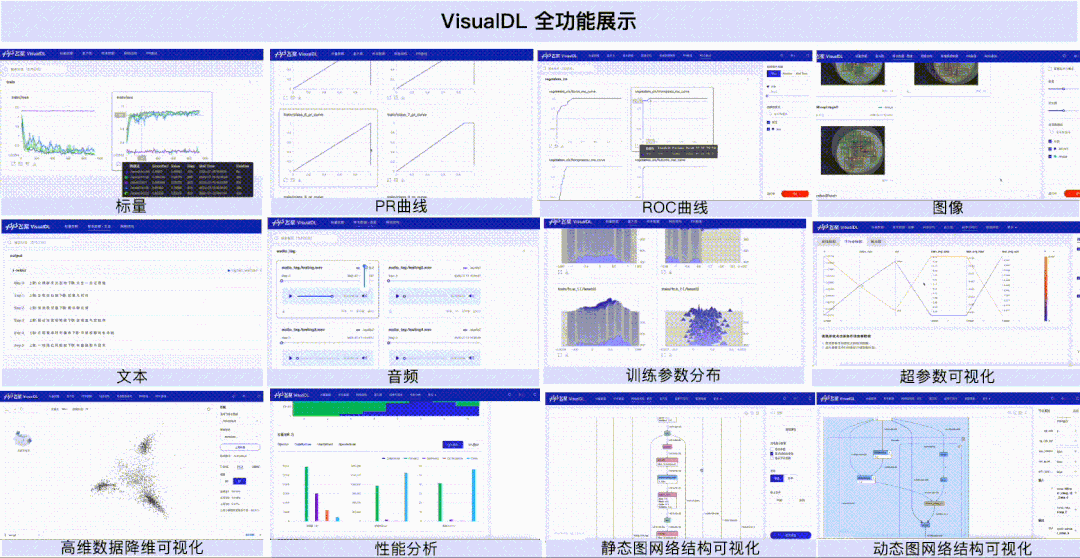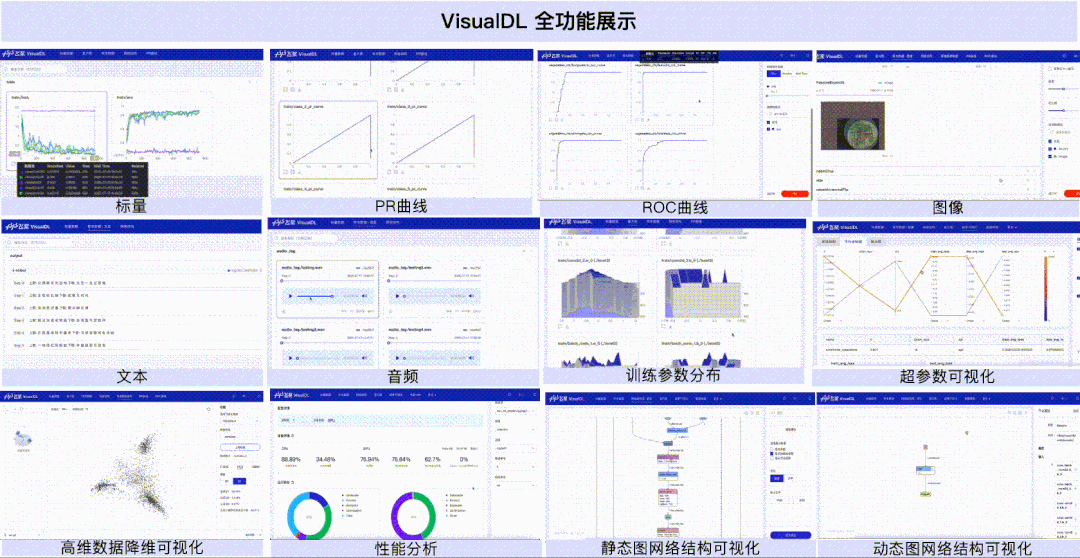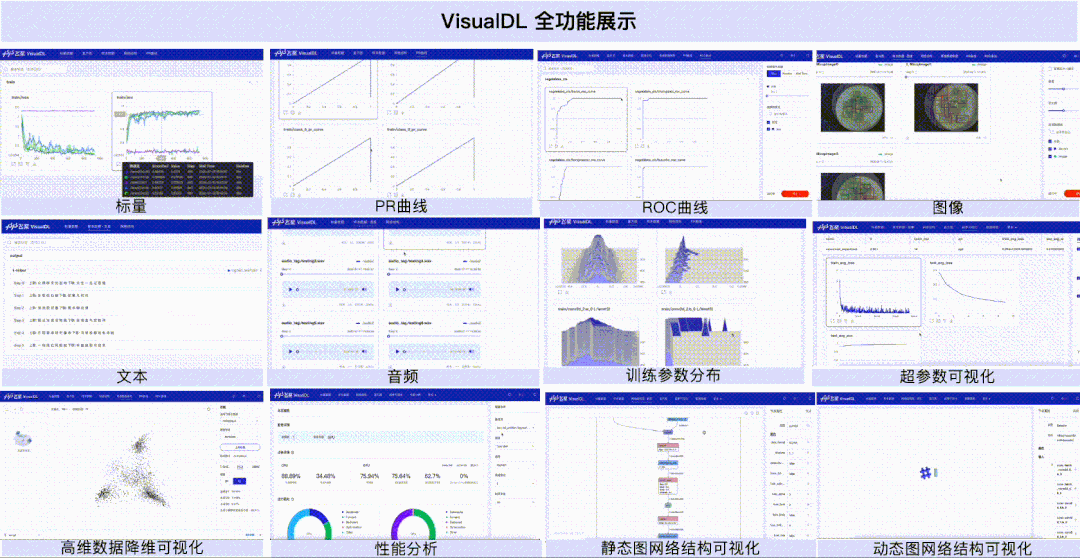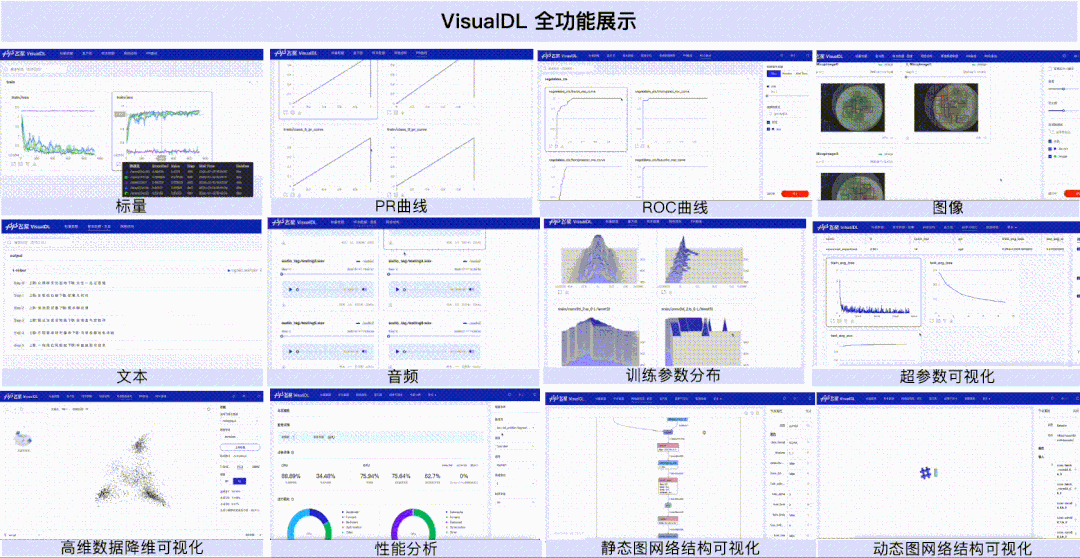
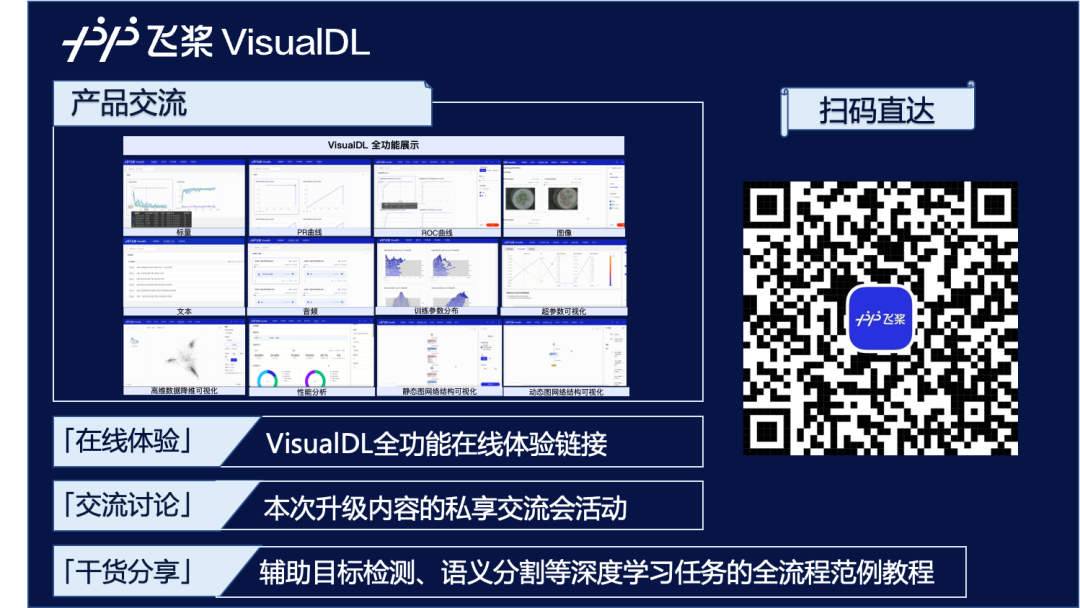
深度学习以网络结构繁杂和参数多著称,这导致开发者在模型训练过程中难免遇到调参方向不明和性能消耗难以优化等问题,大幅降低开发效率,因此模型训练调优的过程也被业界戏称为“炼丹”。随着深度学习技术在各行各业的渗透愈来愈深,如何缩短深度学习产业落地的耗时成为了近年来大家尤为关注的问题。
指标监控
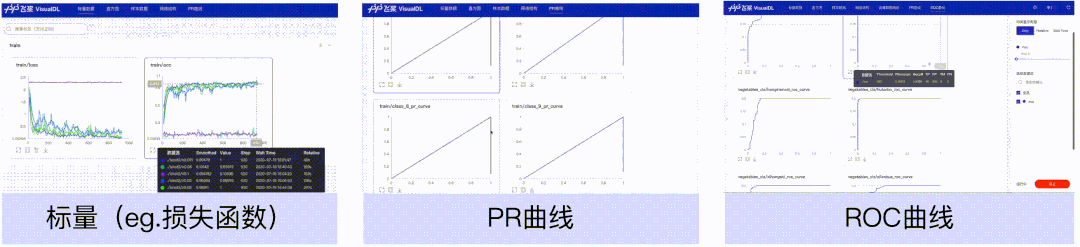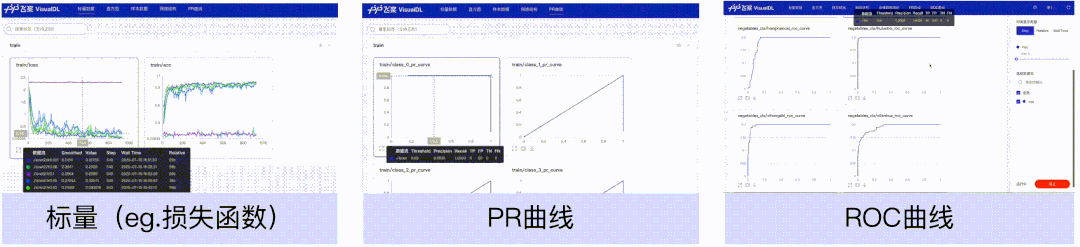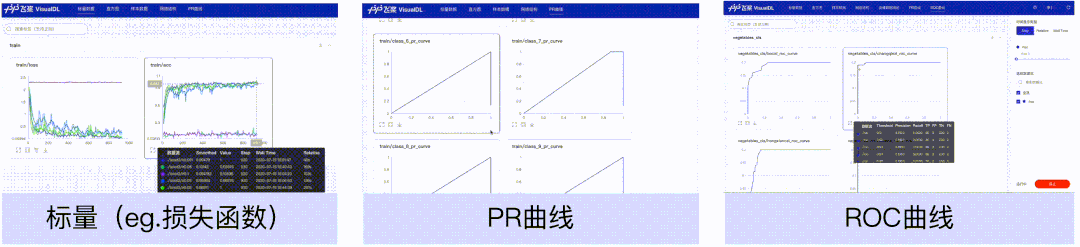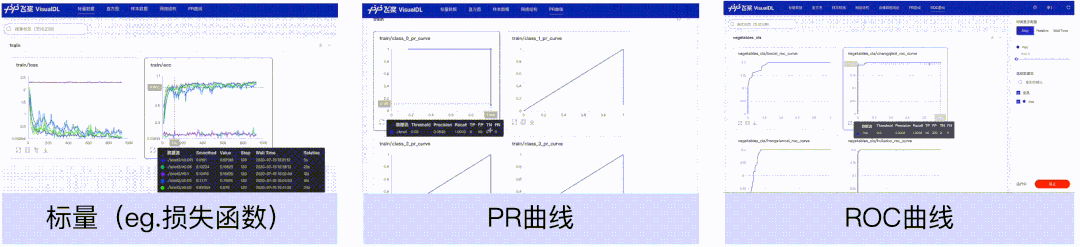
标量、PR曲线、ROC曲线组件,可以帮助用户观察损失函数的变化以及评价模型效果。
样本呈现
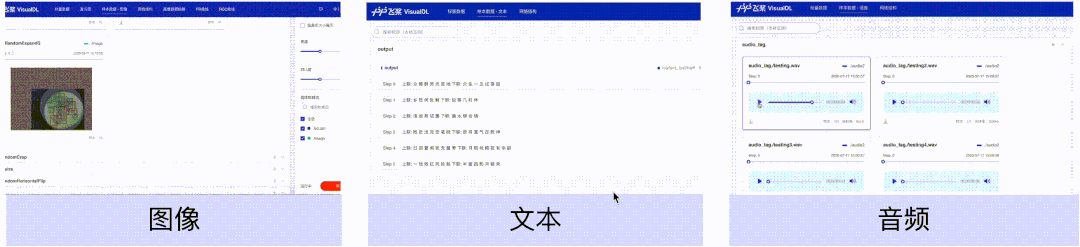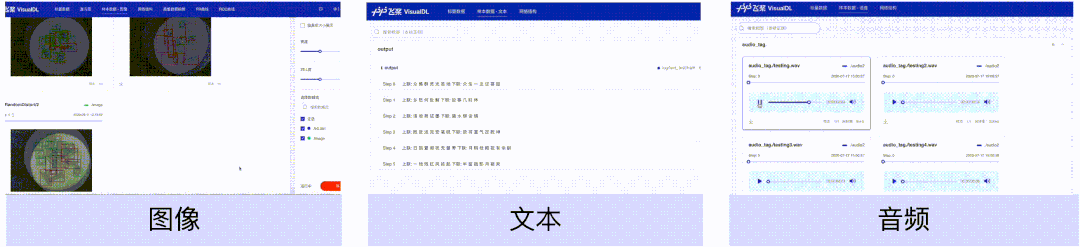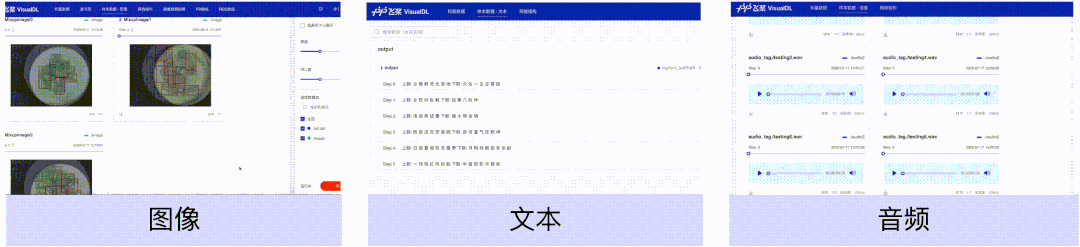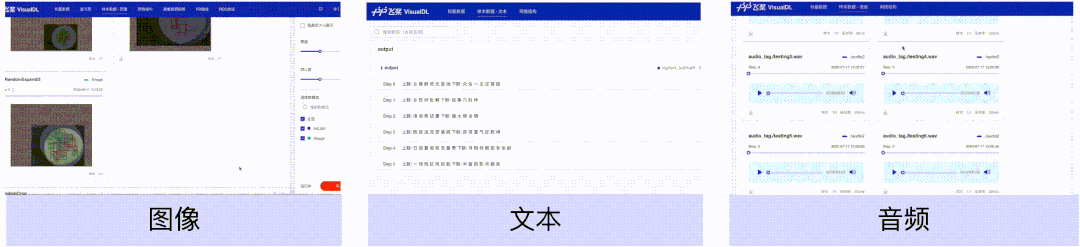
