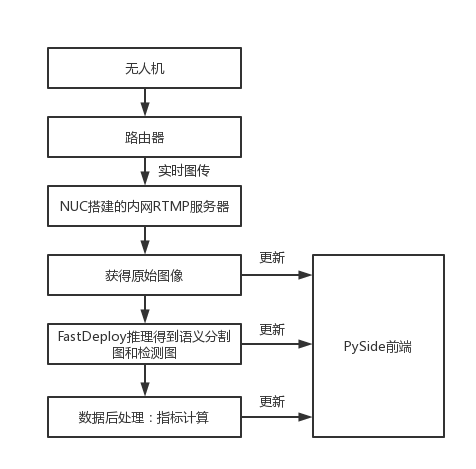
本任务是对无人机图像数据流的实时推理,对推理速度有极高的要求。同时为了减少开发难度和迁移成本,我们采用了X86 CPU架构的英特尔NUC迷你电脑套件作为推理硬件,软件选择了FastDeploy推理部署工具箱快速开发后端OpenVINO推理引擎,加速AI模型推理。此外,在AI模型选择上,我们分别选择了飞桨PP-LiteSeg和飞桨PP-YOLO Tiny两个轻量化模型来完成语义分割和目标检测任务。
如上图所示,首先需要在NUC上架设RTMP推流服务,无人机APP客户端连接内网RTMP服务器,实现无人机的图像实时通过路由器向NUC设备传输。NUC设备端获得图像后,渲染至PySide前端的显示窗口,同时FastDeploy线程执行语义分割和目标检测的推理任务,并把结果和可视化图像实时渲染至前端窗口。
核心软硬件
英特尔NUC迷你电脑套件
(型号:NUC8i5BEH)
FastDeploy >= 0.2.1
PaddleDetection >= 2.5
PaddleSeg >= 2.6
大疆系列无人机及DJI Fly APP
路由器(用于内网RTMP传输)

英特尔NUC迷你电脑硬件
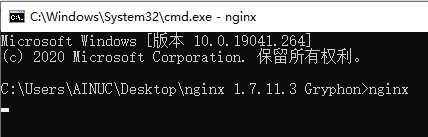
英特尔NUC预装的操作系统是Windows10,所以可以直接下载带RTMP模块的Nginx。
下载链接
worker_processes
1;
events {
worker_connections
1024;
}
rtmp {
server {
listen
8899;
chunk_size
4000;
application live {
live
on;
allow publish all;
allow play all;
}
}
}
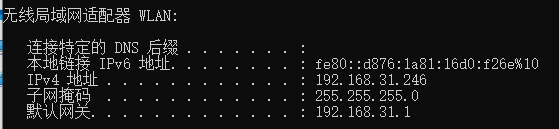
此时,我们需要在cmd命令行输入ipconfig命令查询NUC设备的内网IPv4地址。
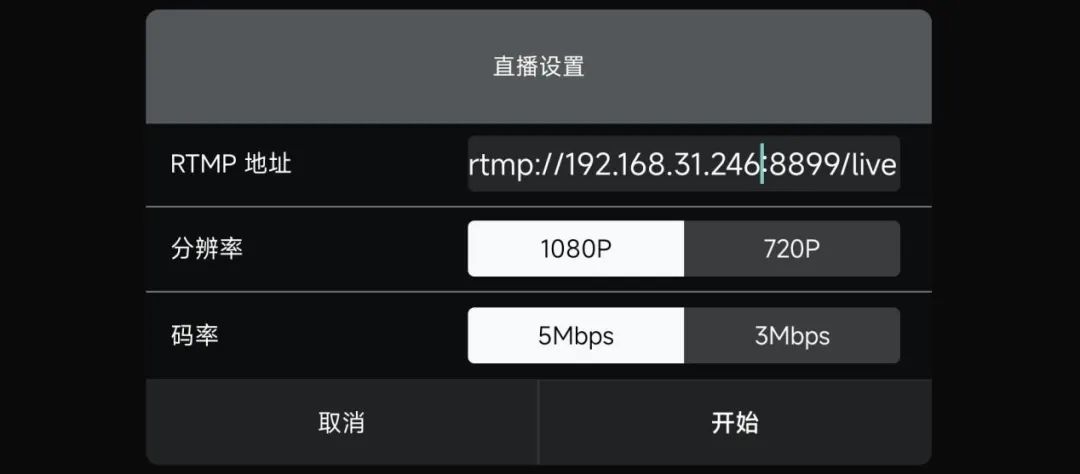
APP推流配置完成之后,可以在NUC设备端调用OpenCV的API进行拉流操作以获取无人机实时画面,Python实现代码如下。
import cv2
rtmpUrl = 'rtmp://192.168.31.246:8899/live'
vid = cv2.VideoCapture(rtmpUrl)
while vid.isOpened():
ret,frame = vid.read()
cv2.imshow('RTMP Test',frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
vid.release()
cv2.destroyAllWindows()
