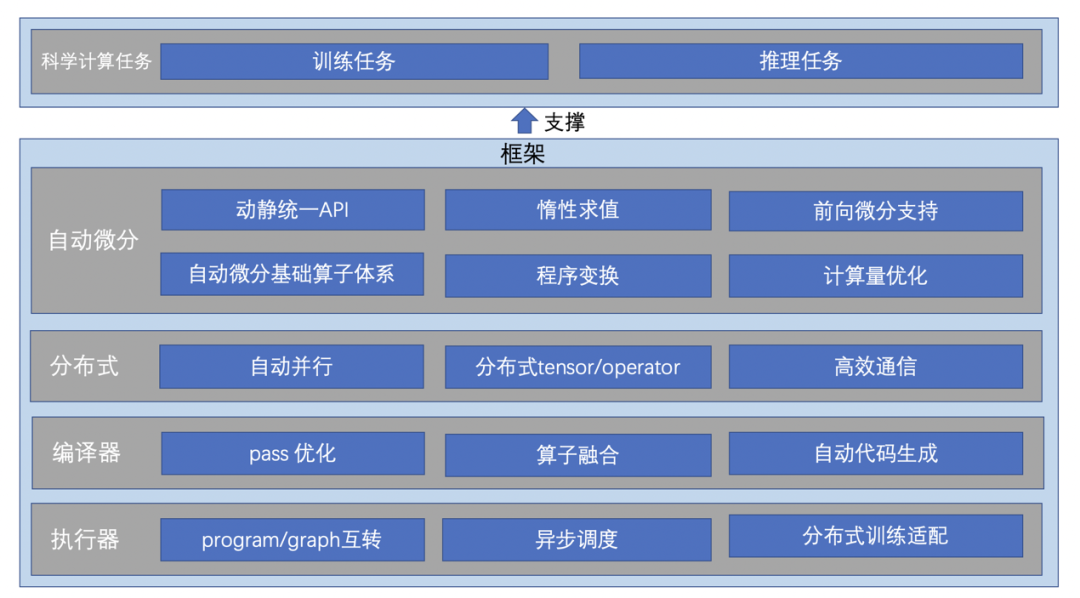
继上一篇典型案例及API功能介绍,本篇重点讲解飞桨核心框架为支持科学计算任务在技术上的创新工作与成果。
飞桨科学计算套件赛桨PaddleScience底层技术依赖飞桨核心框架。为了有力地支撑科学计算任务高效训练与推理,飞桨核心框架在自动微分、编译器、执行器和分布式等多方面分别进行了技术创新。值得一提的是,自动微分在机制上的革新带来了框架计算量方面的优化,结合自研编译器CINN的加持,在典型科学计算任务2D定常Laplace模型上达到业界性能最优。
自动微分
飞桨核心框架在2.3版本中针对自动微分机制和自动微分API提供多种技术创新。
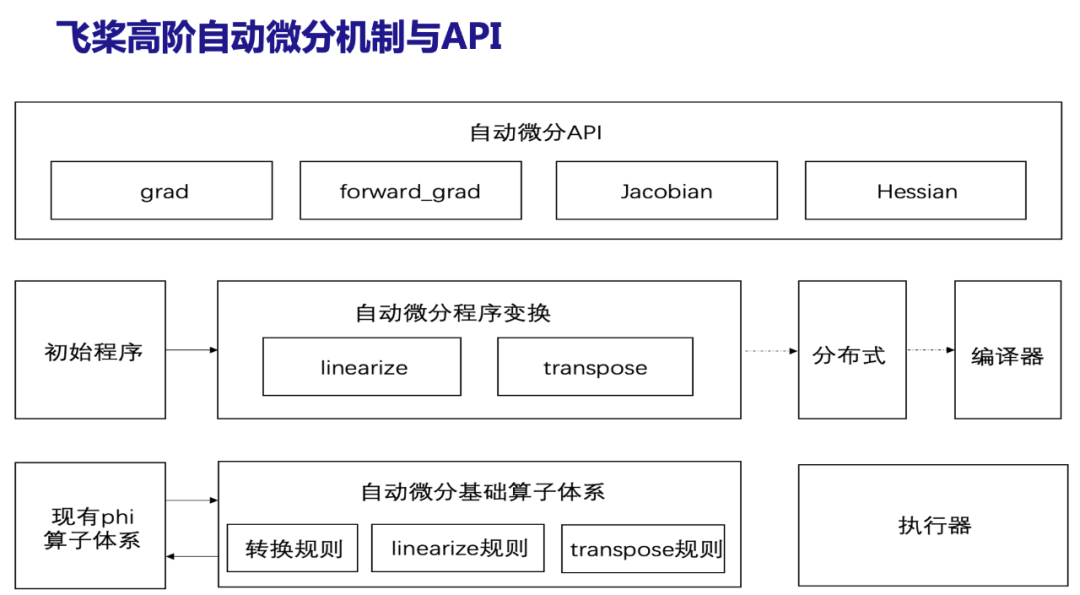
自动微分机制
自动微分在机制方面,通过设计自动微分基础算子体系,并在其上定义linearize和transpose程序变换规则。飞桨在静态图中新增对前向微分的支持,实现前反向不限阶的自动微分机制。创新后的自动微分机制具备良好的算子支持扩展性,目前已经支持全连接网络,并在2D定常Laplace、3D定常圆柱绕流等典型科学计算任务上完成验证工作。
自动微分API
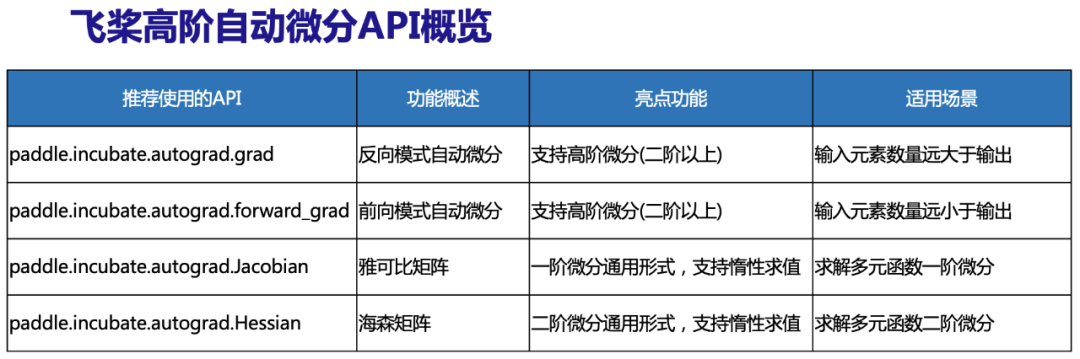
在自动微分API方面,飞桨为外部用户新增2个自动微分API,分别是前向自动微分forward_grad与反向自动微分grad两种接口,均支持高阶微分。为了方便用户使用,同时提供Jacobian、Hessian的求解,支持按行延迟计算,在复杂偏微分方程组中显著提升计算性能。另外,也公开了实现此次创新后的自动微分核心机制API jvp与vjp,当前所有API均放在incubate空间下,处于实验特性,会根据用户需求及具体应用场景持续演进。上述API列表以及计算示例如下表所示。

