

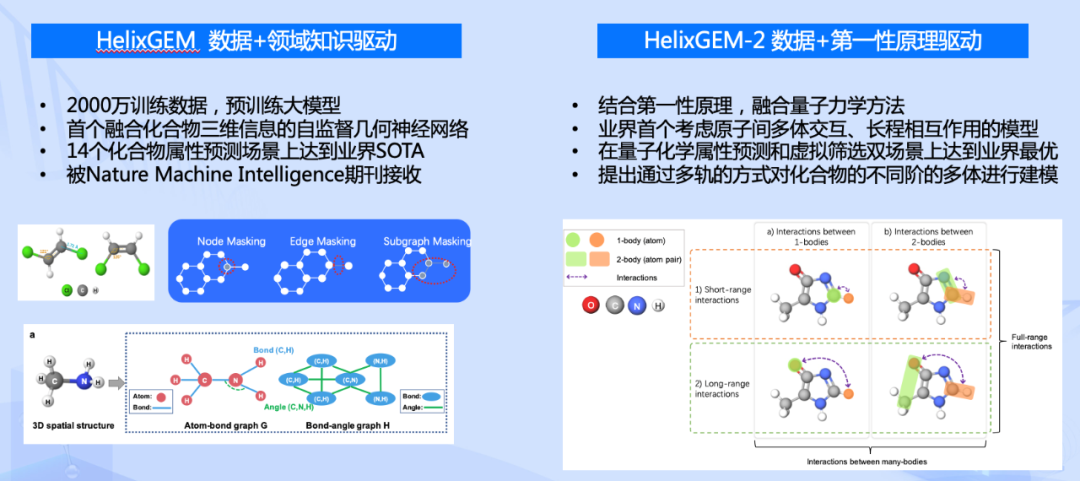
单纯数据驱动的模型构建方式已不足以支撑生物计算领域的技术创新,百度飞桨螺旋桨团队发布第一性原理启发的化合物表征大模型HelixGEM-2,首次提出基于长程多体交互的分子建模新技术,同时刷新大规模量子化学属性预测任务及虚拟筛选任务,显示出其在药物研发领域的巨大应用潜力。
今年2月,百度飞桨螺旋桨团队在《Nature》旗下子刊 《Machine Intelligence》上发表了题为《Geometry Enhanced Molecular Representation Learning for Property Prediction》的文章,首次将化合物的空间结构信息引入到大规模的预训练模型中,在下游十多项的药物属性预测任务中取得SOTA,即HelixGEM模型。HelixGEM 从数据驱动的角度出发,使用千万级别的化合物数据进行预训练,并设计基于几何构象的自监督学习任务,使得模型具备推理化合物三维空间结构的能力。

相关链接
https://arxiv.org/abs/2208.05863
开源地址
核心创新点1
多体长程关系的基础建模
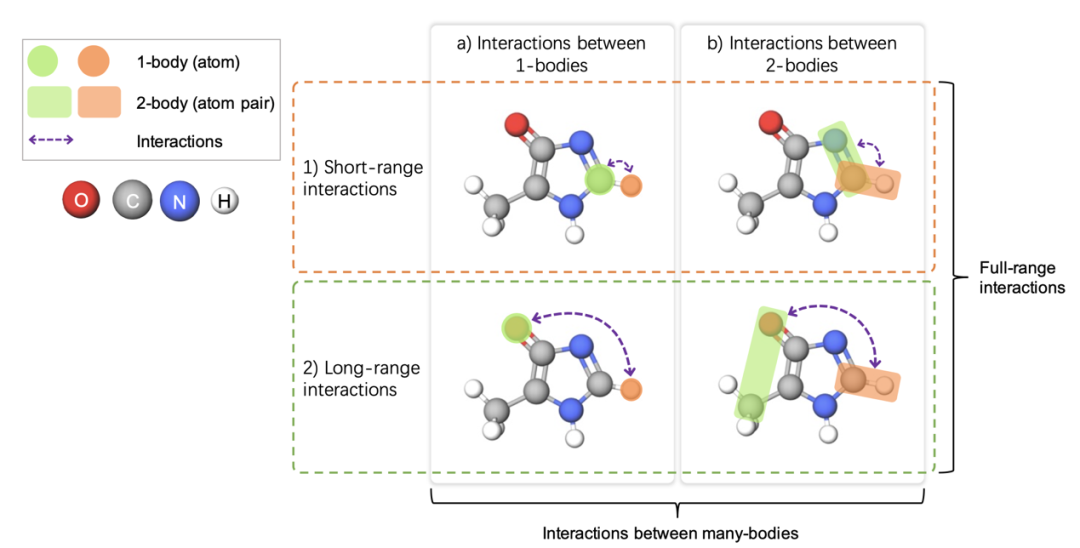
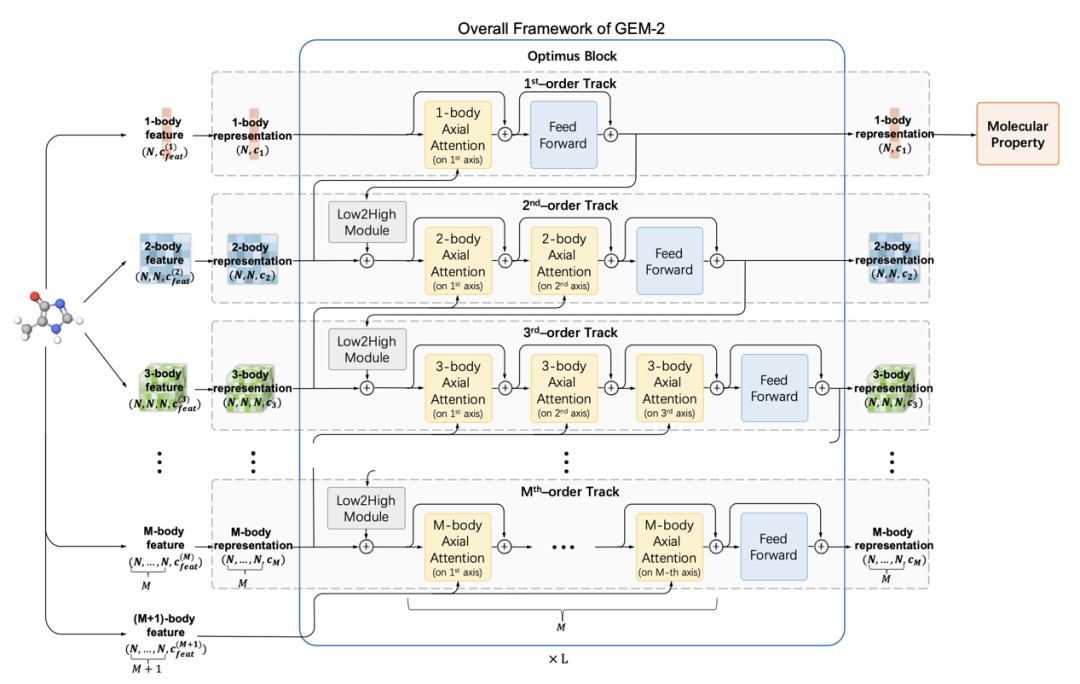
