




近几年出现了基于深度学习的光流估计算法,开山之作是FlowNet[1],于2015年首先使用CNN解决光流估计问题,取得了较好的结果,并且在CVPR2017上发表改进版本FlowNet2.0[2],成为当时State-of-the-art的方法。
项目介绍
光流数据集

光流估计评价指标
RAFT模型搭建
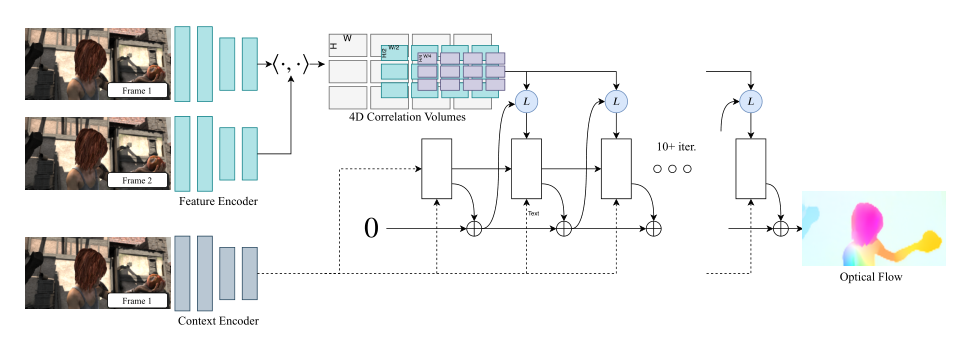
从两个输入图像img1和img2中提取每像素特征的特征编码器(Feature Encoder)以及仅从img1中提取特征的上下文编码器(Context Encoder)。
一个相关层,通过取所有特征向量对的内积,构造4D W×H×W×H相关体。4D矩阵的最后2维在多个尺度上汇集,以构建一组多尺度体积。
接下来进行详解与代码展示
特征提取
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
import numpy as np
from scipy import interpolate
# 本文件是raft模型中的特征提取和上下文提取模块,模块主要使用了残差卷积
class ResidualBlock(nn.Layer):
def __init__(self, in_planes, planes, norm_fn='batch', stride=1):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2D(in_planes, planes,kernel_size=3, padding=1, stride=stride, weight_attr=nn.initializer.KaimingNormal())
self.conv2 = nn.Conv2D(planes, planes, kernel_size=3, padding=1, weight_attr=nn.initializer.KaimingNormal())
self.relu = nn.ReLU() # in_planes=True
if norm_fn == 'batch':
self.norm1 = nn.BatchNorm2D(planes, weight_attr=paddle.ParamAttr(initializer=nn.initializer.Constant(value=1.0)))
self.norm2 = nn.BatchNorm2D(planes, weight_attr=paddle.ParamAttr(initializer=nn.initializer.Constant(value=1.0)))
if not stride == 1:
self.norm3 = nn.BatchNorm2D(planes, weight_attr=paddle.ParamAttr(initializer=nn.initializer.Constant(value=1.0)))
elif norm_fn == 'instance':
self.norm1 = nn.InstanceNorm2D(planes, weight_attr=paddle.ParamAttr(initializer=nn.initializer.Constant(value=1.0)))
self.norm2 = nn.InstanceNorm2D(planes, weight_attr=paddle.ParamAttr(initializer=nn.initializer.Constant(value=1.0)))
if not stride == 1:
self.norm3 = nn.InstanceNorm2D(planes, weight_attr=paddle.ParamAttr(initializer=nn.initializer.Constant(value=1.0)))
if stride == 1:
self.downsample = None
else:
self.downsample = nn.Sequential(
nn.Conv2D(in_planes, planes, kernel_size=1, stride=stride, weight_attr=nn.initializer.KaimingNormal()), self.norm3
)
def forward(self, x):
y = x
y = self.relu(self.norm1(self.conv1(y)))
y = self.relu(self.norm2(self.conv2(y)))
if self.downsample is not None:
x = self.downsample(x)
return self.relu(x+y)
成本量计算
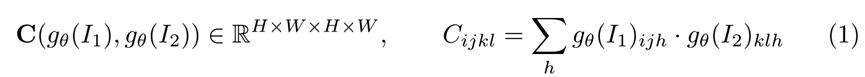
import paddle
import paddle.nn.functional as F
from utils import *
# 本部分涉及了计算光流的成本量函数
class CorrBlock:
def __init__(self, fmap1, fmap2, num_levels=4, radius=4):
self.num_levels = num_levels
self.radius = radius
self.corr_pyramid = []
corr = CorrBlock.corr(fmap1, fmap2)
batch, h1, w1, dim, h2, w2 = corr.shape
corr = paddle.reshape(corr, shape=[batch*h1*w1, dim, h2, w2])
self.corr_pyramid.append(corr)
for i in range(self.num_levels-1):
corr = F.avg_pool2d(corr, 2, stride=2)
self.corr_pyramid.append(corr)
def __call__(self, coords):
