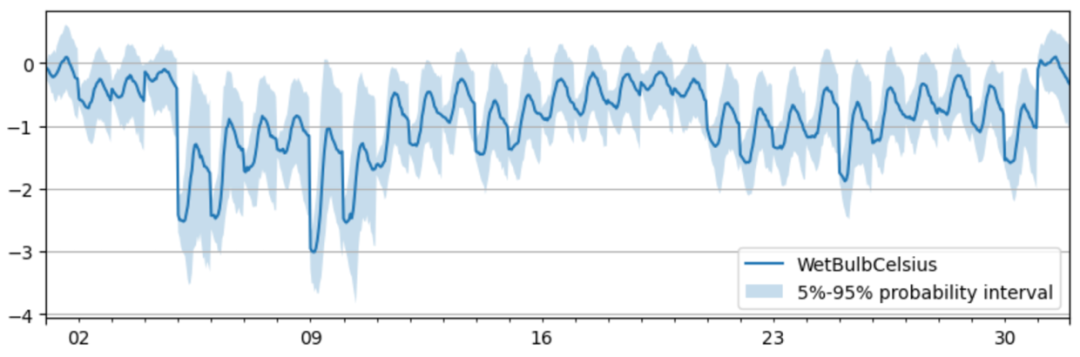
PaddleTS是一款基于飞桨深度学习框架的开源时序建模算法库,其具备统一的时序数据结构、全面的基础模型功能、丰富的数据处理和分析算子以及领先的深度时序算法,可以帮助开发者实现时序数据处理、分析、建模、预测全流程,在预测性维护、智慧能耗分析、价格销量预估等场景中有重要应用价值。
8月9日,PaddleTS首次发布后吸引了数千用户的试用,同时也收到了制造、能源、金融等多个行业的知名企事业单位的应用反馈,例如大气环境监测、生产设备中的故障预警、新能源汽车的剩余电量预估、银行网点现金储备量预估、大坝变形监测等诸多真实场景中得到了有效验证。
更先进
增加表征学习(TS2VEC)
在能源电力场景,我们利用大量母线的原始负荷数据混合作为语料,通过TS2VEC构建预训练模型,基于预训练模型为待预测母线生成特征表达,通过Ridge回归进行预测。表征模型总体效果达到深度时序预测模型当前最好的效果,并在新母线上的预测效果相比以往模型有进一步提升。
更全面
增加概率预测模块及概率预测模型DeepAR
未来往往是不确定的,当我们面临对未来的重要决策,就必然要考虑到可能的风险,也就是最好的情况和最坏的情况。概率预测相比于传统的点预测,提供了描述预测值可能的上下限,可以帮助我们更好的评估未来的风险。概率预测是通过对目标变量的概率分布进行学习,以分位数的形式输出概率预测结果。
在供应链中的库存管理场景,成本受极端事件推动。需求异常高时,会导致缺货和客户不满,而需求异常低时,会导致库存积压和成本高昂的库存作废。概率预测可以为企业提供预测值向上或向下修正面临的所有情形,用来进行最优化补货量,例如如果需要满足90%的服务水平,那么就可以输出90%分位数下对应的销量预测值来作为补货量。PaddleTS增加的概率预测模块以及概率预测模型DeepAR,可以很好的帮助应对这一类场景问题。
更易用
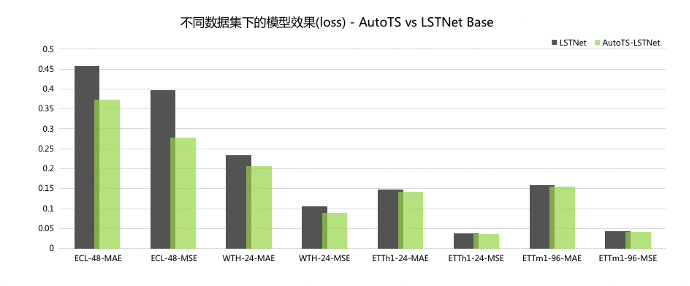
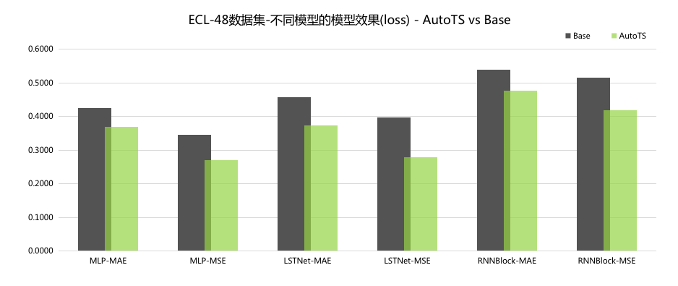
全新的自动建模AutoTS
autots_model = AutoTS(MLPRegressor, 96, 3)
autots_model.fit(tsdataset)MAE:平均绝对误差, MSE:均方误差
更方便
第三方模型和特征算子的快速集成
sklearn.preprocessing.MaxAbsScalersklearn.linear_model.LinearRegressionts_max_abs_scaler = make_ts_transform(sklearn.preprocessing.MaxAbsScaler, drop_origin_columns=True, per_col_transform=True)
ts_model = make_ml_model(sklearn.linear_model.LinearRegression, in_chunk_len=16, out_chunk_len=1)
