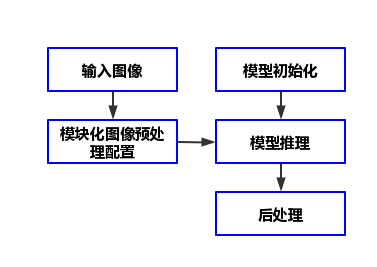
随着大数据、人工智能等数字技术在农业领域的渗透和应用,智慧农业开始从理论概念慢慢走向应用落地,我国的传统农业也逐步迈向智慧农业时代。发展智慧农业是数字乡村建设的重要内容,有助于我国破解“三农”难题,实现农业全产业链的现代化升级转型。但在AI转型实践中,农林企业往往会遇到很多技术问题,AI模型部署就是其中难度相对较高的一环。
模型部署是AI开发的“最后一公里”,但往往这最后一步成了很多产品开发团队加班加点攻关解决的难题,主要的难点有以下几个方面:
难点一:硬件产品开发需要软硬件工程师协同,同时软硬件工程师还要熟悉AI开发技术栈,本来大多数农林企业中就没有完整的人才配套,懂AI的软硬件工程师更是少之又少。
难点二:做落地的工程对AI工程师的技术栈要求高,除了要懂基础开发之外,还要熟悉模型转换、压缩、优化、部署上线等技术内容。
本文共分为四大版块:原部署方案,FastDeploy部署方案,FastDeploy+ FastAPI项目落地,总结。
https://aistudio.baidu.com/aistudio/projectdetail/4411585?contributionType=1
项目效果
ONNX Runtime
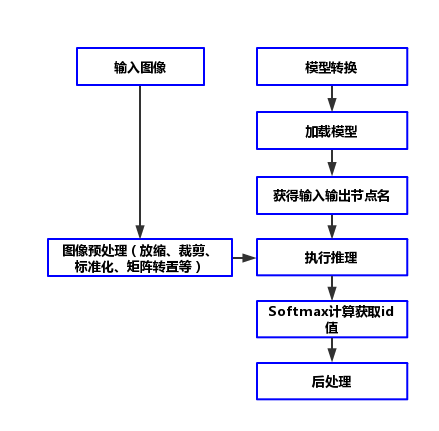
pip install paddle2onnx
pip install onnxruntimepaddle2onnx --model_dir=./inference/ \
--model_filename=inference.pdmodel \
--params_filename=inference.pdiparams \
--save_file=./onnx_model/inference.onnx \
--opset_version=10 \
--enable_onnx_checker=True推理代码
import cv2
import numpy as np
from onnxruntime import InferenceSession
model = InferenceSession('./onnx_model/inference.onnx')
input_names = model.get_inputs()[0].name
output_names = model.get_outputs()[0].name
imageInput = cv2.imread("dataset/healthy/81935a3879e1f68e.jpg")
imageInput = np.array(cv2.resize(imageInput, (224,224)))
imageInput = (imageInput/255-[0.485, 0.456, 0.406])/[0.229, 0.224, 0.225]
imageInput = imageInput[np.newaxis,:]
imageInput = imageInput.transpose([0,3,1,2])
imageInput = imageInput.astype('float32')
batch_output = model.run(
output_names=[output_names],
input_feed={input_names: imageInput})[0]
def softmax(x):
x = x.reshape(-1)
e_x = np.exp(x - np.max(x))
return e_x / e_x.sum(axis=0)
for output in batch_output:
result = softmax(np.array(output)).tolist()
idx = np.argmax(result)
print("Result:", idx)输出结果
Result:3
安装FastDeploy
# FastDeploy分CPU和GPU版本,根据设备情况选择安装其中一个即可
pip install fastdeploy-python -f https://www.paddlepaddle.org.cn/whl/fastdeploy.html
#pip install fastdeploy-gpu-python -f https://www.paddlepaddle.org.cn/whl/fastdeploy.html
推理代码
import fastdeploy as fd
import cv2
model = fd.vision.classification.PaddleClasModel(
model_file = 'inference/inference.pdmodel',
