2022年5月,飞桨框架2.3版本正式发布,创新性地提出了业界首个全流程硬件感知的性能自动调优解决方案,支持“一键开启”的极简操作方式,使开发者无需对模型代码进行任何改动,就可以充分发挥框架和硬件的极致性能。大量模型实验表明,自动调优可达到持平甚至超越经验丰富的性能优化专家手工调整的效果,解决了开发者性能优化费时费力的问题。
深度学习模型的训练往往需要耗费大量机器资源和时间,因此众多AI开发者非常迫切地追求极致性能。通过性能优化,一方面可以缩短模型效果验证的周期,提高研发效率;另一方面也会节约大量的资金成本并有效减少碳排放。例如OpenAI设计并发布的GPT-3模型,据估算一次训练成本高达400余万美元,以致于即使研发人员在训练过程中发现了一个错误,但由于成本原因也并未进行修复。
针对开发者在性能优化方面的痛点问题,飞桨框架2.3版本依据模型整体性能关键点推出了业界首个全流程自动调优方案,在训练时框架可根据不同模型针对不同硬件自动调整运行配置、选择最优算子内核(Kernel)等,使模型获得最佳性能,其效果可以与经验丰富的性能优化专家持平,很好地解决了在各种硬件平台针对不同任务的模型手工调优难的问题。
模型训练主要性能瓶颈分析
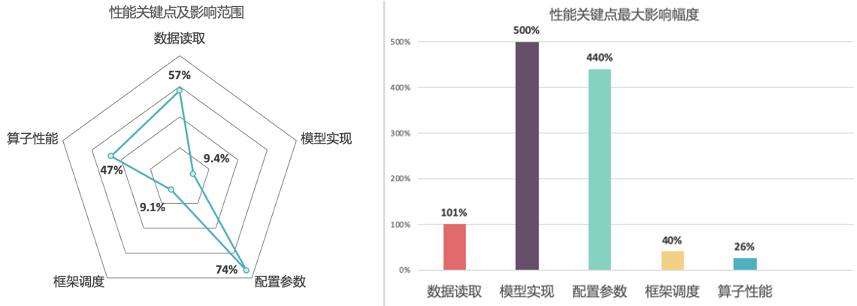
通常我们会以训练精度、训练速度、所需资源来评价一个模型训练性能的优劣。在模型训练收敛的迭代次数不变的情况下,训练速度可以用吞吐量(Instances Per Second,IPS)即每秒处理的样本数目来直观表示。模型的吞吐量会受到多种因素影响,我们首先从硬件层面来分析,看看是哪些情况影响了硬件的执行效率。以下面训练任务的时间轴(timeline)示意图为例,我们可以将常见的性能瓶颈归类为3个方面:
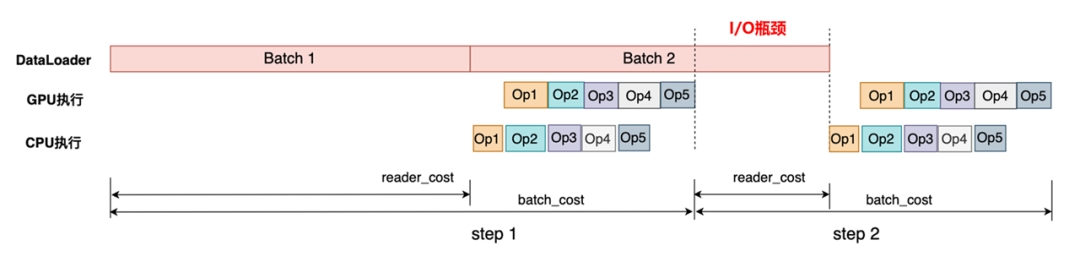
I/O瓶颈:
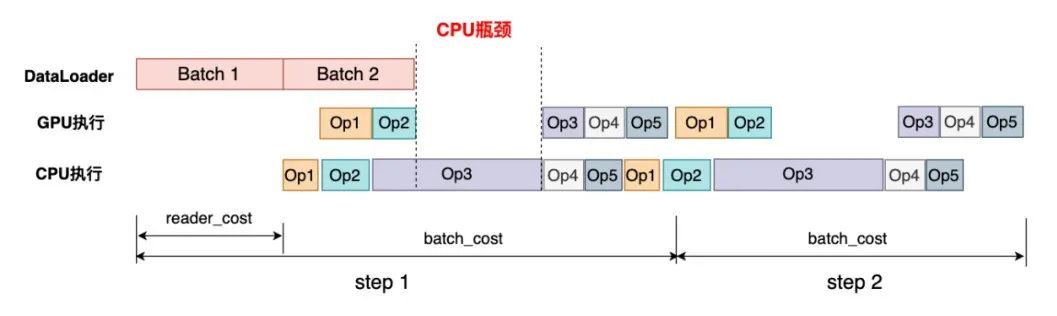
CPU瓶颈
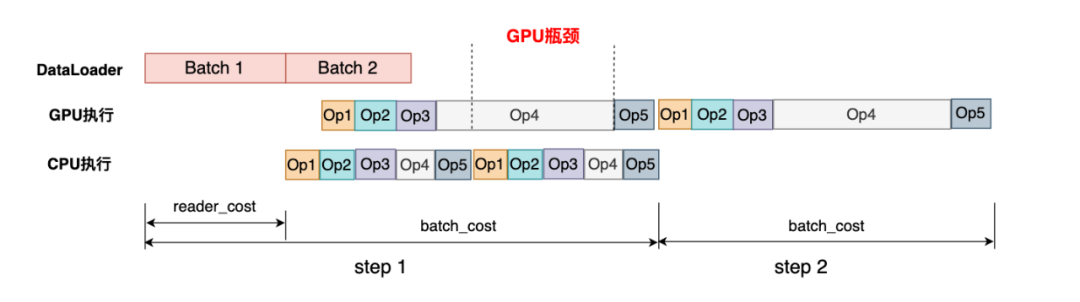
GPU瓶颈
虽然GPU提供了很高的算力,但如果GPU算子实现不够高效,也会导致性能较差。如下图示例中Op4的GPU处理时间明显很长,可能存在较多的优化空间。
数据读取
很多框架都提供了多进程数据读取的功能,但进程数的设置完全依赖用户经验,设置不当反而还会导致性能变差
配置参数
