“全面赋能千行百业”是AI的重要使命,政务、法律、金融、医疗、制造等传统行业智能化程度越来越高,在效率、成本和收益方面蕴藏着巨大的开拓空间。其中,金融业,就正在AI技术的赋能下,发生着一场“降本增效”的变革。
场景层面,提到AI+金融,可能会有人很快想到“股价预测”,但其实比起令人琢磨不透的股价波动,金融行业存在着更多收益确定性高、AI价值附增显著的业务场景。举几个例子:
深耕技术深度和先进性常常能在互联网行业产生可观的收益,同样的,只要方向对,先进的AI技术用在传统行业的场景里同样能起到事半功倍的效果。
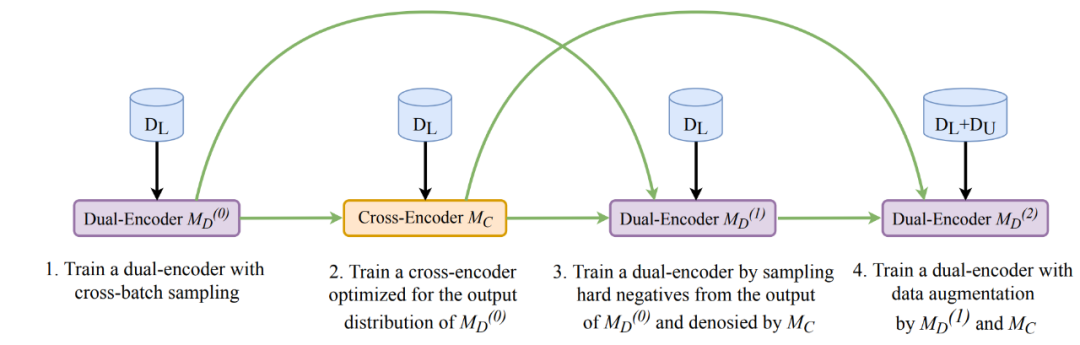
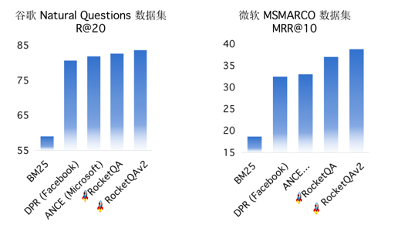
而百度研发了先进的端到端智能问答技术RocketQA,不仅在学术竞赛榜单MS MARCO多次刷新记录,而且实现了精准、泛化能力强的语义召回,在实际应用中大大减少了传统离散检索引入的人工构建开销。
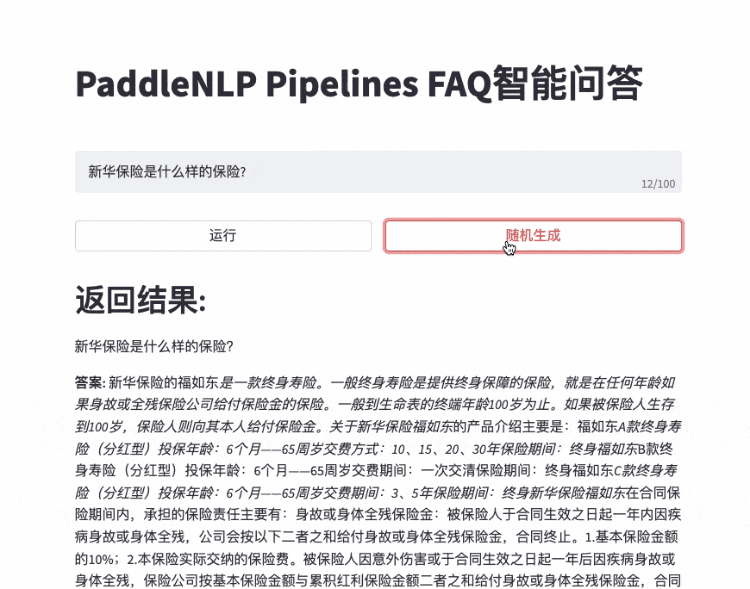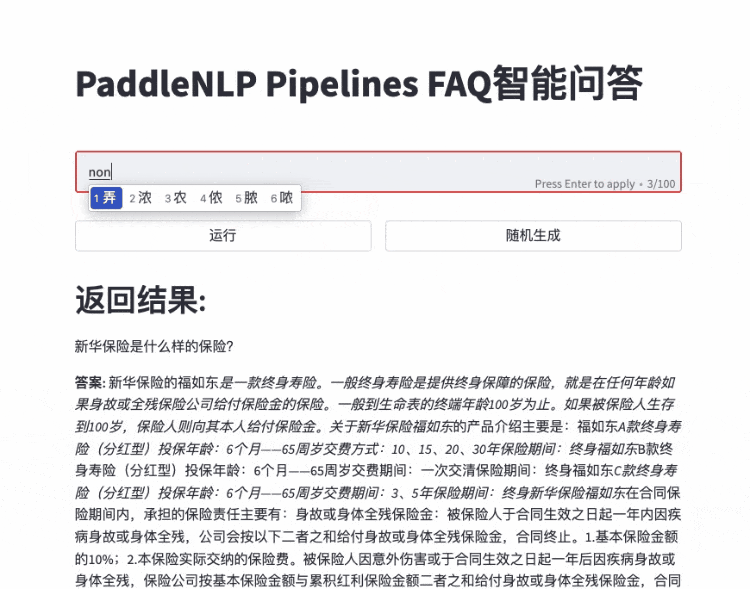