化合物中的多个原子作为一个整体可看作是一个多体,而多体之间的关系建模已被量子力学的方法证明其重要性。一个化合物被表示为多个高阶张量,分别表示单体(1-body),双体(2-body),三体(3-body),…,的表征。HelixGEM-2的网络中包含多个轨道(track),每个轨道分别学习同阶的多体之间的长程关系,并更新相应的表征。此外,不同阶的多体的信息亦可跨轨道进行相互间的传输,进一步提升建模的效果。
核心创新点2
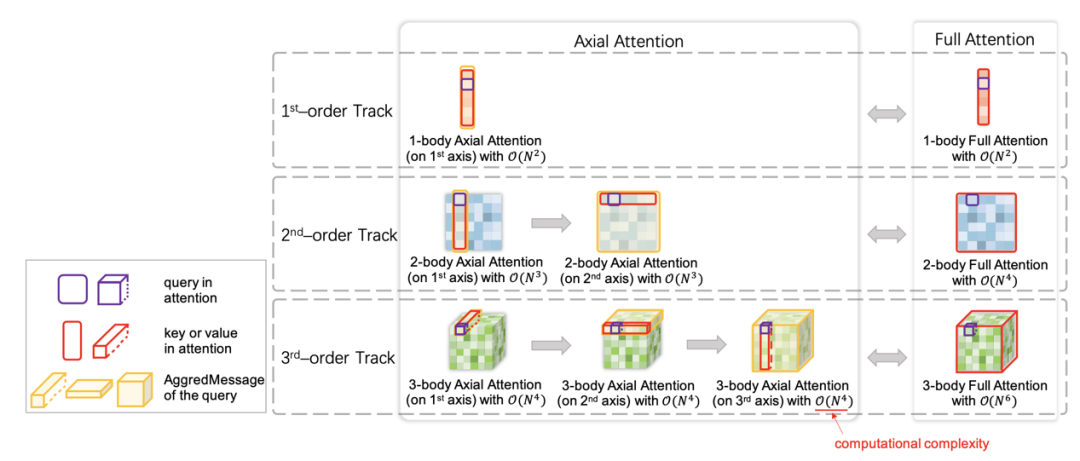
多体长程建模的加速
结果
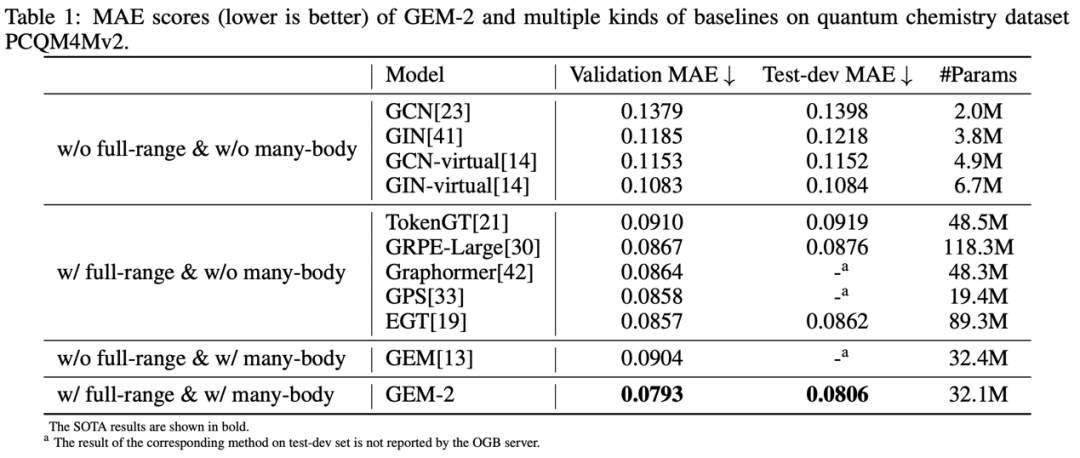
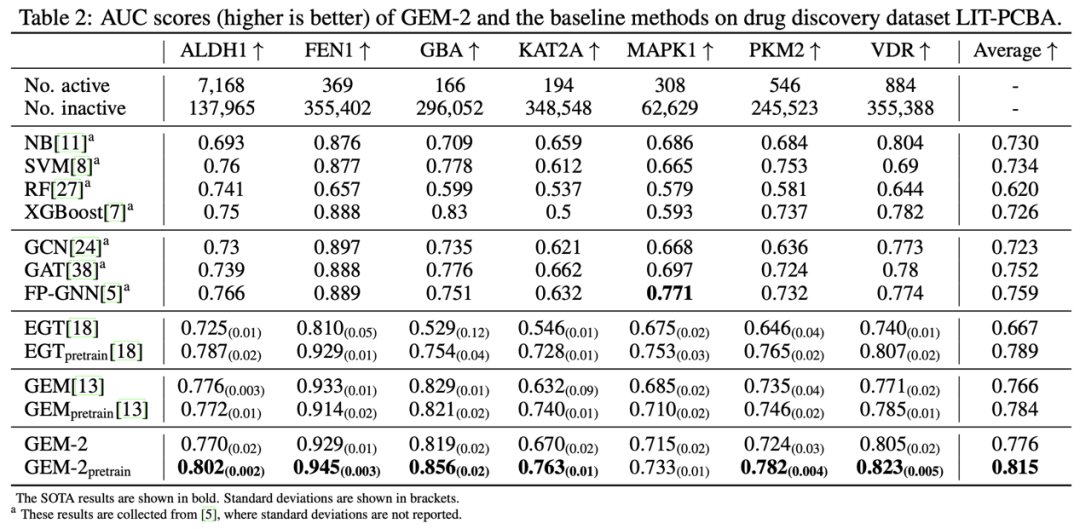
更多信息可访问
https://paddlehelix.baidu.com/
https://github.com/PaddlePaddle/PaddleHelix
WAVE SUMMIT+2022
WAVE SUMMIT+2022将于11月30日在深圳举办,欢迎大家扫码关注飞桨公众号,回复WAVE提前加入官方社群了解详情。
【WAVE SUMMIT+2022报名入口】

单纯数据驱动的模型构建方式已不足以支撑生物计算领域的技术创新,百度飞桨螺旋桨团队发布第一性原理启发的化合物表征大模型HelixGEM-2,首次提出基于长程多体交互的分子建模新技术,同时刷新大规模量子化学属性预测任务及虚拟筛选任务,显示出其在药物研发领域的巨大应用潜力。
