果对业务有着重大影响。例如:
零售企业:准确的预测产品销量,可以为企业备货、配送、运营策略的制定提供有效依据,显著降本增效;

https://github.com/PaddlePaddle/PaddleTS

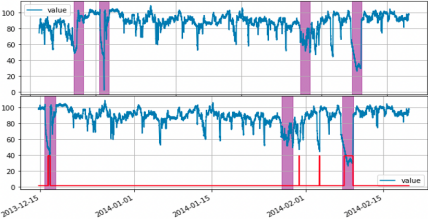
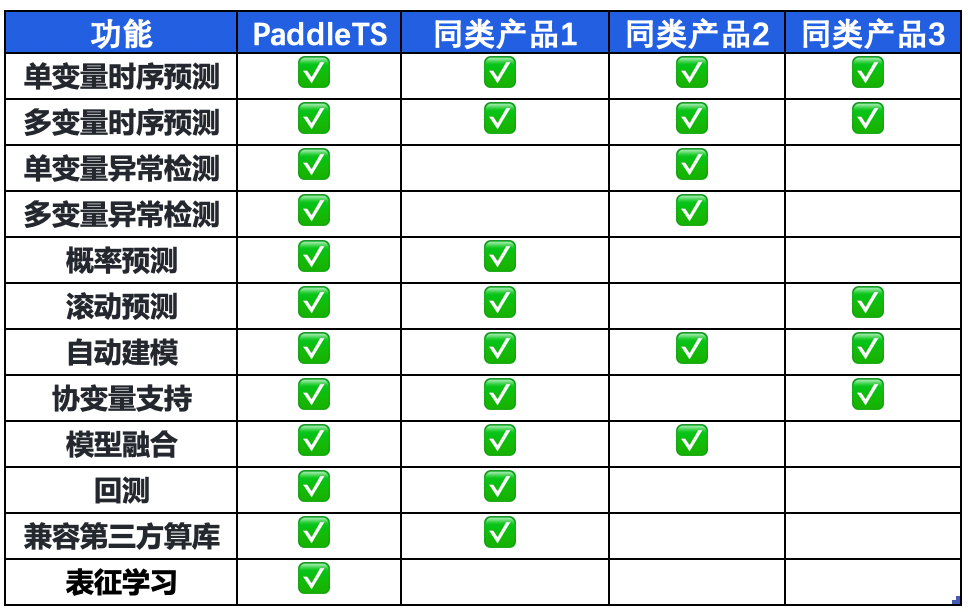
PaddleTS覆盖时序预测和时序异常检测两大核心应用场景,针对建模全流程,提供了丰富的功能。既支持单变量也支持多变量的时序分析,同时还具备模型融合、自动建模及丰富的建模工具组件。PaddleTS无论是在功能丰富度上,还是在集成的时序算法数量上,都超过了市面上典型的开源时序产品。除了基础能力以外,产品还有以下特色功能:
全面的数据类型支持:PaddleTS提供的协变量支持功能,支持历史观测协变量、未来可知协变量、静态协变量和分类变量等各种协变量数据类型,帮助开发者有效利用各种数据充分发挥数据的价值。
简单易用、快速上手
不需要深刻的专业背景和复杂的特征工程
3行代码实现时序建模
dataset = TSDataset.load_from_dataframe(df, **kwargs)
mlp = MLPRegressor(in_chunk_len = 7 * 24, out_chunk_len = 24)
mlp.fit(dataset)
兼容第三方库,机器学习模型也能高效利用
时序预测代码示例
ts_forecasting_model = make_ml_model(sklearn.linear_model.LinearRegression, in_chunk_len=16, out_chunk_len=1)
ts_forecasting_model.fit(tsdataset)
res = ts_forecasting_model.predict(tsdataset)
ts_anomaly_model = make_ml_model(pyod.models.knn.KNN, in_chunk_len=16)
ts_anomaly_model.fit(tsdataset)
res = ts_anomaly_model.predict(tsdataset)
时序专属的自动建模与集成预测器
策略更优、操作更简单
AutoTS功能代码示例
autots_model = AutoTS(MLPRegressor, 96, 24)
autots_model.fit(tsdataset)
Ensemble功能代码示例
ensemble_model = StackingEnsembleForecaster(96,24,estimators=[(NHiTSModel, nhits_params),(RNNBlockRegressor, rnn_params), (MLPRegressor, mlp_params)])
ensemble_model.fit(ts_train, ts_val)
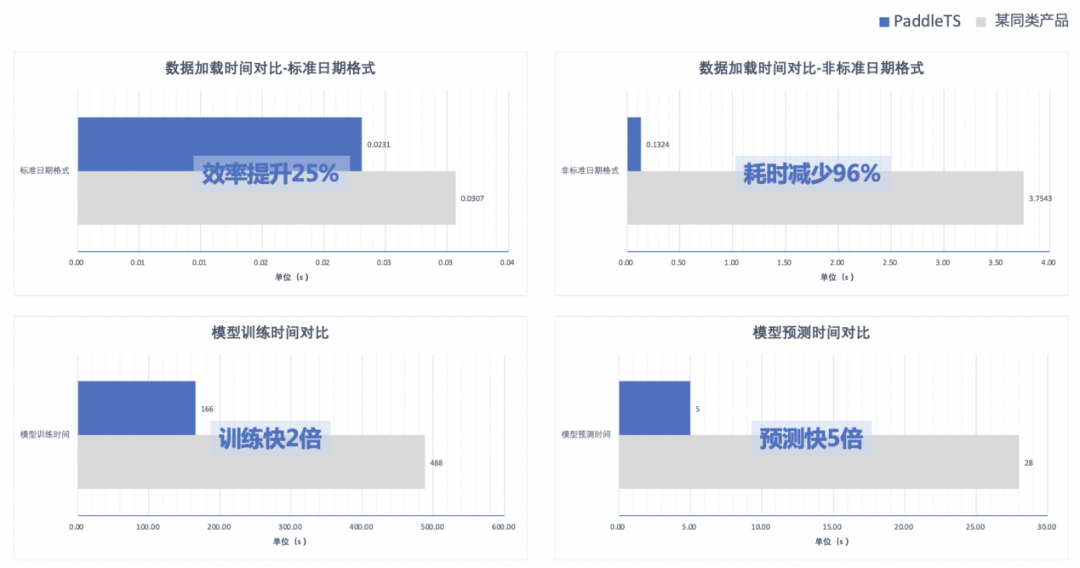
速度快、效果优
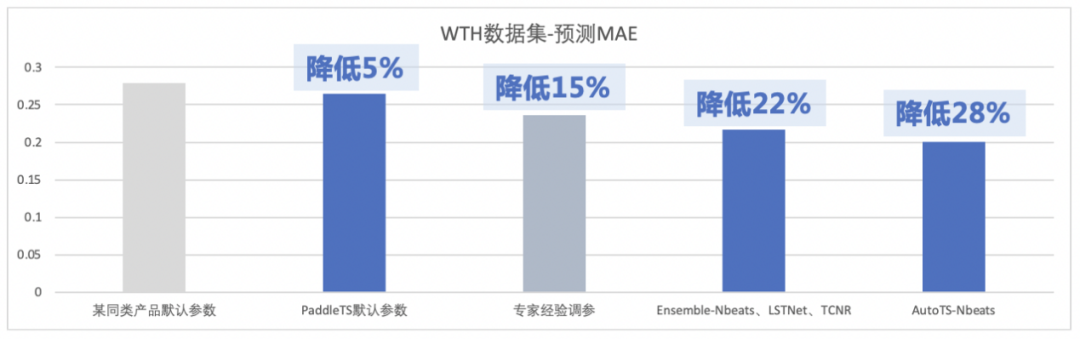
WTH数据集:包含2010年至2013年4年间近1600个美国地区的当地气候数据
加入PaddleTS
技术交流群
【直播课预告】