tsdataset = ts_max_abs_scaler.fit_transform(tsdataset)
ts_model.fit(tsdataset)
res = model.predict(tsdataset)
PaddleTS相关地址
GitHub项目
https://github.com/PaddlePaddle/PaddleTS/
https://paddlets.readthedocs.io/
https://github.com/PaddlePaddle/PaddleTS/issues
PaddleTS 应用案例
PaddleTS首发后,开发者们将其能力应用到了大量真实场景中,本次我们从众多反馈中选取了一个"大坝变形监测"的案例为大家展开介绍。如果你也想将使用感受分享给更多人,也赶快加群联系我们吧~
以下内容截取自飞桨公开项目 ,作者geoyee。
原文地址:
https://aistudio.baidu.com/aistudio/projectdetail/4417167
如何进行数据准备&模型训练
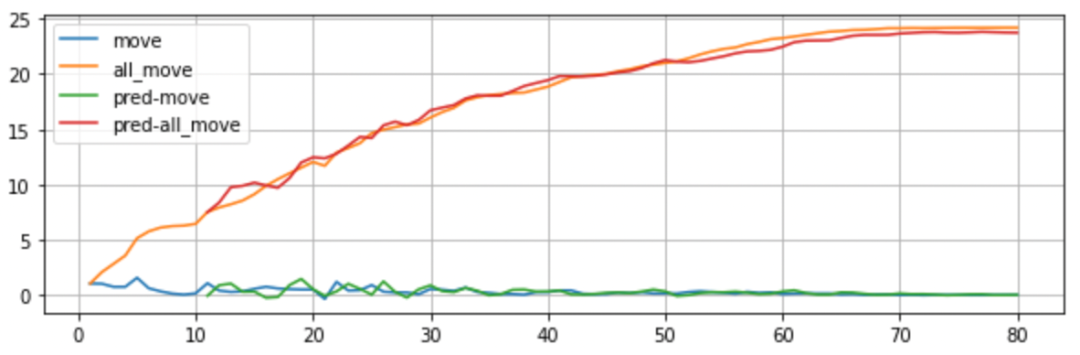
PaddleTS模型效果评估
使用PaddleTS能够方便的完成数据拆分、建模以及效果验证。本次试验使用模型的是LSTNetRegressor,可以看到效果还是非常不错的。至于为什么从10之后才有预测数据,因为这是通过十期数据预测一期,所以前十期数据没办法得到预测的。
move:位移,all_move:累计位移,pred-move:预测位移,pred-all_move:预测累计位移
拓展阅读
重磅首发!PaddleTS飞桨时序建模算法库,预测性维护、智慧能耗分析等一网打尽
【精彩课程推荐】
PaddleTS是一款基于飞桨深度学习框架的开源时序建模算法库,其具备统一的时序数据结构、全面的基础模型功能、丰富的数据处理和分析算子以及领先的深度时序算法,可以帮助开发者实现时序数据处理、分析、建模、预测全流程,在预测性维护、智慧能耗分析、价格销量预估等场景中有重要应用价值。
8月9日,PaddleTS首次发布后吸引了数千用户的试用,同时也收到了制造、能源、金融等多个行业的知名企事业单位的应用反馈,例如大气环境监测、生产设备中的故障预警、新能源汽车的剩余电量预估、银行网点现金储备量预估、大坝变形监测等诸多真实场景中得到了有效验证。
更先进
增加表征学习(TS2VEC)
在能源电力场景,我们利用大量母线的原始负荷数据混合作为语料,通过TS2VEC构建预训练模型,基于预训练模型为待预测母线生成特征表达,通过Ridge回归进行预测。表征模型总体效果达到深度时序预测模型当前最好的效果,并在新母线上的预测效果相比以往模型有进一步提升。
更全面
增加概率预测模块及概率预测模型DeepAR
未来往往是不确定的,当我们面临对未来的重要决策,就必然要考虑到可能的风险,也就是最好的情况和最坏的情况。概率预测相比于传统的点预测,提供了描述预测值可能的上下限,可以帮助我们更好的评估未来的风险。概率预测是通过对目标变量的概率分布进行学习,以分位数的形式输出概率预测结果。