样本数据(图像、文本、音频)组件,可以帮助用户对训练时输入的样本进行直观地查看。
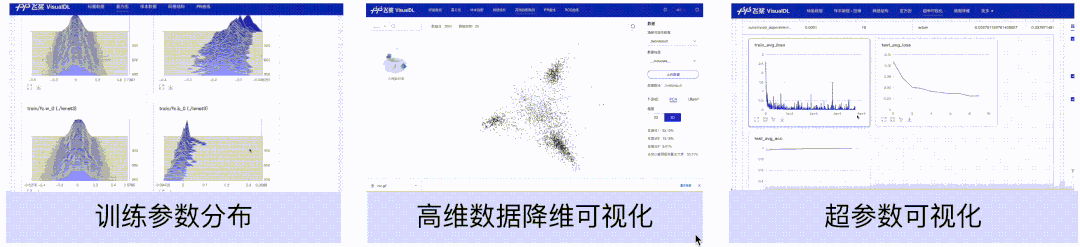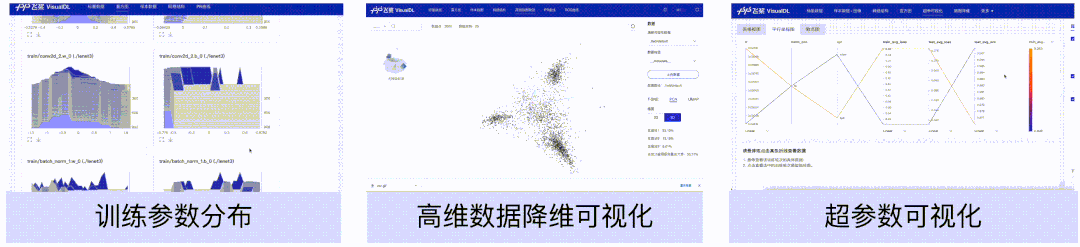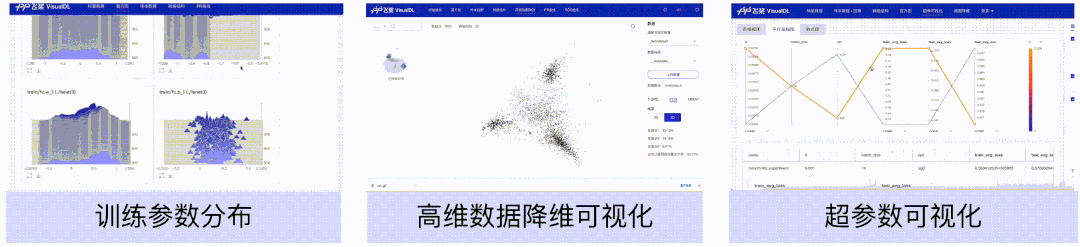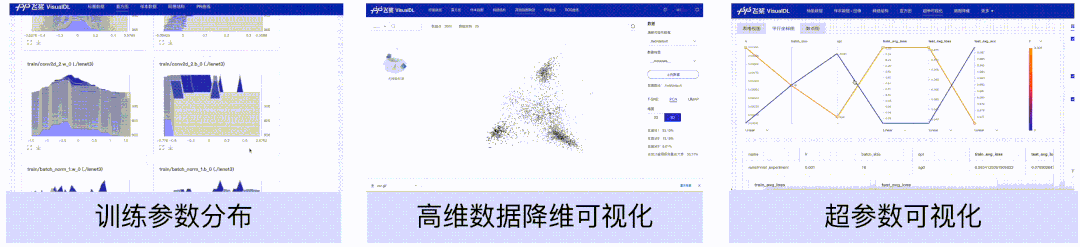
模型理解
直方图、高维数据降维展示、超参数组件,可以帮助用户理解训练过程,如分析模型参数的分布是如何随着训练过程变化,模型某一层输出的张量的变化趋势,分析embedding的距离关系以及对比不同超参数对模型效果的影响等。
结构调试
性能调优
性能分析组件,可以帮助用户分析模型的执行性能,定位性能瓶颈。
项目链接
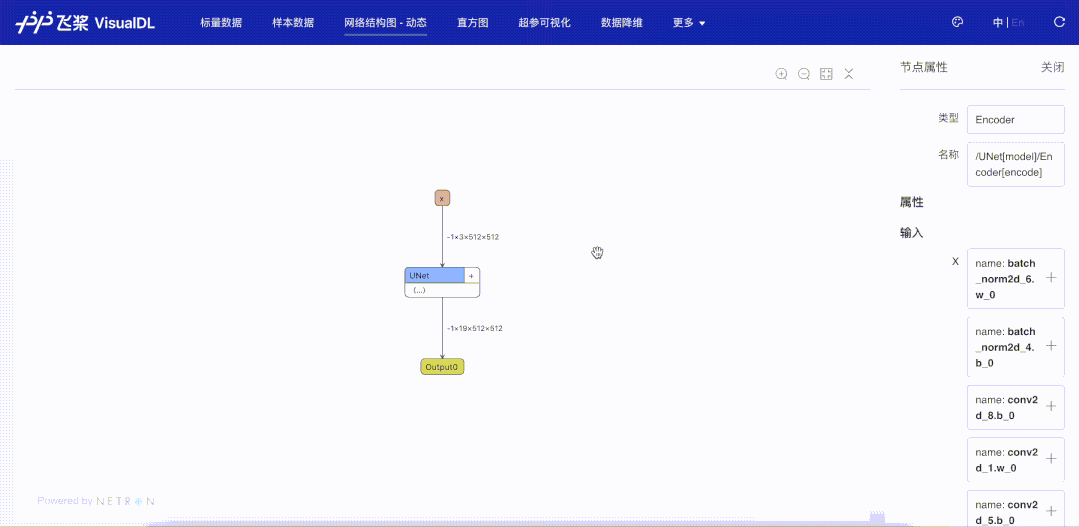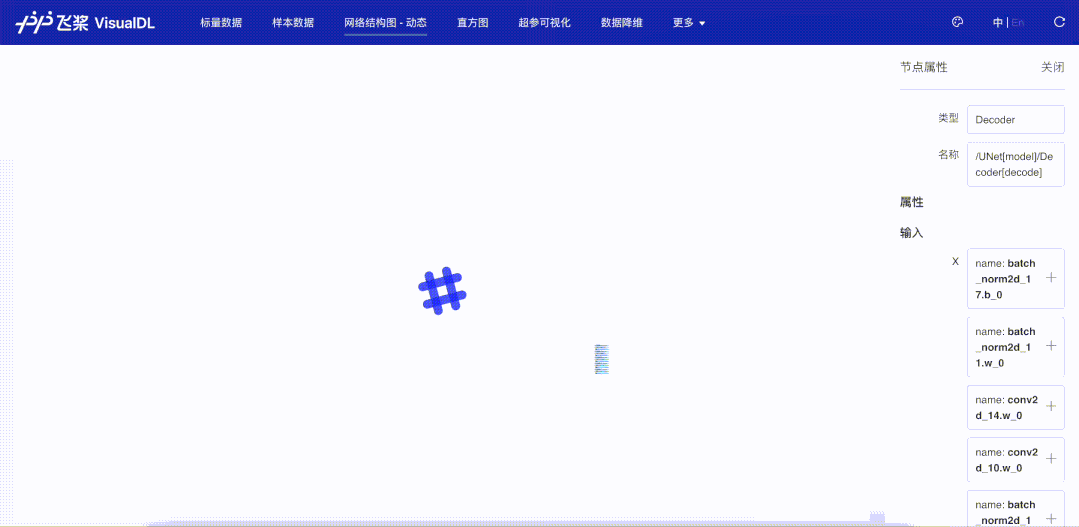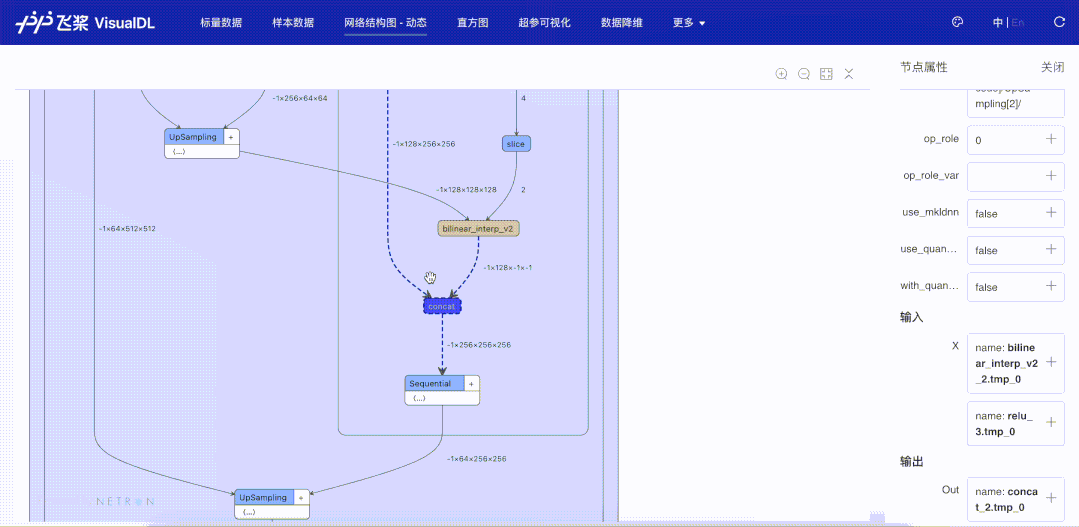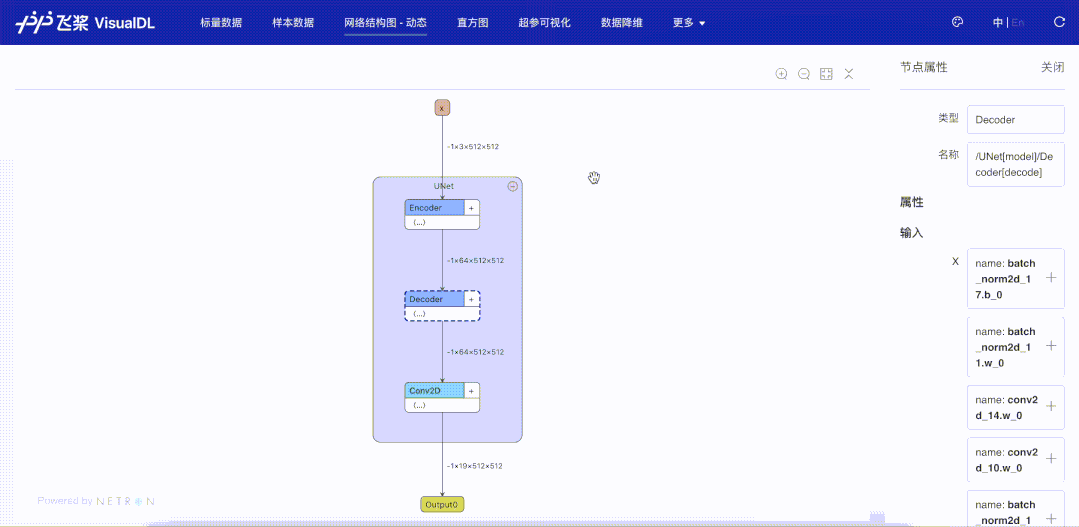
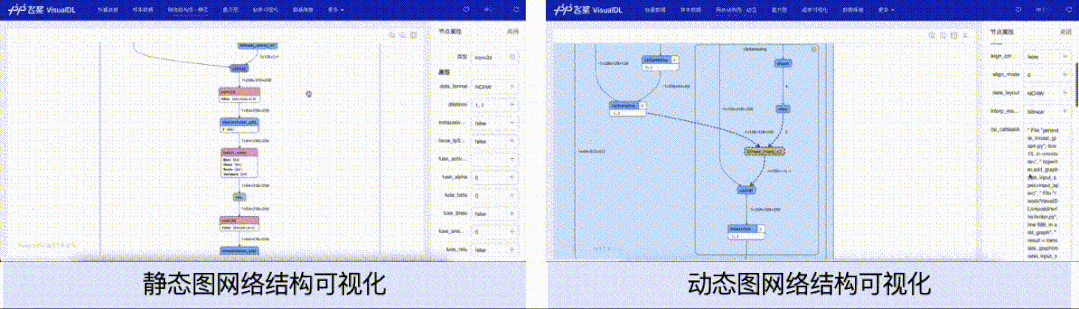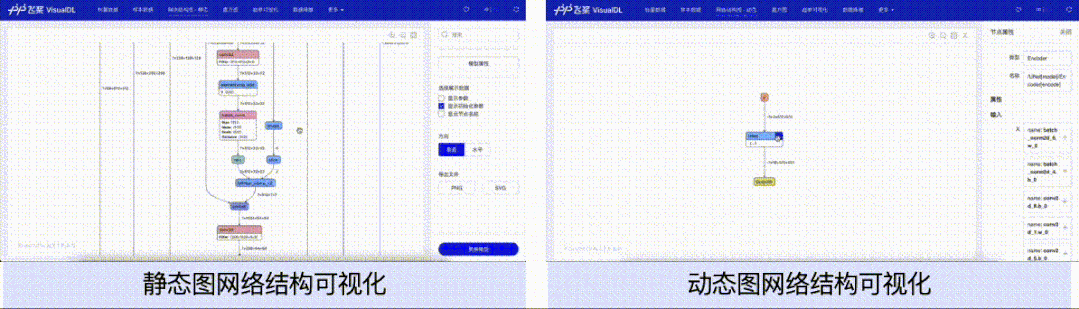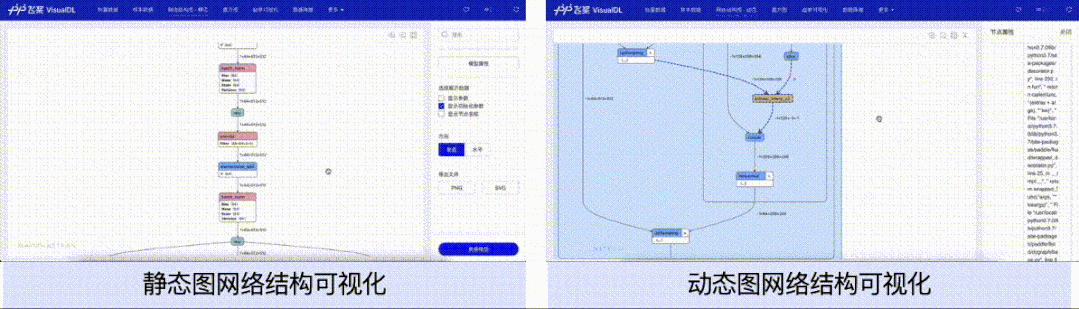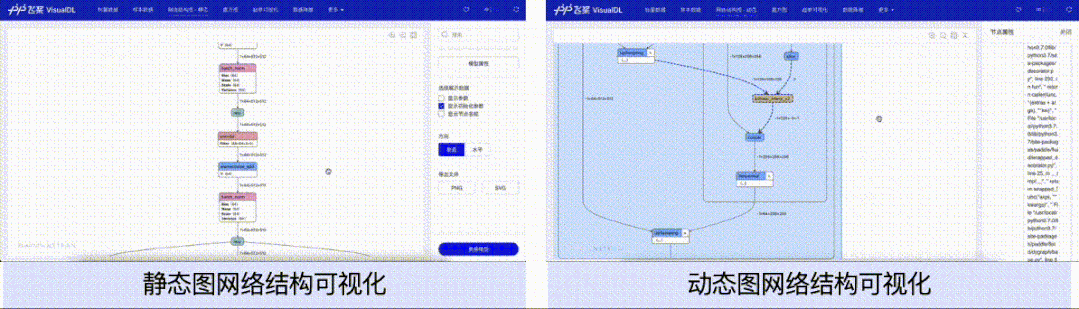