打通了无人机图像实时传输的环节之后,我们进入核心的推理部署环节。由以上Python代码可以看出,RTMP数据流经过OpenCV解码后得到图像帧 (frame),因此推理环节的工作本质就是将每一帧图像输入模型然后得到结果并将输出结果可视化。本环节主要分为三个步骤:模型动静转换、推理脚本编写和前端集成。
首先,我们需要把使用PaddleSeg和PaddleDetection开发套件训练好的动态图模型转换成静态图模型,这一步利用两个套件分别提供的脚本即可简单完成。已经训练好的动态图模型可以在AI Studio项目中获取。
语义分割目标检测动态图模型和语义分割分别在AI Studio项目中ppyolo_inference_model和output_ppliteseg_stdc1/best_model/目录下,分别调用对应的动静转换脚本将两个动态图模型转换成静态图。
python PaddleSeg/export.py \
--config ppliteseg_stdc1.yml \ #配置文件路径,根据实际情况修改
--model_path output_ppliteseg_stdc1/best_model/model.pdparams \
# 动态图模型路径,根据实际情况修改
--save_dir inference_ppliteseg_stdc1 \ # 导出目录
--input_shape 1 3 512 1024 #模型输入尺寸
PaddleDetection
python PaddleDetection/tools/export_model.py \
-c PaddleDetection/configs/ppyolo/ppyolo_tiny_650e_coco.yml \ # 配置文件路径,根据实际情况修改
--output_dir=./ppyolo_inference_model \ # 保存模型的路径
-o weights=ppyolo_tiny_650e_coco.pdparams # 动态图模型路径
注:模型转换的详细教程可参考
https://github.com/PaddlePaddle/PaddleSeg/blob/release/2.6/docs/model_export_cn.md
链接
import cv2
import numpy as np
import fastdeploy as fd
from PIL import Image
from collections import Counter
def FastdeployOption(device=0):
option = fd.RuntimeOption()
if device == 0:
option.use_gpu()
else:
# 使用OpenVino推理
option.use_openvino_backend()
option.use_cpu()
return option
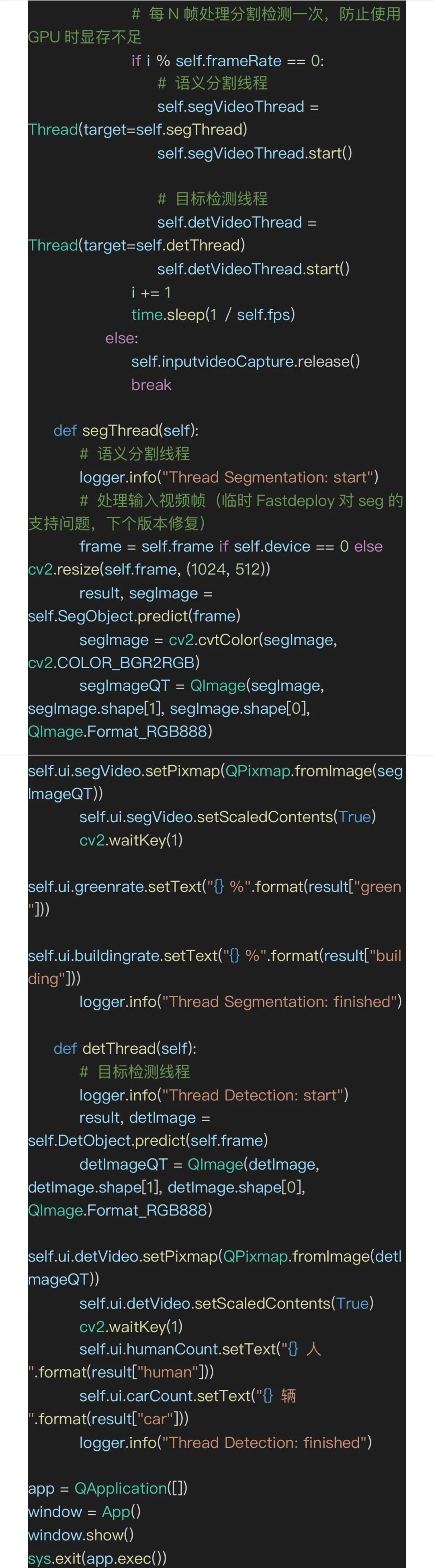