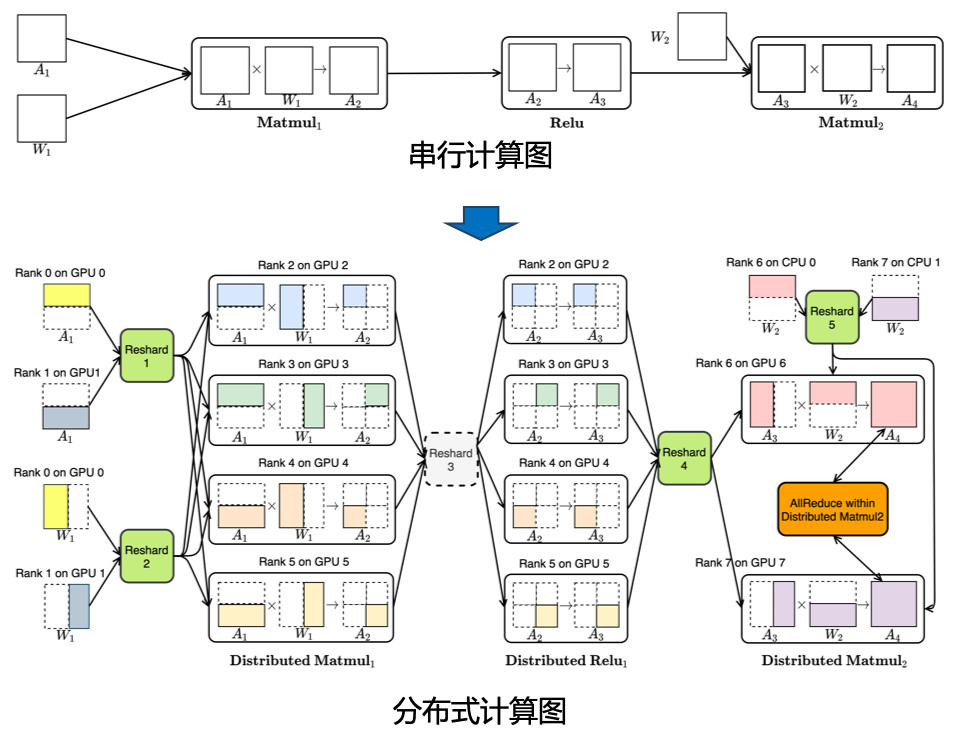
分布式自动并行
编译器
自动微分机制将科学计算模型中的深度学习算子拆分成若干细粒度的基础算子,若直接计算,这些细粒度算子将使得模型的大部分时间被浪费在数据交换和执行调度而非实际计算上。这意味着我们并未完全利用到硬件的计算资源,因此模型的计算速度还仍有较大的提升空间。神经网络编译器在此类问题上有着显著的优势,包括针对计算图的通用Pass优化、算子融合以及自动代码生成等。飞桨神经网络编译器CINN即是解决此类问题的有力工具,它在消除大量无用数据交换和执行调度开销的同时,极大地降低算子开发所需的人力成本,相比于未开启编译加速的执行方式,开启CINN在2D定常Laplace模型上实测有最大3.72倍性能提升。
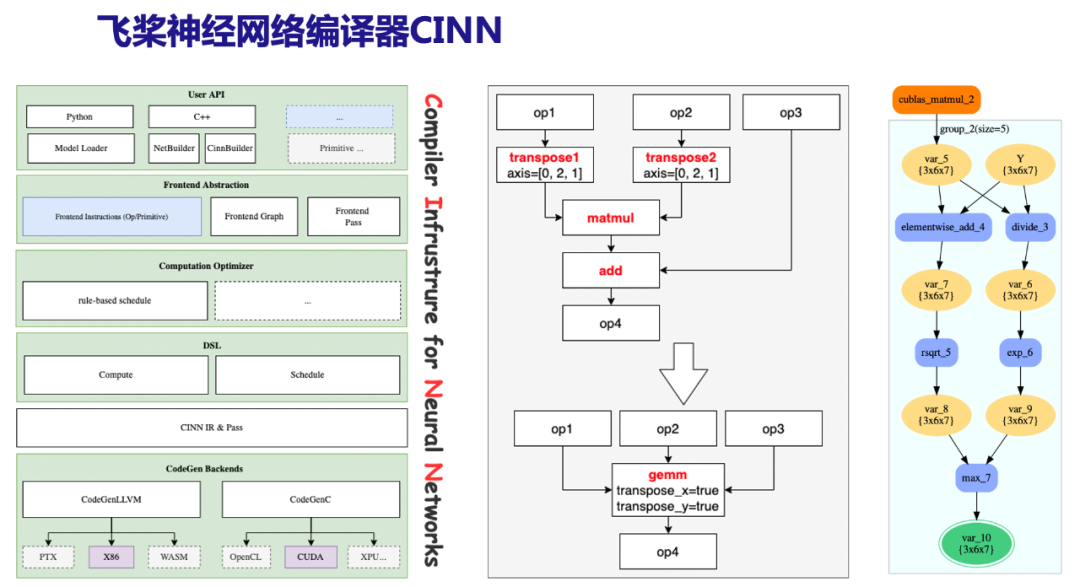
图 左:CINN架构图 中:gemm rewriter示例 右:5个小算子融合示例
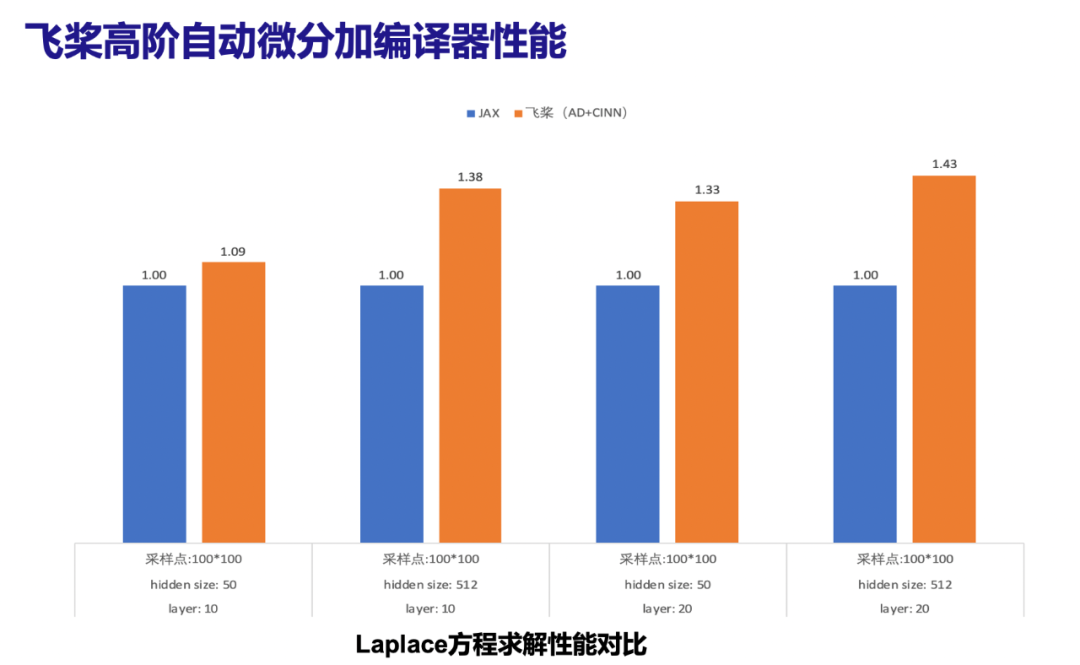
从实验结果可以看出,受益于新自动微分机制上的革新和自研编译器CINN的性能优化加持,在典型科学计算任务2D定常Laplace模型上达到业界性能最优。
执行器
此外,飞桨框架在2.3版本中发布了全新的静态图执行器,其中实现高效的多stream和多线程异步调度组件,使得模型训练更加性能优越和易扩展,并已在单机单卡场景下默认使用。针对PaddleScience,我们通过对静态图新执行器在对接Graph IR体系和支持分布式训练等方面的功能适配和扩充,使图优化后的模型可以利用新执行器进行分布式训练。
拓展阅读
AI+Science系列(一) :飞桨加速CFD(计算流体力学)原理与实践
