想了解更多TrustAI的信息,请点击:
链接:https://github.com/PaddlePaddle/TrustAI
下面将介绍TrustAI如何解决3类数据缺陷问题:
问题一:
训练数据存在脏数据
措施:自动识别脏数据,降低人力检查成本
训练数据标注质量对模型效果有较大影响,往往会成为模型效果提升的瓶颈。但当标注数据规模较大时,数据检查就成为一个难题。
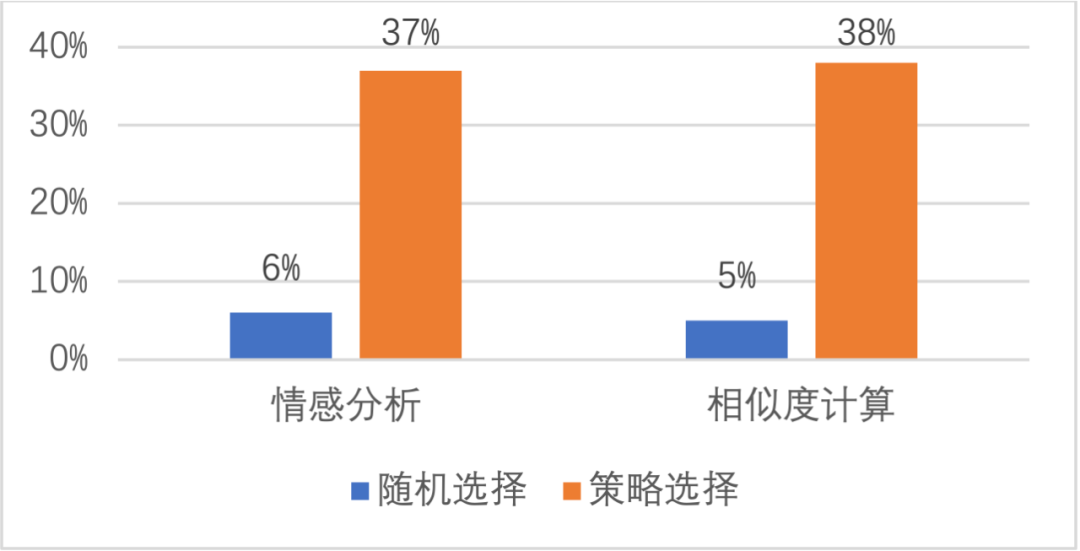
TrustAI提供了脏数据(即标注质量差的数据)自动识别功能,帮助降低人工检查数据的成本。如图一所示,在两个公开数据集上,TrustAI自动识别的脏数据比例远高于随机选择策略。
图一 不同策略识别出的脏数据比例
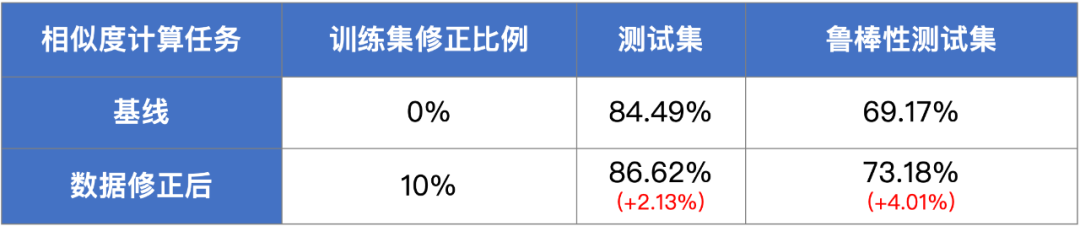
表一 修正脏数据后的实验结果
问题二:
训练数据覆盖不足
措施:标注尽量少的数据,提升模型效果
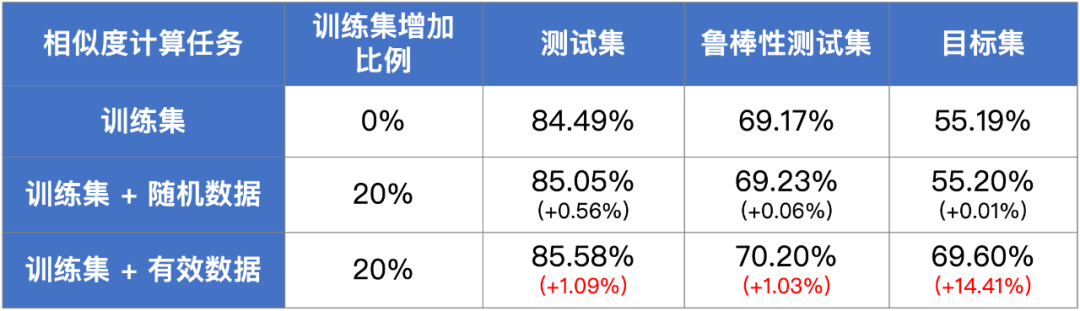
训练数据覆盖不足会导致模型在对应的测试数据上表现不好。数据扩充是提升模型效果直接的方法,然而数据标注是一个费时费力的工作,如何标注更少的数据带来更大的效果提升是大多数NLP开发者面临的难题。
问题三:
训练数据分布偏置
措施:缓解数据偏置对模型训练的影响,提升模型鲁棒性
研究表明,神经网络模型会利用数据集中的偏置作为预测的捷径,如在情感分析任务中,遇到否定词模型会倾向预测为“负向”情感。这种偏置会导致模型没有真正理解语言,导致模型的鲁棒性降低。
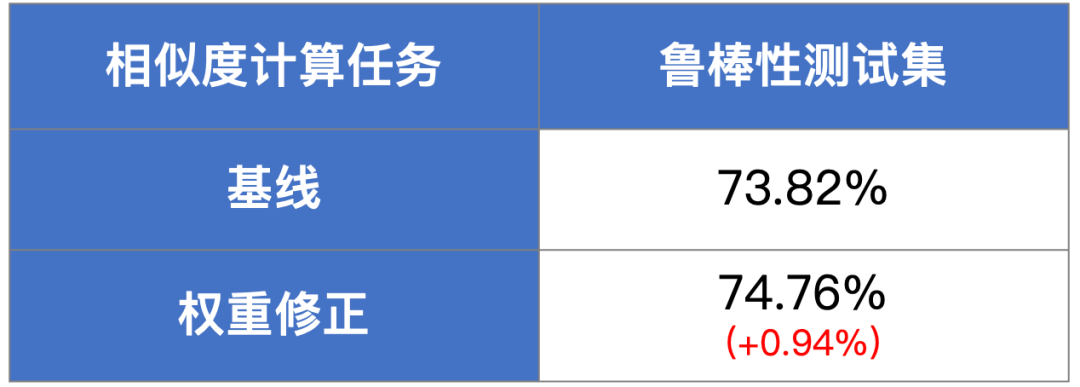
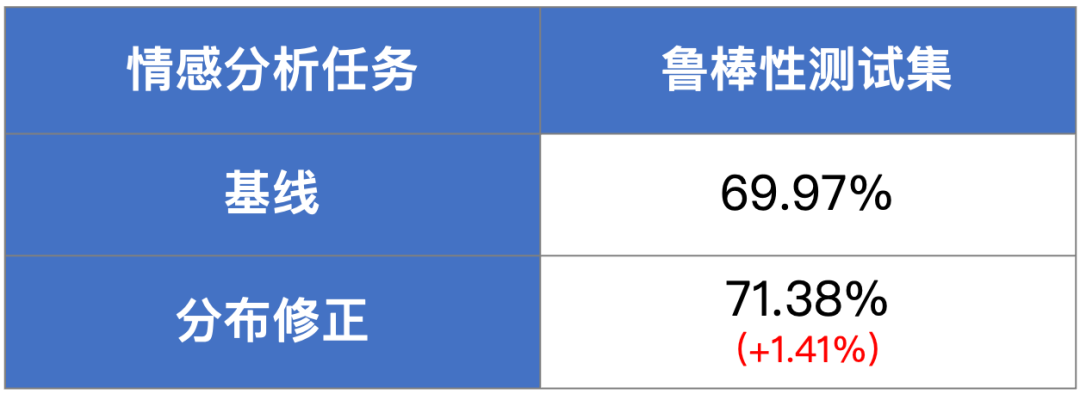
TrustAI提供了数据权重修正和数据分布修正两种优化策略,在不需要人工介入的条件下,缓解训练数据偏置对模型训练的影响,提升模型的语义理解能力,进而提升模型的鲁棒性。如表三所示,在相似度计算任务的鲁棒性测试集上,数据权重修正策略可带来准确率0.94%的提升。在表四中,数据分布修正策略在情感分析任务的鲁棒性数据集上,可使模型准确率提升1.41%。
关于TrustAI工具集推荐阅读
TrustAI支持pip一键安装,欢迎大家了解更多技术详情和使用方法,并贡献你的Star和Fork!
TrustAI项目:(点击阅读原文即可直达)