WAVE SUMMIT⁺2022
WAVE SUMMIT⁺2022将于11月30日在深圳举办,欢迎大家扫码关注飞桨公众号,回复WAVE提前加入官方社群了解详情。
【WAVE SUMMIT⁺2022报名入口】

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~
近日,百度飞桨重磅发布了一款开源时序建模算法库——PaddleTS,可以帮助开发者实现时序数据处理、分析、建模、预测全流程,具有更优的使用体验:
时间序列是按照时间发生的先后顺序进行排列的数据点序列,简称时序。时间序列预测是最常见的时序问题之一,在很多行业都有时序预测的应用,且通常时序预测效果对业务有着重大影响。例如:
零售企业:准确的预测产品销量,可以为企业备货、配送、运营策略的制定提供有效依据,显著降本增效;
https://github.com/PaddlePaddle/PaddleTS
PaddleTS覆盖时序预测和时序异常检测两大核心应用场景,针对建模全流程,提供了丰富的功能。既支持单变量也支持多变量的时序分析,同时还具备模型融合、自动建模及丰富的建模工具组件。PaddleTS无论是在功能丰富度上,还是在集成的时序算法数量上,都超过了市面上典型的开源时序产品。除了基础能力以外,产品还有以下特色功能:
全面的数据类型支持:PaddleTS提供的协变量支持功能,支持历史观测协变量、未来可知协变量、静态协变量和分类变量等各种协变量数据类型,帮助开发者有效利用各种数据充分发挥数据的价值。
简单易用、快速上手
不需要深刻的专业背景和复杂的特征工程
3行代码实现时序建模
dataset = TSDataset.load_from_dataframe(df, **kwargs)
mlp = MLPRegressor(in_chunk_len = 7 * 24, out_chunk_len = 24)
mlp.fit(dataset)
兼容第三方库,机器学习模型也能高效利用
时序预测代码示例
ts_forecasting_model = make_ml_model(sklearn.linear_model.LinearRegression, in_chunk_len=16, out_chunk_len=1)
ts_forecasting_model.fit(tsdataset)
res = ts_forecasting_model.predict(tsdataset)
ts_anomaly_model = make_ml_model(pyod.models.knn.KNN, in_chunk_len=16)
ts_anomaly_model.fit(tsdataset)
res = ts_anomaly_model.predict(tsdataset)
时序专属的自动建模与集成预测器
策略更优、操作更简单
AutoTS功能代码示例
autots_model = AutoTS(MLPRegressor, 96, 24)
autots_model.fit(tsdataset)
Ensemble功能代码示例
ensemble_model = StackingEnsembleForecaster(96,24,estimators=[(NHiTSModel, nhits_params),(RNNBlockRegressor, rnn_params), (MLPRegressor, mlp_params)])
ensemble_model.fit(ts_train, ts_val)
速度快、效果优
WTH数据集:包含2010年至2013年4年间近1600个美国地区的当地气候数据
加入PaddleTS
技术交流群
【直播课预告】
WAVE SUMMIT⁺2022
WAVE SUMMIT⁺2022将于11月30日在深圳举办,欢迎大家扫码关注飞桨公众号,回复WAVE提前加入官方社群了解详情。
【WAVE SUMMIT⁺2022报名入口】
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~