尤其在使用混合精度训练时,需要使Tensor的布局和大小等设置满足硬件限制,目前需要开发人员手工调整
算子性能
大多数框架基本都会用cuDNN、cuBLAS等高性能加速库,但是在各种硬件、各种尺寸和数据类型的场景下,单一加速库也难以保障性能保持最优,不同场景下可能需要使用不同的算子实现,这也需要开发者有足够的经验以及分析能力才能确认
框架调度
一些模型计算开销并不大,这种场景下框架执行调度的开销会对模型性能产生明显影响
模型实现
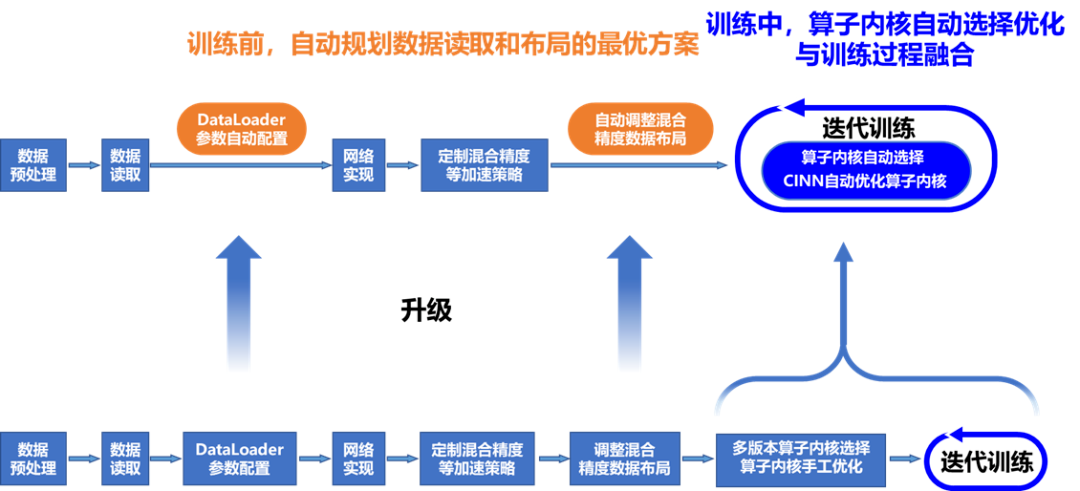
多层次性能自动调优技术
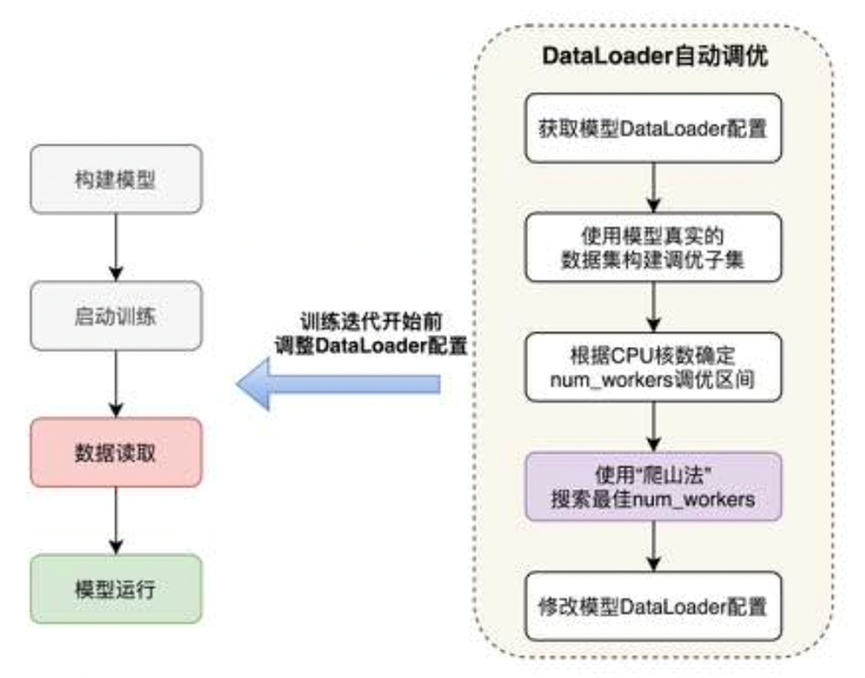
针对不同硬件环境下默认的DataLoader参数配置无法发挥硬件最优性能的问题,在训练开始前,飞桨根据模型的输入数据、训练的硬件对DataLoader参数自动搜索,在训练过程中,使用调优后的配置读取数据。
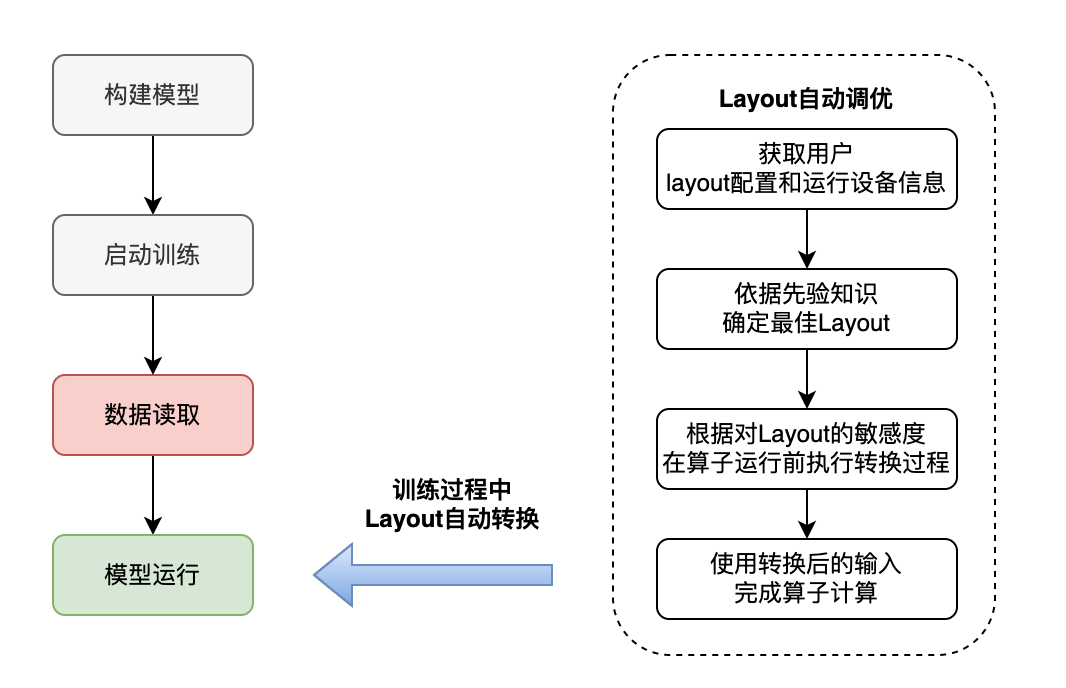
数据布局(Layout)自动切换
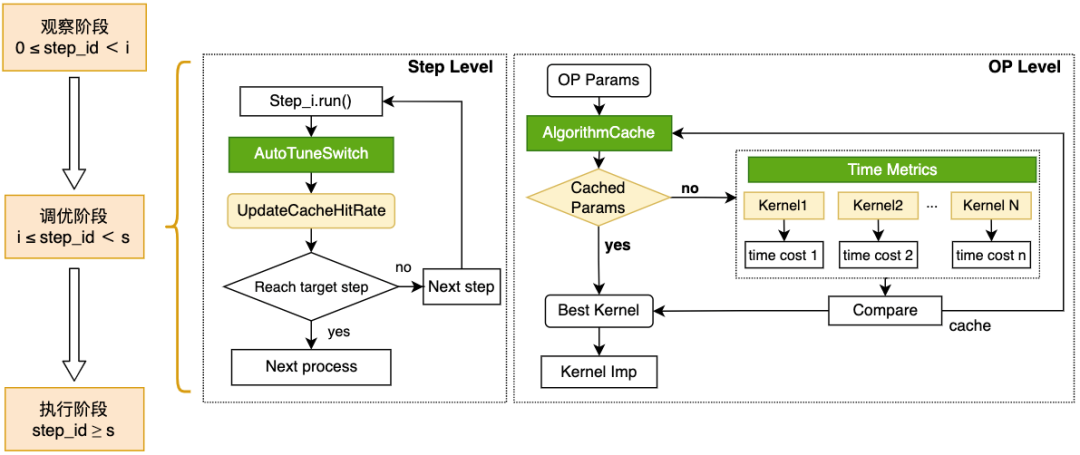
针对各种数据类型、输入尺寸和配置参数下,单一的算子内核难以保证在所有场景下达到最佳性能的问题,飞桨引入调优区间的概念,将整个训练过程分为观察阶段、调优阶段、应用阶段。观察阶段,使用默认实现便于用户调试;调优阶段,使用穷举搜索法选择代价最小的Kernel并进行缓存;应用阶段,依据算子配置从缓存中获取算法,未命中则使用默认实现。基于该功能,模型在输入尺寸固定或动态变化的场景下均可通过算法搜索获得性能提升。
数据读取参数自动调优
目前主流深度学习框架都在数据读取方面进行了底层优化,比如通过多进程并发处理数据读取、预处理以及组batch等任务,通过共享内存加速进程间数据传输,通过异步操作来消除数据拷贝过程的耗时,从而实现异步、并发的方式加速数据读取、预处理和数据拷贝等数据I/O任务。显然,并发对数据读取的性能有很大作用,但大多数框架对并发度的设置(num_workers)仅提供了一个基础的默认值,比如飞桨和PyTorch的默认值都为"0",即仅采用主线程读取数据,此默认设置难以在各种硬件环境下达到最优的性能。考虑到机器设备的CPU核数量有限,数据读取的并发数并非越大越好,过大的并发数会加重CPU进程调度的负担,导致整体性能反而降低。由于最优并发度的设置与硬件相关,因此大多数框架目前都将此设置交给开发者决策,尽管开发者可以通过手工调整提升读取性能,但仍需多次测试才能找到最合适的num_workers参数,无疑增加了模型训练的操作成本。