r = self.radius
coords = paddle.transpose(coords, perm=[0, 2, 3, 1])
batch, h1, w1, _ = coords.shape
out_pyramid = []
for i in range(self.num_levels):
corr = self.corr_pyramid[i]
# linspace为线性等分 r为搜索半径
dx = paddle.linspace(-r, r, 2*r+1)
dy = paddle.linspace(-r, r, 2*r+1)
delta = paddle.stack(paddle.meshgrid(dy, dx), axis=-1)
centroid_lvl = paddle.reshape(coords, shape=[batch*h1*w1, 1, 1, 2]) / 2**i
delta_lvl = paddle.reshape(delta, shape=[1, 2*r+1, 2*r+1, 2])
coords_lvl = centroid_lvl + delta_lvl
corr = bilinear_sampler(corr, coords_lvl)
corr = paddle.reshape(corr, shape=[batch, h1, w1, -1])
out_pyramid.append(corr)
out = paddle.concat(out_pyramid, axis=-1)
return paddle.transpose(out, perm=[0, 3, 1, 2]).astype('float32')
# transpose、permute 操作虽然没有修改底层一维数组,但是新建了一份Tensor元信息,并在新的元信息中的重新指定stride。
@staticmethod
def corr(fmap1, fmap2):
batch, dim, ht, wd = fmap1.shape
# 修改tensor的形状
fmap1 = paddle.reshape(fmap1, shape=[batch, dim, ht*wd])
fmap2 = paddle.reshape(fmap2, shape=[batch, dim, ht*wd])
corr = paddle.matmul(paddle.transpose(fmap1, perm=[0,2,1]), fmap2)
corr = paddle.reshape(corr, shape=[batch, ht, wd, 1, ht, wd])
# 归一化
return corr / paddle.sqrt(paddle.to_tensor(float(dim)))
为何要进行这样计算?有2个方面原因:
进行这样的计算可以找到前一张图片和后一张图片的像素点之间的联系;
这种相关信息张量可以保证同时捕捉到较大和较小的像素位移。
更新迭代
最开始,将flow初始化为0;
更新当前flow:flow = flow + △flow。
每次迭代计算△flow的流程为:
根据本次迭代计算出来的△flow,更新当前的flow后得出本次迭代的flow 。这里得到的flow的分辨率还是原图的1/8,所以再通过上采样得出跟原图同分辨率的flow。后面会用这个flow来计算loss。
RAFT模型创造性的引入GRU作为迭代的主体,成为了很长一段时间内光流估计流域的通用架构。GRU是LSTM网络的一种效果很好的变体,它较LSTM网络的结构更加简单,而且效果也很好,因此也是当前非常流行的一种网络。GRU既然是LSTM的变体,因此也是可以解决RNN网络中的长依赖问题。GRU的参数较少,因此训练速度更快,GRU能够降低过拟合的风险。但是在RAFT训练过程中迭代了12次,依然是耗费了大量的计算资源。
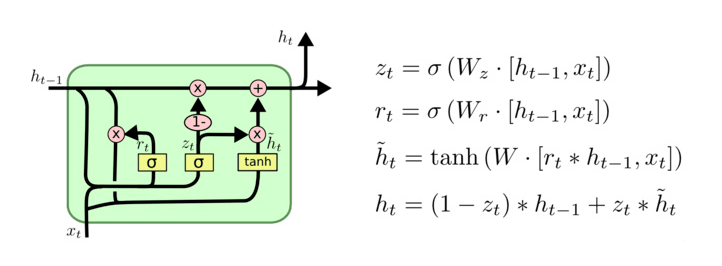
class SepConvGRU(nn.Layer):
def __init__(self, hidden_dim=128, input_dim=192+128):
super(SepConvGRU, self).__init__()
self.convz1 = nn.Conv2D(hidden_dim+input_dim, hidden_dim, (1,5), padding=(0,2))
self.convr1 = nn.Conv2D(hidden_dim+input_dim, hidden_dim, (1,5), padding=(0,2))
self.convq1 = nn.Conv2D(hidden_dim+input_dim, hidden_dim, (1,5), padding=(0,2))
self.convz2 = nn.Conv2D(hidden_dim+input_dim, hidden_dim, (5,1), padding=(2,0))
self.convr2 = nn.Conv2D(hidden_dim+input_dim, hidden_dim, (5,1), padding=(2,0))
self.convq2 = nn.Conv2D(hidden_dim+input_dim, hidden_dim, (5,1), padding=(2,0))
def forward(self, h, x):
# horizontal
hx = paddle.concat([h, x], axis=1)
z = F.sigmoid(self.convz1(hx))
r = F.sigmoid(self.convr1(hx))
q = F.tanh(self.convq1(paddle.concat([r*h, x], axis=1)))
h = (1-z) * h + z * q
# vertical
hx = paddle.concat([h, x], axis=1)
z = F.sigmoid(self.convz2(hx))
r = F.sigmoid(self.convr2(hx)) # 在v1版本中,本行的convr2被写成convz2!