然后,将语义分割模型推理代码封装成一个类,方便前端快速调用。在init方法中,直接调用了SegModel()函数进行模型初始化(热加载),通过SegModel.predict()完成结果的推理,得到推理结果之后执行postprocess()对结果进行解析,提取建筑和绿地的像素数量,统计图像占比,得到环境要素的占比结果。最后调用FastDeploy内置的vis_segmentation()可视化函数,对推理结果进行可视化。
class SegModel(object):
def __init__(self, device=0) -> None:
self.segModel = fd.vision.segmentation.ppseg.PaddleSegModel(
model_file = 'inference/ppliteseg/model.pdmodel',
params_file = 'inference/ppliteseg/model.pdiparams',
config_file = 'inference/ppliteseg/deploy.yaml',
runtime_option=FastdeployOption(device)
)
def predict(self, img):
segResult = self.segModel.predict(img)
result = self.postprocess(segResult)
visImg = fd.vision.vis_segmentation(img, segResult)
return result, visImg
def postprocess(self, result):
resultShape = result.shape
labelmap = result.label_map
labelmapCount = dict(Counter(labelmap))
pixelTotal = int(resultShape[0] * resultShape[1])
# 统计建筑率和绿地率
buildingRate, greenRate = 0, 0
if 8 in labelmapCount:
buildingRate = round(labelmapCount[8] / pixelTotal* 100, 3)
if 9 in labelmapCount:
greenRate = round(labelmapCount[9] / pixelTotal * 100 , 3)
return {"building": buildingRate, "green": greenRate}
class DetModel(object):
def __init__(self, device=0) -> None:
self.detModel = fd.vision.detection.PPYOLO(
model_file = 'inference/ppyolo/model.pdmodel',
params_file = 'inference/ppyolo/model.pdiparams',
config_file = 'inference/ppyolo/infer_cfg.yml',