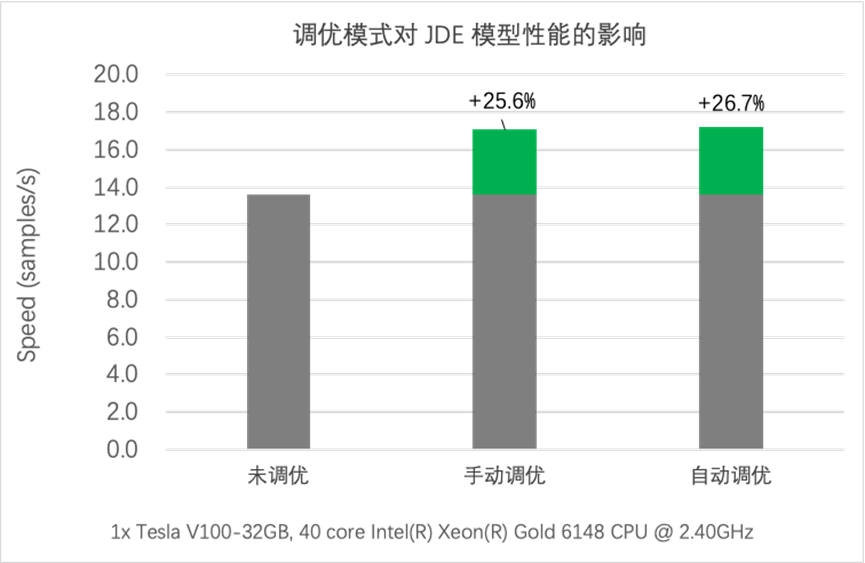
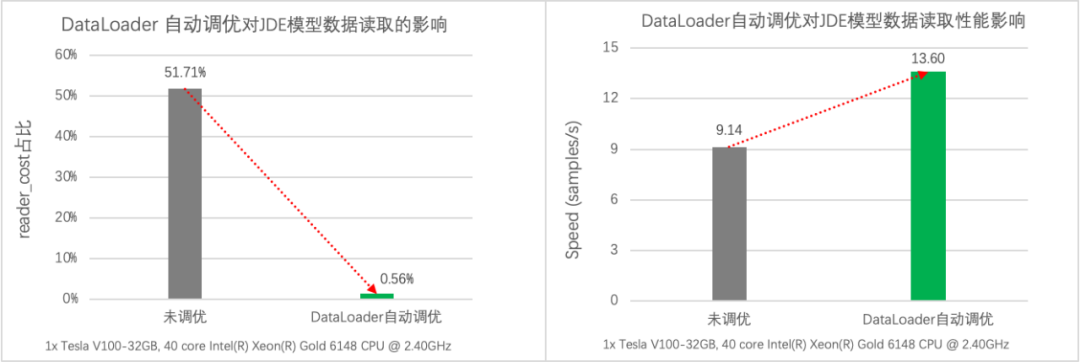
计算机视觉类的任务由于图像数据的读取和预处理开销较高,如果DataLoader未启用多进程异步数据读取,则非常容易出现I/O瓶颈。以目标检测的JDE模型为例,通过性能分析我们发现模型的数据读取开销占比高达51.71%,使用自动调优功能后,模型的数据读取降低至0.56%,同时吞吐量从原始的 9.14 samples/s 提升到13.60samples/s,性能提升了49%。
数据布局(Layout)自动调优
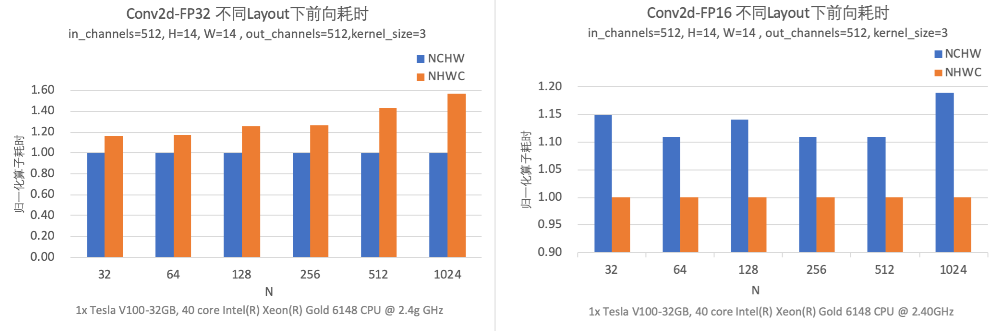
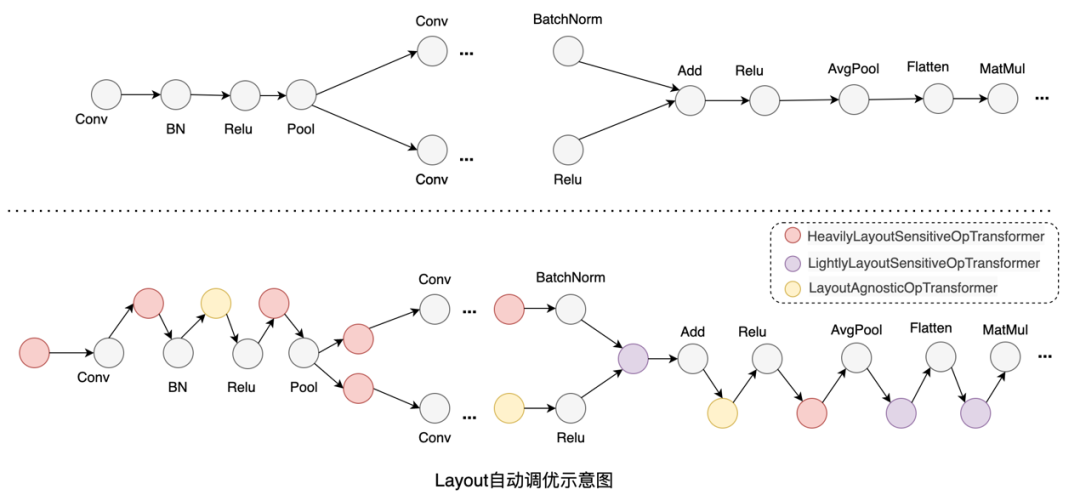
深度学习框架中针对多维数组通常支持通道在前(NCHW)和通道在后(NHWC)两种格式,在不同硬件上数据排布方式的选择会对性能产生较大的影响。下图实验是Conv算子在不同数据布局和数据类型下的前向运算耗时,结果表明在V100 GPU上固定输入、输出通道数及卷积核尺寸的前提下,FP32计算采用NCHW数据布局性能最优,而FP16计算则是采用NHWC最优。因此当一个使用NCHW数据布局的FP32模型想要开启混合精度模式来进行加速的时候,要么需要开发者手动对数据布局进行调整,要么需要额外在相关算子前后插入Transpose操作对数据布局进行转换,但这样又会带来额外的转换开销。
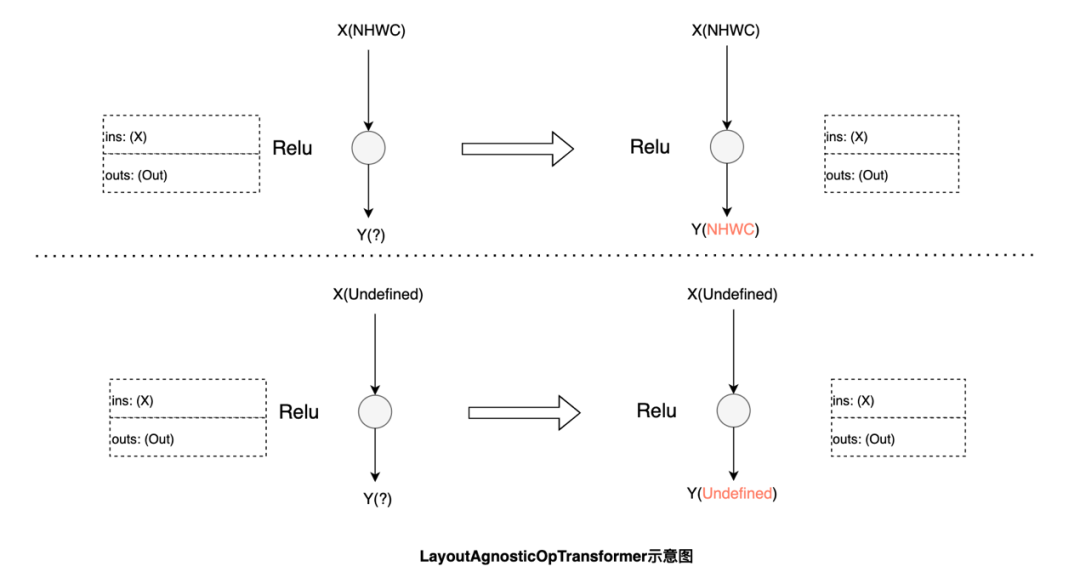
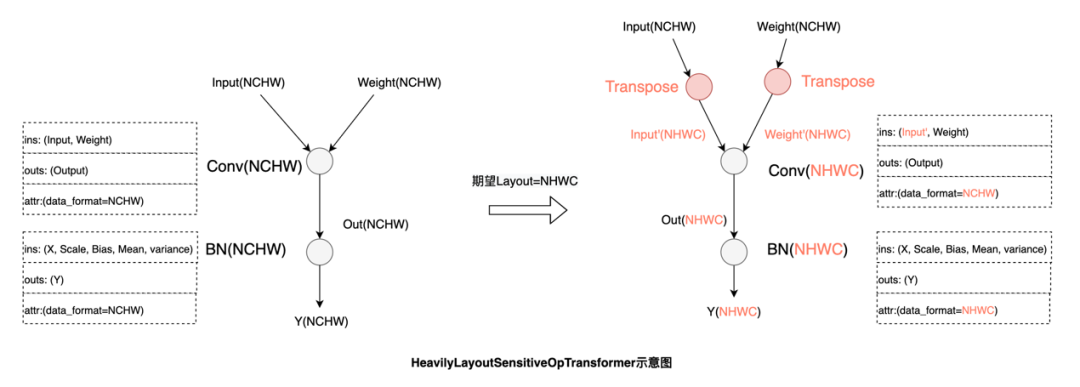
功能和性能与数据布局强相关的算子:
例如Conv,这类算子会在输入不是最佳数据布局时,将输入转换为最佳数据布局:
功能与数据布局强相关,性能影响较弱的算子:
例如Flatten,由于计算过程涉及到张量维度配置,其功能会受数据布局影响。根据输入的数据布局,可以对start和stop的axis做调整达到等效的结果,而在无法通过调整算子参数达到等效时,则需要将输入转换回原始的数据布局进行计算:
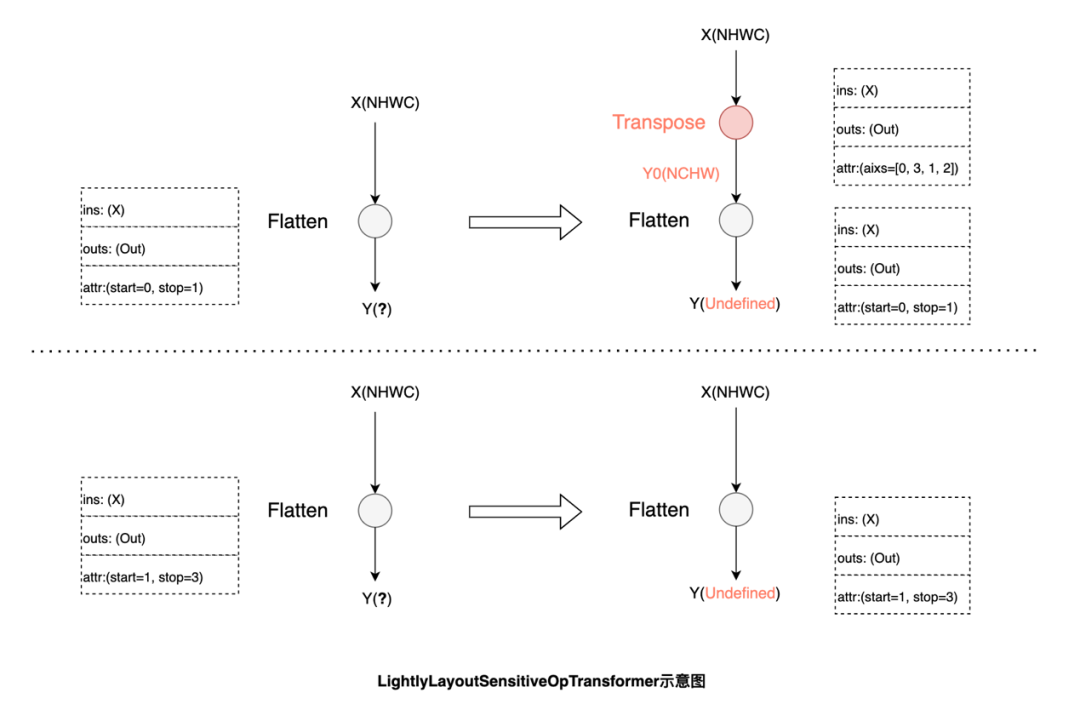