今年2月,百度飞桨螺旋桨团队在《Nature》旗下子刊 《Machine Intelligence》上发表了题为《Geometry Enhanced Molecular Representation Learning for Property Prediction》的文章,首次将化合物的空间结构信息引入到大规模的预训练模型中,在下游十多项的药物属性预测任务中取得SOTA,即HelixGEM模型。HelixGEM 从数据驱动的角度出发,使用千万级别的化合物数据进行预训练,并设计基于几何构象的自监督学习任务,使得模型具备推理化合物三维空间结构的能力。
相关链接
https://arxiv.org/abs/2208.05863
开源地址
核心创新点1
多体长程关系的基础建模
化合物中的多个原子作为一个整体可看作是一个多体,而多体之间的关系建模已被量子力学的方法证明其重要性。一个化合物被表示为多个高阶张量,分别表示单体(1-body),双体(2-body),三体(3-body),…,的表征。HelixGEM-2的网络中包含多个轨道(track),每个轨道分别学习同阶的多体之间的长程关系,并更新相应的表征。此外,不同阶的多体的信息亦可跨轨道进行相互间的传输,进一步提升建模的效果。
核心创新点2
多体长程建模的加速
结果
更多信息可访问
https://paddlehelix.baidu.com/
https://github.com/PaddlePaddle/PaddleHelix
WAVE SUMMIT+2022
WAVE SUMMIT+2022将于11月30日在深圳举办,欢迎大家扫码关注飞桨公众号,回复WAVE提前加入官方社群了解详情。
【WAVE SUMMIT+2022报名入口】