runtime_option=FastdeployOption(device)
)
# 阈值设置
self.threshold = 0.3
def predict(self, img):
detResult = self.detModel.predict(img.copy())
result = self.postprocess(detResult)
visImg = fd.vision.vis_detection(img, detResult, self.threshold, 2)
return result, visImg
def postprocess(self, result):
# 得到结果
detIds = result.label_ids
detScores = result.scores
# 统计数量
humanNum, CarNum = 0, 0
for i in range(len(detIds)):
if detIds[i] == 0 and detScores[i] >= self.threshold:
humanNum += 1
if detIds[i] == 2 and detScores[i] >= self.threshold:
CarNum += 1
return {"human": humanNum, "car": CarNum}
把PP-LiteSeg语义分割模型和PP-YOLO Tiny目标检测模型封装成类之后,保存为inferEngine.py文件,以供后续前端代码调用。
前端开发使用的是PySide6,界面源代码可在文章最后的Github项目链接中获取。整体而言开发难度不大,主要的难点在于三个视频播放的组件同时更新导致的程序卡死或者延时问题。
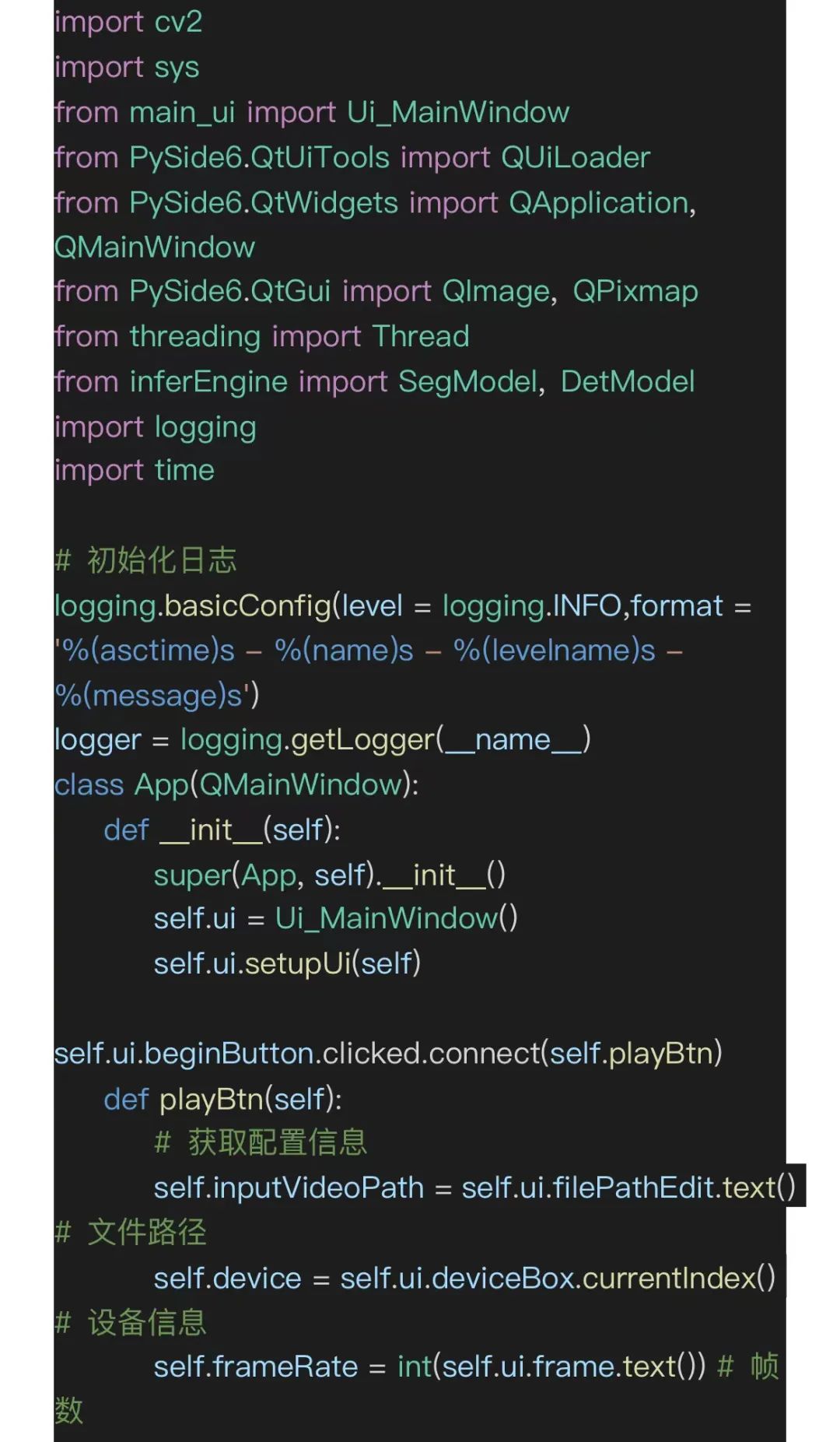
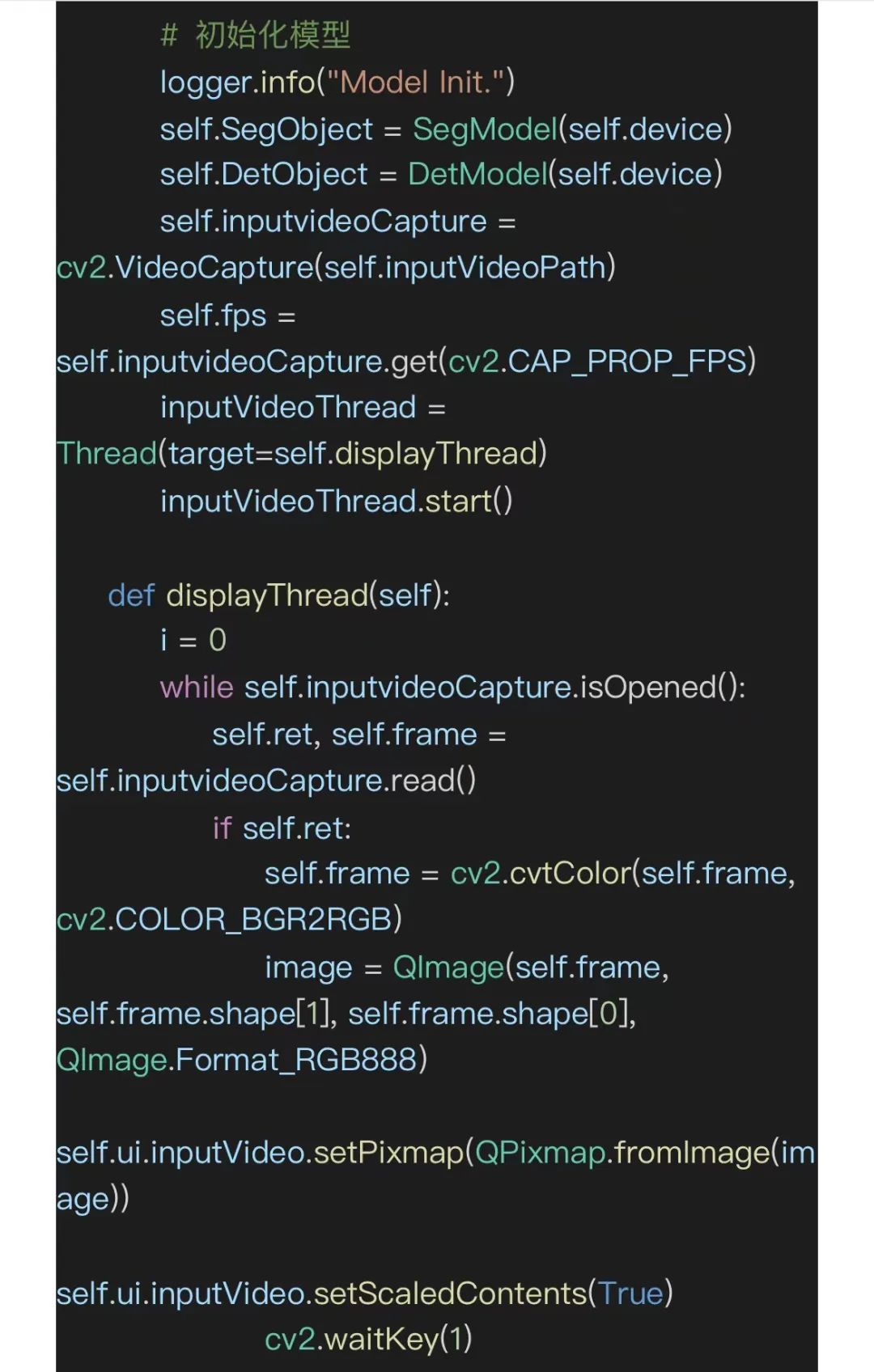
在本项目中应用的解决方法是用多线程,把三个视频播放组件的后端分开三个独立的线程,一个线程(displayThread)把实时视频流原画推送到前端更新,另外两个线程(segThread和detThread)同步完成语义分割和目标检测推理实时视频帧图像并将后处理之后的推理结果图像更新到前端组件上。具体代码如下所示(main.py)。
向下滑动查看所有内容
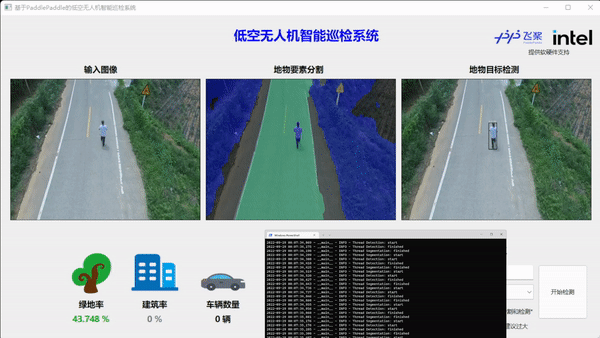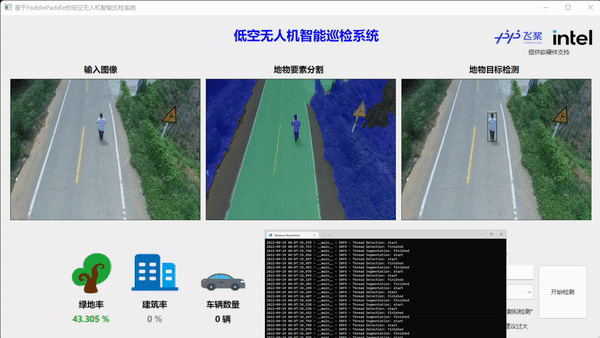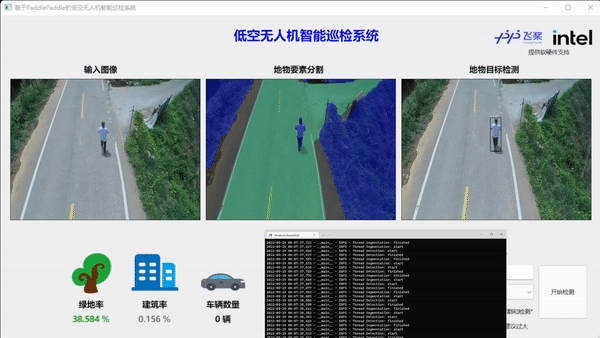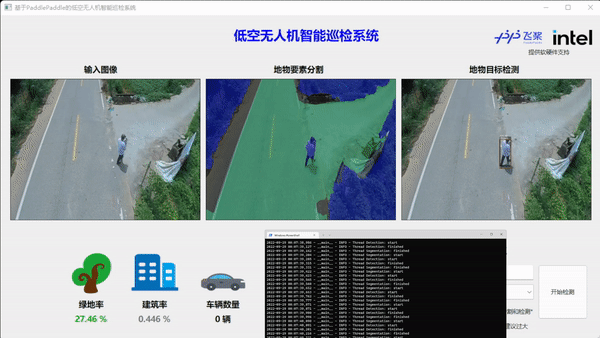
最后执行python main.py运行程序,查看推理效果。
