


你还在头疼于经典模型的复现吗?
不知何处可以得到全面可参照的Benchmark?
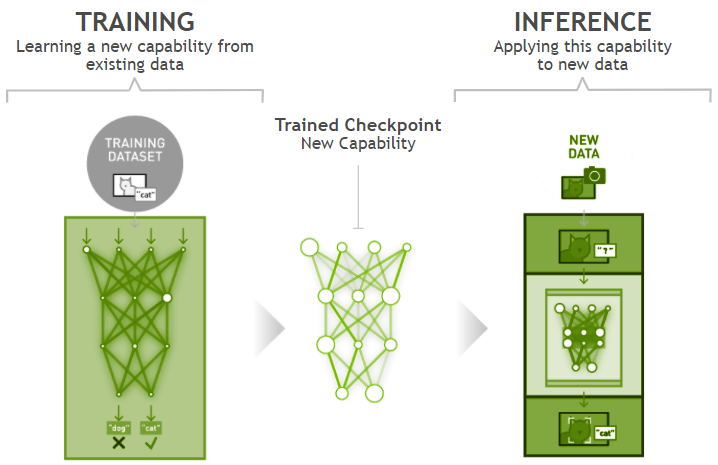
全新上线飞桨ResNet50
NVIDIA Deep Learning Examples仓库上线了基于飞桨实现的ResNet50模型的性能优化结果,该示例全面适配各类NVIDIA GPU和各种硬件拓扑(单机单卡、单机多卡),性能极致优化。值得一提的是,Deep Learning Examples中飞桨ResNet50模型训练速度已超过对应的PyTorch版ResNet50。