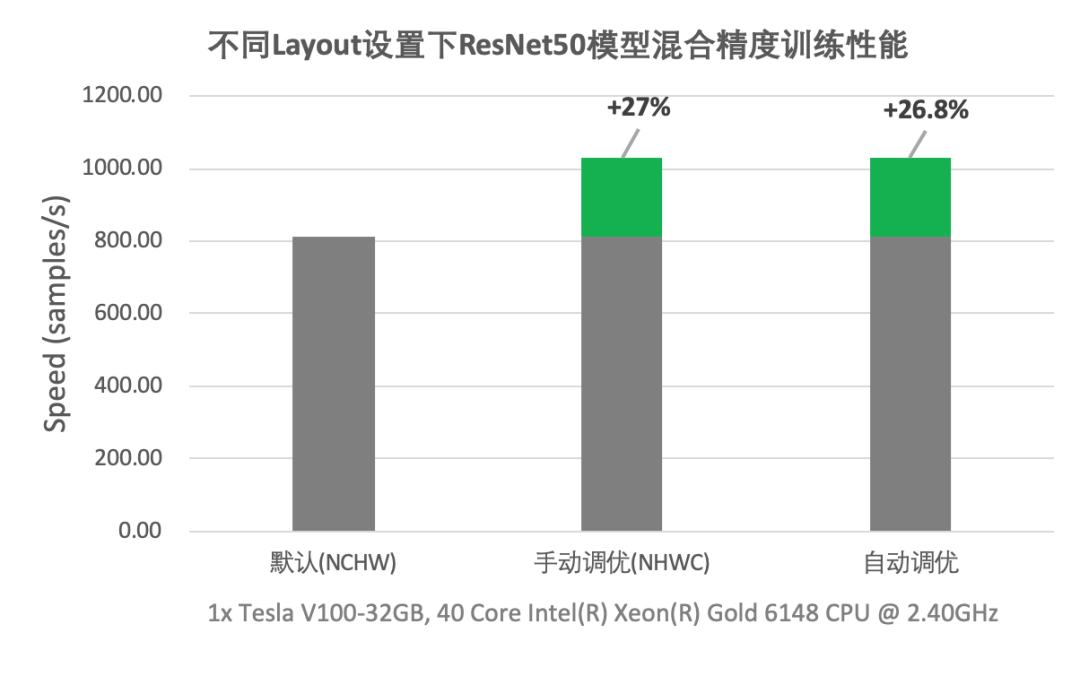
在自动调优的过程中,飞桨会引入最小的转换代价使模型在最佳数据布局下运行,换取更大的性能收益。使用V100 GPU进行ResNet50的混合精度训练,在模型默认数据布局为NCHW的情况下,开启自动调优后吞吐量提升了26.8%,与手工调优性能持平。
多版本算子内核自动选择
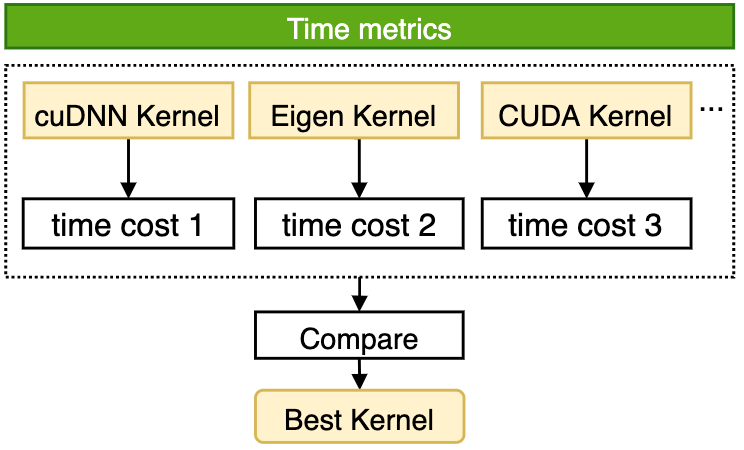
在实现方案上,算子内核自动选择功能由观察阶段、优化阶段、执行阶段组成,各阶段的主要功能如下:
观察阶段
优化阶段
框架自动采用穷举计算模式,针对当前算子的输入调用全部可用算法计算,记录并比较各算法的性能,从中选出最高效算法后,利用Cache机制将当前计算场景与被选中算法进行绑定,保证当前计算场景在后续复现时,算子内可以立即查询Cache并执行最高性能算法。
执行阶段
根据cache信息调用最佳算法完成算子计算,若在后续计算中面对数据变换等情形时,则走入默认计算分支,避免庞大的算法选择开销。
算子内核自动选择机制可有效应对各类变尺度数据集训练场景,挖掘算子内各算法性能潜力,在各类训练场景下获得良好的性能收益。例如PaddleDetection套件中数据shape变化非常大的JDE模型,可以发现开启算子内核自动选择功能后,模型的训练性能可以获得大幅提升,且超越了手动设置cuDNN启发式搜索模式等各种手动设置的性能。
此外,飞桨提供的算子内核自动选择机制在设计上不仅覆盖了框架原生的多种算子实现,还覆盖飞桨深度学习编译器中生成和优化的算子,结合编译器对算子的自动优化能力,可以达到更好的性能。在ResNet50模型上的测试表明,性能已经可以持平业界最优编译器优化的结果。
一键开启自动调优
飞桨框架2.3版本可以通过以下方法:
paddle.incubate.autotune.set_config(config=None)
一键开启所有自动调优功能。也可以根据调试的需求自定义调优功能的开和关:
kernel
layout
dataloader
config = {
"kernel": {
"enable": True,
"tuning_range": [1, 5],
"layout": {
"enable": True,
"dataloader": {
"enable": True,
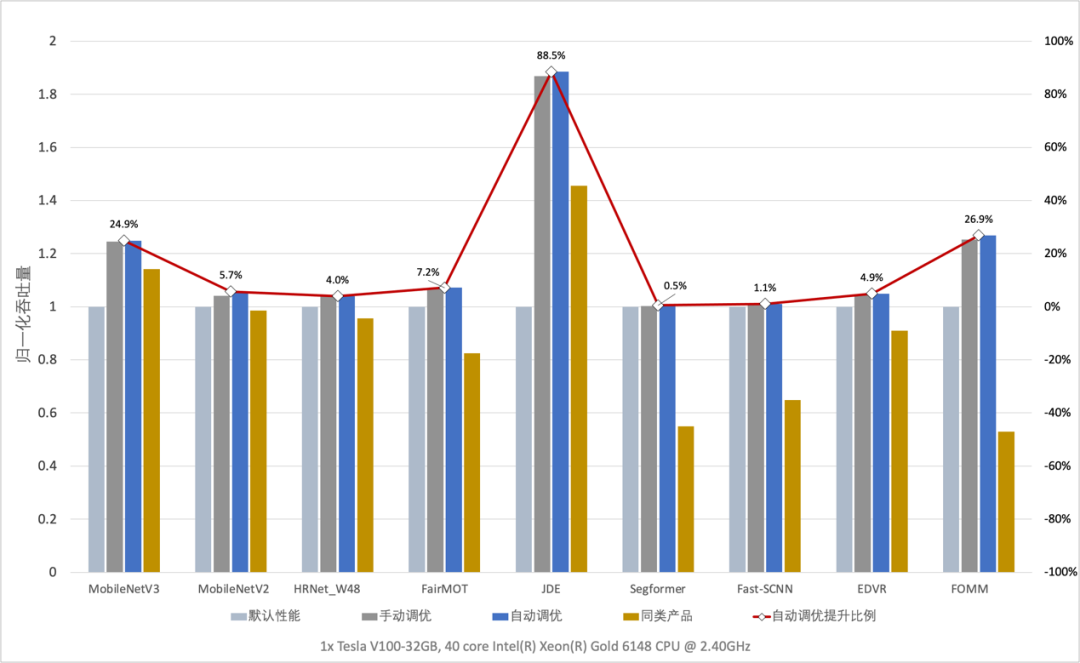