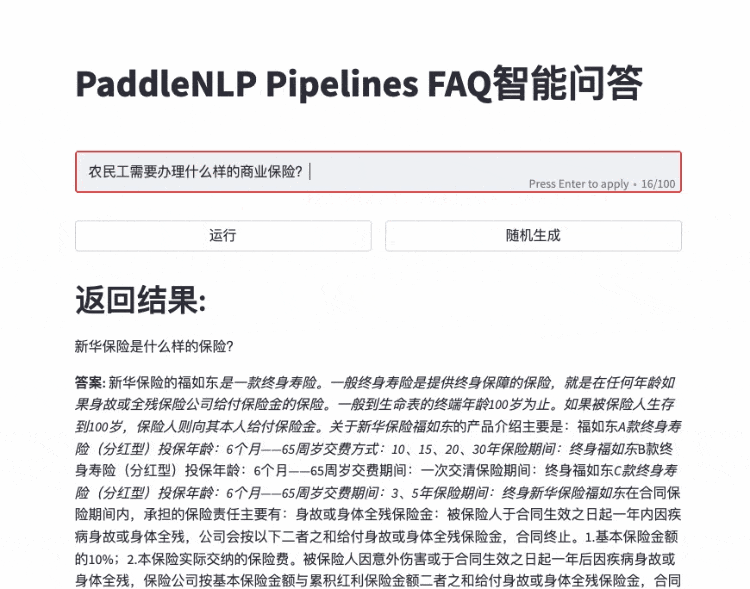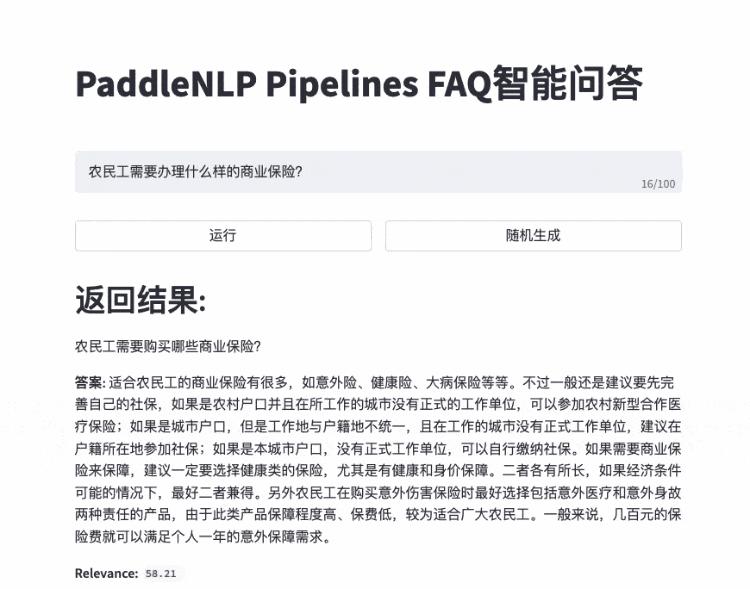
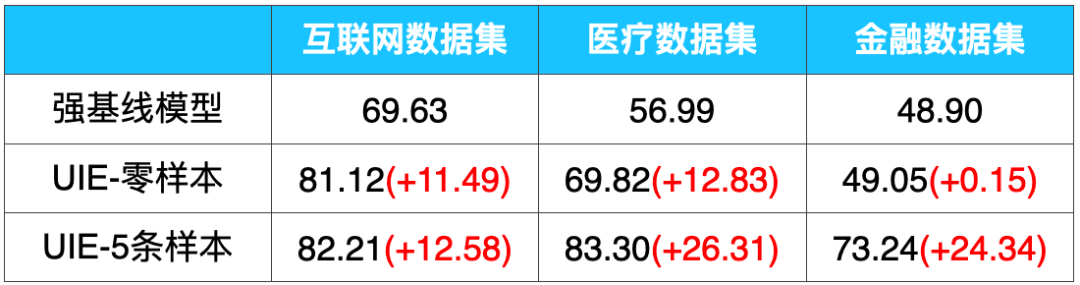
总之,基于端到端智能问答技术RocketQA构建出的FAQ问答系统,不仅构建效率大大提升,且无需标注数据、比传统技术方案具备显著的效果优势。
然而,如果徒有先进的AI技术,却没有配套的高效落地工具,那传统行业的落地依然困难重重,工具的重要性不言而喻。
“深度学习,NLP啥的太难懂了,我们一时半会搞不定”
——来自行业人员吐槽
“需求场景太多了,人手不够,开发不过来”
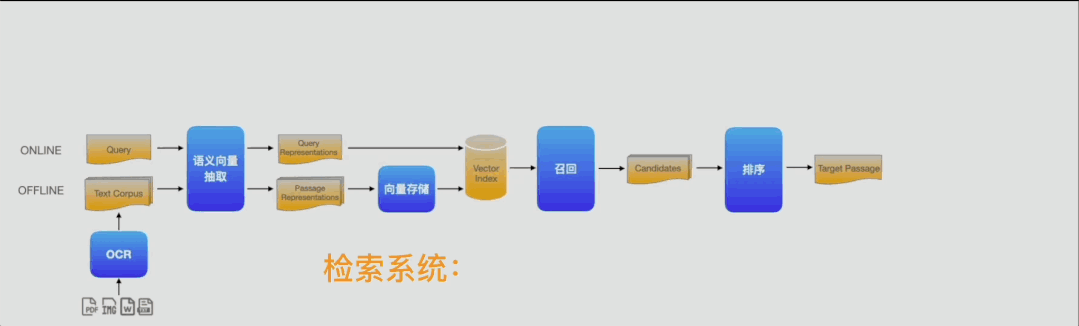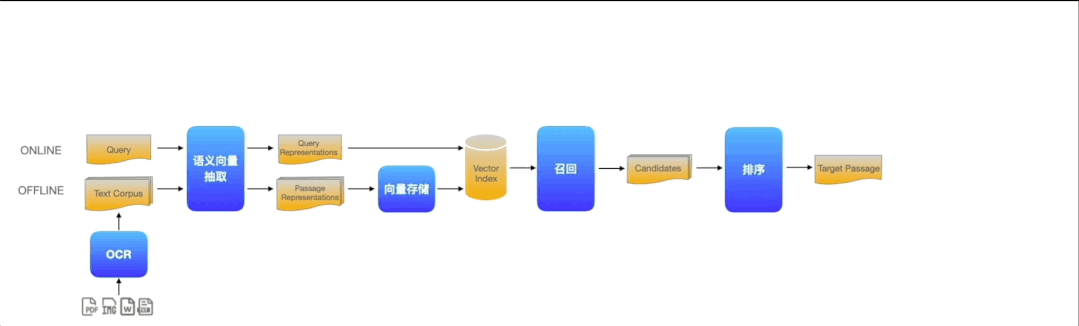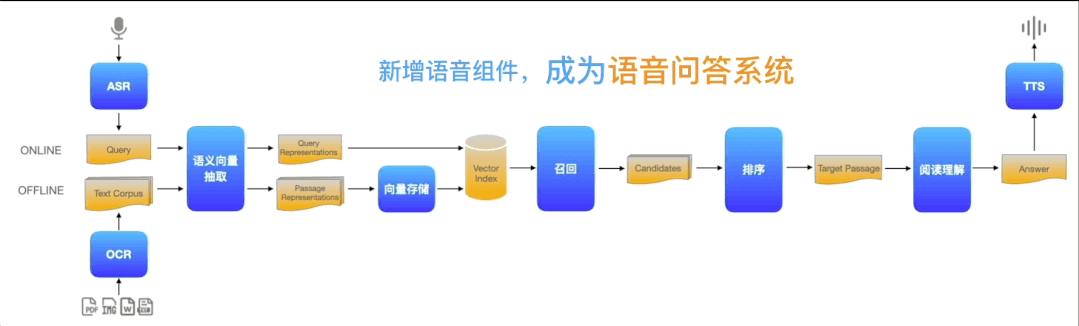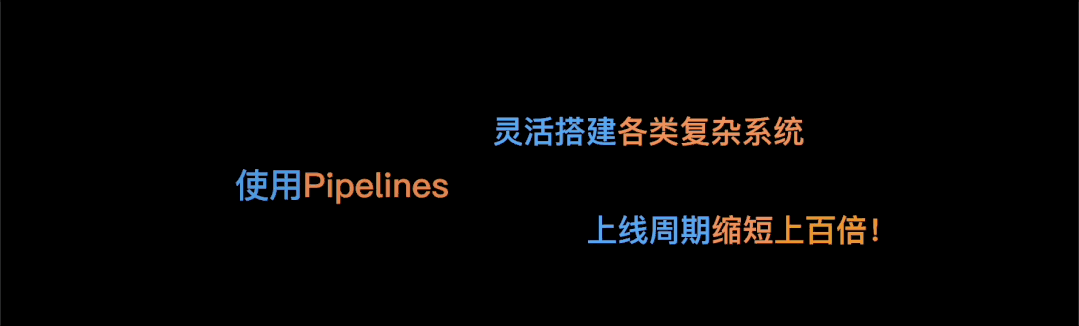
而Pipelines就实现了上图一样轻松灵活的开发模式,可将AI模型的上线周期缩短百倍以上。