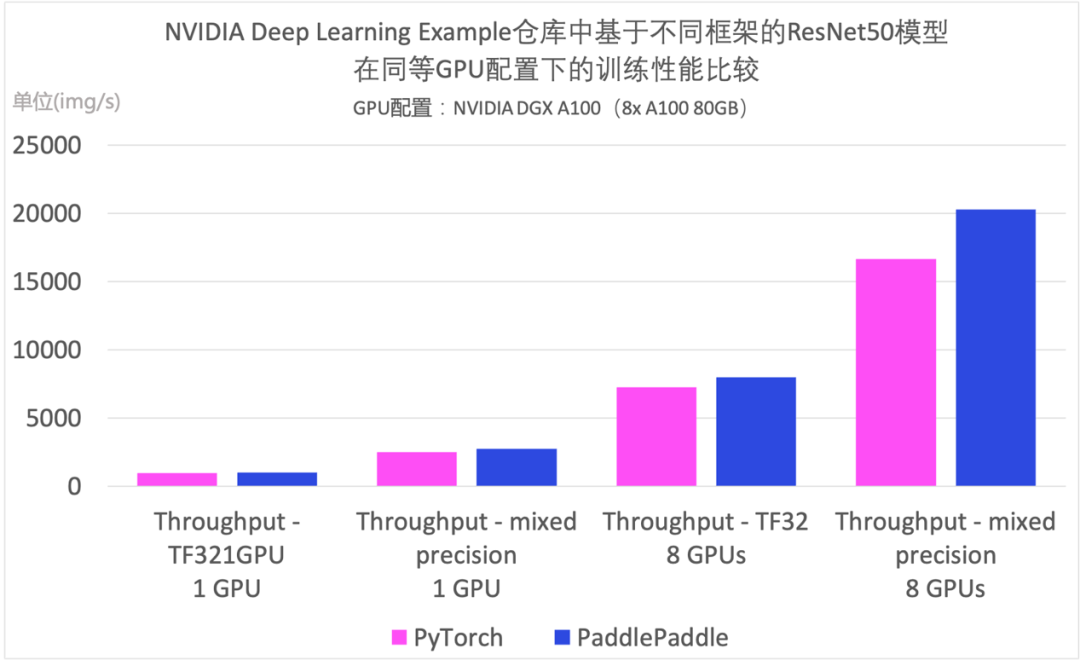
图2: NVIDIA Deep Learning Examples仓库中基于飞桨与PyTorch的ResNet50模型在同等GPU配置下的训练性能比较,GPU配置为NVIDIA DGX A100(8x A100 80GB)。 *数据来源:[1][2]
优势二:通过使用AMP、ASP等工具,提高推理性能
优势三:通过集成TensorRT,优化推理模型
训练精度结果
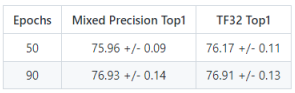
图3:训练精度:
NVIDIA DGX A100 (8x A100 80GB) 数据来源:[1]