项目直达:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/text_classification
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~
想了解更多TrustAI的信息,请点击:
链接:https://github.com/PaddlePaddle/TrustAI
下面将介绍TrustAI如何解决3类数据缺陷问题:
问题一:
训练数据存在脏数据
措施:自动识别脏数据,降低人力检查成本
训练数据标注质量对模型效果有较大影响,往往会成为模型效果提升的瓶颈。但当标注数据规模较大时,数据检查就成为一个难题。
TrustAI提供了脏数据(即标注质量差的数据)自动识别功能,帮助降低人工检查数据的成本。如图一所示,在两个公开数据集上,TrustAI自动识别的脏数据比例远高于随机选择策略。
图一 不同策略识别出的脏数据比例
表一 修正脏数据后的实验结果
问题二:
训练数据覆盖不足
措施:标注尽量少的数据,提升模型效果
训练数据覆盖不足会导致模型在对应的测试数据上表现不好。数据扩充是提升模型效果直接的方法,然而数据标注是一个费时费力的工作,如何标注更少的数据带来更大的效果提升是大多数NLP开发者面临的难题。
问题三:
训练数据分布偏置
措施:缓解数据偏置对模型训练的影响,提升模型鲁棒性
研究表明,神经网络模型会利用数据集中的偏置作为预测的捷径,如在情感分析任务中,遇到否定词模型会倾向预测为“负向”情感。这种偏置会导致模型没有真正理解语言,导致模型的鲁棒性降低。
TrustAI提供了数据权重修正和数据分布修正两种优化策略,在不需要人工介入的条件下,缓解训练数据偏置对模型训练的影响,提升模型的语义理解能力,进而提升模型的鲁棒性。如表三所示,在相似度计算任务的鲁棒性测试集上,数据权重修正策略可带来准确率0.94%的提升。在表四中,数据分布修正策略在情感分析任务的鲁棒性数据集上,可使模型准确率提升1.41%。
关于TrustAI工具集推荐阅读
TrustAI支持pip一键安装,欢迎大家了解更多技术详情和使用方法,并贡献你的Star和Fork!
TrustAI项目:(点击阅读原文即可直达)
项目直达:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/text_classification
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~