针对动态图组网的层级结构特性,支持模型开发者按层级可视化模型结构。模型的节点可以折叠和展开,每一个层级节点即是组网时候所用的nn.Layer,相比于静态图模型可视化时只能以框架底层的Op为节点,动态图可视化可以让开发者将展示的模型结构和所写的组网代码一一对应起来,为开发者验证组网的准确性提供了便利。
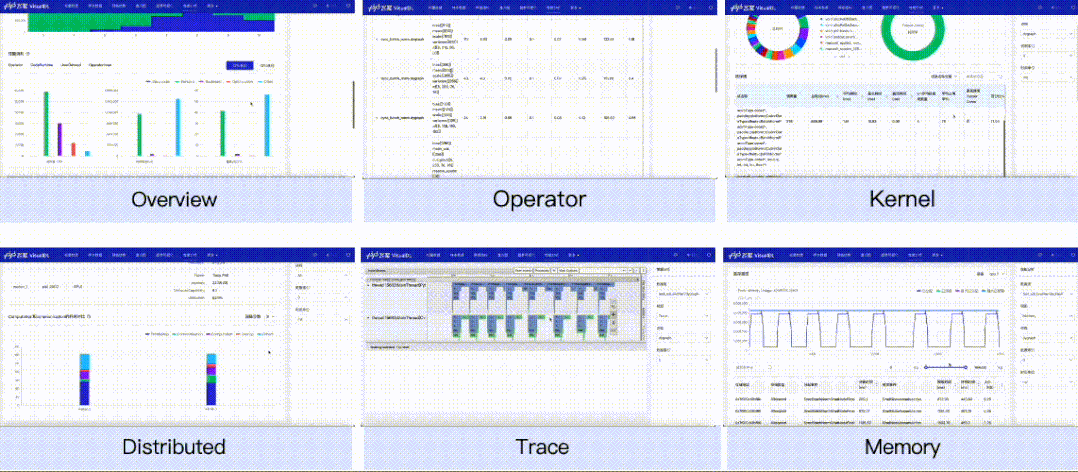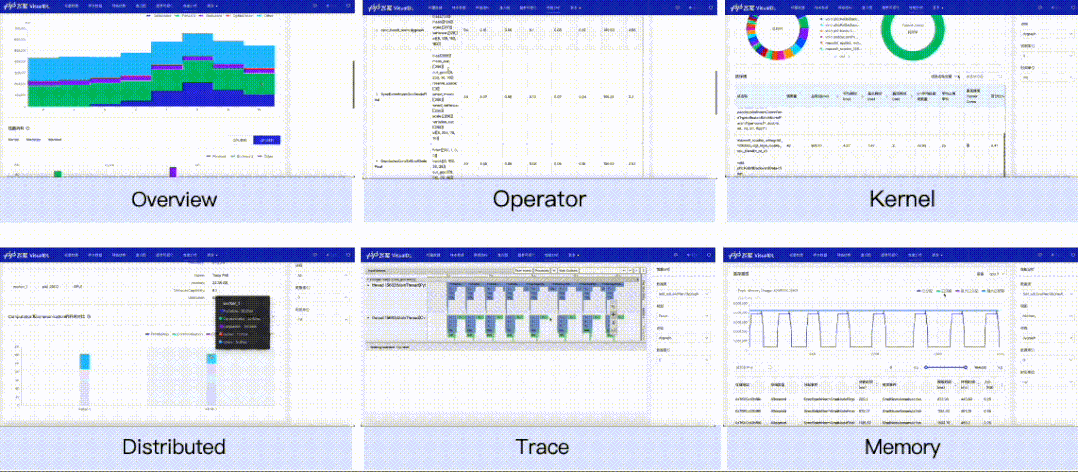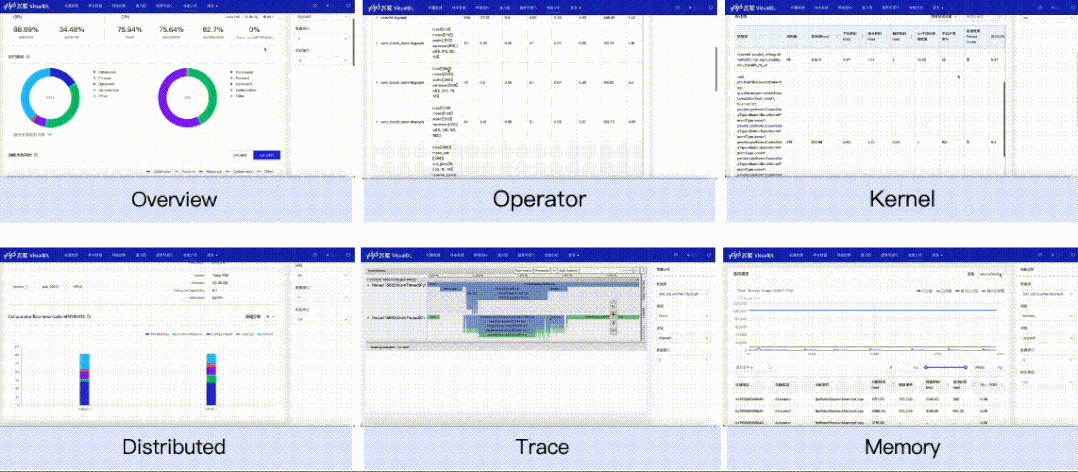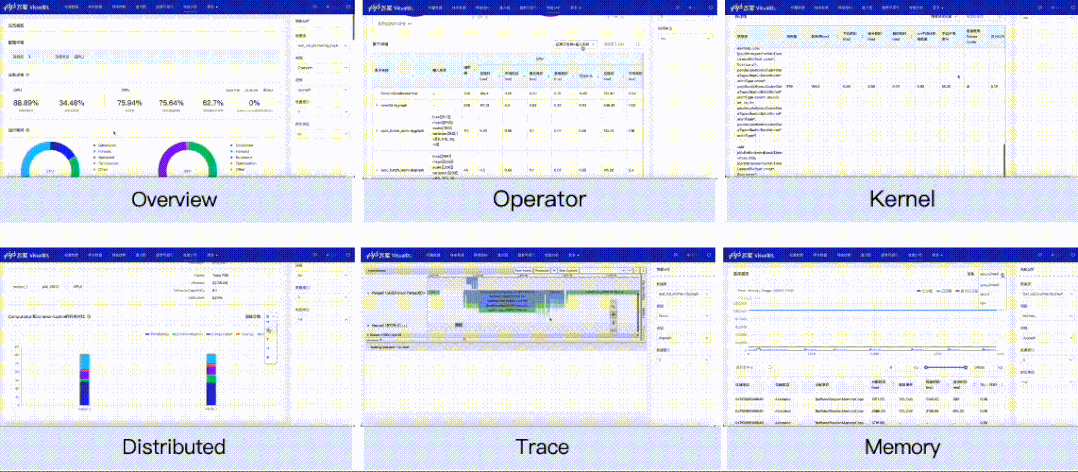
对飞桨框架导出的性能数据提供可视化支持,新增Overview、Operator、GPU Kernel、Distributed、Trace、Memory共六个视图的数据分析。开发者可以获取到模型运行的每个阶段(如前向、反向)的执行时间、框架算子的执行时间、GPU计算Kernel的时间、显存分配和释放的时间和大小等,这些信息既可以用于判断性能瓶颈,也可以用于验证执行了某个性能优化方案后的效果。