NVIDIA DGX A100 (8x A100 80GB) 数据来源:[1]
训练性能结果


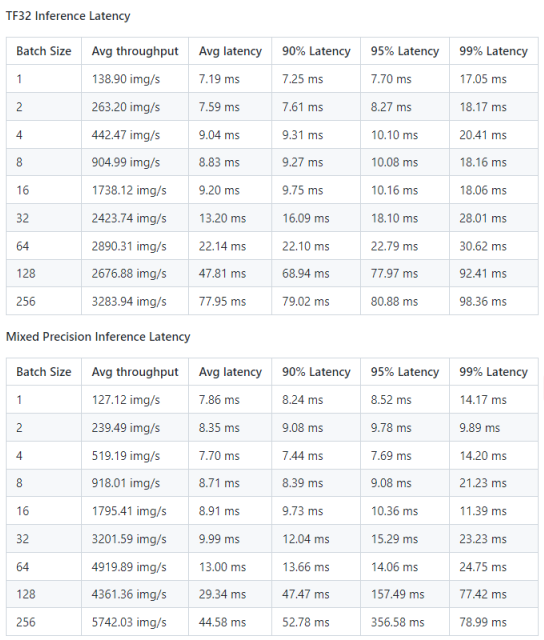
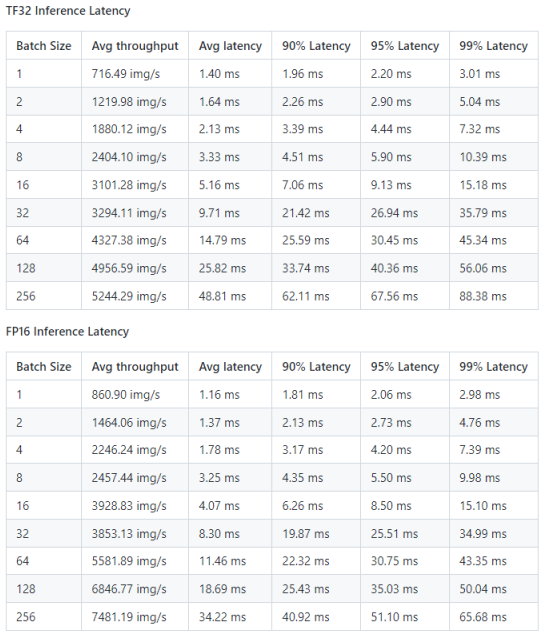
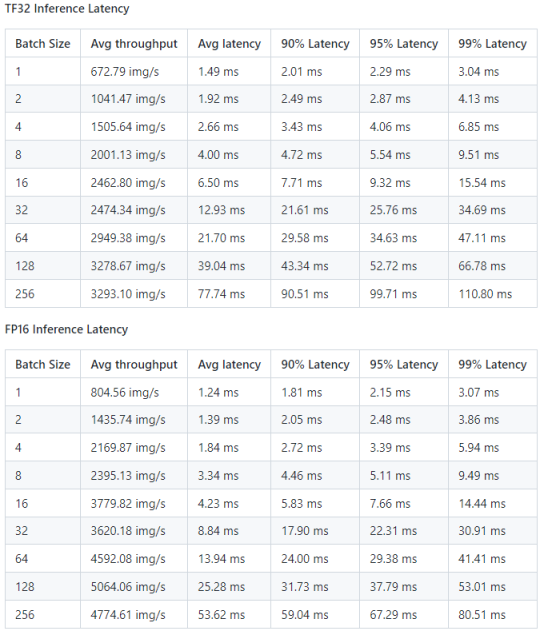
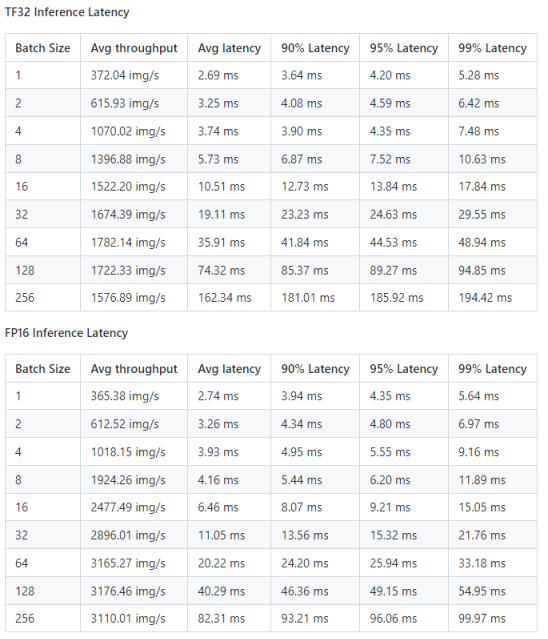
推理性能结果
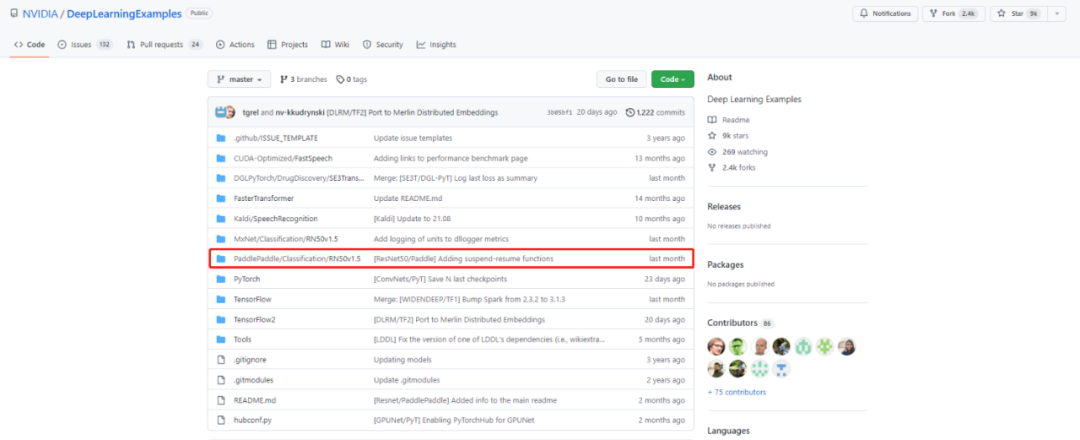
仓库中的飞桨ResNeT50?