params_file = 'inference/inference.pdiparams',
config_file = 'inference.yml')
img = cv2.imread('dataset/healthy/81935a3879e1f68e.jpg')
result = model.predict(img)
print(result)输出结果
ClassifyResult(
label_ids: 3, #该标签和AI Studio项目中制作的AI数据集标签有关系,表示健康图片
scores: 0.888799,
)
我们将推理得到的label ID和labelmap映射文件对应,得到分类id映射的中文名,再将结果进行可视化。
from PIL import Image, ImageDraw, ImageFont
# 得到分类id
labelId = result.label_ids[0]
# 读取labelmap映射文件
with open("dataset/labels_chinese.txt", 'r') as o:
labelmap = o.readlines()
label = labelmap[labelId].replace('\n', '')
image = Image.fromarray(img)
vis = ImageDraw.Draw(image)
font = ImageFont.truetype(font='simhei.ttf',size=150)
vis.rectangle([(0,0), (1000, 200)], fill="green")
vis.text((200, 30), label, fill=(255, 255, 255), font=font)
image.show()输出结果

最后再结合FastAPI把输入输出固定成变量,写成可以通过内网或者外网IP能够访问的服务化API接口。
import cv2
from fastapi import FastAPI, File, UploadFile
import tempfile
import uvicorn
import fastdeploy as fd
app = FastAPI()
#初始化模型
model = fd.vision.classification.PaddleClasModel(
model_file = 'inference/inference.pdmodel',
params_file = 'inference/inference.pdiparams',
config_file = 'inference.yml')
@app.post("/image/")
async def get_image(file: UploadFile = File(...)):
# 接收前端上传的图片
img = await file.read()
tempfileName = tempfile.NamedTemporaryFile(suffix='.jpg', delete=False)
tempfileName.write(img)
tempfileName.close()
# 使用FastDeploy推理
img = cv2.imread(tempfileName.name)
result = model.predict(img)
labelId = result.label_ids[0]
# 读取labelmap文件查找映射的中文名
with open("dataset/labels_chinese.txt", 'r', encoding="utf-8") as o:
labelmap = o.readlines()
label = labelmap[labelId].replace('\n', '')
if label == '健康叶片':
status = 'primary'
else:
status = 'warn'
return {"disease": label, "status": status}
if __name__ == "__main__":
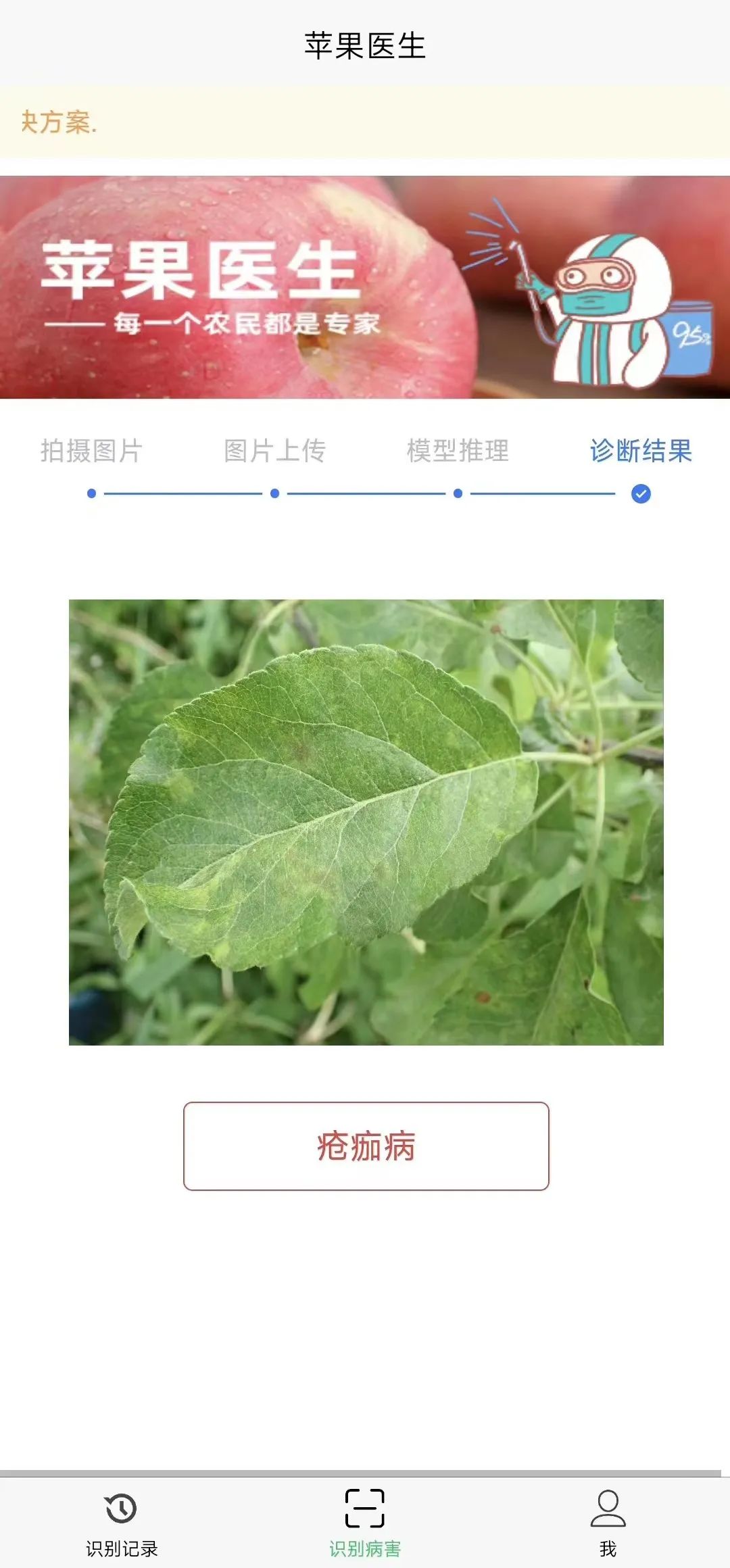
uvicorn.run(app, host="0.0.0.0", port=8000)通过API测试工具,模拟前端上传一张健康叶片的图片测试,查看接口返回的效果:
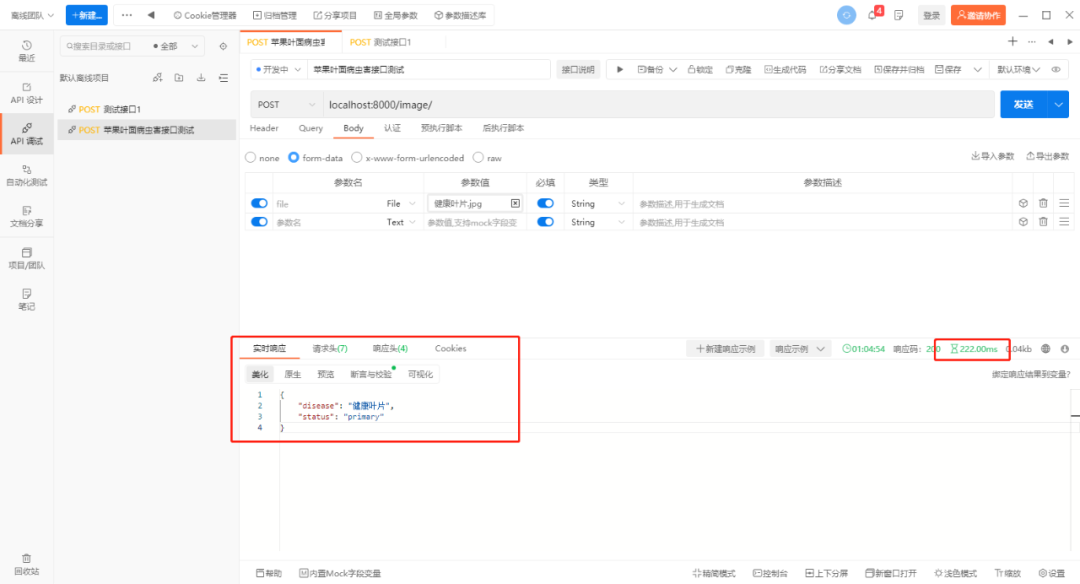
在测试结果中可以看到程序成功地返回了正确的分类结果,并且从右边的响应时间来看,在Intel CPU i5-6200U笔记本的环境下,FastDeploy的整体推理速度还是非常快的(如果进一步优化IO,整体速度会提升更多)。
更多模型部署使用
往期精彩
火箭发动机喷流的“监察队长”:基于飞桨探索火箭发动机真空羽流流场的快速计算