FastDeploy是一个帮助开发者快速部署深度学习模型的推理部署工具箱,内置了包括OpenVINO、TensorRT、ONNX Runtime、Paddle Inference后端,正在集成Paddle Lite、RKNN等推理后端。并对各后端进行了针对性的优化,很好地兼容了英特尔NUC迷你主机的硬件,无需另外安装OpenVINO套件和配置环境,同时也免去了调优提速的烦恼,降低了开发者的学习成本和部署成本,提高了部署开发效率。目前已经支持包括飞桨等生态60+热门模型。更多AI模型的推理部署,可前往FastDeploy的GitHub了解。
往期精彩

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~
本任务是对无人机图像数据流的实时推理,对推理速度有极高的要求。同时为了减少开发难度和迁移成本,我们采用了X86 CPU架构的英特尔NUC迷你电脑套件作为推理硬件,软件选择了FastDeploy推理部署工具箱快速开发后端OpenVINO推理引擎,加速AI模型推理。此外,在AI模型选择上,我们分别选择了飞桨PP-LiteSeg和飞桨PP-YOLO Tiny两个轻量化模型来完成语义分割和目标检测任务。
如上图所示,首先需要在NUC上架设RTMP推流服务,无人机APP客户端连接内网RTMP服务器,实现无人机的图像实时通过路由器向NUC设备传输。NUC设备端获得图像后,渲染至PySide前端的显示窗口,同时FastDeploy线程执行语义分割和目标检测的推理任务,并把结果和可视化图像实时渲染至前端窗口。
核心软硬件
英特尔NUC迷你电脑套件
(型号:NUC8i5BEH)
FastDeploy >= 0.2.1
PaddleDetection >= 2.5
PaddleSeg >= 2.6
大疆系列无人机及DJI Fly APP
路由器(用于内网RTMP传输)
英特尔NUC迷你电脑硬件
英特尔NUC预装的操作系统是Windows10,所以可以直接下载带RTMP模块的Nginx。
下载链接
worker_processes
1;
events {
worker_connections
1024;
}
rtmp {
server {
listen
8899;
chunk_size
4000;
application live {
live
on;
allow publish all;
allow play all;
}
}
}
此时,我们需要在cmd命令行输入ipconfig命令查询NUC设备的内网IPv4地址。
APP推流配置完成之后,可以在NUC设备端调用OpenCV的API进行拉流操作以获取无人机实时画面,Python实现代码如下。
import cv2
rtmpUrl = 'rtmp://192.168.31.246:8899/live'
vid = cv2.VideoCapture(rtmpUrl)
while vid.isOpened():
ret,frame = vid.read()
cv2.imshow('RTMP Test',frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
vid.release()
cv2.destroyAllWindows()