在本次功能升级之前,用户想要使用VisualDL可视化模型结构,只能可视化静态图格式的模型。然而静态图格式的模型结构中不存在模型的层级信息,只有以框架底层的Op为单个节点的信息。对于习惯使用动态图的用户而言,所展示的模型结构并不能直观地能和所定义的网络层(nn.Layer)对应起来,导致开发者无法直观便捷地将模型结构与代码关联起来,增加了使用成本。
为了解决这一问题,VisualDL的LogWriter(数据采集的类)新增了add_graph接口,使用该接口,用户只需传入所定义的nn.Layer动态图模型即可以导出模型结构并按照动态图组网的层级结构方式进行可视化。add_graph接口会自动分析并生成网络的层级信息,通过分析这些层级信息,来支持动态地展开和折叠节点,以及显示展开或者折叠后的节点输入和输出的张量流向关系。
飞桨框架从v2.3.0开始支持通过使用paddle.profiler来收集模型运行时的性能数据并导出,模型的性能数据由在框架中记录的各种类别的事件构成。如Operator类型的事件记录的是框架中算子执行的信息,Kernel类型的事件记录的是设备侧如GPU中Kernel执行计算的信息。
VisualDL本次加入性能分析功能,替用户解析并可视化性能数据,从多个不同的视角来分析程序的执行性能。目前共提供Overview、Operator、GPU Kernel、Distributed、Trace、Memory共六个视图的数据分析。
GPU Kernel视图——展示计算设备(如 GPU)上Kernel的执行情况,你可以获取到Kernel的执行次数和耗时、Kernel的其它属性以及它们的耗时占比关系。