相关地址
https://www.paddlepaddle.org.cn/science
飞桨PPSIG-Science小组

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~
继上一篇典型案例及API功能介绍,本篇重点讲解飞桨核心框架为支持科学计算任务在技术上的创新工作与成果。
飞桨科学计算套件赛桨PaddleScience底层技术依赖飞桨核心框架。为了有力地支撑科学计算任务高效训练与推理,飞桨核心框架在自动微分、编译器、执行器和分布式等多方面分别进行了技术创新。值得一提的是,自动微分在机制上的革新带来了框架计算量方面的优化,结合自研编译器CINN的加持,在典型科学计算任务2D定常Laplace模型上达到业界性能最优。
自动微分
飞桨核心框架在2.3版本中针对自动微分机制和自动微分API提供多种技术创新。
自动微分机制
自动微分在机制方面,通过设计自动微分基础算子体系,并在其上定义linearize和transpose程序变换规则。飞桨在静态图中新增对前向微分的支持,实现前反向不限阶的自动微分机制。创新后的自动微分机制具备良好的算子支持扩展性,目前已经支持全连接网络,并在2D定常Laplace、3D定常圆柱绕流等典型科学计算任务上完成验证工作。
自动微分API
在自动微分API方面,飞桨为外部用户新增2个自动微分API,分别是前向自动微分forward_grad与反向自动微分grad两种接口,均支持高阶微分。为了方便用户使用,同时提供Jacobian、Hessian的求解,支持按行延迟计算,在复杂偏微分方程组中显著提升计算性能。另外,也公开了实现此次创新后的自动微分核心机制API jvp与vjp,当前所有API均放在incubate空间下,处于实验特性,会根据用户需求及具体应用场景持续演进。上述API列表以及计算示例如下表所示。
