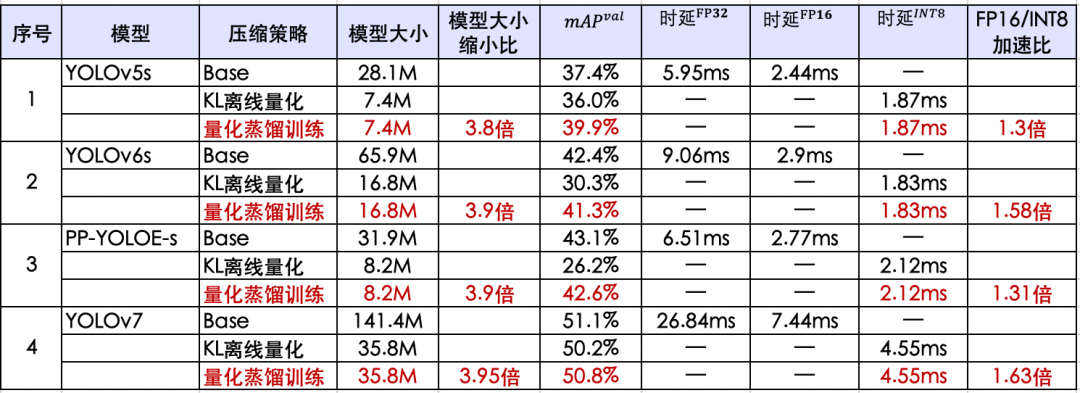
众所周知,YOLO系列算法在检测场景中获得了广泛应用,但是工程师追求“更准、更小、更快”的效率能力永无止境。本文为大家介绍一个低成本、高收益的AI模型自动压缩工具(ACT, Auto Compression Toolkit),在YOLO系列模型上利用基于知识蒸馏的量化训练方法,无需修改训练源代码,通过几十分钟量化训练,即可获得非常好的收益。举例来看:该方法在YOLOv7上模型体积降低75%,GPU上推理速度可提升163%。
图1 自动压缩工具在YOLO系列模型上的模型压缩和速度提升
【测试环境与补充说明】
1.测试数据与指标:mAP的指标均在COCO val2017数据集中评测得到。
注:YOLOv6原论文精度Baseline是mAP43.1%,由于模型导出是固定shape,所以导成ONNX后有掉点(-0.7%),实测精度42.4%;YOLOv7在原论文Baseline mAP 51.2%,导成ONNX后实测精度51.1%。
本文将从以下五个方面进一步技术解读,全文大约2300字,预计阅读时长3分钟。
模型自动压缩工具-动机和思考
模型自动压缩工具-量化蒸馏训练技术解析
模型自动压缩工具-量化蒸馏训练技术实战(以YOLOv7为例)
模型自动压缩工具-推理部署
未来工作展望
传送门:
https://github.com/PaddlePaddle/PaddleSlim/tree/develop/example/auto_compression/pytorch_yolo_series
模型自动压缩工具
动机与思考
模型量化是提升模型推理速度的手段之一,实际使用中有如下几点困难:
模型参数分布不均匀,导致量化误差大
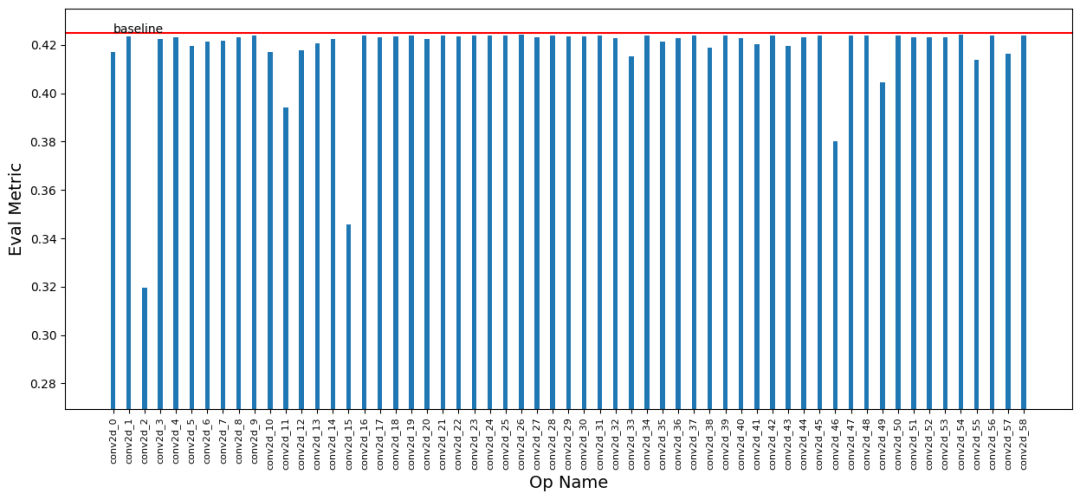
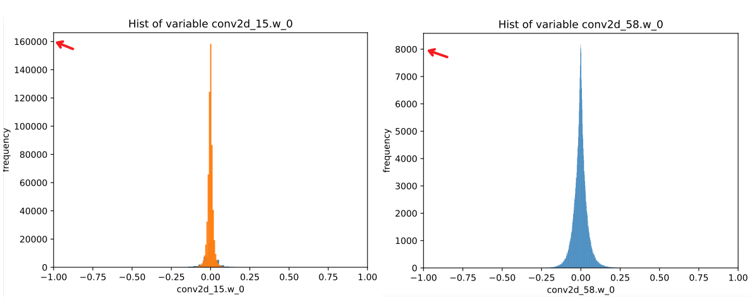 图3 权重数值分布对比
图3 权重数值分布对比
任务复杂度高,模型精度受量化误差的影响大
量化训练需修改训练代码,难度大,技术门槛高
量化蒸馏训练技术解析
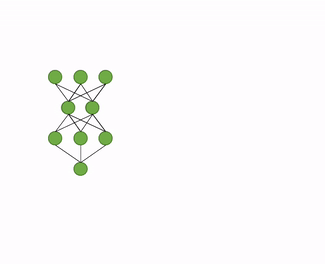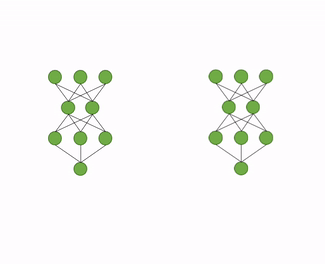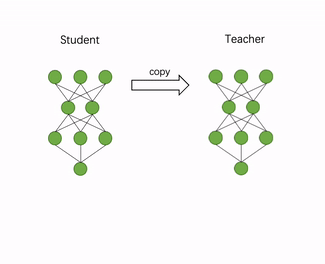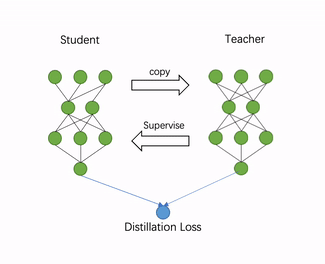
本文介绍的自动压缩工具(ACT)针对YOLO系列模型,利用知识蒸馏技术,自动为推理模型添加训练逻辑;无需修改训练代码,仅拿训练好的模型和部分无标注数据,训练几十分钟,即可达到预期效果。具体步骤包括如下3步,详细过程如下图所示。
构造教师模型
添加loss
自动地分析模型结构,寻找适合添加蒸馏loss的层,一般是最后一个带可训练参数的层。比如,检测模型head有多个分支的话,会将每个head最后一个conv作为蒸馏节点。
蒸馏训练
ACT还支持更多功能,包括离线量化超参搜索、算法自动组合和硬件感知等。功能详情以及ACT在更多场景的应用,请参加自动压缩工具首页介绍。
近期我们会将自动压缩代码提到YOLOv5、YOLOv6、YOLOv7、PP-YOLOE的官方repo中,这样大家在原模型项目中也可使用该能力。
量化蒸馏训练技术实战(以YOLOv7为例)
准备预测模型 导出ONNX模型。
git clone https://github.com/WongKinYiu/yolov7.git
cd yolov7
python export.py --weights yolov7-tiny.pt --grid准备训练数据&定义DataLoader
class COCOValDataset(paddle.io.Dataset):
def __init__(self,
dataset_dir=None,
image_dir=None,