paddle.incubate.autotune.set_config(config)通过实验对比,飞桨框架自动调优后的训练性能,可以持平或超越专家级手工配置优化的效果,而且在不少模型上相对飞桨或其它框架的默认配置都有较大幅度的性能提升。
结语
飞桨框架2.3版本发布的多层次性能自动调优技术,可以一键开启优化,自动适配不同硬件环境,大幅降低开发者性能优化所需的技术门槛,自动调优后的训练性能可以达到与专家级手工配置优化持平或超越的效果,发挥框架的极致性能。当下,飞桨正进一步强化自动调优能力,以期在更多的模型和硬件场景下发挥更显著的作用。未来会将多层次性能自动调优功能默认开启,并加入更多的自动调优策略,期待更多的开发者能够应用此功能提高模型训练效率。
拓展阅读
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~
2022年5月,飞桨框架2.3版本正式发布,创新性地提出了业界首个全流程硬件感知的性能自动调优解决方案,支持“一键开启”的极简操作方式,使开发者无需对模型代码进行任何改动,就可以充分发挥框架和硬件的极致性能。大量模型实验表明,自动调优可达到持平甚至超越经验丰富的性能优化专家手工调整的效果,解决了开发者性能优化费时费力的问题。
深度学习模型的训练往往需要耗费大量机器资源和时间,因此众多AI开发者非常迫切地追求极致性能。通过性能优化,一方面可以缩短模型效果验证的周期,提高研发效率;另一方面也会节约大量的资金成本并有效减少碳排放。例如OpenAI设计并发布的GPT-3模型,据估算一次训练成本高达400余万美元,以致于即使研发人员在训练过程中发现了一个错误,但由于成本原因也并未进行修复。
针对开发者在性能优化方面的痛点问题,飞桨框架2.3版本依据模型整体性能关键点推出了业界首个全流程自动调优方案,在训练时框架可根据不同模型针对不同硬件自动调整运行配置、选择最优算子内核(Kernel)等,使模型获得最佳性能,其效果可以与经验丰富的性能优化专家持平,很好地解决了在各种硬件平台针对不同任务的模型手工调优难的问题。
模型训练主要性能瓶颈分析
通常我们会以训练精度、训练速度、所需资源来评价一个模型训练性能的优劣。在模型训练收敛的迭代次数不变的情况下,训练速度可以用吞吐量(Instances Per Second,IPS)即每秒处理的样本数目来直观表示。模型的吞吐量会受到多种因素影响,我们首先从硬件层面来分析,看看是哪些情况影响了硬件的执行效率。以下面训练任务的时间轴(timeline)示意图为例,我们可以将常见的性能瓶颈归类为3个方面:
I/O瓶颈:
CPU瓶颈
GPU瓶颈
虽然GPU提供了很高的算力,但如果GPU算子实现不够高效,也会导致性能较差。如下图示例中Op4的GPU处理时间明显很长,可能存在较多的优化空间。
数据读取
很多框架都提供了多进程数据读取的功能,但进程数的设置完全依赖用户经验,设置不当反而还会导致性能变差
配置参数
尤其在使用混合精度训练时,需要使Tensor的布局和大小等设置满足硬件限制,目前需要开发人员手工调整
算子性能
大多数框架基本都会用cuDNN、cuBLAS等高性能加速库,但是在各种硬件、各种尺寸和数据类型的场景下,单一加速库也难以保障性能保持最优,不同场景下可能需要使用不同的算子实现,这也需要开发者有足够的经验以及分析能力才能确认
框架调度
一些模型计算开销并不大,这种场景下框架执行调度的开销会对模型性能产生明显影响
模型实现
多层次性能自动调优技术
针对不同硬件环境下默认的DataLoader参数配置无法发挥硬件最优性能的问题,在训练开始前,飞桨根据模型的输入数据、训练的硬件对DataLoader参数自动搜索,在训练过程中,使用调优后的配置读取数据。
数据布局(Layout)自动切换
针对各种数据类型、输入尺寸和配置参数下,单一的算子内核难以保证在所有场景下达到最佳性能的问题,飞桨引入调优区间的概念,将整个训练过程分为观察阶段、调优阶段、应用阶段。观察阶段,使用默认实现便于用户调试;调优阶段,使用穷举搜索法选择代价最小的Kernel并进行缓存;应用阶段,依据算子配置从缓存中获取算法,未命中则使用默认实现。基于该功能,模型在输入尺寸固定或动态变化的场景下均可通过算法搜索获得性能提升。
数据读取参数自动调优
目前主流深度学习框架都在数据读取方面进行了底层优化,比如通过多进程并发处理数据读取、预处理以及组batch等任务,通过共享内存加速进程间数据传输,通过异步操作来消除数据拷贝过程的耗时,从而实现异步、并发的方式加速数据读取、预处理和数据拷贝等数据I/O任务。显然,并发对数据读取的性能有很大作用,但大多数框架对并发度的设置(num_workers)仅提供了一个基础的默认值,比如飞桨和PyTorch的默认值都为"0",即仅采用主线程读取数据,此默认设置难以在各种硬件环境下达到最优的性能。考虑到机器设备的CPU核数量有限,数据读取的并发数并非越大越好,过大的并发数会加重CPU进程调度的负担,导致整体性能反而降低。由于最优并发度的设置与硬件相关,因此大多数框架目前都将此设置交给开发者决策,尽管开发者可以通过手工调整提升读取性能,但仍需多次测试才能找到最合适的num_workers参数,无疑增加了模型训练的操作成本。