分布式自动并行
编译器
自动微分机制将科学计算模型中的深度学习算子拆分成若干细粒度的基础算子,若直接计算,这些细粒度算子将使得模型的大部分时间被浪费在数据交换和执行调度而非实际计算上。这意味着我们并未完全利用到硬件的计算资源,因此模型的计算速度还仍有较大的提升空间。神经网络编译器在此类问题上有着显著的优势,包括针对计算图的通用Pass优化、算子融合以及自动代码生成等。飞桨神经网络编译器CINN即是解决此类问题的有力工具,它在消除大量无用数据交换和执行调度开销的同时,极大地降低算子开发所需的人力成本,相比于未开启编译加速的执行方式,开启CINN在2D定常Laplace模型上实测有最大3.72倍性能提升。
图 左:CINN架构图 中:gemm rewriter示例 右:5个小算子融合示例
从实验结果可以看出,受益于新自动微分机制上的革新和自研编译器CINN的性能优化加持,在典型科学计算任务2D定常Laplace模型上达到业界性能最优。
执行器
此外,飞桨框架在2.3版本中发布了全新的静态图执行器,其中实现高效的多stream和多线程异步调度组件,使得模型训练更加性能优越和易扩展,并已在单机单卡场景下默认使用。针对PaddleScience,我们通过对静态图新执行器在对接Graph IR体系和支持分布式训练等方面的功能适配和扩充,使图优化后的模型可以利用新执行器进行分布式训练。
拓展阅读
AI+Science系列(一) :飞桨加速CFD(计算流体力学)原理与实践
相关地址
https://www.paddlepaddle.org.cn/science
飞桨PPSIG-Science小组
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~