q = F.tanh(self.convq2(paddle.concat([r*h, x], axis=1)))
h = (1-z) * h + z* q
return h
训练策略
# --------------------------Hyperparameter begin----------------------------------------
num_steps =
120000
# 训练次数
batch_size =
16
# 一批训练数量
gamma =
0.
85
# 这个是求损失用到的gamma,官方默认是0.85
max_flow =
400
# 像素移动的最大值,超过最大值则忽略不计
num_workers =
4
# DataLoader读取数据的进程
learning_rate =
0.
00040
# 学习率
log_iter =
100
# 每训练log_iter次打印一次日志
VAL_FREQ =
2500
# 每训练VAL_FREQ次验证一次
log = Logger(
'test.txt', batch_size)
# 日志文件的名字,位置是work/log
warmup_proportion =
0.
3
# 学习率策略:线性热启动+线性衰减
polynomial_lr = paddle.optimizer.lr.PolynomialDecay(learning_rate=learning_rate, decay_steps=
int((
1-warmup_proportion)*num_steps) +
100, end_lr = learning_rate /
10000)
scheduler = paddle.optimizer.lr.LinearWarmup(learning_rate=polynomial_lr, warmup_steps=
int(warmup_proportion*num_steps), start_lr =
0.
00001, end_lr=learning_rate)
# 优化器:AdamW
optimizer = paddle.optimizer.AdamW(learning_rate=scheduler, weight_decay=
0.
00001, epsilon=
1e-
8, parameters=model.parameters())
# --------------------------Hyperparameter end---------------------------------------
总结
目前基于深度学习的光流估计算法,都使用了大规模的数据集,包括FlyingThings、FlyingChairs等合成数据集,KITTI、Sintel等真实数据集,但是由于AI Studio的存储空间、训练时间有限,所以我在本项目中只使用了FlyingChairs数据集,所以目前的模型在处理真实数据集时还有提升的空间。
推荐使用AI Studio的V100 32G环境训练,如果是16G环境,需要调低batchsize,调低lr,增加num_steps。
参考文献
[5].Sun, D., et al. (2021). Autoflow: Learning a better training set for optical flow. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.
WAVE SUMMIT⁺2022
WAVE SUMMIT⁺2022将于11月30日在深圳举办,欢迎大家扫码关注飞桨公众号,回复WAVE提前加入官方社群了解详情。
【WAVE SUMMIT⁺2022报名入口】

近几年出现了基于深度学习的光流估计算法,开山之作是FlowNet[1],于2015年首先使用CNN解决光流估计问题,取得了较好的结果,并且在CVPR2017上发表改进版本FlowNet2.0[2],成为当时State-of-the-art的方法。
项目介绍
光流数据集
光流估计评价指标
RAFT模型搭建
从两个输入图像img1和img2中提取每像素特征的特征编码器(Feature Encoder)以及仅从img1中提取特征的上下文编码器(Context Encoder)。
一个相关层,通过取所有特征向量对的内积,构造4D W×H×W×H相关体。4D矩阵的最后2维在多个尺度上汇集,以构建一组多尺度体积。
接下来进行详解与代码展示
特征提取
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
import numpy as np
from scipy import interpolate
# 本文件是raft模型中的特征提取和上下文提取模块,模块主要使用了残差卷积
class ResidualBlock(nn.Layer):
def __init__(self, in_planes, planes, norm_fn='batch', stride=1):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2D(in_planes, planes,kernel_size=3, padding=1, stride=stride, weight_attr=nn.initializer.KaimingNormal())
self.conv2 = nn.Conv2D(planes, planes, kernel_size=3, padding=1, weight_attr=nn.initializer.KaimingNormal())
self.relu = nn.ReLU() # in_planes=True
if norm_fn == 'batch':
self.norm1 = nn.BatchNorm2D(planes, weight_attr=paddle.ParamAttr(initializer=nn.initializer.Constant(value=1.0)))
self.norm2 = nn.BatchNorm2D(planes, weight_attr=paddle.ParamAttr(initializer=nn.initializer.Constant(value=1.0)))
if not stride == 1:
self.norm3 = nn.BatchNorm2D(planes, weight_attr=paddle.ParamAttr(initializer=nn.initializer.Constant(value=1.0)))
elif norm_fn == 'instance':
self.norm1 = nn.InstanceNorm2D(planes, weight_attr=paddle.ParamAttr(initializer=nn.initializer.Constant(value=1.0)))
self.norm2 = nn.InstanceNorm2D(planes, weight_attr=paddle.ParamAttr(initializer=nn.initializer.Constant(value=1.0)))
if not stride == 1:
self.norm3 = nn.InstanceNorm2D(planes, weight_attr=paddle.ParamAttr(initializer=nn.initializer.Constant(value=1.0)))
if stride == 1:
self.downsample = None
else:
self.downsample = nn.Sequential(
nn.Conv2D(in_planes, planes, kernel_size=1, stride=stride, weight_attr=nn.initializer.KaimingNormal()), self.norm3
)
def forward(self, x):
y = x
y = self.relu(self.norm1(self.conv1(y)))
y = self.relu(self.norm2(self.conv2(y)))
if self.downsample is not None:
x = self.downsample(x)
return self.relu(x+y)
成本量计算
import paddle
import paddle.nn.functional as F
from utils import *
# 本部分涉及了计算光流的成本量函数
class CorrBlock:
def __init__(self, fmap1, fmap2, num_levels=4, radius=4):
self.num_levels = num_levels
self.radius = radius
self.corr_pyramid = []
corr = CorrBlock.corr(fmap1, fmap2)
batch, h1, w1, dim, h2, w2 = corr.shape
corr = paddle.reshape(corr, shape=[batch*h1*w1, dim, h2, w2])
self.corr_pyramid.append(corr)
for i in range(self.num_levels-1):
corr = F.avg_pool2d(corr, 2, stride=2)
self.corr_pyramid.append(corr)
def __call__(self, coords):
r = self.radius
coords = paddle.transpose(coords, perm=[0, 2, 3, 1])
batch, h1, w1, _ = coords.shape
out_pyramid = []
for i in range(self.num_levels):
corr = self.corr_pyramid[i]
# linspace为线性等分 r为搜索半径
dx = paddle.linspace(-r, r, 2*r+1)
dy = paddle.linspace(-r, r, 2*r+1)
delta = paddle.stack(paddle.meshgrid(dy, dx), axis=-1)
centroid_lvl = paddle.reshape(coords, shape=[batch*h1*w1, 1, 1, 2]) / 2**i
delta_lvl = paddle.reshape(delta, shape=[1, 2*r+1, 2*r+1, 2])
coords_lvl = centroid_lvl + delta_lvl
corr = bilinear_sampler(corr, coords_lvl)
corr = paddle.reshape(corr, shape=[batch, h1, w1, -1])
out_pyramid.append(corr)
out = paddle.concat(out_pyramid, axis=-1)
return paddle.transpose(out, perm=[0, 3, 1, 2]).astype('float32')
# transpose、permute 操作虽然没有修改底层一维数组,但是新建了一份Tensor元信息,并在新的元信息中的重新指定stride。
@staticmethod
def corr(fmap1, fmap2):
batch, dim, ht, wd = fmap1.shape
# 修改tensor的形状
fmap1 = paddle.reshape(fmap1, shape=[batch, dim, ht*wd])
fmap2 = paddle.reshape(fmap2, shape=[batch, dim, ht*wd])
corr = paddle.matmul(paddle.transpose(fmap1, perm=[0,2,1]), fmap2)
corr = paddle.reshape(corr, shape=[batch, ht, wd, 1, ht, wd])
# 归一化
return corr / paddle.sqrt(paddle.to_tensor(float(dim)))
为何要进行这样计算?有2个方面原因:
进行这样的计算可以找到前一张图片和后一张图片的像素点之间的联系;
这种相关信息张量可以保证同时捕捉到较大和较小的像素位移。
更新迭代
最开始,将flow初始化为0;
更新当前flow:flow = flow + △flow。
每次迭代计算△flow的流程为:
根据本次迭代计算出来的△flow,更新当前的flow后得出本次迭代的flow 。这里得到的flow的分辨率还是原图的1/8,所以再通过上采样得出跟原图同分辨率的flow。后面会用这个flow来计算loss。
