性能优化
PP-Structurev2
模型优化策略概述
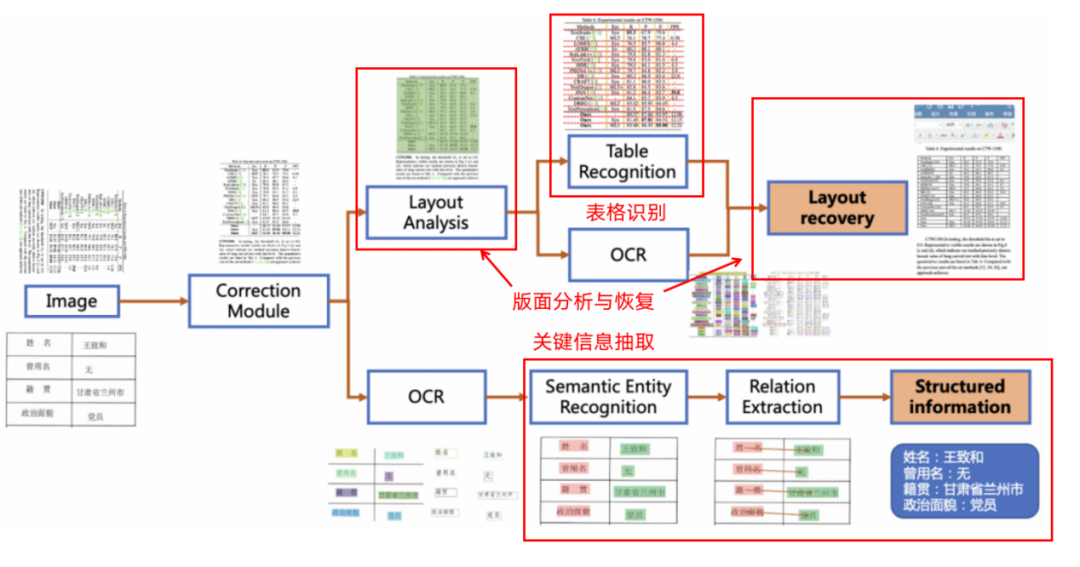
图2 PP-Structurev2流程图
模块1:版面分析
PP-PicoDet:轻量级版面分析模型
FGD:兼顾全局与局部特征的模型蒸馏算法
模块2:表格识别
PP-LCNet: CPU友好型轻量级骨干网络
模块3:关键信息抽取
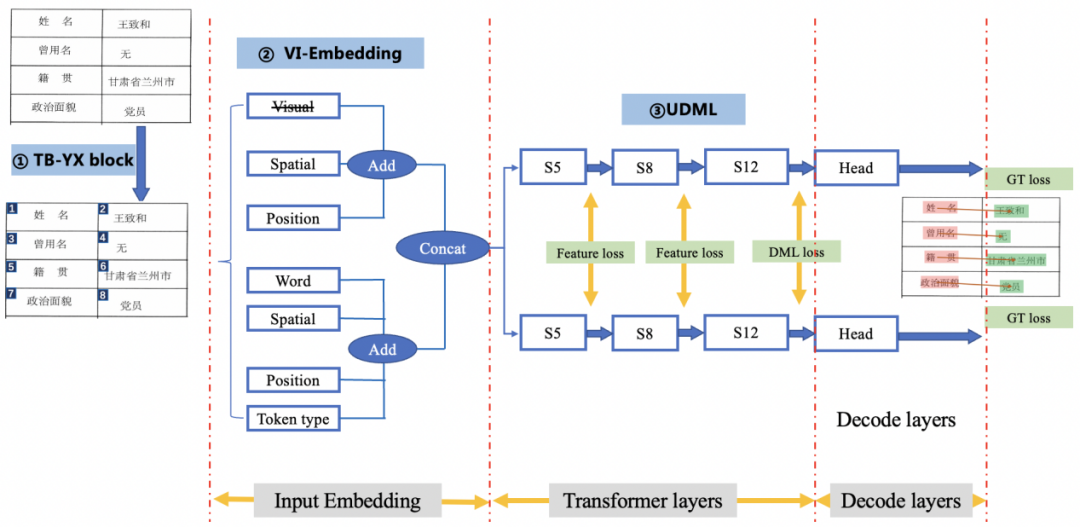
VI-LayoutXLM:视觉特征无关的多模态预训练模型结构
区别二:表格识别预测耗时不变,模型精度提升6%,端到端TEDS提升2%;
PP-Structurev2
核心8个优化策略详细解读
模块1:
版面分析与恢复优化策略2个
PP-PicoDet:轻量级版面分析模型
图3 版面分析效果图(分类为文字、图片、表格、图注、标注等)
模块2:
表格识别优化策略3个
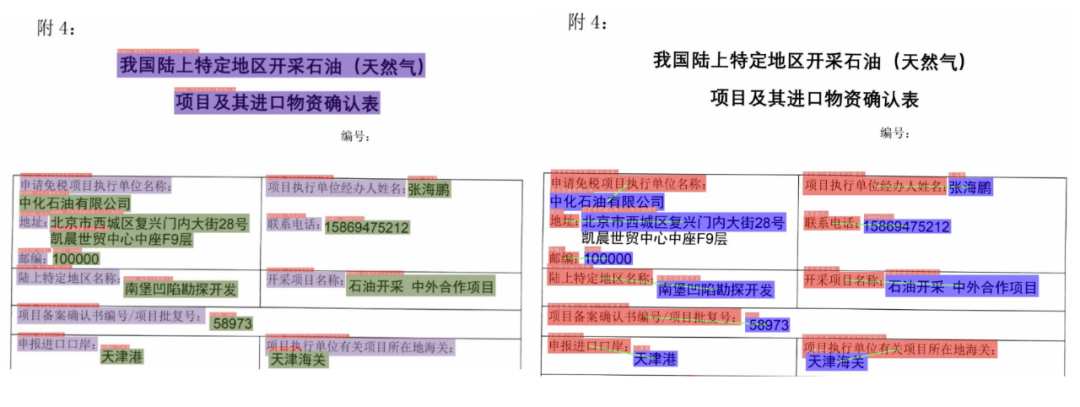
可视化结果如下,左为输入图像[1],右为识别的HTML表格结果
图5 可视化结果
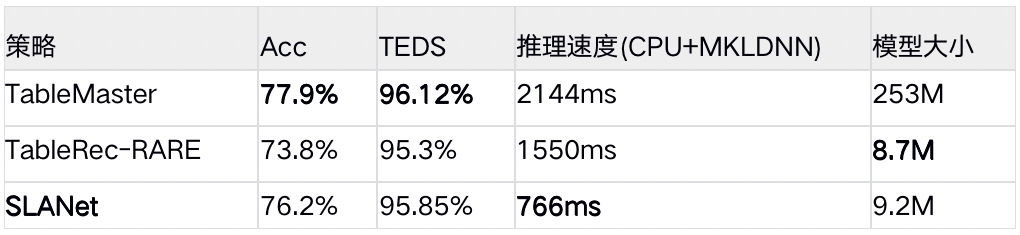
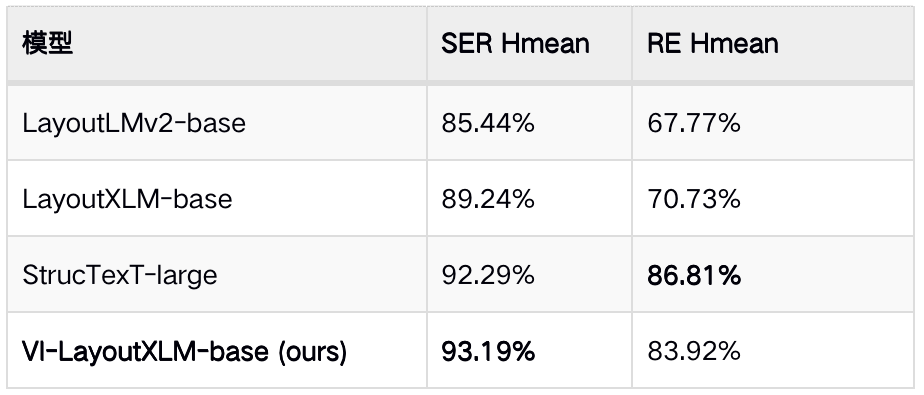
在PubtabNet英文表格识别数据集上,和其他方法对比如下。SLANet平衡精度与模型大小,推理速度最快,能够适配更多应用场景:
表1 SLANet模型与其他模型效果对比
PP-LCNet: CPU友好型轻量级骨干网络
PP-LCNet是结合Intel-CPU端侧推理特性而设计的轻量高性能骨干网络,在图像分类任务上,该方案在“精度-速度”均衡方面的表现比ShuffleNetV2、MobileNetV3、GhostNet等轻量级模型更优。PP-Structurev2中,我们采用PP-LCNet作为骨干网络,表格识别模型精度从71.73%提升至72.98%;同时加载通过SSLD知识蒸馏方案训练得到的图像分类模型权重作为表格识别的预训练模型,最终精度进一步提升2.95%至74.71%。
CSP-PAN:轻量级高低层特征融合模块