登录GitHub NVIDIA Deep Learning Examples仓库后,找到下列选项下载模型源代码即可。
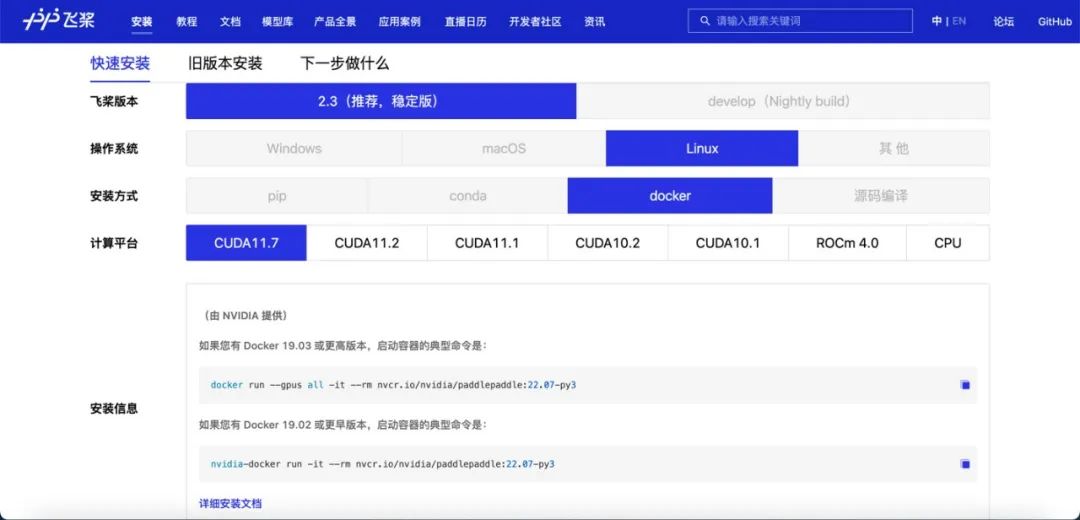
参考《NGC飞桨容器安装指南》下载安装:
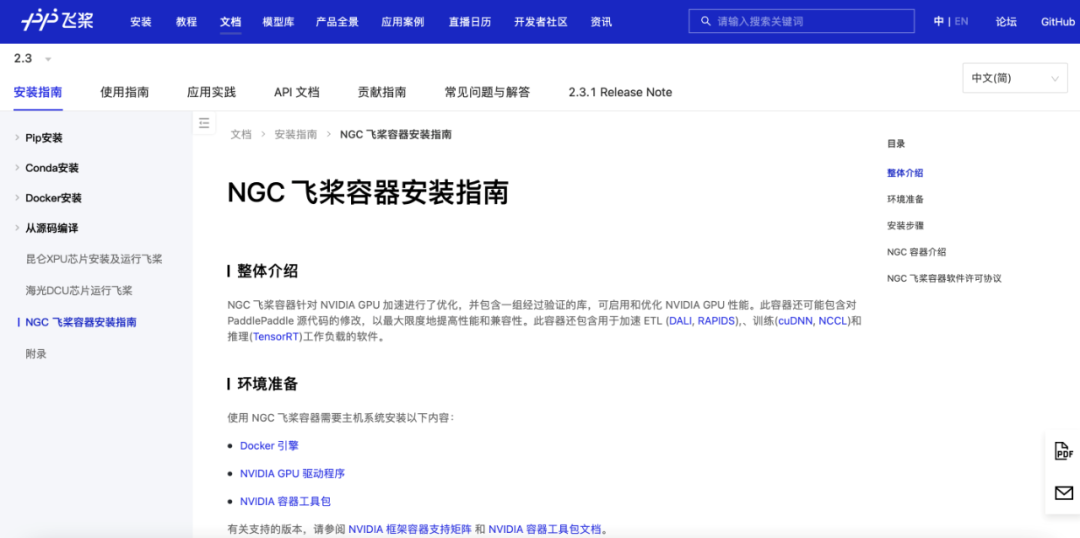
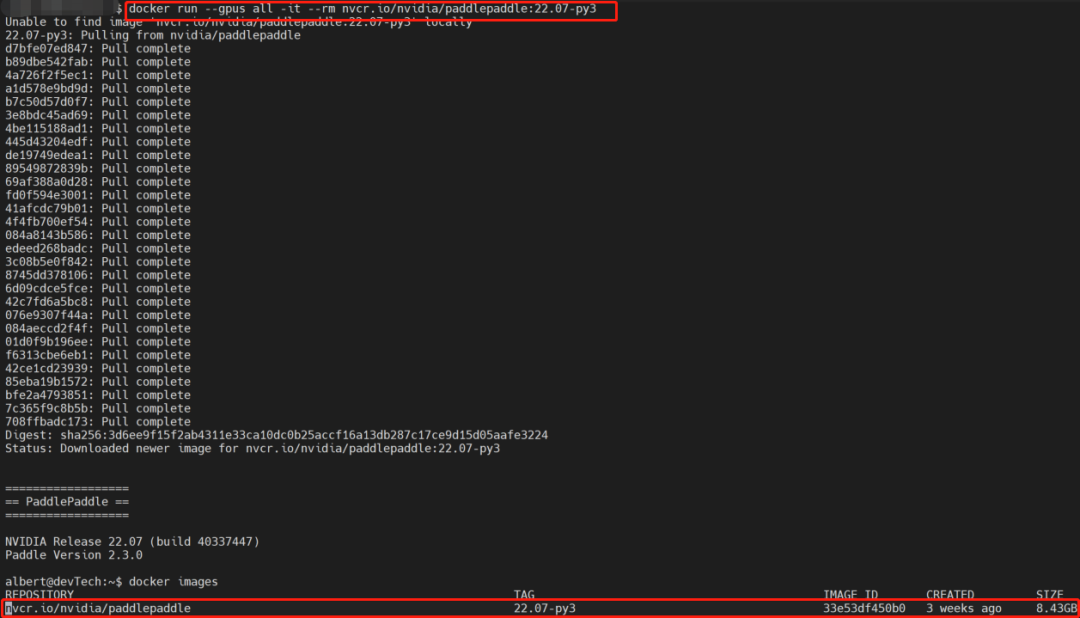
NVIDIA飞桨容器现已开放免费下载,点击“阅读原文”跳转至飞桨官网《NGC飞桨容器安装指南》页面可获取安装指南。同时,您可扫描下方二维码加入用户体验群,提交体验报告将获得更多精美礼品!
参考资料
https://github.com/NVIDIA/DeepLearningExamples/tree/master/PaddlePaddle/Classification/RN50v1.5
拓展阅读
揭秘!MLPerf Training v2.0飞桨何以力压NGC PyTorch,实现同等GPU配置BERT模型训练性能第一
你还在头疼于经典模型的复现吗?
不知何处可以得到全面可参照的Benchmark?
全新上线飞桨ResNet50
NVIDIA Deep Learning Examples仓库上线了基于飞桨实现的ResNet50模型的性能优化结果,该示例全面适配各类NVIDIA GPU和各种硬件拓扑(单机单卡、单机多卡),性能极致优化。值得一提的是,Deep Learning Examples中飞桨ResNet50模型训练速度已超过对应的PyTorch版ResNet50。