打通了无人机图像实时传输的环节之后,我们进入核心的推理部署环节。由以上Python代码可以看出,RTMP数据流经过OpenCV解码后得到图像帧 (frame),因此推理环节的工作本质就是将每一帧图像输入模型然后得到结果并将输出结果可视化。本环节主要分为三个步骤:模型动静转换、推理脚本编写和前端集成。
首先,我们需要把使用PaddleSeg和PaddleDetection开发套件训练好的动态图模型转换成静态图模型,这一步利用两个套件分别提供的脚本即可简单完成。已经训练好的动态图模型可以在AI Studio项目中获取。
语义分割目标检测动态图模型和语义分割分别在AI Studio项目中ppyolo_inference_model和output_ppliteseg_stdc1/best_model/目录下,分别调用对应的动静转换脚本将两个动态图模型转换成静态图。
python PaddleSeg/export.py \
--config ppliteseg_stdc1.yml \ #配置文件路径,根据实际情况修改
--model_path output_ppliteseg_stdc1/best_model/model.pdparams \
# 动态图模型路径,根据实际情况修改
--save_dir inference_ppliteseg_stdc1 \ # 导出目录
--input_shape 1 3 512 1024 #模型输入尺寸
PaddleDetection
python PaddleDetection/tools/export_model.py \
-c PaddleDetection/configs/ppyolo/ppyolo_tiny_650e_coco.yml \ # 配置文件路径,根据实际情况修改
--output_dir=./ppyolo_inference_model \ # 保存模型的路径
-o weights=ppyolo_tiny_650e_coco.pdparams # 动态图模型路径
注:模型转换的详细教程可参考
https://github.com/PaddlePaddle/PaddleSeg/blob/release/2.6/docs/model_export_cn.md
链接
import cv2
import numpy as np
import fastdeploy as fd
from PIL import Image
from collections import Counter
def FastdeployOption(device=0):
option = fd.RuntimeOption()
if device == 0:
option.use_gpu()
else:
# 使用OpenVino推理
option.use_openvino_backend()
option.use_cpu()
return option