对骨干网络提取的特征进行融合,可以有效解决尺度变化较大等复杂场景中的模型预测问题。早期,FPN模块被提出并用于特征融合,但是它的特征融合过程仅包含单向(高->低),融合不够充分。CSP-PAN基于PAN进行改进,在保证特征融合更为充分的同时,使用CSP block、深度可分离卷积等策略减小了计算量。在表格识别场景中,我们进一步将CSP-PAN的通道数从128降低至96以降低模型大小。最终表格识别模型精度提升0.97%至75.68%,预测速度提升10%。
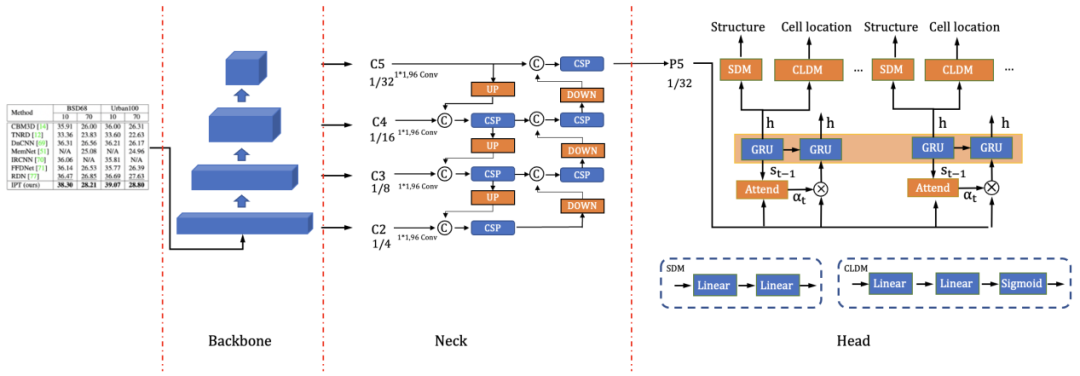
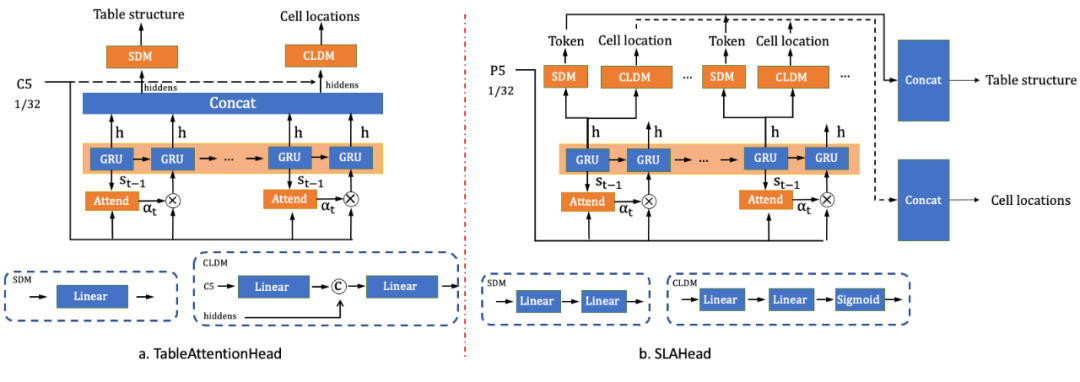
图6 SLAHead结构
模块3:
关键信息抽取优化策略3个
LayoutLMv2以及LayoutXLM中引入视觉骨干网络,用于提取视觉特征,并与后续的text embedding进行联合,作为多模态的输入embedding。但是该模块为基于ResNet_x101_64x4d的特征提取网络,特征抽取阶段耗时严重,因此我们将其去除,同时仍然保留文本、位置以及布局等信息,最终发现针对LayoutXLM进行改进,下游SER任务精度无损,针对LayoutLMv2进行改进,下游SER任务精度仅降低2.1%,而模型大小减小了约340M。具体消融实验可以参考技术报告。
图7 关键信息抽取流程图
TB-YX:考虑阅读顺序的文本行排序逻辑
文本阅读顺序对于信息抽取与文本理解等任务至关重要,传统多模态模型中,没有考虑不同OCR工具可能产生的不正确阅读顺序,而模型输入中包含位置编码,阅读顺序会直接影响预测结果,在预处理中,我们对文本行按照从上到下,从左到右(YX)的顺序进行排序,为防止文本行位置轻微干扰带来的排序结果不稳定问题,在排序的过程中,引入位置偏移阈值Th,对于Y方向距离小于Th的2个文本内容,使用X方向的位置从左到右进行排序。
社区开发者应用
PDF转Word小工具
软件的使用十分简单,解压压缩包,运行exe安装完成后打开软件,上传图片,点击转换后即可转换得到Word文件。
加入PaddleOCR
技术交流群
入群福利
福利三:获取PaddleOCR团队整理的10G重磅OCR学习大礼包,包括:
入群方式
图片来源
[1] 图片源于网络
更多阅读