anno_path=None,
img_size=[640, 640]):
self.dataset_dir = dataset_dir
self.image_dir = image_dir
self.img_size = img_size
self.ann_file = os.path.join(dataset_dir, anno_path)
self.coco = COCO(self.ann_file)
self.ids = list(sorted(self.coco.imgs.keys()))
def __getitem__(self, idx):
img_id = self.ids[idx]
img = self._get_img_data_from_img_id(img_id)
img, scale_factor = self.image_preprocess(img, self.img_size)
return {'image': img, 'im_id': np.array([img_id]), 'scale_factor': scale_factor}
def __len__(self):
return len(self.ids)
定义评估接口
为了在压缩过程中实时评估量化模型的精度,需要定义一个eval_function来做模型推理效果评估。这一步是可选的,如果没有eval_function也不会影响量化训练的过程。
def eval_function(exe, compiled_test_program, test_feed_names, test_fetch_list):
bboxes_list, bbox_nums_list, image_id_list = [], [], []
for data in val_loader:
data_all = {k: np.array(v) for k, v in data.items()}
outs = exe.run(compiled_test_program,
feed={test_feed_names[0]: data_all['image']},
fetch_list=test_fetch_list,
return_numpy=False)
postprocess = YOLOv7PostProcess(
score_threshold=0.001, nms_threshold=0.65, multi_label=True)
res = postprocess(np.array(outs[0]), data_all['scale_factor'])
bboxes_list.append(res['bbox'])
bbox_nums_list.append(res['bbox_num'])
image_id_list.append(np.array(data_all['im_id']))
map_res = coco_metric(anno_file, bboxes_list, bbox_nums_list, image_id_list)
return map_res[0]
定义配置文件
定义量化训练的配置文件,Distillation表示蒸馏参数配置,Quantization表示量化参数配置,TrainConfig表示训练时的训练轮数、优化器等设置。具体超参的设置可以参考ACT超参设置文档。
Distillation: # 蒸馏参数设置
alpha: 1.0 # 蒸馏loss所占权重
loss: soft_label
Quantization: # 量化参数设置
use_pact: true # 是否使用PACT量化算法
activation_quantize_type: 'moving_average_abs_max' # 激活量化方式,选择'moving_average_abs_max'即可