RAFT模型创造性的引入GRU作为迭代的主体,成为了很长一段时间内光流估计流域的通用架构。GRU是LSTM网络的一种效果很好的变体,它较LSTM网络的结构更加简单,而且效果也很好,因此也是当前非常流行的一种网络。GRU既然是LSTM的变体,因此也是可以解决RNN网络中的长依赖问题。GRU的参数较少,因此训练速度更快,GRU能够降低过拟合的风险。但是在RAFT训练过程中迭代了12次,依然是耗费了大量的计算资源。
class SepConvGRU(nn.Layer):
def __init__(self, hidden_dim=128, input_dim=192+128):
super(SepConvGRU, self).__init__()
self.convz1 = nn.Conv2D(hidden_dim+input_dim, hidden_dim, (1,5), padding=(0,2))
self.convr1 = nn.Conv2D(hidden_dim+input_dim, hidden_dim, (1,5), padding=(0,2))
self.convq1 = nn.Conv2D(hidden_dim+input_dim, hidden_dim, (1,5), padding=(0,2))
self.convz2 = nn.Conv2D(hidden_dim+input_dim, hidden_dim, (5,1), padding=(2,0))
self.convr2 = nn.Conv2D(hidden_dim+input_dim, hidden_dim, (5,1), padding=(2,0))
self.convq2 = nn.Conv2D(hidden_dim+input_dim, hidden_dim, (5,1), padding=(2,0))
def forward(self, h, x):
# horizontal
hx = paddle.concat([h, x], axis=1)
z = F.sigmoid(self.convz1(hx))
r = F.sigmoid(self.convr1(hx))
q = F.tanh(self.convq1(paddle.concat([r*h, x], axis=1)))
h = (1-z) * h + z * q
# vertical
hx = paddle.concat([h, x], axis=1)
z = F.sigmoid(self.convz2(hx))
r = F.sigmoid(self.convr2(hx)) # 在v1版本中,本行的convr2被写成convz2!
q = F.tanh(self.convq2(paddle.concat([r*h, x], axis=1)))
h = (1-z) * h + z* q
return h
训练策略
# --------------------------Hyperparameter begin----------------------------------------
num_steps =
120000
# 训练次数
batch_size =
16
# 一批训练数量
gamma =
0.
85
# 这个是求损失用到的gamma,官方默认是0.85
max_flow =
400
# 像素移动的最大值,超过最大值则忽略不计
num_workers =
4
# DataLoader读取数据的进程
learning_rate =
0.
00040
# 学习率
log_iter =
100
# 每训练log_iter次打印一次日志
VAL_FREQ =
2500
# 每训练VAL_FREQ次验证一次
log = Logger(
'test.txt', batch_size)
# 日志文件的名字,位置是work/log
warmup_proportion =
0.
3
# 学习率策略:线性热启动+线性衰减
polynomial_lr = paddle.optimizer.lr.PolynomialDecay(learning_rate=learning_rate, decay_steps=
int((
1-warmup_proportion)*num_steps) +
100, end_lr = learning_rate /
10000)
scheduler = paddle.optimizer.lr.LinearWarmup(learning_rate=polynomial_lr, warmup_steps=
int(warmup_proportion*num_steps), start_lr =
0.
00001, end_lr=learning_rate)
# 优化器:AdamW
optimizer = paddle.optimizer.AdamW(learning_rate=scheduler, weight_decay=
0.
00001, epsilon=
1e-
8, parameters=model.parameters())
# --------------------------Hyperparameter end---------------------------------------
总结
目前基于深度学习的光流估计算法,都使用了大规模的数据集,包括FlyingThings、FlyingChairs等合成数据集,KITTI、Sintel等真实数据集,但是由于AI Studio的存储空间、训练时间有限,所以我在本项目中只使用了FlyingChairs数据集,所以目前的模型在处理真实数据集时还有提升的空间。
推荐使用AI Studio的V100 32G环境训练,如果是16G环境,需要调低batchsize,调低lr,增加num_steps。
参考文献
[5].Sun, D., et al. (2021). Autoflow: Learning a better training set for optical flow. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.
WAVE SUMMIT⁺2022
WAVE SUMMIT⁺2022将于11月30日在深圳举办,欢迎大家扫码关注飞桨公众号,回复WAVE提前加入官方社群了解详情。
【WAVE SUMMIT⁺2022报名入口】