https://www.paddlepaddle.org.cn
Gitee
https://gitee.com/paddlepaddle/PaddleOCR
PP-Structurev2技术报告

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~
性能优化
PP-Structurev2
模型优化策略概述
图2 PP-Structurev2流程图
模块1:版面分析
PP-PicoDet:轻量级版面分析模型
FGD:兼顾全局与局部特征的模型蒸馏算法
模块2:表格识别
PP-LCNet: CPU友好型轻量级骨干网络
模块3:关键信息抽取
VI-LayoutXLM:视觉特征无关的多模态预训练模型结构
区别二:表格识别预测耗时不变,模型精度提升6%,端到端TEDS提升2%;
PP-Structurev2
核心8个优化策略详细解读
模块1:
版面分析与恢复优化策略2个
PP-PicoDet:轻量级版面分析模型
图3 版面分析效果图(分类为文字、图片、表格、图注、标注等)
模块2:
表格识别优化策略3个
可视化结果如下,左为输入图像[1],右为识别的HTML表格结果
图5 可视化结果
在PubtabNet英文表格识别数据集上,和其他方法对比如下。SLANet平衡精度与模型大小,推理速度最快,能够适配更多应用场景:
表1 SLANet模型与其他模型效果对比
PP-LCNet: CPU友好型轻量级骨干网络
PP-LCNet是结合Intel-CPU端侧推理特性而设计的轻量高性能骨干网络,在图像分类任务上,该方案在“精度-速度”均衡方面的表现比ShuffleNetV2、MobileNetV3、GhostNet等轻量级模型更优。PP-Structurev2中,我们采用PP-LCNet作为骨干网络,表格识别模型精度从71.73%提升至72.98%;同时加载通过SSLD知识蒸馏方案训练得到的图像分类模型权重作为表格识别的预训练模型,最终精度进一步提升2.95%至74.71%。
CSP-PAN:轻量级高低层特征融合模块