quantize_op_types: # 需要量化的OP类型,可以是conv2d、depthwise_conv2d、mul、matmul_v2等
- conv2d
- depthwise_conv2d
TrainConfig: # 训练的配置
train_iter: 3000 # 训练的轮数
eval_iter: 1000 # 训练中每次评估精度的间隔轮数
learning_rate: 0.00001 # 训练学习率
optimizer_builder: # 优化器设置
optimizer:
type: SGD
weight_decay: 4.0e-05
开始运行
少量代码就可以开始ACT量化训练。启动ACT时,需要传入模型文件的路径(model_dir)、模型文件名(model_filename)、参数文件名称(params_filename)、压缩后模型存储路径(save_dir)、压缩配置文件(config)、dataloader和评估精度的eval_callback。
from paddleslim.auto_compression import AutoCompression
ac = AutoCompression(
model_dir=global_config["model_dir"],
model_filename=global_config["model_filename"],
params_filename=global_config["params_filename"],
save_dir=FLAGS.save_dir,
config=all_config,
train_dataloader=train_loader,
eval_callback=eval_function)
ac.compress()
https://github.com/PaddlePaddle/PaddleSlim/tree/develop/example/auto_compression/pytorch_yolo_series
推理部署
完成量化训练后的模型,支持Paddle Inference TensorRT部署(以下简称Paddle TensorRT)。
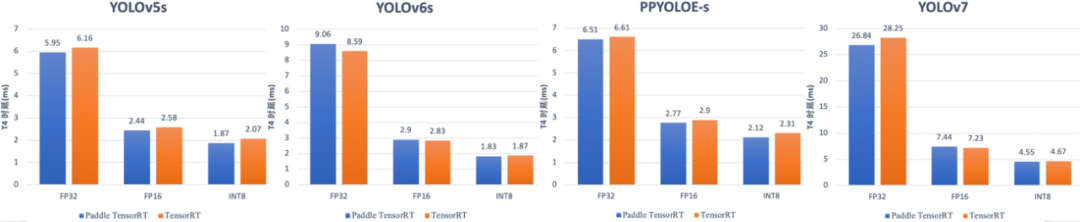
在YOLO系列模型上测试, Paddle TensorRT的性能与直接使用TensorRT基本持平,如下图所示(在YOLOv5s、PP-YOLOE-s、YOLOv7上,Paddle TensorRT性能优于TensorRT),相关推理部署代码已经集成到了自动压缩工具开源项目,可以直接下载体验。
图4 YOLO系列模型在Paddle TensorRT和TensorRT上的速度对比
# FP32
./build/trt_run --model_file yolov7_infer/model.pdmodel --params_file yolov7_infer/model.pdiparams --run_mode=trt_fp32
# FP16
./build/trt_run --model_file yolov7_infer/model.pdmodel --params_file yolov7_infer/model.pdiparams --run_mode=trt_fp16
# INT8
./build/trt_run --model_file yolov7_quant/model.pdmodel --params_file yolov7_quant/model.pdiparams --run_mode=trt_int8未来工作展望
ACT自动化压缩工具将支持更多AI模型的压缩;支持YOLO系列模型剪枝、非结构化稀疏等压缩方法;升级ACT能力,加入更多前沿压缩算法;支持完善更多部署方法,包括ONNX Runtime、OpenVINO等,进一步助力AI模型工程落地。
直播预告
想了解YOLO系列模型压缩策略,了解更多自动压缩工具的算法和能力,快快扫码加群关注我们的直播间吧!