Distributed视图——展示分布式程序中通信 (Communication)、计算 (Computation) 以及这两者 Overlap 的时间,结合Trace视图你可以获取到通信和计算之间的并行关系。
Memory视图——展示存储分配以及释放的情况,你可以直观看到框架管理的内存和显存随着时间的变化情况,以及每次分配或释放内存所发生的地址和时间,并会根据发生时间来对应相应的事件,以便定位该存储操作发生的位置。
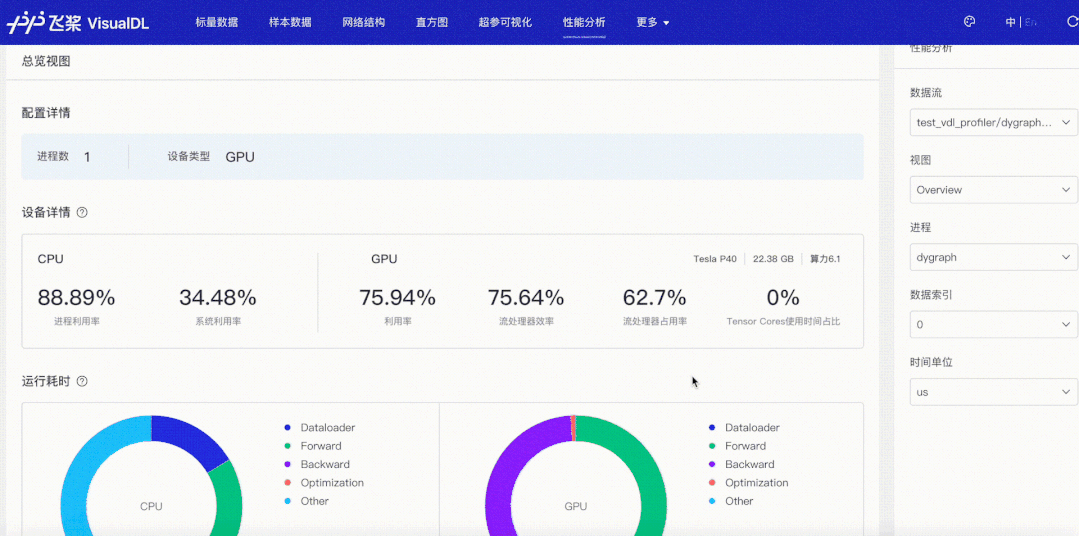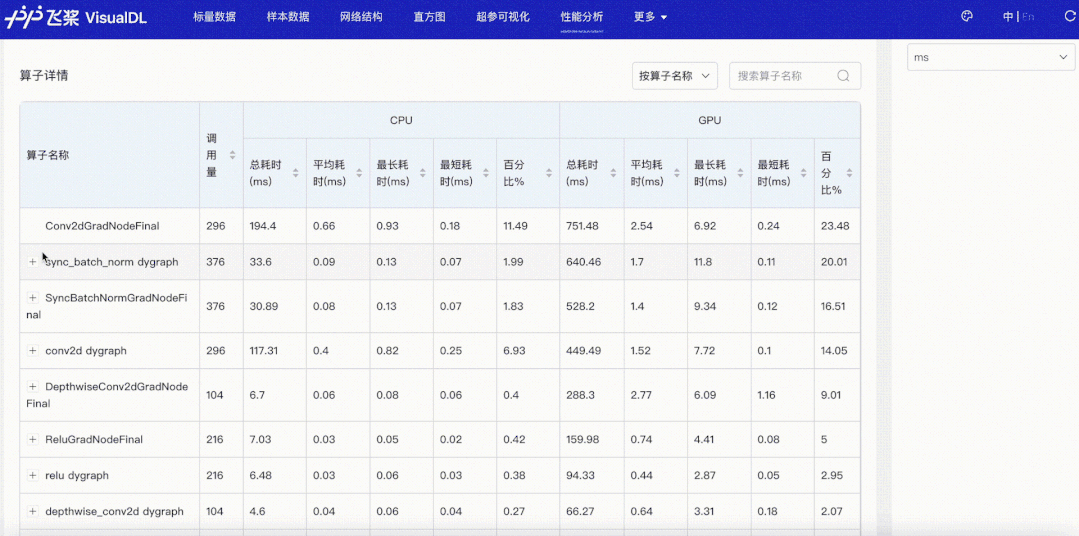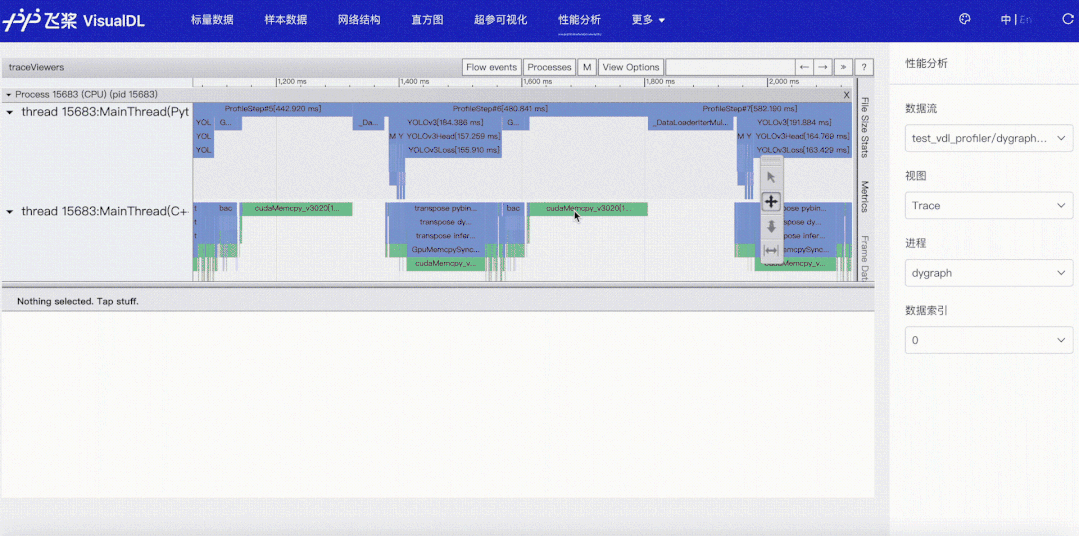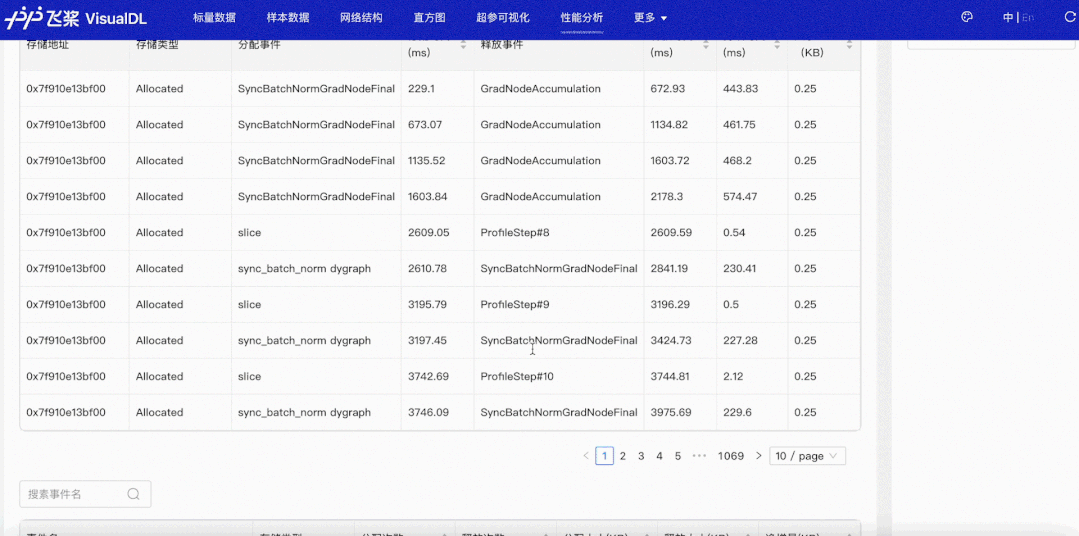
我们以最常见的数据读取瓶颈为例,看看性能分析功能是如何在性能调优中发挥作用的。使用默认参数下的Dataloader,开启框架的性能分析功能(使用方式可参考飞桨官网使用指南之模型性能分析),导出性能分析数据,然后开启VisualDL可视化数据。
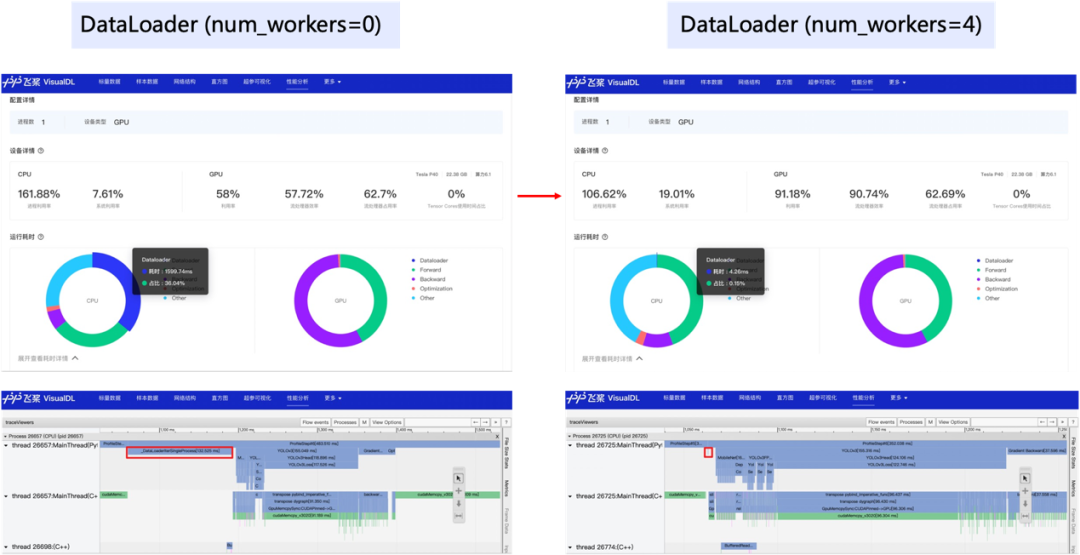
上述的简单案例展示了性能分析工具是如何提供数据指标来辅助开发者进行性能调优的,不同的性能瓶颈可能需要从不同的视图中去获取数据指标进行判断,但是在性能分析方面,使用VisualDL一定能够助你一臂之力!
项目链接:

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~
深度学习以网络结构繁杂和参数多著称,这导致开发者在模型训练过程中难免遇到调参方向不明和性能消耗难以优化等问题,大幅降低开发效率,因此模型训练调优的过程也被业界戏称为“炼丹”。随着深度学习技术在各行各业的渗透愈来愈深,如何缩短深度学习产业落地的耗时成为了近年来大家尤为关注的问题。
指标监控
标量、PR曲线、ROC曲线组件,可以帮助用户观察损失函数的变化以及评价模型效果。
样本呈现
样本数据(图像、文本、音频)组件,可以帮助用户对训练时输入的样本进行直观地查看。
模型理解
直方图、高维数据降维展示、超参数组件,可以帮助用户理解训练过程,如分析模型参数的分布是如何随着训练过程变化,模型某一层输出的张量的变化趋势,分析embedding的距离关系以及对比不同超参数对模型效果的影响等。
结构调试
性能调优
性能分析组件,可以帮助用户分析模型的执行性能,定位性能瓶颈。
项目链接
针对动态图组网的层级结构特性,支持模型开发者按层级可视化模型结构。模型的节点可以折叠和展开,每一个层级节点即是组网时候所用的nn.Layer,相比于静态图模型可视化时只能以框架底层的Op为节点,动态图可视化可以让开发者将展示的模型结构和所写的组网代码一一对应起来,为开发者验证组网的准确性提供了便利。