然后,将语义分割模型推理代码封装成一个类,方便前端快速调用。在init方法中,直接调用了SegModel()函数进行模型初始化(热加载),通过SegModel.predict()完成结果的推理,得到推理结果之后执行postprocess()对结果进行解析,提取建筑和绿地的像素数量,统计图像占比,得到环境要素的占比结果。最后调用FastDeploy内置的vis_segmentation()可视化函数,对推理结果进行可视化。
class SegModel(object):
def __init__(self, device=0) -> None:
self.segModel = fd.vision.segmentation.ppseg.PaddleSegModel(
model_file = 'inference/ppliteseg/model.pdmodel',
params_file = 'inference/ppliteseg/model.pdiparams',
config_file = 'inference/ppliteseg/deploy.yaml',
runtime_option=FastdeployOption(device)
)
def predict(self, img):
segResult = self.segModel.predict(img)
result = self.postprocess(segResult)
visImg = fd.vision.vis_segmentation(img, segResult)
return result, visImg
def postprocess(self, result):
resultShape = result.shape
labelmap = result.label_map
labelmapCount = dict(Counter(labelmap))
pixelTotal = int(resultShape[0] * resultShape[1])
# 统计建筑率和绿地率
buildingRate, greenRate = 0, 0
if 8 in labelmapCount:
buildingRate = round(labelmapCount[8] / pixelTotal* 100, 3)
if 9 in labelmapCount:
greenRate = round(labelmapCount[9] / pixelTotal * 100 , 3)
return {"building": buildingRate, "green": greenRate}
class DetModel(object):
def __init__(self, device=0) -> None:
self.detModel = fd.vision.detection.PPYOLO(
model_file = 'inference/ppyolo/model.pdmodel',
params_file = 'inference/ppyolo/model.pdiparams',
config_file = 'inference/ppyolo/infer_cfg.yml',