图2: NVIDIA Deep Learning Examples仓库中基于飞桨与PyTorch的ResNet50模型在同等GPU配置下的训练性能比较,GPU配置为NVIDIA DGX A100(8x A100 80GB)。 *数据来源:[1][2]
优势二:通过使用AMP、ASP等工具,提高推理性能
优势三:通过集成TensorRT,优化推理模型
训练精度结果
图3:训练精度:
NVIDIA DGX A100 (8x A100 80GB) 数据来源:[1]
NVIDIA DGX A100 (8x A100 80GB) 数据来源:[1]
训练性能结果
推理性能结果
仓库中的飞桨ResNeT50?
登录GitHub NVIDIA Deep Learning Examples仓库后,找到下列选项下载模型源代码即可。
参考《NGC飞桨容器安装指南》下载安装:
NVIDIA飞桨容器现已开放免费下载,点击“阅读原文”跳转至飞桨官网《NGC飞桨容器安装指南》页面可获取安装指南。同时,您可扫描下方二维码加入用户体验群,提交体验报告将获得更多精美礼品!
参考资料
https://github.com/NVIDIA/DeepLearningExamples/tree/master/PaddlePaddle/Classification/RN50v1.5
拓展阅读
揭秘!MLPerf Training v2.0飞桨何以力压NGC PyTorch,实现同等GPU配置BERT模型训练性能第一