直播时间:2022.08.22(周一)19:00-20:00。
欢迎大家扫码报名!
项目地址
GitHub:
Gitee:
拓展阅读
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~
众所周知,YOLO系列算法在检测场景中获得了广泛应用,但是工程师追求“更准、更小、更快”的效率能力永无止境。本文为大家介绍一个低成本、高收益的AI模型自动压缩工具(ACT, Auto Compression Toolkit),在YOLO系列模型上利用基于知识蒸馏的量化训练方法,无需修改训练源代码,通过几十分钟量化训练,即可获得非常好的收益。举例来看:该方法在YOLOv7上模型体积降低75%,GPU上推理速度可提升163%。
图1 自动压缩工具在YOLO系列模型上的模型压缩和速度提升
【测试环境与补充说明】
1.测试数据与指标:mAP的指标均在COCO val2017数据集中评测得到。
注:YOLOv6原论文精度Baseline是mAP43.1%,由于模型导出是固定shape,所以导成ONNX后有掉点(-0.7%),实测精度42.4%;YOLOv7在原论文Baseline mAP 51.2%,导成ONNX后实测精度51.1%。
本文将从以下五个方面进一步技术解读,全文大约2300字,预计阅读时长3分钟。
模型自动压缩工具-动机和思考
模型自动压缩工具-量化蒸馏训练技术解析
模型自动压缩工具-量化蒸馏训练技术实战(以YOLOv7为例)
模型自动压缩工具-推理部署
未来工作展望
传送门:
https://github.com/PaddlePaddle/PaddleSlim/tree/develop/example/auto_compression/pytorch_yolo_series
模型自动压缩工具
动机与思考
模型量化是提升模型推理速度的手段之一,实际使用中有如下几点困难:
模型参数分布不均匀,导致量化误差大
图3 权重数值分布对比
任务复杂度高,模型精度受量化误差的影响大
量化训练需修改训练代码,难度大,技术门槛高
量化蒸馏训练技术解析
本文介绍的自动压缩工具(ACT)针对YOLO系列模型,利用知识蒸馏技术,自动为推理模型添加训练逻辑;无需修改训练代码,仅拿训练好的模型和部分无标注数据,训练几十分钟,即可达到预期效果。具体步骤包括如下3步,详细过程如下图所示。
构造教师模型
添加loss
自动地分析模型结构,寻找适合添加蒸馏loss的层,一般是最后一个带可训练参数的层。比如,检测模型head有多个分支的话,会将每个head最后一个conv作为蒸馏节点。
蒸馏训练
ACT还支持更多功能,包括离线量化超参搜索、算法自动组合和硬件感知等。功能详情以及ACT在更多场景的应用,请参加自动压缩工具首页介绍。
近期我们会将自动压缩代码提到YOLOv5、YOLOv6、YOLOv7、PP-YOLOE的官方repo中,这样大家在原模型项目中也可使用该能力。
量化蒸馏训练技术实战(以YOLOv7为例)
准备预测模型 导出ONNX模型。
git clone https://github.com/WongKinYiu/yolov7.git
cd yolov7
python export.py --weights yolov7-tiny.pt --grid准备训练数据&定义DataLoader
class COCOValDataset(paddle.io.Dataset):
def __init__(self,
dataset_dir=None,
image_dir=None,
anno_path=None,
img_size=[640, 640]):
self.dataset_dir = dataset_dir
self.image_dir = image_dir
self.img_size = img_size
self.ann_file = os.path.join(dataset_dir, anno_path)
self.coco = COCO(self.ann_file)
self.ids = list(sorted(self.coco.imgs.keys()))
def __getitem__(self, idx):
img_id = self.ids[idx]
img = self._get_img_data_from_img_id(img_id)
img, scale_factor = self.image_preprocess(img, self.img_size)
return {'image': img, 'im_id': np.array([img_id]), 'scale_factor': scale_factor}
def __len__(self):
return len(self.ids)
定义评估接口
为了在压缩过程中实时评估量化模型的精度,需要定义一个eval_function来做模型推理效果评估。这一步是可选的,如果没有eval_function也不会影响量化训练的过程。
def eval_function(exe, compiled_test_program, test_feed_names, test_fetch_list):
bboxes_list, bbox_nums_list, image_id_list = [], [], []
for data in val_loader:
data_all = {k: np.array(v) for k, v in data.items()}
outs = exe.run(compiled_test_program,
feed={test_feed_names[0]: data_all['image']},
fetch_list=test_fetch_list,
return_numpy=False)