开发者说论文|让谣言无处遁形:基于飞桨完成社交媒体谣言的互动分析和验证

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~
随着大数据、人工智能等数字技术在农业领域的渗透和应用,智慧农业开始从理论概念慢慢走向应用落地,我国的传统农业也逐步迈向智慧农业时代。发展智慧农业是数字乡村建设的重要内容,有助于我国破解“三农”难题,实现农业全产业链的现代化升级转型。但在AI转型实践中,农林企业往往会遇到很多技术问题,AI模型部署就是其中难度相对较高的一环。
模型部署是AI开发的“最后一公里”,但往往这最后一步成了很多产品开发团队加班加点攻关解决的难题,主要的难点有以下几个方面:
难点一:硬件产品开发需要软硬件工程师协同,同时软硬件工程师还要熟悉AI开发技术栈,本来大多数农林企业中就没有完整的人才配套,懂AI的软硬件工程师更是少之又少。
难点二:做落地的工程对AI工程师的技术栈要求高,除了要懂基础开发之外,还要熟悉模型转换、压缩、优化、部署上线等技术内容。
本文共分为四大版块:原部署方案,FastDeploy部署方案,FastDeploy+ FastAPI项目落地,总结。
https://aistudio.baidu.com/aistudio/projectdetail/4411585?contributionType=1
项目效果
ONNX Runtime
pip install paddle2onnx
pip install onnxruntimepaddle2onnx --model_dir=./inference/ \
--model_filename=inference.pdmodel \
--params_filename=inference.pdiparams \
--save_file=./onnx_model/inference.onnx \
--opset_version=10 \
--enable_onnx_checker=True推理代码
import cv2
import numpy as np
from onnxruntime import InferenceSession
model = InferenceSession('./onnx_model/inference.onnx')
input_names = model.get_inputs()[0].name
output_names = model.get_outputs()[0].name
imageInput = cv2.imread("dataset/healthy/81935a3879e1f68e.jpg")
imageInput = np.array(cv2.resize(imageInput, (224,224)))
imageInput = (imageInput/255-[0.485, 0.456, 0.406])/[0.229, 0.224, 0.225]
imageInput = imageInput[np.newaxis,:]
imageInput = imageInput.transpose([0,3,1,2])
imageInput = imageInput.astype('float32')
batch_output = model.run(
output_names=[output_names],
input_feed={input_names: imageInput})[0]
def softmax(x):
x = x.reshape(-1)
e_x = np.exp(x - np.max(x))
return e_x / e_x.sum(axis=0)
for output in batch_output:
result = softmax(np.array(output)).tolist()
idx = np.argmax(result)
print("Result:", idx)输出结果
Result:3
安装FastDeploy
# FastDeploy分CPU和GPU版本,根据设备情况选择安装其中一个即可
pip install fastdeploy-python -f https://www.paddlepaddle.org.cn/whl/fastdeploy.html
#pip install fastdeploy-gpu-python -f https://www.paddlepaddle.org.cn/whl/fastdeploy.html
推理代码
import fastdeploy as fd
import cv2
model = fd.vision.classification.PaddleClasModel(
model_file = 'inference/inference.pdmodel',