相关地址
PaddleNLP 项目地址:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/pipelines/examples/FAQ
RocketQA 项目地址:
https://github.com/PaddlePaddle/rocketqa
TrustAI 项目地址:

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~
“全面赋能千行百业”是AI的重要使命,政务、法律、金融、医疗、制造等传统行业智能化程度越来越高,在效率、成本和收益方面蕴藏着巨大的开拓空间。其中,金融业,就正在AI技术的赋能下,发生着一场“降本增效”的变革。
场景层面,提到AI+金融,可能会有人很快想到“股价预测”,但其实比起令人琢磨不透的股价波动,金融行业存在着更多收益确定性高、AI价值附增显著的业务场景。举几个例子:
深耕技术深度和先进性常常能在互联网行业产生可观的收益,同样的,只要方向对,先进的AI技术用在传统行业的场景里同样能起到事半功倍的效果。
而百度研发了先进的端到端智能问答技术RocketQA,不仅在学术竞赛榜单MS MARCO多次刷新记录,而且实现了精准、泛化能力强的语义召回,在实际应用中大大减少了传统离散检索引入的人工构建开销。
总之,基于端到端智能问答技术RocketQA构建出的FAQ问答系统,不仅构建效率大大提升,且无需标注数据、比传统技术方案具备显著的效果优势。
然而,如果徒有先进的AI技术,却没有配套的高效落地工具,那传统行业的落地依然困难重重,工具的重要性不言而喻。
“深度学习,NLP啥的太难懂了,我们一时半会搞不定”
——来自行业人员吐槽
“需求场景太多了,人手不够,开发不过来”
而Pipelines就实现了上图一样轻松灵活的开发模式,可将AI模型的上线周期缩短百倍以上。
相关地址
PaddleNLP 项目地址:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/pipelines/examples/FAQ
RocketQA 项目地址:
https://github.com/PaddlePaddle/rocketqa
TrustAI 项目地址:
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~