postprocess = YOLOv7PostProcess(
score_threshold=0.001, nms_threshold=0.65, multi_label=True)
res = postprocess(np.array(outs[0]), data_all['scale_factor'])
bboxes_list.append(res['bbox'])
bbox_nums_list.append(res['bbox_num'])
image_id_list.append(np.array(data_all['im_id']))
map_res = coco_metric(anno_file, bboxes_list, bbox_nums_list, image_id_list)
return map_res[0]
定义配置文件
定义量化训练的配置文件,Distillation表示蒸馏参数配置,Quantization表示量化参数配置,TrainConfig表示训练时的训练轮数、优化器等设置。具体超参的设置可以参考ACT超参设置文档。
Distillation: # 蒸馏参数设置
alpha: 1.0 # 蒸馏loss所占权重
loss: soft_label
Quantization: # 量化参数设置
use_pact: true # 是否使用PACT量化算法
activation_quantize_type: 'moving_average_abs_max' # 激活量化方式,选择'moving_average_abs_max'即可
quantize_op_types: # 需要量化的OP类型,可以是conv2d、depthwise_conv2d、mul、matmul_v2等
- conv2d
- depthwise_conv2d
TrainConfig: # 训练的配置
train_iter: 3000 # 训练的轮数
eval_iter: 1000 # 训练中每次评估精度的间隔轮数
learning_rate: 0.00001 # 训练学习率
optimizer_builder: # 优化器设置
optimizer:
type: SGD
weight_decay: 4.0e-05
开始运行
少量代码就可以开始ACT量化训练。启动ACT时,需要传入模型文件的路径(model_dir)、模型文件名(model_filename)、参数文件名称(params_filename)、压缩后模型存储路径(save_dir)、压缩配置文件(config)、dataloader和评估精度的eval_callback。
from paddleslim.auto_compression import AutoCompression
ac = AutoCompression(
model_dir=global_config["model_dir"],
model_filename=global_config["model_filename"],
params_filename=global_config["params_filename"],
save_dir=FLAGS.save_dir,
config=all_config,
train_dataloader=train_loader,
eval_callback=eval_function)
ac.compress()
https://github.com/PaddlePaddle/PaddleSlim/tree/develop/example/auto_compression/pytorch_yolo_series
推理部署
完成量化训练后的模型,支持Paddle Inference TensorRT部署(以下简称Paddle TensorRT)。
在YOLO系列模型上测试, Paddle TensorRT的性能与直接使用TensorRT基本持平,如下图所示(在YOLOv5s、PP-YOLOE-s、YOLOv7上,Paddle TensorRT性能优于TensorRT),相关推理部署代码已经集成到了自动压缩工具开源项目,可以直接下载体验。
图4 YOLO系列模型在Paddle TensorRT和TensorRT上的速度对比
# FP32
./build/trt_run --model_file yolov7_infer/model.pdmodel --params_file yolov7_infer/model.pdiparams --run_mode=trt_fp32
# FP16
./build/trt_run --model_file yolov7_infer/model.pdmodel --params_file yolov7_infer/model.pdiparams --run_mode=trt_fp16
# INT8
./build/trt_run --model_file yolov7_quant/model.pdmodel --params_file yolov7_quant/model.pdiparams --run_mode=trt_int8未来工作展望
ACT自动化压缩工具将支持更多AI模型的压缩;支持YOLO系列模型剪枝、非结构化稀疏等压缩方法;升级ACT能力,加入更多前沿压缩算法;支持完善更多部署方法,包括ONNX Runtime、OpenVINO等,进一步助力AI模型工程落地。
直播预告
想了解YOLO系列模型压缩策略,了解更多自动压缩工具的算法和能力,快快扫码加群关注我们的直播间吧!
直播时间:2022.08.22(周一)19:00-20:00。
欢迎大家扫码报名!
项目地址
GitHub:
Gitee:
拓展阅读
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~