runtime_option=FastdeployOption(device)
)
# 阈值设置
self.threshold = 0.3
def predict(self, img):
detResult = self.detModel.predict(img.copy())
result = self.postprocess(detResult)
visImg = fd.vision.vis_detection(img, detResult, self.threshold, 2)
return result, visImg
def postprocess(self, result):
# 得到结果
detIds = result.label_ids
detScores = result.scores
# 统计数量
humanNum, CarNum = 0, 0
for i in range(len(detIds)):
if detIds[i] == 0 and detScores[i] >= self.threshold:
humanNum += 1
if detIds[i] == 2 and detScores[i] >= self.threshold:
CarNum += 1
return {"human": humanNum, "car": CarNum}
把PP-LiteSeg语义分割模型和PP-YOLO Tiny目标检测模型封装成类之后,保存为inferEngine.py文件,以供后续前端代码调用。
前端开发使用的是PySide6,界面源代码可在文章最后的Github项目链接中获取。整体而言开发难度不大,主要的难点在于三个视频播放的组件同时更新导致的程序卡死或者延时问题。
在本项目中应用的解决方法是用多线程,把三个视频播放组件的后端分开三个独立的线程,一个线程(displayThread)把实时视频流原画推送到前端更新,另外两个线程(segThread和detThread)同步完成语义分割和目标检测推理实时视频帧图像并将后处理之后的推理结果图像更新到前端组件上。具体代码如下所示(main.py)。
向下滑动查看所有内容
最后执行python main.py运行程序,查看推理效果。
FastDeploy是一个帮助开发者快速部署深度学习模型的推理部署工具箱,内置了包括OpenVINO、TensorRT、ONNX Runtime、Paddle Inference后端,正在集成Paddle Lite、RKNN等推理后端。并对各后端进行了针对性的优化,很好地兼容了英特尔NUC迷你主机的硬件,无需另外安装OpenVINO套件和配置环境,同时也免去了调优提速的烦恼,降低了开发者的学习成本和部署成本,提高了部署开发效率。目前已经支持包括飞桨等生态60+热门模型。更多AI模型的推理部署,可前往FastDeploy的GitHub了解。
往期精彩
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~