对骨干网络提取的特征进行融合,可以有效解决尺度变化较大等复杂场景中的模型预测问题。早期,FPN模块被提出并用于特征融合,但是它的特征融合过程仅包含单向(高->低),融合不够充分。CSP-PAN基于PAN进行改进,在保证特征融合更为充分的同时,使用CSP block、深度可分离卷积等策略减小了计算量。在表格识别场景中,我们进一步将CSP-PAN的通道数从128降低至96以降低模型大小。最终表格识别模型精度提升0.97%至75.68%,预测速度提升10%。
图6 SLAHead结构
模块3:
关键信息抽取优化策略3个
LayoutLMv2以及LayoutXLM中引入视觉骨干网络,用于提取视觉特征,并与后续的text embedding进行联合,作为多模态的输入embedding。但是该模块为基于ResNet_x101_64x4d的特征提取网络,特征抽取阶段耗时严重,因此我们将其去除,同时仍然保留文本、位置以及布局等信息,最终发现针对LayoutXLM进行改进,下游SER任务精度无损,针对LayoutLMv2进行改进,下游SER任务精度仅降低2.1%,而模型大小减小了约340M。具体消融实验可以参考技术报告。
图7 关键信息抽取流程图
TB-YX:考虑阅读顺序的文本行排序逻辑
文本阅读顺序对于信息抽取与文本理解等任务至关重要,传统多模态模型中,没有考虑不同OCR工具可能产生的不正确阅读顺序,而模型输入中包含位置编码,阅读顺序会直接影响预测结果,在预处理中,我们对文本行按照从上到下,从左到右(YX)的顺序进行排序,为防止文本行位置轻微干扰带来的排序结果不稳定问题,在排序的过程中,引入位置偏移阈值Th,对于Y方向距离小于Th的2个文本内容,使用X方向的位置从左到右进行排序。
社区开发者应用
PDF转Word小工具
软件的使用十分简单,解压压缩包,运行exe安装完成后打开软件,上传图片,点击转换后即可转换得到Word文件。
加入PaddleOCR
技术交流群
入群福利
福利三:获取PaddleOCR团队整理的10G重磅OCR学习大礼包,包括:
入群方式
图片来源
[1] 图片源于网络
更多阅读
https://www.paddlepaddle.org.cn
Gitee
https://gitee.com/paddlepaddle/PaddleOCR
PP-Structurev2技术报告
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~