对飞桨框架导出的性能数据提供可视化支持,新增Overview、Operator、GPU Kernel、Distributed、Trace、Memory共六个视图的数据分析。开发者可以获取到模型运行的每个阶段(如前向、反向)的执行时间、框架算子的执行时间、GPU计算Kernel的时间、显存分配和释放的时间和大小等,这些信息既可以用于判断性能瓶颈,也可以用于验证执行了某个性能优化方案后的效果。
在本次功能升级之前,用户想要使用VisualDL可视化模型结构,只能可视化静态图格式的模型。然而静态图格式的模型结构中不存在模型的层级信息,只有以框架底层的Op为单个节点的信息。对于习惯使用动态图的用户而言,所展示的模型结构并不能直观地能和所定义的网络层(nn.Layer)对应起来,导致开发者无法直观便捷地将模型结构与代码关联起来,增加了使用成本。
为了解决这一问题,VisualDL的LogWriter(数据采集的类)新增了add_graph接口,使用该接口,用户只需传入所定义的nn.Layer动态图模型即可以导出模型结构并按照动态图组网的层级结构方式进行可视化。add_graph接口会自动分析并生成网络的层级信息,通过分析这些层级信息,来支持动态地展开和折叠节点,以及显示展开或者折叠后的节点输入和输出的张量流向关系。
飞桨框架从v2.3.0开始支持通过使用paddle.profiler来收集模型运行时的性能数据并导出,模型的性能数据由在框架中记录的各种类别的事件构成。如Operator类型的事件记录的是框架中算子执行的信息,Kernel类型的事件记录的是设备侧如GPU中Kernel执行计算的信息。