计算机视觉类的任务由于图像数据的读取和预处理开销较高,如果DataLoader未启用多进程异步数据读取,则非常容易出现I/O瓶颈。以目标检测的JDE模型为例,通过性能分析我们发现模型的数据读取开销占比高达51.71%,使用自动调优功能后,模型的数据读取降低至0.56%,同时吞吐量从原始的 9.14 samples/s 提升到13.60samples/s,性能提升了49%。
数据布局(Layout)自动调优
深度学习框架中针对多维数组通常支持通道在前(NCHW)和通道在后(NHWC)两种格式,在不同硬件上数据排布方式的选择会对性能产生较大的影响。下图实验是Conv算子在不同数据布局和数据类型下的前向运算耗时,结果表明在V100 GPU上固定输入、输出通道数及卷积核尺寸的前提下,FP32计算采用NCHW数据布局性能最优,而FP16计算则是采用NHWC最优。因此当一个使用NCHW数据布局的FP32模型想要开启混合精度模式来进行加速的时候,要么需要开发者手动对数据布局进行调整,要么需要额外在相关算子前后插入Transpose操作对数据布局进行转换,但这样又会带来额外的转换开销。
功能和性能与数据布局强相关的算子:
例如Conv,这类算子会在输入不是最佳数据布局时,将输入转换为最佳数据布局:
功能与数据布局强相关,性能影响较弱的算子:
例如Flatten,由于计算过程涉及到张量维度配置,其功能会受数据布局影响。根据输入的数据布局,可以对start和stop的axis做调整达到等效的结果,而在无法通过调整算子参数达到等效时,则需要将输入转换回原始的数据布局进行计算:
在自动调优的过程中,飞桨会引入最小的转换代价使模型在最佳数据布局下运行,换取更大的性能收益。使用V100 GPU进行ResNet50的混合精度训练,在模型默认数据布局为NCHW的情况下,开启自动调优后吞吐量提升了26.8%,与手工调优性能持平。
多版本算子内核自动选择
在实现方案上,算子内核自动选择功能由观察阶段、优化阶段、执行阶段组成,各阶段的主要功能如下:
观察阶段
优化阶段
框架自动采用穷举计算模式,针对当前算子的输入调用全部可用算法计算,记录并比较各算法的性能,从中选出最高效算法后,利用Cache机制将当前计算场景与被选中算法进行绑定,保证当前计算场景在后续复现时,算子内可以立即查询Cache并执行最高性能算法。