params_file = 'inference/inference.pdiparams',
config_file = 'inference.yml')
img = cv2.imread('dataset/healthy/81935a3879e1f68e.jpg')
result = model.predict(img)
print(result)输出结果
ClassifyResult(
label_ids: 3, #该标签和AI Studio项目中制作的AI数据集标签有关系,表示健康图片
scores: 0.888799,
)
我们将推理得到的label ID和labelmap映射文件对应,得到分类id映射的中文名,再将结果进行可视化。
from PIL import Image, ImageDraw, ImageFont
# 得到分类id
labelId = result.label_ids[0]
# 读取labelmap映射文件
with open("dataset/labels_chinese.txt", 'r') as o:
labelmap = o.readlines()
label = labelmap[labelId].replace('\n', '')
image = Image.fromarray(img)
vis = ImageDraw.Draw(image)
font = ImageFont.truetype(font='simhei.ttf',size=150)
vis.rectangle([(0,0), (1000, 200)], fill="green")
vis.text((200, 30), label, fill=(255, 255, 255), font=font)
image.show()输出结果
最后再结合FastAPI把输入输出固定成变量,写成可以通过内网或者外网IP能够访问的服务化API接口。
import cv2
from fastapi import FastAPI, File, UploadFile
import tempfile
import uvicorn
import fastdeploy as fd
app = FastAPI()
#初始化模型
model = fd.vision.classification.PaddleClasModel(
model_file = 'inference/inference.pdmodel',
params_file = 'inference/inference.pdiparams',
config_file = 'inference.yml')
@app.post("/image/")
async def get_image(file: UploadFile = File(...)):
# 接收前端上传的图片
img = await file.read()
tempfileName = tempfile.NamedTemporaryFile(suffix='.jpg', delete=False)
tempfileName.write(img)
tempfileName.close()
# 使用FastDeploy推理
img = cv2.imread(tempfileName.name)
result = model.predict(img)
labelId = result.label_ids[0]
# 读取labelmap文件查找映射的中文名
with open("dataset/labels_chinese.txt", 'r', encoding="utf-8") as o:
labelmap = o.readlines()
label = labelmap[labelId].replace('\n', '')
if label == '健康叶片':
status = 'primary'
else:
status = 'warn'
return {"disease": label, "status": status}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)通过API测试工具,模拟前端上传一张健康叶片的图片测试,查看接口返回的效果:
在测试结果中可以看到程序成功地返回了正确的分类结果,并且从右边的响应时间来看,在Intel CPU i5-6200U笔记本的环境下,FastDeploy的整体推理速度还是非常快的(如果进一步优化IO,整体速度会提升更多)。
更多模型部署使用
往期精彩
火箭发动机喷流的“监察队长”:基于飞桨探索火箭发动机真空羽流流场的快速计算
开发者说论文|让谣言无处遁形:基于飞桨完成社交媒体谣言的互动分析和验证
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~