VisualDL本次加入性能分析功能,替用户解析并可视化性能数据,从多个不同的视角来分析程序的执行性能。目前共提供Overview、Operator、GPU Kernel、Distributed、Trace、Memory共六个视图的数据分析。
GPU Kernel视图——展示计算设备(如 GPU)上Kernel的执行情况,你可以获取到Kernel的执行次数和耗时、Kernel的其它属性以及它们的耗时占比关系。
Distributed视图——展示分布式程序中通信 (Communication)、计算 (Computation) 以及这两者 Overlap 的时间,结合Trace视图你可以获取到通信和计算之间的并行关系。
Memory视图——展示存储分配以及释放的情况,你可以直观看到框架管理的内存和显存随着时间的变化情况,以及每次分配或释放内存所发生的地址和时间,并会根据发生时间来对应相应的事件,以便定位该存储操作发生的位置。
我们以最常见的数据读取瓶颈为例,看看性能分析功能是如何在性能调优中发挥作用的。使用默认参数下的Dataloader,开启框架的性能分析功能(使用方式可参考飞桨官网使用指南之模型性能分析),导出性能分析数据,然后开启VisualDL可视化数据。
上述的简单案例展示了性能分析工具是如何提供数据指标来辅助开发者进行性能调优的,不同的性能瓶颈可能需要从不同的视图中去获取数据指标进行判断,但是在性能分析方面,使用VisualDL一定能够助你一臂之力!
项目链接:
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~