执行阶段
根据cache信息调用最佳算法完成算子计算,若在后续计算中面对数据变换等情形时,则走入默认计算分支,避免庞大的算法选择开销。
算子内核自动选择机制可有效应对各类变尺度数据集训练场景,挖掘算子内各算法性能潜力,在各类训练场景下获得良好的性能收益。例如PaddleDetection套件中数据shape变化非常大的JDE模型,可以发现开启算子内核自动选择功能后,模型的训练性能可以获得大幅提升,且超越了手动设置cuDNN启发式搜索模式等各种手动设置的性能。
此外,飞桨提供的算子内核自动选择机制在设计上不仅覆盖了框架原生的多种算子实现,还覆盖飞桨深度学习编译器中生成和优化的算子,结合编译器对算子的自动优化能力,可以达到更好的性能。在ResNet50模型上的测试表明,性能已经可以持平业界最优编译器优化的结果。
一键开启自动调优
飞桨框架2.3版本可以通过以下方法:
paddle.incubate.autotune.set_config(config=None)
一键开启所有自动调优功能。也可以根据调试的需求自定义调优功能的开和关:
kernel
layout
dataloader
config = {
"kernel": {
"enable": True,
"tuning_range": [1, 5],
"layout": {
"enable": True,
"dataloader": {
"enable": True,
paddle.incubate.autotune.set_config(config)通过实验对比,飞桨框架自动调优后的训练性能,可以持平或超越专家级手工配置优化的效果,而且在不少模型上相对飞桨或其它框架的默认配置都有较大幅度的性能提升。
结语
飞桨框架2.3版本发布的多层次性能自动调优技术,可以一键开启优化,自动适配不同硬件环境,大幅降低开发者性能优化所需的技术门槛,自动调优后的训练性能可以达到与专家级手工配置优化持平或超越的效果,发挥框架的极致性能。当下,飞桨正进一步强化自动调优能力,以期在更多的模型和硬件场景下发挥更显著的作用。未来会将多层次性能自动调优功能默认开启,并加入更多的自动调优策略,期待更多的开发者能够应用此功能提高模型训练效率。
拓展阅读
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~