在供应链中的库存管理场景,成本受极端事件推动。需求异常高时,会导致缺货和客户不满,而需求异常低时,会导致库存积压和成本高昂的库存作废。概率预测可以为企业提供预测值向上或向下修正面临的所有情形,用来进行最优化补货量,例如如果需要满足90%的服务水平,那么就可以输出90%分位数下对应的销量预测值来作为补货量。PaddleTS增加的概率预测模块以及概率预测模型DeepAR,可以很好的帮助应对这一类场景问题。
更易用
全新的自动建模AutoTS
autots_model = AutoTS(MLPRegressor, 96, 3)
autots_model.fit(tsdataset)MAE:平均绝对误差, MSE:均方误差
更方便
第三方模型和特征算子的快速集成
sklearn.preprocessing.MaxAbsScalersklearn.linear_model.LinearRegressionts_max_abs_scaler = make_ts_transform(sklearn.preprocessing.MaxAbsScaler, drop_origin_columns=True, per_col_transform=True)
ts_model = make_ml_model(sklearn.linear_model.LinearRegression, in_chunk_len=16, out_chunk_len=1)
tsdataset = ts_max_abs_scaler.fit_transform(tsdataset)
ts_model.fit(tsdataset)
res = model.predict(tsdataset)PaddleTS相关地址
GitHub项目
https://github.com/PaddlePaddle/PaddleTS/
https://paddlets.readthedocs.io/
https://github.com/PaddlePaddle/PaddleTS/issues
PaddleTS 应用案例
PaddleTS首发后,开发者们将其能力应用到了大量真实场景中,本次我们从众多反馈中选取了一个"大坝变形监测"的案例为大家展开介绍。如果你也想将使用感受分享给更多人,也赶快加群联系我们吧~
以下内容截取自飞桨公开项目 ,作者geoyee。
原文地址:
https://aistudio.baidu.com/aistudio/projectdetail/4417167
如何进行数据准备&模型训练
PaddleTS模型效果评估
使用PaddleTS能够方便的完成数据拆分、建模以及效果验证。本次试验使用模型的是LSTNetRegressor,可以看到效果还是非常不错的。至于为什么从10之后才有预测数据,因为这是通过十期数据预测一期,所以前十期数据没办法得到预测的。
move:位移,all_move:累计位移,pred-move:预测位移,pred-all_move:预测累计位移
拓展阅读
重磅首发!PaddleTS飞桨时序建模算法库,预测性维护、智慧能耗分析等一网打尽
【精彩课程推荐】